Dynamic Language Models for Continuously Evolving Content
KDD 2021
분야 및 배경지식
새로운 단어 처리 (Out Of Vocabulary; OOV)
- 임베딩을 공유하는 특별한 토큰(예: UNK)으로 모든 새로운 단어를 대체
- 각각의 새로운 단어에 유일한 랜덤 임베딩 부여
- 단어를 더욱 작은 단위(fine-grained)로 분할
- 단어의 임베딩을 만들기 위해 fine-grained unit의 임베딩을 결합하는 레이어를 추가하기도 함
- 하지만 몇몇 단어들은 이러한 세부 유닛(subunit)들로부터 추론될 수 없음
- on the fly; OOV 단어를 포함한 예시 문장들과 사전 내 OOV 단어의 정의와 같은 문맥을 활용해 임베딩 생성
시간에 따른 의미의 변화 (Semantic Shift)
- 몇 개의 단어를 골라 오랜 기간 의미의 변화를 추적하거나, distributed representation에 있는 단어의 의미 변화를 자동으로 감지하는 연구
- 전체 시기에 걸쳐 시간을 인지하는(time-aware) 임베딩을 배움과 동시에 정렬(alignment) 문제를 해결하도록 하는 연구
- 기존 연구의 한계: 대부분의 선행 연구들은 비문맥화된(non-contextualized) 임베딩에 기반하였으며 연구 중 일부만 Transformer 기반의 언어모델에 대해 연구
Increment Learning
- 기존 모델의 성능을 확장시키기 위해 연속적으로 학습(예: 연속적으로 class와 같은 input data를 늘리는 등)
- 새로운 정보를 배울 때 기존에 학습한 정보를 까먹는 catastrophic forgetting 문제 발생 가능
- 다른 incremental learning과는 다르게, 해당 연구의 경우 기존의 단어들의 의미 또한 변할 수 있음 (새로운 데이터만 추가되는 것이 아니라)
문제점
- 웹 컨텐츠는 계속해서 진화하고 언어모델은 이를 잘 처리할 수 있도록 적응(adapt)해야 함
- 세상 또한 변하지만, 특히 트위터와 같은 웹 컨텐츠에서 의미의 변화가 더욱 빠르고 크게 일어남
- 기존의 토큰들의 의미적인 변화(semantic shift)에 잘 대응해야
- 새로 등장한 토큰들을 잘 이해해야
해결책
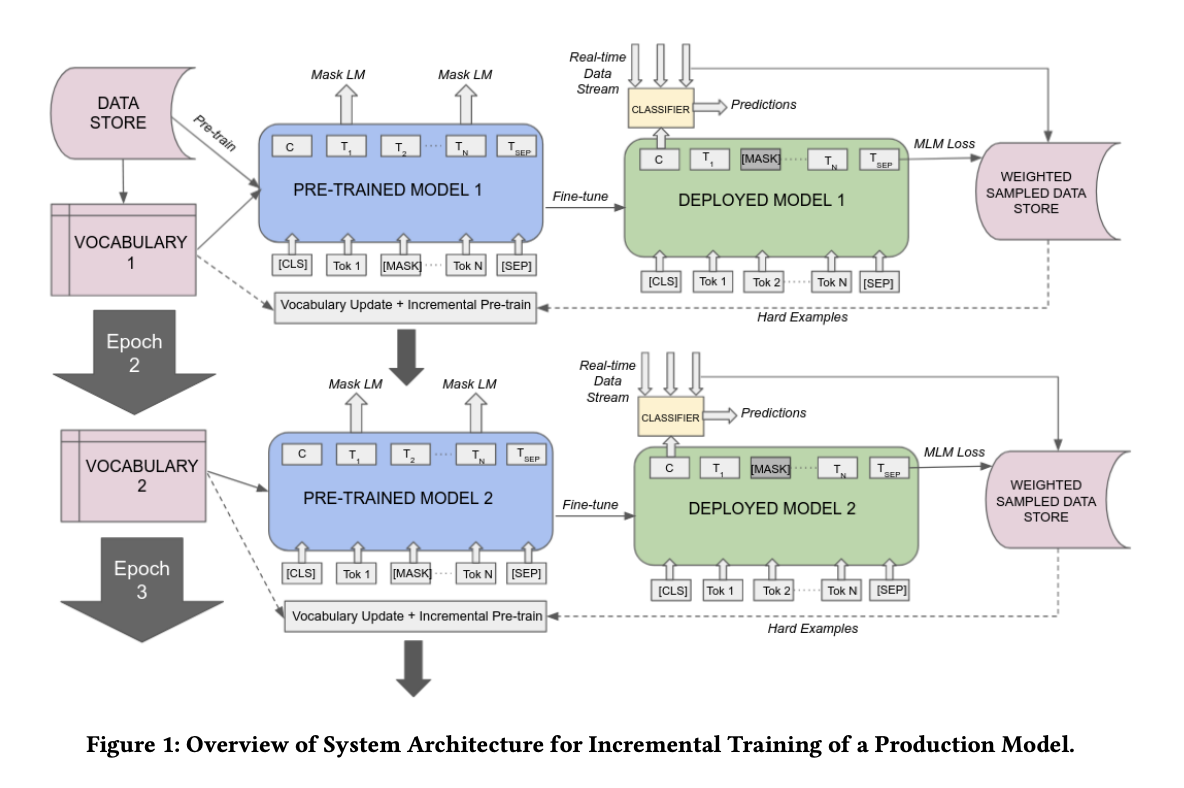
wordpiece vocabulary를 역동적으로 업데이트
- 오래된 wordpiece를 제거하고 새로 등장한 wordpiece를 더함으로써 단어사전을 최신으로 유지
- 효율적인 모델의 parameterization을 보장하기 위해 일정한 크기를 유지
효율적인 샘플링 방식 제안 (3가지)
- 진화하는 컨텐츠를 포함하는 대표적인 트윗들을 뽑아내기 위함
- active learning과 연관성 존재
1) Token Embedding Shift Method
- 이전 모델과 업데이트된 모델의 토큰 임베딩 사이의 cosine distance를 측정
- 가장 큰 임베딩의 변화를 보인 최상위 X 토큰들을 확인 (X는 도메인에 의존)
- 샘플링할 때 커다란 임베딩 변화를 보인 특정 토큰들을 포함한 트윗들에 더 큰 비중(weight)을 할당
- 길이에 따른 영향을 없애기 위해 트윗 길이를 정규화(normalize)해 임베딩 cosine distance와 선형적으로 결합
2) Sentence Embedding Shift Method
- 이전 모델과 업데이트된 모델의 문장 임베딩 사이의 cosine distance를 측정
- weighted random sampling을 수행하기 위해 임베딩 cosine distance와 트윗 길이의 결합을 사용
3) Token MLM Loss Method
- BERT가 사전학습을 수행할 때 사용했던 Masked Language Modeling (MLM) loss 이용
- 사전학습된 BERT의 마지막 레이어에서 토큰들을 직접 마스킹(mask)한 후 같은 레이어의 주변 토큰들을 사용해 마스킹된 토큰들을 예측
- 모델의 실시간 실행 품질(online serving quality)에 큰 영향을 미치지 않을 뿐 아니라 계산 자체가 가벼움
- 배포된 모델의 새로운 데이터에서 상당한 MLM loss의 증가가 발생할 경우, 새로운 incremental training이 실시됨
- 새로운 데이터로부터 어려운 예시들을 가져와 모델 단어사전을 업데이트하고, 연속적으로(incrementally) 이 예시들을 활용해 사전학습 진행
- 그 이후 특정 태스크를 위해 모델을 파인튜닝
평가
사전학습
- 모델: year-based Twitter BERT models on Masked Language Modeling task
- 데이터셋: 2013-2019 트위터 코퍼스
Downstream Tasks (finetuning)
- Country Hashtag Prediction (2014-2017): 모델의 단어사전에 인기있는 전체 해시태그(#) 포함
- 평가지표: micro-F1, macro-F1, accuracy
- OffensEval (2019): #을 제거하고 모든 해시태그를 wordpiece로 구분
- 평가지표: F1 score, AUC-ROC
의의
- 처음부터 새로 학습하는 것에 비해 학습비용 감소, 더 좋은 성능 달성, 실시간 배포에 유리
- 새로운 데이터에 모델을 적응(adapt)시키는 것이 성능을 굉장히 많이 향상시킴
- 모든 incremental 방식(연속학습 방식)이 기본적인 모델(base model)보다 월등히 성능이 향상됨
- incremental model이 새로운 컨텐츠를 계속해서 학습함에도 불구하고 지난 연도로부터 상속된 지식이 유용함을 보임
- incremental model 중에서 이 논문에서 제안한 세 개의 샘플링 방식이 기존의 샘플링 방식보다 큰 성능 향상을 보임
한계
- novelty가 약함 (단순한 접근방식)
- 트윗 기반의 모델에 대해 집중, 다른 다양한 태스크에도 과연 해당 방식이 적용 가능할지 의문

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab