채용 시 코딩테스트의 골자는 기초 알고리즘을 활용하여, 주어진 상황을 코드로 얼마나 잘 구현해낼 수 있는가임
Chapter1. Algorithm
Chapter2. 시간 복잡도와 공간복잡도
Chapter2-1. 시간 복잡도(Time Complexity)
Chapter2-2. 공간 복잡도(Space Complexity)
Chapter3. Algorithm의 유형
Chapter3-1. Greedy Algorithm
Chapter3-2. Algorithm 구현
Chapter3-3. Dynamic Programming
Chapter3-4. Algorithm의 유형 예제
- Greedy Algorithm
- Algorithm 구현 - Brute-Force Algorithm
- Dynamic Programming - 피보나치 수열과 타일링
연습문제 - Algorithm의 유형
Chapter4. Algorithm with Math
Chapter4-1. 순열과 조합
Chapter4-2. GCD와 LCM
Chapter4-3. 멱집합
Chapter4-4. Algorithm with Math 예제
- 순열과 조합 - 순열과 조합을 이용한 문제들
- GCD와 LCM - GCD와 LCM을 이용한 문제들
- 멱집합 - Power Set
연습문제 - Algorithm with Math
Chapter5. 정규표현식
Chapter1. Algorithm
알고리즘은 문제를 해결하는 최선의 선택입니다.
과연 최선인 경우의 수는 무엇일까? 컴퓨터를 이용해 문제를 해결할 때에는, 무수히 많은 방법을 시도할 수 있다. 모든 경우의 수를 하나씩 비교해서 그 중 최선을 골라낼 수도 있다. 또, 하나씩 비교하지 않더라도 가장 좋아 보이는 것을 먼저 찾아냈다면, 뒤쪽의 경우의 수를 그냥 무시하는 경우도 있다.
컴퓨터가 데이터를 비교하고 연산하는 속도가 너무 빠르기 때문에, 이 과정을 보는 사람들에게는 컴퓨터가 그저 입력과 동시에 결과를 출력하는 걸로 보인다.
질문
컴퓨터는 어떻게 최선의 수를 찾을 수 있을까?
컴퓨터는 어떻게 문제를 해결할까?
- 일상 생활과 알고리즘의 관계에 대해 이해한다.
- 알고리즘이 무엇인지 학습하고 이해한다.
- 알고리즘이라 명시되기 위한 조건에 대해 학습하고 이해한다.
- 알고리즘의 중요성에 대해 학습하고 이해한다.
알고리즘이란?
알고리즘은 9세기 경 아라비아의 천문학자이자 수학자인 알고리즈미(al-Khowarizmi)의 이름에서 유래되었다. 알고리즈미는 십진법에 의해 덧셈, 뺄셈, 곱셈, 나눗셈, 제곱근, 원주율을 구하는 방법을 아랍어로 기록해 놓았는데, 이런 식으로 사칙연산 및 다양한 산술의 해를 구하는 절차를 공식화 해놓은 기록이 후에 알고리즘으로 발전되었다.
즉 알고리즘은 어떤 문제를 해결하기 위해서 일련의 절차를 정의하고, 공식화한 형태로 표현한 일종의 문제의 풀이 방법, 해(解)를 의미한다. 이런 알고리즘은 프로그래밍에서는 input 값을 통해 output 값을 얻기 위한 계산 과정을 의미한다. 주어진 문제를 해결할 때, 정확하고 효율적으로 결과 값을 얻는 것이 필요하고 그때 바로 이 알고리즘이 사용된다. 문제 해결을 위한 단계들을 체계적으로 명시할 수 있는 상황이라면 그것은 알고리즘으로 충분히 풀어낼 수 있다고 볼 수 있다.
그렇다면 일련의 절차를 정의하고, 공식화만 시킨다면 전부 알고리즘이라고 볼 수 있을까? nope. 어떠한 문제 해법이 알고리즘이라 명시 되려면 일정한 조건들을 반드시 만족해야만 한다.
여기 일상생활에서 볼 수 있는 상황이 하나 있다.
횡단보도 옆에 신호등이 있다. 현재는 빨간불이지만 5분 뒤에는 초록불로 바뀔 것이다.
5분이 지나고, 초록불로 바뀐 신호등은 10초 뒤 ‘30’이라는 숫자와 함께 1초에 한 번씩 점등하기 시작한다.
총 30번을 점등한 신호등은 이어 빨간불로 바뀐다.
- 입력(Input) : 알고리즘은 출력에 필요한 자료를 입력받을 수 있어야 한다. 이 상황에서는 우선, 빨간불인 신호등이 초록불이 되려면 5분이라는 시간을 입력 받아야 한다.
- 참고로, 신호등은 항상 시간을 입력받아야 알고리즘이 동작하지만 꼭 입력을 받지 않아도 되는 알고리즘도 있다. (ex. 원주율(pi)의 1조 번째 자리 수를 구하려는 경우 입력은 없지만 출력은 있다.)
- 출력(Output) : 알고리즘은 실행이 되면 적어도 한 가지 이상의 결과를 반드시 출력해야 한다. 만약 알고리즘에 출력이 없다면 이 알고리즘은 끝이 났는지, 끝이 나지 않았는지 확인할 길이 없기 때문이다. 출력은 알고리즘에서 “끝이 났다" 라는 표현이므로 반드시 존재해야 하며, 이는 유한성과도 연관이 있다. 이 상황에서 출력은 “초록불로 바뀐다"이다.
- 유한성(Finiteness) : 알고리즘은 유한한 명령어를 수행한 후, 유한한 시간 내에 종료해야 한다. 이는 알고리즘은 실행된 후에는 반드시 종료되어야 한다는 말과도 같다. 알고리즘이 무한히 실행이 된다면 무한히 기다려야 할 것이며, 그것은 출력의 기약이 없는 알고리즘일 것. 신호등이 빨간불인 상태에서 초록불로 변하는 과정에 대한 기약이 없다면 그 신호등은 제대로 된 알고리즘으로 동작하는 것이 아님.
- 명확성(Definiteness) : 알고리즘의 각 단계는 단순하고 명확해야 하며, 모호해서는 안 된다. 예를 들어 ‘신호등이 몇 분 뒤에 켜집니다’ 와 같이 표현한다면, 명확성이 떨어질 뿐더러 모호한 표현이라고 볼 수 있다. ‘신호등이 5분 뒤에 켜집니다‘ 와 같이 명확하게 표현을 해야만 한다.
- 효율성(Efficiency) : 알고리즘은 가능한 한 효율적이어야 한다. 모든 과정은 명백하게 실행 가능해야 하며, 실행 가능성이 떨어지는 알고리즘은 효율적이지 못한 알고리즘이라 볼 수 있다. 알고리즘은 시간 복잡도와 공간 복잡도를 통해 결정이 되므로, 시간 복잡도와 공간 복잡도가 낮을수록 효율적인 알고리즘이라 볼 수 있다.
알고리즘의 중요성
알고리즘은 프로그래밍 뿐이 아니라 일상생활에서도 다양한 문제를 해결하는 데에 활용할 수 있다. 좋은 알고리즘은 절차가 명확하게 표현되어 있고, 효율적이므로 다양한 문제 해결 과정에서 나타나는 불필요한 작업들을 줄여줄 수 있다.
다만, 알고리즘의 순서가 달라지면 결과 또한 다르게 나타날 수 있다는 것은 주의해야할 점이다.
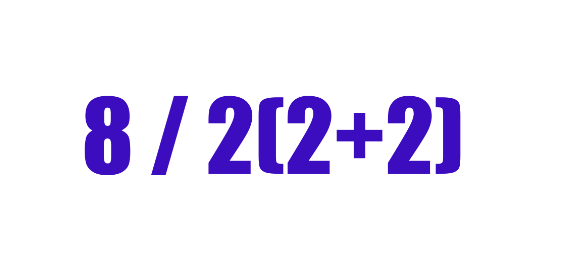
이 사칙연산 문제는 한 때 커뮤니티를 뜨겁게 달궜던 문제이다. 계산을 어떻게 하느냐에 따라 답이 16과 1, 두 개로 나뉘었기 때문. 수식을 계산하는 방식에는 우위가 있으며 그 우선순위는 대괄호, 지수, 나누기, 곱하기, 더하기 및 빼기 순으로 두는 것이 사칙연산의 기본적인 개념이다. 이 우위는 수식 내에 다양하게 섞여 있을수록 더욱 중요해진다.
문제가 되는 해당 사칙연산의 알고리즘을 짤 당시 곱셈과 나눗셈, 괄호로 이뤄진 수식을 계산할 때 이런 계산 방식의 우위를 따르면 당연히 괄호 안에 있는 것부터 먼저 연산하도록 알고리즘을 짤 것이다. 여기서 중요한 것은 그 다음 연산부터이다.

“괄호와 가까운 연산부터 순서대로 연산한다" 와 “왼쪽부터 순서대로 연산한다" 중에서 어떤 연산 순서 규칙을 선택하느냐에 따라 답이 달라지게 된다. 괄호와 가까운 순서부터 연산하게 되면 1이 나오게 되고, 왼쪽부터 순서대로 연산하게 되면 16이 나오게 됨.
사실, 해당 사칙연산의 답은 괄호가 있을 뿐 단순한 계산식이기 때문에 왼쪽부터 순서대로 계산을 해야 하므로 16이 정답이 된다. 그러나 계산 알고리즘을 이와 다른 규칙으로 로직을 짠 다른 계산기인 경우 답이 1로 다르게 나오게 되는 것임
정확하지 않은 알고리즘은 정확하지 않은 해(解)를 내놓게 된다. 정확하지 않은 답은 혼란을 주고, 프로그래밍 자체에 큰 문제를 야기할 수 있다. 그러므로 알고리즘은 정확하게 짜는 것이 그 무엇보다도 중요하다.
알고리즘은 어떻게 해야 잘 풀 수 있을까?
문제를 이해하자(정확한 문제 정의)
대부분의 코딩 테스트에서는 문제의 설명과 입출력예시, 제한사항, 그리고 주의사항 등으로 문제 상황을 제시한다. 주어진 조건을 토대로 문제가 무엇인지를 이해하는 것부터 시작해야 한다.
문제를 어떻게 해결할 수 있을지, 전략을 세우자.
- 연습장에 전체적인 그림을 그려보자. 전체적인 흐름을 이해할 수 있음.
- 수도코드를 작성하기 전, 인간의 사고로 문제를 해결할 수 있어야 한다. 연습장이나 온라인 화이트보드를 사용하여 문제에 대해 논의하고 해결하자.
- 코드를 작성하기 전에 수도코드를 먼저 작성하자! 알고리즘 전략은 잘 짜여진 수도코드에서부터 시작한다!
- 막혔던 생각이 설명을 하면서 해결되는 경우도 있다.
문제를 코드로 옮겨 보자.
- 앞서 논의한 전략을 코드로 옮겨 보자!
- 구현한 코드를 페어와 논의해 보고, 구현한 코드의 최적화를 시도해 보자!
그래서, 알고리즘을 공부해야하는 이유는?
우리가 개발자로서 만나게 될 대부분의 개발 태스크는 알고리즘 문제만큼 어렵지 않다고 함. 그러나 새로운 문제에 봉착했을 때, 전략과 알고리즘을 구상하여 실제로 코드로 구현해 보는 경험은 매우 중요하다.
많은 기업에서 주니어 개발자를 채용할 때에, 알고리즘 풀이를 통해 지원자의 역량을 가늠한다. 알고리즘 풀이를 통해 지원자의 로직과 문제해결 방식을 확인하고, 이를 통해 개발자다운 사고방식을 보는 것이다.
이번 유닛에서는 문제를 해결하여 정확한 답안을 출력해야 한다. 그러나 정확한 답을 찾는 일이 최종목표는 아님. 이 유닛의 최종 목표는 문제를 해결하기 위해 고군분투하는 그 과정을 경험하고, 개발자로서 더 성장하는 것이다. 어렵지만 끝까지 포기하지 않는 것이 답을 내는 것보다 더 중요하다. 문제를 풀지 못했다고 해서 절대로 좌절하지 말자. 누구에게나 처음은 있는 법이니까.
Chapter2. 시간 복잡도와 공간복잡도
알고리즘 문제를 풀다 보면 문제에 대한 해답을 찾는 것이 가장 중요하다. 그러나 그에 못지않게, 효율적인 방법으로 문제를 해결했는지도 중요하다. 혹시 문제를 풀다가, 이것보다 더 효율적인 방법은 없을까? 또는 이게 제일 좋은 방법이 맞나? 라는 생각을 해 본 적이 있는가? 효율적인 방법을 고민한다는 것은 시간 복잡도를 고민한다는 것과 같은 말이다.
- 시간 복잡도가 무엇인지 학습하고 이해합니다.
- Big-O 표기법에 대해 학습하고, 각 종류에 대해 이해합니다.
- 데이터 크기에 따른 시간 복잡도에 대해 학습하고 이해합니다.
- 공간 복잡도의 개념에 대해 이해합니다.
- 가변 공간과 고정 공간에 대해 이해합니다.
- 공간 복잡도의 중요성에 대해 이해합니다.
Chapter2-1. 시간 복잡도(Time Complexity)
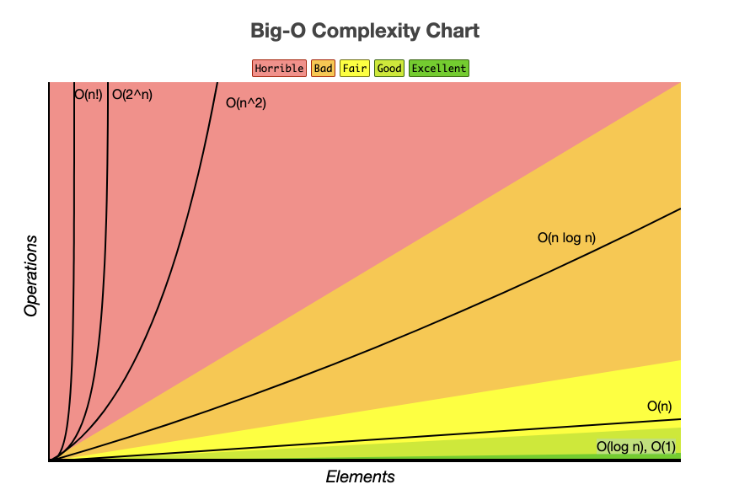 [그림] 시간 복잡도 그래프
[그림] 시간 복잡도 그래프
문제를 해결하기 위한 알고리즘의 로직을 코드로 구현할 때, 시간 복잡도를 고려한다는 것은 무슨 의미일까? 한 문장으로 정리하자면 다음과 같다.
입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?
앞서 이야기했던 효율적인 알고리즘을 구현한다는 것은, 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다. 그리고 이 시간 복잡도는 주로 빅-오 표기법을 사용해 나타낸다.
Big-O 표기법
시간 복잡도를 표기하는 방법은 다음과 같다.
- Big-O(빅-오)
- Big-Ω(빅-오메가)
- Big-θ(빅-세타)
위 세 가지 표기법은 시간 복잡도를 각각 최악, 최선, 중간(평균)의 경우에 대하여 나타내는 방법이다.
이 중에서 Big-O 표기법이 가장 자주 사용된다. 빅오 표기법은 최악의 경우를 고려하므로, 프로그램이 실행되는 과정에서 소요되는 최악의 시간까지 고려할 수 있기 때문이다. "최소한 특정 시간 이상이 걸린다" 혹은 "평균적으로 이 정도 시간이 걸린다"를 고려하는 것보다 "이 정도 시간까지도 걸릴 수 있다"를 고려해야 그에 맞는 대응이 가능하다.
결과를 반환하는 데 최선의 경우 1초, 평균적으로 1분, 최악의 경우 1시간이 걸리는 알고리즘을 구현했고, 최선의 경우를 고려한다고 가정해보자. 이 알고리즘을 100번 실행한다면, 최선의 경우 100초가 걸린다. 만약 실제로 걸린 시간이 1시간을 훌쩍 넘겼다면, 어디에서 문제가 발생한 거지?란 의문이 생길 것. 최선의 경우만 고려하였으니, 어디에서 문제가 발생했는지 알아내기 위해서는 로직의 많은 부분을 파악해야 하므로 문제를 파악하는 데 많은 시간이 필요해짐. 평균값을 기대하는 시간 복잡도를 고려하는 것도 결국 최선의 경우를 고려한 것과 같은 고민을 하게 된다.
따라서 다른 표기법보다 Big-O 표기법을 많이 사용한다.
다만, 최악의 경우가 발생하지 않기를 바라며 시간을 계산하는 것이 아닌, 최악의 경우도 고려하여 대비하는 것이 바람직하다.
Big-O 표기법의 종류
O(1)
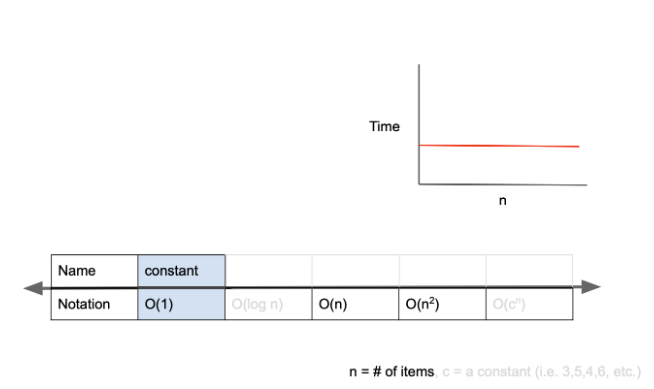
Big-O 표기법은 입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?를 표기하는 방법dl다. O(1)는 constant complexity라고 하며, 입력값이 증가하더라도 시간이 늘어나지 않는다. 다시 말해 입력값의 크기와 관계없이, 즉시 출력값을 얻어낼 수 있다는 의미이다.
O(1)의 시간 복잡도를 가진 알고리즘을 살펴보자.
function O_1_algorithm(arr, index) {
return arr[index];
}
let arr = [1, 2, 3, 4, 5];
let index = 1;
let result = O_1_algorithm(arr, index);
console.log(result); // 2위 알고리즘에선 입력값의 크기가 아무리 커져도 즉시 출력값을 얻어낼 수 있다. 예를 들어, arr의 길이가 백만, 몇백만이더라도, 즉시 해당 index에 접근해 값을 반환할 수 있다.
O(n)
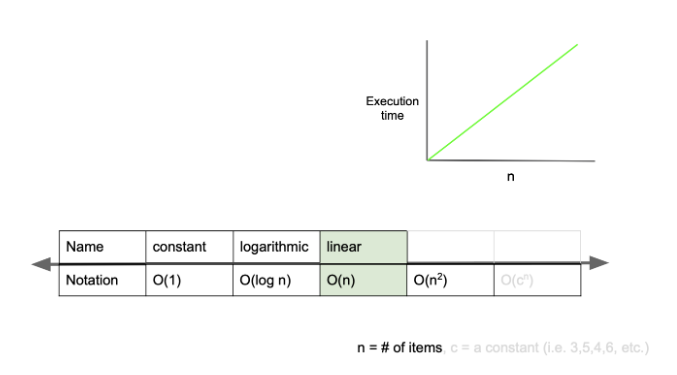
O(n)은 linear complexity라고 부르며, 입력값이 증가함에 따라 시간도 같은 비율로 증가하는 것을 의미한다.
예를 들어 입력값이 1일 때 1초의 시간이 걸리고, 입력값을 100배로 증가시켰을 때 1초의 100배인 100초가 걸리는 알고리즘을 구현했다면, 그 알고리즘은 O(n)의 시간 복잡도를 가진다고 할 수 있다.
O(n)의 시간 복잡도를 가진 알고리즘을 살펴보자.
function O_n_algorithm(n) {
for (let i = 0; i < n; i++) {
// do something for 1 second
}
}
function another_O_n_algorithm(n) {
for (let i = 0; i < 2n; i++) {
// do something for 1 second
}
}O_n_algorithm 함수에선 입력값(n)이 1 증가할 때마다 코드의 실행 시간이 1초씩 증가한다. 즉 입력값이 증가함에 따라 같은 비율로 걸리는 시간이 늘어나고 있다.
그렇다면 함수 another_O_n_algorithm 은 어떤가? 입력값이 1 증가할때마다 코드의 실행 시간이 2초씩 증가한다.
이것을 보고, "아! 그렇다면 이 알고리즘은 O(2n) 이라고 표현하겠구나!" 라고 생각할 수 있다. 그러나, 사실 이 알고리즘 또한 Big-O 표기법으로는 O(n)으로 표기한다. 입력값이 커지면 커질수록 계수(n 앞에 있는 수)의 의미(영향력)가 점점 퇴색되기 때문에, 같은 비율로 증가하고 있다면 2배가 아닌 5배, 10배로 증가하더라도 O(n)으로 표기한다.
O(log n)
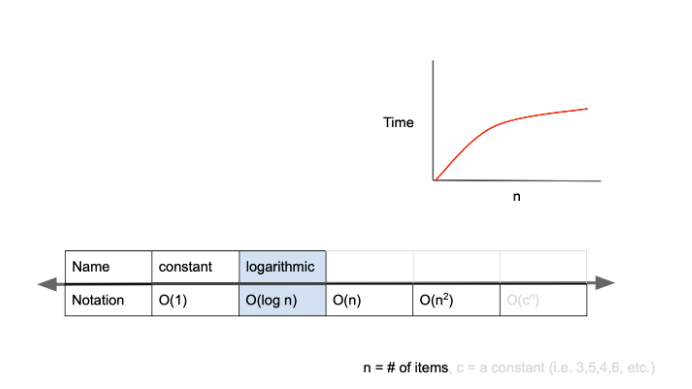
O(log n)은 logarithmic complexity라고 부르며 Big-O표기법중 O(1) 다음으로 빠른 시간 복잡도를 가진다.
대표적인 예로, BST(Binary Search Tree)가 있다. BST에서는 원하는 값을 탐색할 때, 노드를 이동할 때마다 경우의 수가 절반으로 줄어든다.
O(n^2)
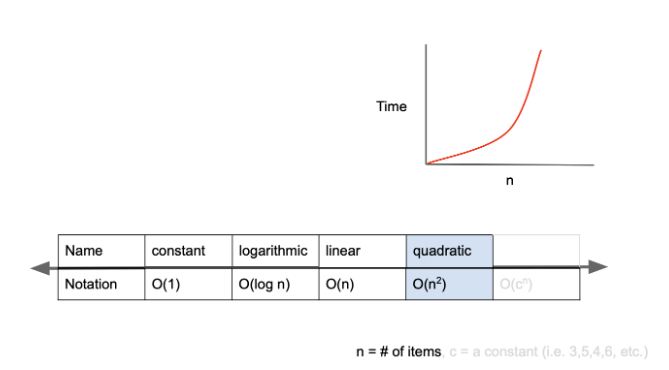
O(n^2)은 quadratic complexity라고 부르며, 입력값이 증가함에 따라 시간이 n의 제곱수의 비율로 증가하는 것을 의미한다.
예를 들어 입력값이 1일 경우 1초가 걸리던 알고리즘에 5라는 값을 주었더니 25초가 걸리게 된다면, 이 알고리즘의 시간 복잡도는 O(n^2)라고 표현한다.
O(n^2)의 시간 복잡도를 가진 알고리즘을 살펴보자.
function O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
// do something for 1 second
}
}
}
function another_O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
for (let k = 0; k < n; k++) {
// do something for 1 second
}
}
}
}2n, 5n 을 모두 O(n)이라고 표현하는 것처럼, n^3과 n^5 도 모두 O(n^2)로 표기한다. n이 커지면 커질수록 지수가 주는 영향력이 점점 퇴색되기 때문에 이렇게 표기한다.
O(2^n)
O(2n)은 exponential complexity라고 부르며 Big-O 표기법 중 가장 느린 시간 복잡도를 가진다.
종이를 42번 접으면 그 두께가 지구에서 달까지의 거리보다 커진다는 이야기를 들어보신 적 있는가? 고작 42번 만에 얇은 종이가 그만한 두께를 가질 수 있는 것은, 매번 접힐 때마다 두께가 2배로 늘어나기 때문이다.
구현한 알고리즘의 시간 복잡도가 O(2n)이라면 다른 접근 방식을 고민해 보는 것이 좋다.
function fibonacci(n) {
if (n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}재귀로 구현하는 피보나치 수열은 O(2n)의 시간 복잡도를 가진 대표적인 알고리즘이다.
브라우저 개발자 창에서 n을 40으로 두어도 수초가 걸리는 것을 확인할 수 있으며, n이 100 이상이면 평생 결과를 반환받지 못할 수도 있다.
데이터 크기에 따른 시간 복잡도
일반적으로 코딩 테스트 문제를 풀 때에는 정확한 값을 제한된 시간 내에 반환하는 프로그램을 작성해야 한다. 그래서 시간제한과 주어진 데이터 크기 제한에 따른 시간 복잡도를 어림잡아 예측해 보는 것은 중요하다.
예를 들어, 입력으로 주어지는 데이터에는 n만큼의 크기를 가지는 데이터가 있고, n이 1,000,000보다 작은 수일 때 O(n) 혹은 O(nlogn)의 시간 복잡도를 가지도록 예측하여 프로그램을 작성할 수 있다. 여기서 n²의 시간 복잡도는 예측할 수가 없기 때문. n²의 시간 복잡도를 예측할 수 없는 이유는 실제 수를 대입해 계산해보면 유추할 수 있다. 1,000,000²은 즉시 처리하기에 무리가 있는 숫자입니다. (1,000,000 * 1,000,000 = 1,000,000,000,000(조)) 그렇기 때문에 시간 복잡도를 줄이려고 노력해야 한다.
그러나 만약 n ≤ 500 으로 입력이 제한된 경우에는 O(n³)의 시간 복잡도를 가질 수 있다고 예측할 수 있다. 예측한 대로 O(n³)의 시간 복잡도를 가지는 프로그램을 작성해 문제를 금방 풀 수 있다면, 이때는 굳이 시간 복잡도를 O(log n)까지 줄이기 위해 끙끙댈 필요는 없다.
즉, 입력 데이터가 클 때는 O(n) 혹은 O(log n)의 시간 복잡도를 만족할 수 있도록 예측해서 문제를 풀어야 한다. 그러나 주어진 데이터가 작을 때는 시간 복잡도가 크더라도 문제를 풀어내는 것에 집중하자.
대략적인 데이터 크기에 따른 시간 복잡도는 다음과 같다.
| 데이터 크기 제한 | 예상되는시간 복잡도 |
|---|---|
| n ≤ 1,000,000 | O(n) or O (logn) |
| n ≤ 10,000 | O(n2) |
| n ≤ 500 | O(n3) |
위 표를 기준으로 문제마다 예상되는 시간 복잡도를 예측해 보자!
Chapter2-2. 공간 복잡도(Space Complexity)
공간 복잡도는 알고리즘이 수행되는 데에 필요한 메모리의 총량을 의미한다. 즉 프로그램이 필요로 하는 메모리 공간을 산출하는 것을 의미한다.
프로그램이 요구하는 공간은 고정적인 공간과 함께 가변적인 공간을 함께 요구한다. 여기서 집중해야 할 부분은 가변적인 공간이다. 왜냐하면 고정적인 공간은 처리할 데이터의 양에 무관하게 항상 요구되는 공간으로서, 프로그램의 성능에 큰 영향을 주지 않기 때문. 그러나 가변적인 공간은 처리할 데이터의 양에 따라 다르게 요구되는 공간으로서 프로그램의 성능에 큰 영향을 준다.
이런 공간 복잡도 계산은 시간 복잡도 계산과 비슷하게 빅 오 (Big-O) 표기법으로 표현한다. 아래의 가장 간단한 공간복잡도 예시를 보자.
공간 복잡도 예시
function factorial(n) {
if(n === 1) {
return n;
}
return n*factorial(n-1);
}함수 factorial은 재귀함수로 구현되었다. 변수 n에 따라 변수 n이 n개가 만들어지게 되며, factorial 함수를 재귀함수로 1까지 호출할 경우 n부터 1까지 스택에 쌓이게 된다. 따라서 해당 함수의 공간 복잡도는 O(n)이라 볼 수 있다.
공간 복잡도는 얼마나 중요한가?
*보통 때의 공간 복잡도는 시간 복잡도보다 중요성이 떨어진다. 왜냐하면 시간이 적으면서 메모리까지 지수적으로 증가하는 경우는 거의 없으며 시간 내에 발생하는 메모리 문제들은 보통 알고리즘을 구현할 때에 발생하는 문제이기 때문.
보통 시간 복잡도에 맞다면 공간 복잡도도 얼추 통과하기 때문에, 만약 알고리즘 구현 시 공간 복잡도에 실패했다면, 보통은 변수를 설정할 때 쓸데없는 공간을 많이 차지하도록 설정했을 경우가 많을 것이니 그것부터 확인해야 한다.
그러나 때에 따라 공간 복잡도를 중요하게 보는 경우가 있는데, 동적 계획법(Dynamic Programming)과 같은 알고리즘이나 하드웨어 환경이 매우 한정되어 있는 경우가 바로 그 경우이다.
*동적 계획법은 알고리즘 자체가 구현 시 메모리를 많이 요구하기 때문에 입력 값의 범위가 넓어지면 사용하지 못하는 경우도 많고, 하드웨어 환경이 매우 한정되어 있는 경우(ex. 임베디드, 펌웨어 등)라면 가용 메모리가 제한되어 있기 때문이다.
Chapter3. Algorithm의 유형
알고리즘 문제를 푼다는 것은, 내가 생각한 문제 해결 과정을 컴퓨팅 사고로 변환하여 코드로 구현한다는 것과 같다. 수많은 문제 해결 과정은 대부분 여러 개의 카테고리로 묶여진다.
코딩 테스트는 각 문제마다 문제에 원하는 의도 및 적용해야 하는 개념이 분명하게 있고, 그것을 해결하는 것이 목표이다. 이번에는 알고리즘에 어떤 유형이 있는지 학습해보자.
- greedy algorith이 무엇인지 학습하고, 문제 해결 단계를 이해합니다.
- greedy algorithm의 적용 예시와 문제의 단계적 구분에 대해 학습하고 이해합니다.
- greedy algorithm의 특징에 대해 학습하고 이해합니다.
- greedy algorithm을 이용한 예시를 보고, 동작 방식을 분석해봅니다.
- 알고리즘 구현에 대해 이해합니다.
- 완전 탐색의 개념과 규칙에 대해 이해하고, Brute Force 예시에 대해 이해합니다.
- 시뮬레이션의 개념과 예시에 대해 이해합니다.
- 알고리즘 구현을 위해 필요한 개념을 적용한 예시 코드를 보고 분석합니다.
- dynamic programming이 무엇인지 학습하고, 어떤 조건을 만족해야 하는지 이해합니다.
- dynamic programming의 최적의 해결 방법에 대해 학습하고 이해합니다.
- dynamic programming의 대표적인 문제를 소개한 것을 보고, 분석합니다.
Chapter3-1. Greedy Algorithm
Greedy는 "탐욕스러운, 욕심 많은" 이란 뜻이다. Greedy Algorithm(탐욕 알고리즘)은 말 그대로 선택의 순간마다 당장 눈앞에 보이는 최적의 상황만을 쫓아 최종적인 해답에 도달하는 방법이다.
탐욕 알고리즘으로 문제를 해결하는 방법은 다음과 같이 단계적으로 구분할 수 있다.
Greedy Algorithm 문제 해결 단계
- 선택 절차(Selection Procedure): 현재 상태에서의 최적의 해답을 선택한다.
- 적절성 검사(Feasibility Check): 선택된 해가 문제의 조건을 만족하는지 검사한다.
- 해답 검사(Solution Check): 원래의 문제가 해결되었는지 검사하고, 해결되지 않았다면 선택 절차로 돌아가 위의 과정을 반복한다.
Greedy Algorithm 적용 예시
예시1

김코딩은 오늘도 편의점에서 열심히 아르바이트하고 있다. 손님으로 온 박해커는 과자와 음료를 하나씩 집어 들었고, 물건 가격은 총 4,040원이 나왔다. 박해커는 계산을 하기 위해 5,000원을 내밀며, 거스름돈은 동전의 개수를 최소한으로 하여 거슬러 달라고 하였다.
이때 김코딩은 어떻게 거슬러 주어야 할까? 탐욕 알고리즘으로 동전의 개수를 헤아리는 일은, 우리가 일반적으로 거스름돈으로 동전을 선택하는 방법과 동일하다. 거스름돈 960원을 채우기 위해서 먼저, 500원짜리 동전을 한 개 선택한다. 그다음은 100원짜리 동전을 네 개 선택하고, 그다음엔 50원짜리 동전과 10원짜리 동전을 각각 하나씩 선택할 것이다. 김코딩의 입장에 탐욕 알고리즘의 문제 해결 과정을 적용하면 다음과 같이 문제를 단계적으로 구분할 수 있다.
- 선택 절차 : 거스름돈의 동전 개수를 줄이기 위해 현재 가장 가치가 높은 동전을 우선 선택한다.
- 적절성 검사 : 1번 과정을 통해 선택된 동전들의 합이 거슬러 줄 금액을 초과하는지 검사한다. 초과하면 가장 마지막에 선택한 동전을 삭제하고, 1번으로 돌아가 한 단계 작은 동전을 선택한다.
- 해답 검사 : 선택된 동전들의 합이 거슬러 줄 금액과 일치하는지 검사한다. 액수가 부족하면 1번 과정부터 다시 반복한다.
이 과정을 통해 얻은 문제에 대한 해답은 다음과 같다.
- 가장 가치가 높은 동전인 500원 1개를 먼저 거슬러 주고 잔액을 확인한 뒤, 이후 100원 4개, 50원 1개, 10원 1개의 순서대로 거슬러 준다.
한 가지 예시를 더 살펴보자
예시2
🥖$3 40g | 🍞$1.5 25g | 🥯$2.5 5g | 🥐 $2 20g
👜 LIMIT 35g
장발장이 빵 가게에서 빵을 훔치려고 한다. 장발장의 가방은 35g까지의 빵만 담을 수 있고, 빵은 가격이 전부 다르며, 4 개의 종류가 각 1 개씩 있다. 빵은 쪼개어 담을 수 있다. 장발장은 최대한 가격이 많이 나가는 빵으로만 채우고 싶다.
장발장이 탐욕 알고리즘을 사용한다면 문제는 다음과 같이 간단해진다.
1. 가방에 넣을 수 있는 물건 중 무게 대비 가장 비싼 물건을 넣는다.
2. 그다음으로 넣을 수 있는 물건 중 무게 대비 가장 비싼 물건을 넣는다.
3. 만약, 가방에 다 들어가지 않는다면 쪼개어 넣는다.
| 구분 | 1달러당 무게(반올림) |
|---|---|
| 🥖 | 13.3g |
| 🍞 | 16.7g |
| 🥯 | 2g |
| 🥐 | 10g |
달러당 부피가 가장 작은 빵(무게 대비 가장 비싼 물건)부터 담아야 한다.
- $1당 2g인 🥯 3번 빵(5g) 먼저 가방에 담을 수 있다: [남은 가방의 무게: 30g]
- $1당 10g인 🥐 4번 빵(20g)을 다음으로 담을 수 있다: [남은 가방의 무게: 10g]
- $1당 13.3g인 🥖1번 빵(40g)을 다음으로 담을 수 있다.
그러나, 40g을 온전히 못 채우기 때문에 쪼개어, 10g만 넣는다: [남은 가방의 무게: 0g]
= $2.5 + $2 + $0.75 ⇒ 장발장은 최대 $5.25어치의 빵을 훔칠 수 있다.
탐욕 알고리즘은 문제를 해결하는 과정에서 매 순간, 최적이라 생각되는 해답(locally optimal solution)을 찾으며, 이를 토대로 최종 문제의 해답(globally optimal solution)에 도달하는 문제 해결 방식이다.
하지만, 만약 “빵을 쪼갤 수 없는 상황”이라면 Greedy는 마시멜로 실험 결과처럼 최적의 결과를 보장할 수 없다.
무게 대비 가장 비싼 물건을 넣는다는 조건을 두고 현재에 최선을 다하게 되면 빈 자리 5g이 남게 되고 결과를 도출하게 되지만, 빈 자리 5g을 채워 더 큰 최대값을 만들 수 있는 최선의 상황이 있을 수도 있기 때문.
마시멜로 실험이란?
지금 마시멜로를 받겠다고 말하면 1개를 받을 수 있지만, 1분을 기다렸다가 받는다면 2개를 받을 수 있다.
greedy는 "현재"에 최선인 선택을 하기 때문에 마시멜로를 당장 받아내어 1개를 받게 되지만,
전체적으로 보게 되면 1분 뒤에 받는 2개가 최적의 선택이 된다.따라서, 다음 두 가지의 조건을 만족하는 "특정한 상황" 이 아니면 탐욕 알고리즘은 최적의 해를 보장하지 못한다. 탐욕 알고리즘을 적용하려면 해결하려는 문제가 다음의 2가지 조건을 성립하여야 한다.
탐욕 알고리즘의 특징
- 탐욕적 선택 속성(Greedy Choice Property) : 앞의 선택이 이후의 선택에 영향을 주지 않는다.
- 최적 부분 구조(Optimal Substructure) : 문제에 대한 최종 해결 방법은 부분 문제에 대한 최적 문제 해결 방법으로 구성된다.
탐욕 알고리즘은 항상 최적의 결과를 도출하는 것은 아니지만, 어느 정도 최적에 근사한 값을 빠르게 도출할 수 있는 장점이 있다. 이 장점으로 인해 탐욕 알고리즘은 근사 알고리즘으로 사용할 수 있다.
Chapter3-2. Algorithm 구현
알고리즘 문제를 푼다는 것은, 내가 생각한 문제 해결 과정을 컴퓨팅 사고로 변환하여 코드로 구현한다는 것과 같고, 각 유형은 원하는 의도가 분명하게 있고, 그것을 해결하는 것이 목표라고 했다.
- 데이터를 정렬할 수 있는가?
- 데이터를 효율적으로 탐색할 수 있는가?
- 데이터를 조합할 수 있는가? ...etc
이렇게 카테고리를 분류한다고 해도 내가 생각한 로직을 '코드로 구현'한다는 건 전부 공통적인 속성이다. 이러한 문제 해결을 코드로 풀어낼 때, 정확하고 빠를 수록 구현 능력이 좋다고 말한다. 구현 능력이 좋은 개발자를 선발할 의도로 구현 능력을 직접 평가하기도 한다. '정해진 시간 안에 빠르게 문제를 해결하는 능력'을 보기 위함이다. 머리로 이해하고 있어도 코드로 작성하지 않는다(혹은 시간 부족으로 못한다)면 정답이 될 수 없기 때문.
본인이 선택한 프로그래밍 언어의 문법을 정확히 알고 있어야 하며, 문제의 조건에 전부 부합하는 코드를 실수 없이 빠르게 작성하는 것을 목표로 두는 것을 구현 문제, 구현 유형이라고 통칭할 수 있다.
보통 이러한 문제들은 구현하는 것 자체를 굉장히 까다롭게 만듭니다. 지문을 매우 길게 작성하거나, 까다로운 조건이나 상황을 붙인다거나, 로직은 쉽지만 구현하려는 코드가 굉장히 길어지게 되는 문제들이 대다수입니다. 그렇기 때문에 깊은 집중력과 끈기가 필요합니다.
구현 능력을 보는 대표적인 사례에는 완전 탐색(brute force)과 시뮬레이션(simulation)이 있다. 완전 탐색이란 가능한 모든 경우의 수를 전부 확인하여 문제를 푸는 방식을 뜻하고, 시뮬레이션은 문제에서 요구하는 복잡한 구현 요구 사항을 하나도 빠트리지 않고 코드로 옮겨, 마치 시뮬레이션을 하는 것과 동일한 모습을 그리는 것을 뜻한다.
완전 탐색
모든 문제는 완전 탐색으로 풀 수 있다. 이 방법은 굉장히 단순하고 무식하지만 "답이 무조건 있다"는 강력함이 있다.
예를 들어, 양의 정수 1부터 100까지의 임의의 요소가 오름차순으로 하나씩 담긴 배열 중, 원하는 값 N을 찾기 위해서는 배열의 첫 요소부터 마지막 요소까지 전부 확인을 한다면 최대 100 번의 탐색 끝에 원하는 값을 찾을 수 있다.
그렇지만, 문제 해결을 할 때엔 기본적으로 두 가지 규칙이 붙는다.
- 첫번째, 문제를 해결할 수 있는가?
- 두번째, 효율적으로 동작하는가?
완전 탐색은 첫 번째 규칙을 만족시킬 수 있는 강력한 무기이지만, 두 번째 규칙은 만족할 수 없는 경우가 있다.
양의 정수 1부터 100까지의 임의의 요소가 오름차순으로 하나씩 담긴 배열 중, 원하는 값 N을 찾으시오.
단, 시간 복잡도가 O(N)보다 낮아야 합니다.
이러한 문제가 나왔을 때, 최악의 경우 100 번을 시도해야 하는 완전 탐색은 두 번째 규칙을 만족할 수 없다. 배열을 작은 수에서 큰 수, 혹은 그 반대로 정렬한 후 이분 탐색을 사용하는 방법 등 다른 알고리즘을 사용해야 한다.
그렇기 때문에, 완전 탐색은 문제를 풀 수 있는 가능한 모든 방법을 고려한 후 효율적으로 동작하는 알고리즘이 완전 탐색 밖에 없다고 판단될 때 적용할 수 있다.
완전 탐색은 단순히 모든 경우의 수를 탐색하는 모든 경우를 통칭한다. 완전히 탐색하는 방법에는 Brute Force(조건/반복을 사용하여 해결), 재귀, 순열, DFS/BFS 등 여러 가지가 있다. 그 중, Brute Force(무차별 대입)에 대해 예시를 보자.
Brute Force 예시
우리 집에는 세 명의 아이들이 있다. 아이들의 식성은 까다로워, 먹기 싫은 음식과 좋아하는 음식을 철저하게 구분한다. 먹기 싫은 음식이 식탁에 올라왔을 땐 음식 냄새가 난다며 그 주변의 음식까지 전부 먹지 않고, 좋아하는 음식이 올라왔을 땐 해당 음식을 먹어야 한다. 세 아이의 식성은 다음과 같다.
첫째: (싫어하는 음식 - 미역국, 카레) (좋아하는 음식 - 소고기, 된장국, 사과)
둘째: (싫어하는 음식 - 참치, 카레) (좋아하는 음식 - 미역국, 된장국, 바나나)
셋째: (싫어하는 음식 - 소고기) (좋아하는 음식 - 돼지고기, 된장국, 참치)
100 개의 반찬이 일렬로 랜덤하게 담긴 상이 차려지고, 한 명씩 전부 먹을 수 있다고 할 때, 가장 많이 먹게 되는 아이와 가장 적게 먹게 되는 아이는 누구일까? (단, 그 주변의 음식은 반찬의 앞, 뒤로 한정한다.)
이 문제는 단순히 100 개의 반찬을 첫째, 둘째, 셋째의 식성에 맞게 하나씩 대입하여 풀 수 있습니다.
for(let i = 0; i < 100; i++) {
if(첫째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(둘째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(셋째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
}
return 많이 먹은 아이;각각 몇 가지 음식을 얼마나 먹을 수 있는지 각각 계산한 후, 제일 많이 먹는 아이와 제일 적게 먹는 아이를 파악할 수 있다. 문제를 풀 때, 반복문이 아닌 배열을 전부 순회하는 메서드를 사용한다거나 간결한 코드를 위한 문법을 사용한다고 하더라도 배열을 전부 탐색하여 세 명의 값을 도출한다는 것엔 변함이 없다.
시뮬레이션
시뮬레이션은 모든 과정과 조건이 제시되어, 그 과정을 거친 결과가 무엇인지 확인하는 유형이다. 보통 문제에서 설명해 준 로직 그대로 코드로 작성하면 되어서 문제 해결을 떠올리는 것 자체는 쉬울 수 있으나 길고 자세하여 코드로 옮기는 작업이 까다로울 수 있다.
시뮬레이션 예시
무엇을 위한 조직인지는 모르겠지만, 비밀스러운 비밀 조직 '시크릿 에이전시'는 소통의 흔적을 남기지 않기 위해 3 일에 한 번씩 사라지는 메신저 앱을 사용했습니다. 그러나 내부 스파이의 대화 유출로 인해 대화를 할 때 조건을 여러 개 붙이기로 했습니다. 해당 조건은 이렇습니다.
- 캐릭터는 아이디, 닉네임, 소속이 영문으로 담긴 배열로 구분합니다.
- 소속은 'true', 'false', 'null' 중 하나입니다.
- 소속이 셋 중 하나가 아니라면 아이디, 닉네임, 소속, 대화 내용의 문자열을 전부 X로 바꿉니다.
- 아이디와 닉네임은, 길이를 2진수로 바꾼 뒤, 바뀐 숫자를 더합니다.
- 캐릭터와 대화 내용을 구분할 땐
공백:공백으로 구분합니다: ['Blue', 'Green', 'null'] : hello.- 띄어쓰기 포함, 대화 내용이 10 글자가 넘을 때, 내용에
.,-+이 있다면 삭제합니다.- 띄어쓰기 포함, 대화 내용이 10 글자가 넘지 않을 때, 내용에
.,-+@#$%^&*?!이 있다면 삭제합니다.- 띄어쓰기를 기준으로 문자열을 반전합니다: 'abc' -> 'cba'
- 띄어쓰기를 기준으로 소문자와 대문자를 반전합니다: 'Abc' -> 'aBC'
시크릿 에이전시의 바뀌기 전 대화를 받아, 해당 조건들을 전부 수렴하여 수정한 대화를 객체에 키와 값으로 담아 반환하세요. 같은 캐릭터가 두 번 말했다면, 공백을 한 칸 둔 채로 대화 내용에 추가되어야 합니다.
대화는 문자열로 제공되며, 하이픈- 으로 구분됩니다.
문자열은 전부 싱글 쿼터로 제공되며, 전체를 감싸는 문자열은 더블 쿼터로 제공됩니다.
예: "['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'"
문제는 대화 내용이 담긴 문자열을 입력받아, 문자열을 파싱하여 재구성을 하려고 한다.
예시를 이용하여 순차적으로 작성해보자.
"['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'"입력값으로 받은 문자열을 각 캐릭터와 대화에 맞게 문자열로 파싱을 하고, 파싱한 문자열을 상대로 캐릭터와 대화를 구분한다.- 첫 번째 파싱은
-을 기준으로['Blue', 'Green', 'null'] : 'hello. im G.',['Black', 'red', 'true']: '? what? who are you?'두 부분으로 나눈다. - 두 번째 파싱은
:을 기준으로\['Blue', 'Green', 'null'\]배열과'hello. im G.'문자열로 나눈다.
- 첫 번째 파싱은
-
배열과 문자열을 사용해, 조건에 맞게 변형한다.
- 소속이 셋 중 하나인지 판별한다.
['Blue', 'Green', 'null']아이디와 닉네임의 길이를 2진수로 바꾼 뒤, 숫자를 더한다:[1, 2, 'null']'hello. im G.'10 글자가 넘기 때문에,.,-+@#$%^&*를 삭제:'hello im G''hello im G'띄어쓰기를 기준으로 문자열을 반전:'olleh mi G''olleh mi G'소문자와 대문자를 반전:'OLLEH MI g'
-
변형한 배열과 문자열을 키와 값으로 받아 객체에 넣는다.
{ "[1, 2, 'null']": 'OLLEH MI g' }
이렇듯, 문제에 대한 이해를 바탕으로 제시하는 조건을 하나도 빠짐없이 처리해야 정답을 받을 수 있다. 하나라도 놓친다면 통과할 수 없게 되고, 길어진 코드 때문에 헷갈릴 수도 있으니 주의해야 한다.
Chapter3-3. Dynamic Programming
Dynamic Programming(DP, 동적 계획법)은 탐욕 알고리즘(Greedy)과 함께 언급하는 알고리즘으로, 줄임말로 DP 라고 하는 이 알고리즘은, 탐욕 알고리즘과 같이 작은 문제에서 출발한다는 점은 같다. 그러나, 탐욕 알고리즘이 매 순간 최적의 선택을 찾는 방식이라면, DP는 모든 경우의 수를 조합해 최적의 해법을 찾는다.
즉, 주어진 문제를 여러 개의 (작은) 하위 문제로 나누어 풀고, 하위 문제들의 해결 방법을 결합하여 최종 문제를 해결한다. 하위 문제를 계산한 뒤 그 해결책을 저장하고, 나중에 동일한 하위 문제를 만날 경우 저장된 해결책을 적용해 계산 횟수를 줄인다. 다시 말해, 하나의 문제는 단 한 번만 풀도록 하는 알고리즘이 바로 이 다이내믹 프로그래밍이다.
다이내믹 프로그래밍은 다음 두 가지 가정이 만족하는 조건에서 사용할 수 있다.
- Overlapping Sub-problems : 큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다.
- Optimal Substructure : 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 같다. 즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다.
Overlapping Sub-problems
큰 문제로부터 나누어진 작은 문제는 큰 문제를 해결할 때 여러 번 반복해서 사용될 수 있어야 한다.
이 가정의 대표적인 예시로 피보나치 수열을 들 수 있다.
피보나치 수열은 첫째와 둘째 항이 1이며, 그 뒤의 모든 항은 바로 앞 두 항의 합과 같은 수열이다.
function fib(n) {
if(n <= 2) {
return 1;
};
return fib(n - 1) + fib(n - 2);
}
// 1, 1, 2, 3, 5, 8...[코드] 재귀함수로 구현한 피보나치 수열
이 함수의 계산 과정을 그림으로 살펴보면, 다음과 같다.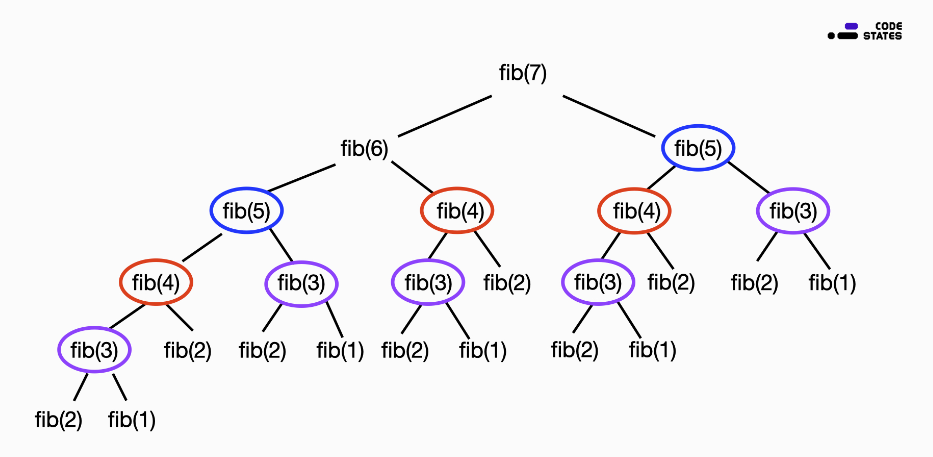
7번째 피보나치 수 fib(7) 를 구하는 과정은 다음과 같다.
fib(7) = fib(6) + fib(5)
fib(7) = (fib(5) + fib(4)) + fib(5) // fib(6) = fib(5) + fib(4)
fib(7) = ((fib(4) + fib(3)) + fib(4)) + (fib(4) + fib(3)) // fib(5) = fib(4) + fib(3)
...피보나치 수열은 위 예시처럼 동일한 계산을 반복적으로 수행해야 한다.
fib(5) 는 두 번, fib(4) 는 세 번, fib(3) 은 다섯 번의 동일한 계산을 반복한다.
이렇게, 작은 문제의 결과를 큰 문제를 해결하기 위해 여러 번 반복하여 사용할 수 있을 때, 부분 문제의 반복(Overlapping Sub-problems)이라는 조건을 만족한다.
그러나 이 조건을 만족하는지 확인하기 전에, 한 가지 주의해야 할 점이 있다. 주어진 문제를 단순히 반복 계산하여 해결하는 것이 아니라, 작은 문제의 결과가 큰 문제를 해결하는 데에 여러 번 사용될 수 있어야 한다.
Optimal Substructure
이 조건에서 말하는 정답은 최적의 해결 방법(Optimal solution)을 의미한다. 주어진 문제에 대한 최적의 해법을 구할 때, 주어진 문제의 작은 문제들의 최적의 해법(Optimal solution of Sub-problems)을 찾아야 한다. 그리고 작은 문제들의 최적의 해법을 결합하면, 결국 전체 문제의 최적의 해법(Optimal solution)을 구할 수 있다.
이 가정의 대표적인 예시로 최단 경로를 찾는 문제를 들 수 있다.
A에서 D로 가는 최단 경로를 찾아야 한다. 다음과 같이 각 지점이 있고, 한 지점에서 다른 지점으로 갈 수 있는 경로와 해당 경로의 거리는 다음과 같다.
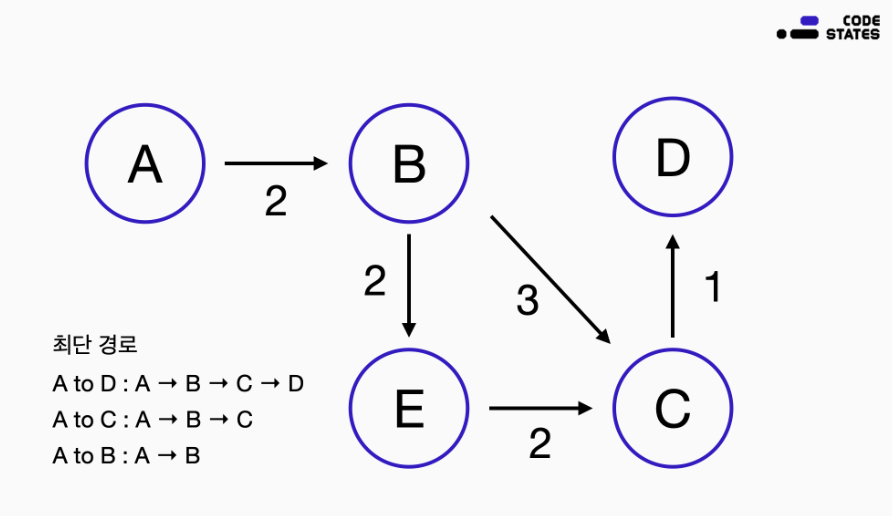 [그림] 방향성 그래프 예시
[그림] 방향성 그래프 예시
-
A → D로 가는 최단 경로 :
A → B → C → D -
A → C로 가는 최단 경로 :
A → B → C -
A → B로 가는 최단 경로 :
A → B
정리해보면 A에서 D로 가는 최단 경로는 그것의 작은 문제인 A에서 C로 가는 최단 경로, 그리고 한 번 더 작은 문제인 A에서 B로 가는 최단 경로로부터 파악할 수 있다. 이렇게 Dynamic Programming을 적용하기 위해서는, 작은 문제의 최적 해법을 결합하여 최종 문제의 최적 해법을 구할 수 있어야 한다.
Chapter3-4. Algorithm의 유형 예제
Greedy Algorithm - 거스름돈
타로는 자주 JOI 잡화접에서 물건을 산다. JOI 잡화점에는 잔돈으로 500엔, 100엔, 50엔, 10엔, 5엔, 1엔이 충분히 있고, 언제나 거스름돈 개수가 가장 적게 잔돈을 준다. 타로가 JOI 잡화점에서 물건을 사고 카운터에서 1000엔 지폐를 한 장 냈을 때, 받을 잔돈에 포함된 잔돈의 개수를 구하는 프로그램을 작성하시오.
JOI 잡화점에는 잔돈으로 500엔, 100엔, 50엔, 10엔, 5엔, 1엔이 충분히 있고, 언제나 거스름돈 개수가 가장 적게 잔돈을 준다고 되어 있다. 즉 언제나 거스름돈을 적게 주는 알고리즘을 짜야만 한다.
예제 1
입력 : 380 / 출력 : 4
예제 2
입력 : 1 / 출력 : 15
380엔을 타로가 지불을 해야 한다면 타로가 받아야 할 거스름돈은 620엔이다. 그렇다면 500엔 1개, 100엔 1개, 10엔 2개로 총 4개의 동전을 거슬러 받는 것이 가장 적게 잔돈을 거슬러 받는 방법일 것이다. 가장 적게 거슬러 받기 위한 로직을 작성해보자.
function keepTheChange(input) {
//1000엔짜리 지폐를 냈다는 가정이 있고, 입력 값으로는 지불해야 할 금액이 들어옵니다.
let change = Number(1000 - input);
//카운트하기 위해 변수 count에 0을 할당합니다.
let count = 0;
//입력 값에 배열이 들어오지 않으므로 직접 배열을 만들어줍니다.
const joiCoins = [500, 100, 50, 10, 5, 1];
//만든 배열의 개수만큼만 돌려줘야 합니다.
for(let i = 0; i < joiCoins.length; i++){
//거스름돈이 0원이 되면 for문을 멈춥니다.
if(change === 0) break;
//거스름돈과 잔돈을 나눈 몫을 카운팅합니다.(쓰인 잔돈의 개수 카운팅)
count += Math.floor(Number(change/joiCoins[i]));
//거스름돈을 잔돈으로 나눈 나머지를 재할당합니다.
change %= joiCoins[i];
}
//count를 리턴합니다.
return count;
}함수 keepTheChange는 항상 1000엔짜리 지폐를 냈다는 가정이 있고, 입력 값으로는 지불해야 할 금액이 들어오기 때문에 변수 change에 1000 - input을 하여 잔돈을 먼저 계산을 해준다.
JOI 잡화점은 항상 잔돈이 충분히 있고 거스름돈 개수가 가장 적게 잔돈을 주어야만 하기 때문에, 가장 금액이 큰 잔돈부터 계산을 시작한다. 그러기 위해서는 가장 금액이 큰 잔돈 순서대로 배열을 만들어 줄 필요성이 있으므로, joiCoins라는 배열을 만들어 큰 잔돈 순서대로 요소를 채워준다.
for문에서는 만든 배열의 요소 개수만큼만 반복문을 돌릴 것이고, if문에서는 잔돈이 0원이 되면 for문을 멈추도록 조건을 짠 뒤, 거스름돈이 큰 순서대로 나눠서 몫을 구하는 방식을 취한다.
count 변수에는 change와 joiCoins[i]를 나눈 몫을 카운트하여 넣어주고, change에는 거스름돈으로 나누어 나온 나머지를 재할당 해준다.
greedy Algorithm은 선택의 순간마다 당장 눈앞에 보이는 최적의 상황만을 쫓아 최종적인 해답에 도달하는 방법이라고 학습했다. 따라서 해당 로직은 “거스름돈을 가장 큰 잔돈부터 나눠서 0원으로 만든다" 라는 최적의 상황을 쫓게 되는 것이다.
Algorithm 구현 - Brute-Force Algorithm
컴퓨터 과학에서 Brute Force는 시행착오 방법론을 말한다. 그리고 암호학에서도 이 용어를 사용한다.
암호학에서는 Brute Force Attack이라고 불리며 특정한 암호를 풀기 위해서 모든 값을 대입하는 방법을 말한다. 수많은 시행착오를 통해 민감한 데이터를 해킹하는 방법이다. 무차별 대입 공격이 다른 해킹 방법과 다른 점은 지능형 전략을 사용하지 않는 점이다. 무차별 대입 공격은 올바른 조합을 찾을 때까지 다양한 조합을 시도한다.
예를 들어 0-9 사이의 4자리 숫자로 된 자물쇠가 있다고 가정해 보자. 이 자물쇠의 번호 조합은 잊어버렸지만 튼튼해서 다른 자물쇠로는 바꾸고 싶지 않다. 자물쇠를 사용하려면 비밀번호를 0000부터 9999까지의 경우의 수를 모두 하나하나 대입하여 자물쇠를 열어야 한다. 이때 최악의 경우 10000번의 시도가 필요하다. 이렇게 하나하나 대입하여 시도하는 방법이 Brute Force Attack이다.
Brute Force Algorithm
Brute Force Algorithm은 무차별 대입 방법을 나타내는 알고리즘이다. 순수한 컴퓨팅 성능에 의존하여 모든 가능성을 시도하여 문제를 해결하는 방법이다. Brute Force는 최적의 솔루션이 아니라는 것을 의미하기도 한다. 공간복잡도와 시간복잡도의 요소를 고려하지 않고 최악의 시나리오를 취하더라도 솔루션을 찾으려고 하는 방법을 의미한다.
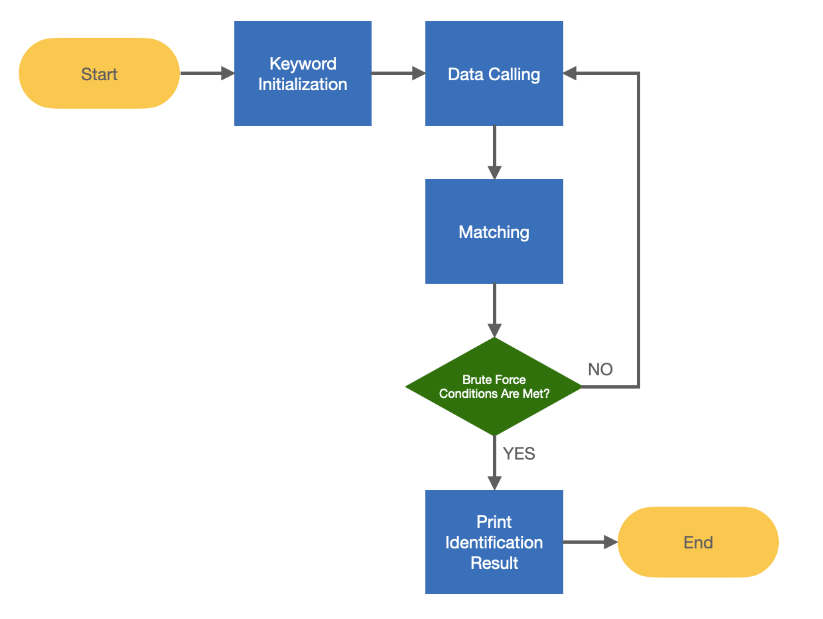 [그림] Brute Force Algorithm의 플로우 차트
[그림] Brute Force Algorithm의 플로우 차트
Brute Force Algorithm은 크게 두 가지 경우에 사용된다.
- 프로세스 속도를 높이는데
사용할 수 있는 다른 알고리즘이 없을 때 - 문제를 해결하는 여러 솔루션이 있고
각 솔루션을 확인해야 할 때
예를 들어 어떤 문서 중에서 ‘kimcoding’ 이란 문자열을 찾아야 한다고 가정해 보자.
이때, 사전과 같이 모든 단어가 정렬되어 있다면 이진 탐색 알고리즘을 이용하여 절반씩 범위를 줄일 수 있다. 모든 단어 n에 대해 시간복잡도는 O(logn)이 될 수도 있다. 하지만 문서는 사전처럼 정렬되어 있지 않은 경우, 목표 단어 ‘kimcoding’에 도달하려면 각 단어를 반복해서 비교해야 한다. 시간복잡도는 O(n)과 같다.
이처럼 Brute Force Algorithm은 문제에 더 적절한 해결 방법을 찾기 전에 시도하는 방법이다. 그러나 데이터의 범위가 커질수록 상당히 비효율적이다. 프로젝트의 규모가 커진다면 더 효율적인 알고리즘을 사용 해야 한다.
Brute Force Algorithm의 한계
Brute Force Algorithm은 문제의 복잡도에 매우 민감한 단점을 가지고 있다. 문제가 복잡해질수록 기하급수적으로 많은 자원을 필요로 하는 비효율적인 알고리즘이 될 수 있다. 여기서 자원은 시간이 될 수도 있고 컴퓨팅 자원이 될 수도 있다.
일반적으로 문제의 규모가 현재 자원으로 충분히 커버가 가능한 경우에 Brute Force Algorithm을 사용한다. 만약 이를 벗어난 경우는 정확도를 조금 희생하고 더 효율적인 알고리즘을 사용한다.
Brute Force Algorithm을 어디서 사용하고 있을까?
Brute Force Algorithm은 많은 곳에서 사용하고 있다. 지금까지 풀었던 문제를 돌아보면 Brute Force Algorithm을 사용해서 풀었던 문제들도 있을 것이다. 반복문을 통해서 범위를 줄이지 않고 하나하나 비교하는 것도 Brute Force Algorithm이다.
순차 검색 알고리즘 (Sequential Search)
배열 안에 특정 값이 존재하는지 검색할 때 인덱스 0부터 마지막 인덱스까지 차례대로 검색합니다.
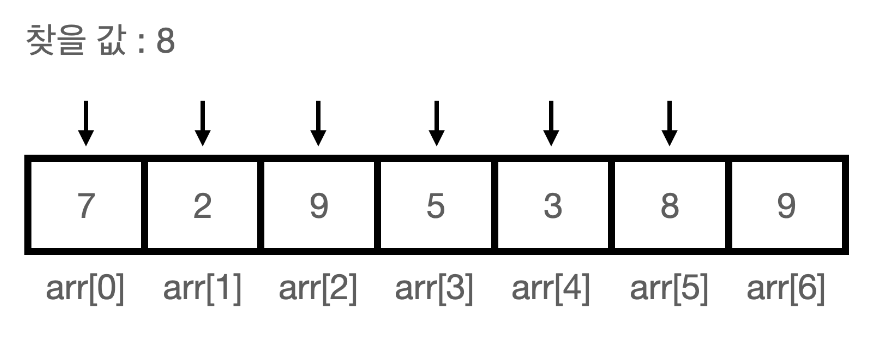
function SequentialSearch2(arr, k) {
// 검색 키 K를 사용하여 순차 검색을 구현
// 입력: n개의 요소를 갖는 배열 A와 검색 키 K
// 출력: K값과 같은 요소 인덱스 또는 요소가 없을 때 -1
let n = arr.length; // 현재의 배열 개수를 n에 할당합니다.
arr[n] = k; // 검색 키를 arr n인덱스에 할당합니다.
let i = 0; // while 반복문의 초기 값을 지정하고
while (arr[i] !== k) { // 배열의 값이 k와 같지 않을 때까지 반복합니다.
i = i + 1; // k와 같지않을 때 i를 +1 합니다.
}
if (i < n) { // i가 k를 할당하기전의 배열개수보다 적다면(배열안에 k값이 있다면)
return i; // i를 반환합니다.
} else {
return -1; // -1을 반환합니다.
}
}문자열 매칭 알고리즘 (Brute-Force String Matching) (이해못함)
길이가 n인 전체 문자열이, 길이가 m인 문자열 패턴을 포함하는지를 검색한다.
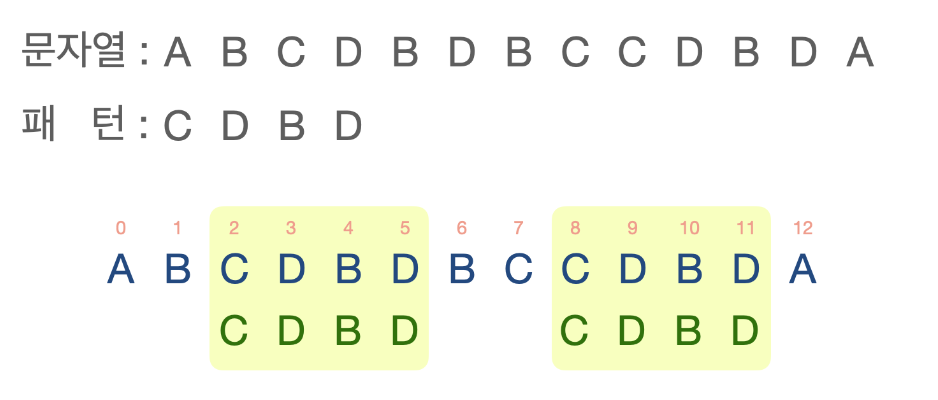
function BruteForceStringMatch(arr, patternArr) {
// Brute Force 문자열 매칭을 구현합니다.
// 입력: n개의 문자 텍스트를 나타내는 배열 T, m개의 문자 패턴을 나타내는 배열P
// 출력: 일치하는 문자열이 있으면 첫번째 인덱스를 반환합니다. 검색에 실패한 경우 -1을 반환합니다.
let n = arr.length;
let m = patternArr.length;
for (let i = 0; i < n - m; i++) {
// 전체 요소개수에서 패턴개수를 뺀 만큼만 반복합니다. 그 수가 마지막 비교요소이기 때문입니다.
// i 반복문은 패턴과 비교의 위치를 잡는 반복문입니다.
let j = 0;
// j는 전체와 패턴의 요소 하나하나를 비교하는 반복문입니다.
while (j < m && patternArr[j] === arr[i + j]) {
// j가 패턴의 개수보다 커지면 안되기때문에 개수만큼만 반복합니다.
// 패턴에서는 j인덱스와 전체에서는 i + j 인덱스의 값이 같은지 판단합니다.
// 같을때 j에 +1 합니다.
j = j + 1;
}
if (j === m) {
// j와 패턴 수가 같다는 것은 패턴의 문자열과 완전히 같은 부분이 존재한다는 의미입니다.
// 이 때의 비교했던 위치를 반환합니다.
return i;
}
}
return -1;
}선택 정렬 알고리즘 (Selection Sort)
전체 배열을 검색하여 현재 요소와 비교하고 컬렉션이 완전히 정렬될 때까지 현재 요소보다 더 작거나 큰 요소(오름차순 또는 내림차순에 따라)를 교환하는 정렬 알고리즘.
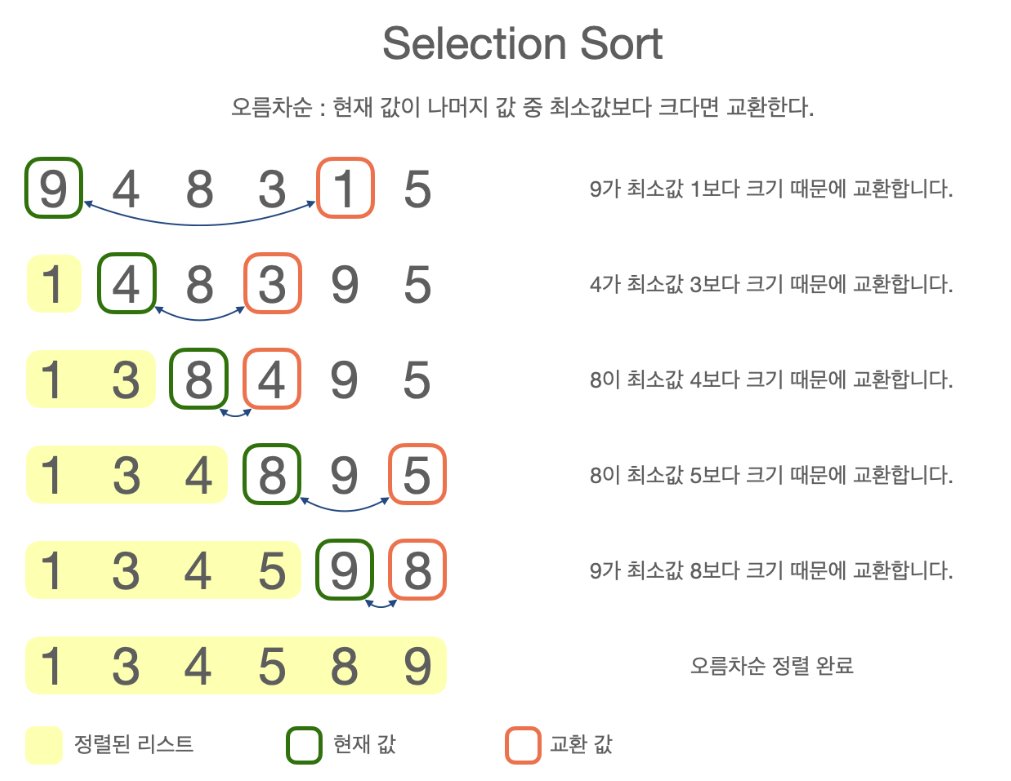
function SelectionSort(arr) {
// 주어진 배열을 Selection Sort로 오름차순 정렬합니다.
// 입력: 정렬 가능한 요소의 배열 A
// 출력: 오름차순으로 정렬된 배열
for (let i = 0; i < arr.length - 1; i++) {
// 배열의 0번째 인덱스부터 마지막인덱스까지 반복합니다.
// 현재 값 위치에 가장 작은 값을 넣을 것입니다.
let min = i;
// 현재 인덱스를 최소값의 인덱스를 나타내는 변수에 할당합니다.
for (let j = i + 1; j < arr.length; j++) {
// 현재 i에 +1을 j로 반복문을 초기화하고 i 이후의 배열요소과 비교하는 반복문을 구성합니다.
if (arr[j] < arr[min]) {
// j인덱스의 배열 값이 현재 인덱스의 배열 값보다 작다면
min = j;
// j 인덱스를 최소를 나타내는 인덱스로 할당합니다.
}
}
// 반복문이 끝났을 때(모든 비교가 끝났을때)
// min에는 최소값의 인덱스가 들어있습니다.
// i값과 최소값을 바꿔서 할당합니다.
let temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
// 모든 반복문이 끝나면 정렬된 배열을 반환합니다.
return arr;
}그 밖의 Brute Force 활용 알고리즘
- 버블 정렬 알고리즘 - Bubble Sort
- Tree 자료 구조의 완전탐색 알고리즘 - Exhausive Search (BFS, DFS)
- 동적 프로그래밍 - DP(Dynamic Programing)
더 공부하면 좋은 키워드
- Brute Force vs Dynamic Programing
- Closet-Pair Problems by Brute Force
- Convex-Hull Problems by Brute Force
Dynamic Programming - 피보나치 수열과 타일링
Fibonacci
DP를 이용하여 피보나치 수열 문제를 해결하려고 할 때, 크게 두 가지 방식 Recursion + Memoization 과 Iteration + Tabulation 이 있다.
Recursion + Memoization
다이내믹 프로그래밍은 하위 문제의 해결책을 저장한 뒤, 동일한 하위 문제가 나왔을 경우 저장해놓은 해결책을 이용한다. 이때 결과를 저장하는 방법을 Memoization이라고 한다.
Memoization의 정의: 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술
function fibMemo(n, memo = []) {
// 이미 해결한 하위 문제인지 찾아본다
if(memo[n] !== undefined) {
return memo[n];
}
if(n <= 2) {
return 1;
}
// 없다면 재귀로 결괏값을 도출하여 res 에 할당
let res = fibMemo(n-1, memo) + fibMemo(n-2, memo);
// 추후 동일한 문제를 만났을 때 사용하기 위해 리턴 전에 memo 에 저장
memo[n] = res;
return res;
}[코드] 다이내믹 프로그래밍을 적용한 피보나치 수열
fibMemo함수의 파라미터로n과 빈 배열memo를 전달한다.- 이 빈 배열은 하위 문제의 결괏값을 저장하는 데에 사용한다.
memo의n번째 인덱스가undefined이 아니라면 : 다시 말해 n 번째 인덱스에 해당하는 피보나치 값이 저장되어 있다면, 저장되어 있는 값을 그대로 사용한다.undefined라면 : 즉, 처음 계산하는 수라면fibMemo(n-1, memo) + fibMemo(n-2, memo)를 이용하여 값을 계산하고, 그 결괏값을 res 라는 변수에 할한다.- 마지막으로
res를 리턴하기 전에memo의 n 번째 인덱스에res값을 저장합니다.- 이렇게 하면 (n+1)번째의 값을 구하고 싶을 때, n번째 값을
memo에서 확인해 사용할 수 있다.
- 이렇게 하면 (n+1)번째의 값을 구하고 싶을 때, n번째 값을
위의 과정을 이미지로 표현하면 다음과 같다.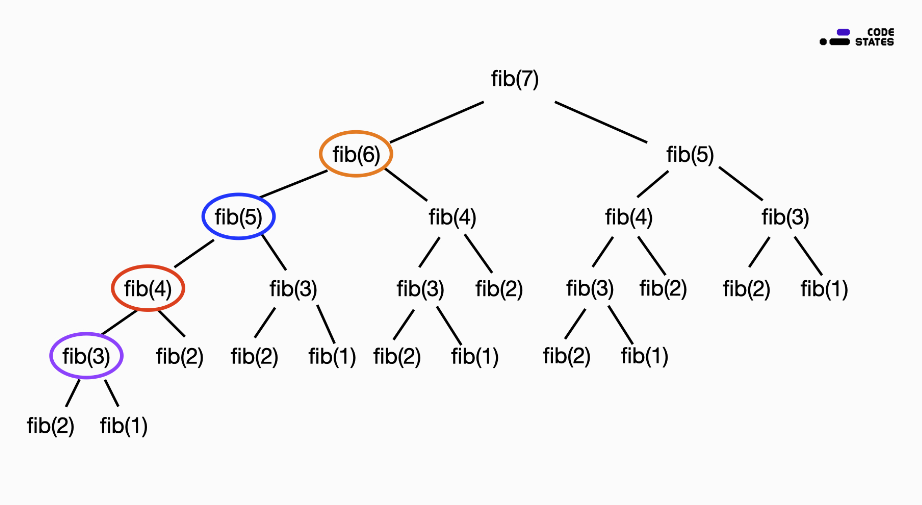
[그림] Memoization을 적용한 피보나치 수열 모식도
fib(7) 을 구하기 위해서는 이전의 작업으로 저장해 놓은 하위 문제의 결괏값을 사용한다. n이 커질수록 계산해야 할 과정은 선형으로 늘어나기 때문에 시간 복잡도는 O(N) 이 된다.
Memorization을 사용하지 않고 재귀 함수로만 문제를 풀 경우, n이 커질수록 계산해야 할 과정이 두 배씩 늘어나 시간 복잡도가 O(2^N)에 되는 것과 비교하였을 때, 다이내믹 프로그래밍의 강점을 확인할 수 있다.
다이내믹 프로그래밍을 적용한 피보나치 수열에서 fib(7)을 구하기 위해 fib(6)을, fib(6)을 구하기 위해 fib(5)을 호출한다. 이런 풀이 과정이 마치, 위에서 아래로 내려가는 것과 같다. 큰 문제를 해결하기 위해 작은 문제를 호출한다고 하여, 이 방식을 Top-down 방식이라 부르기도 한다.
Iteration + Tabulation
이번에는 반복문을 이용하여 다이내믹 프로그래밍을 구현해보자.
Tabulation의 정의: 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 제일 작은 값부터 구해 리스트(도표)에 작성함으로써 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술
하위 문제의 결괏값을 배열에 저장하고, 필요할 때 조회하여 사용하는 것은 재귀 함수를 이용한 방법과 같다. 그러나 재귀 함수를 이용한 방법이 문제를 해결하기 위해 큰 문제부터 시작하여 작은 문제로 옮아가며 문제를 해결하였다면, 반복문을 이용한 방법은, 작은 문제에서부터 시작하여 큰 문제를 해결해 나가는 방법이다. 따라서 이 방식을 Bottom-up 방식이라 부르기도 한다.
function fibTab(n) {
if(n <= 2) {
return 1;
}
// n 이 1 & 2일 때의 값을 미리 배열에 저장해 놓는다
let fibNum = [0, 1, 1];
for(let i = 3; i <= n; i++) {
fibNum[i] = fibNum[i-1] + fibNum[i-2];
// n >= 3 부터는 앞서 배열에 저장해 놓은 값들을 이용하여
// n번째 피보나치 수를 구한 뒤 배열에 저장 후 리턴한다
}
return fibNum[n];
}[코드] 반복문과 다이내믹 프로그래밍으로 구현한 피보나치 수열
fibTab함수의 파라미터는n하나뿐이다. 만약,n이 2와 같거나, 그 이하라면 1을 반환.- 피보나치 수열의 첫 번째와 두 번째는 1, 1이라는 것을 기억해야한다.
fibNum이라는 변수에n이 1 & 2일 때의 값을 배열을 사용해 저장해 놓는다.- 피보나치 수열은 1부터 시작하지만 인덱스는 0부터 시작하기 때문에 0 번째 인덱스를 채워 줄 dummy data로 0을 삽입한다.
- 2의 다음인
3부터 n까지피보나치 수를 구하고,fibNum배열에 저장한다. fibNum의 n 번째 인덱스 값을 반환한다.
피보나치 수열을 총 세 가지 방법(재귀, 탑다운, 바텀업)으로 구현했다.. 이렇게 구현한 3가지 방법이 시간 복잡도를 얼마나 효과적으로 개선하였는지 눈으로 직접 확인해야 한다.
연습문제 - Algorithm의 유형
Chapter4. Algorithm with Math
알고리즘 문제를 풀 때 가장 먼저 해야 할 것은 무엇일까? 문제를 이해하고 어떻게 풀 것인지 전략을 세우는 것이다. 문제 풀이를 위해 전략을 세우지 않는다면, 어떤 자료구조를 사용할지, 어떤 알고리즘 기법을 사용할지 판단할 수 없다.
최근 코딩 테스트에 등장하는 알고리즘 문제는 단순히 "너 이 알고리즘 알아?"라고 물어보지 않는다. 요즘 출제되는 문제는 "특정 방법을 사용해서 풀어 볼래?"라고 물어보는 문제가 자주 등장한다. 이때 "특정 방법을 사용해서 풀어 볼래?"라는 질문은 수학적 사고 능력, 다시 말해 "컴퓨팅 사고를 할 수 있어?"라고 물어보는 것과 같다. 따라서, 수학적 사고를 통해 컴퓨팅 사고를 할 수 있어야 한다.
다양한 수학적 개념이 있지만, 알고리즘 문제와 코딩 테스트에 자주 등장하고 필요한 주요 개념들만 학습해보자. 크게 3가지 개념 GCD/LCM(최대공약수, 최소공배수), 순열/조합, 멱집합을 간단히 공부하고, 문제를 풀면서 활용해보자. 이를 통해 어떤 문제에서 어떤 수학적 개념이 필요한지 파악하는 연습을 하자.
우리는 수학이라는 학문을 공부하는 것이 아니라, 문제가 어떤 수학적 개념을 요구하는지 파악해야 한다. 따라서 당장 코드를 작성하지 않고, 여러 가지 상황을 먼저 접해 보자. 그리고 나서 각 수학 개념에 관련된 문제를 코드로 구현.
- 조합의 개념과 공식을 이해합니다.
- 순열의 개념과 공식을 이해합니다.
- 순열과 조합의 개념이 적용된 문제의 로직을 이해합니다.
- GCD와 LCM가 무엇인지 학습하고, 해당 개념을 구현한 식에 대해 -이해합니다.
- GCD와 관련이 있는 유클리드 호제법에 대해 학습하고, 해당 개념을 구현한 식에 대해 이해합니다.
- 유클리드 호제법을 이용한 GCD와 LCM을 구하는 방식에 대해 학습하고 로직을 이해합니다.
- GCD와 LCM의 개념이 적용된 예제를 학습하고, 해당 로직에 대해 이해합니다.
- 멱집합의 개념과 단계를 나누는 기준에 대해 이해합니다.
- 멱집합을 찾는 과정에 대한 모식도를 이해합니다.
- 멱집합의 개념이 적용된 예제의 로직을 이해합니다.
Chapter4-1. 순열과 조합
순열
순열(順列, permutation)은 서로 다른 n개의 원소를 가지는 어떤 집합에서 중복 없이 순서에 상관있게 r개의 원소를 선택하거나 혹은 나열하는 것이며, 이는 조합과 마찬가지로 n개의 원소로 이루어진 집합에서 r개의 원소로 이루어진 부분집합을 만드는 것과 같다.

여기 사과와 오렌지, 레몬 총 3개의 원소로 이루어진 집합이 있다. 만약에 이 3가지의 과일 중 2가지의 과일을 중복 없이, 이번에는 순서에 상관있게 부분집합을 만든다면 총 몇 개의 부분집합이 나올 수 있을까?
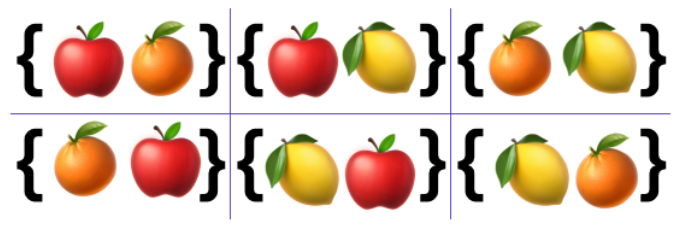
[그림] 3가지의 과일 중 2가지의 과일을 선택해 만든 순열
총 6개의 부분집합이 나올 수 있을 것이다. 왜냐하면 순열은 조합과 달리 순서도 따져서 부분집합을 만들기 때문이다. 즉 사과가 뒤로 가는 경우와 사과가 앞으로 가는 경우를 다르게 보고 각기 하나의 경우의 수로 치는 것이다. 그래서 {사과 오렌지} {오렌지 사과}가 다른 집합으로 취급될 수 있는 것이다.
순열의 식은 이렇게 표현된다.
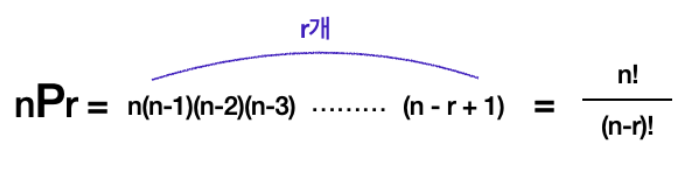
순열은 일반화 과정을 거쳐, Permutation의 약자 P로 표현한다. 여기서도 n은 원소의 총 개수를 의미하고, r은 그중 뽑는 개수를 의미한다. 여기서 중요한 것은, 앞서 설명했듯이 순열 또한 중복을 허용하지 않기 때문에 반드시 R <= N을 만족해야 한다는 것. 한 번 3P2의 값을 식을 통해 확인해보자.
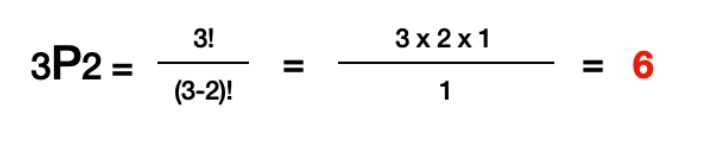
이렇게 식을 통해 확인해 보았을 때도 6개의 부분조합이 도출이 됨을 알 수 있다. 이어서 살펴볼 조합의 식은 순열의 개념이 이용이 된다.
조합
조합(組合, combination)은 서로 다른 n개의 원소를 가지는 어떤 집합에서 중복 없이 순서에 상관없게 r개의 원소를 선택하는 것이며, 이는 n개의 원소로 이루어진 집합에서 r개의 원소로 이루어진 부분집합을 만드는 것과 같다.

만약에 이 3가지의 과일 중 2가지의 과일을 중복 없이, 순서에 상관없는 부분집합을 만든다면 총 몇 개의 부분집합이 나올 수 있을까?

총 3개의 부분집합이 나올 수 있을 것입니다. 왜냐하면 조합은 순서에 상관없이 원소를 선택해 부분집합을 만드는 것이기 때문이다. 즉 사과가 뒤로 가든, 앞으로 가든 상관 없이 그저 사과 1개와 오렌지 1개가 있으면 하나의 경우의 수로 치는 것이다.
조합의 식은 이렇게 표현한다.

조합은 일반화 과정을 거쳐, Combination의 약자 C로 표현한다. 여기서 n은 원소의 총 개수를 의미하고, r은 그중 뽑는 개수를 의미한다. 여기서 중요한 것은, 앞서 설명했듯이 조합은 중복을 허용하지 않기 때문에 반드시 R ≤ N을 만족해야 한다는 것이다.
예를들어 3C5는 과일이 3개가 있는데 3개 중에서 4개, 5개를 뽑으라는 것인데 이는, 없는 것들을 뽑으라는 말과 똑같기 때문에 R은 최대 N개까지만 뽑을 수 있다.
한 번 3C2의 값을 식을 통해 확인해보자.
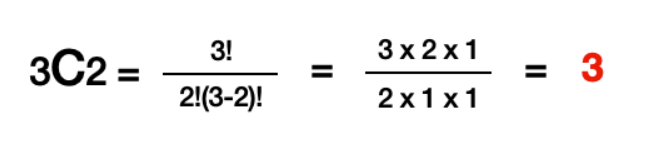
이렇게 식을 통해 확인해 보았을 때도 3개의 부분조합이 도출이 됨을 알 수 있다.
Chapter4-2. GCD와 LCM
GCD
최대공약수(Greatest Common Divisor, GCD)는 두 수 이상의 여러 공약수 중 최대인 수를 가리킨다.
공약수(Common Divisor)
최대공약수의 개념 중 공약수는 두 수 이상의 여러 수 중 공통된 약수를 의미한다. 여기서 약수(Divisor)는 어떤 수를 나누어떨어지게 하는 수를 말한다.
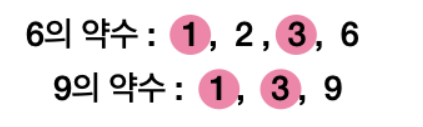
1, 3이 공약수
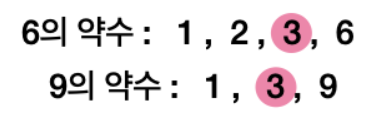
여러 개의 공약수 중 최대인 수가 바로 최대공약수이므로, 6과 9의 최대공약수는 3이다.
LCM
최소공배수(Lowest Common Multiple, LCM)은 두 수 이상의 여러 공배수 중 최소인 수를 가리킨다.
공배수(Common Multiple)
공배수는 두 수 이상의 여러 수 중 공통된 배수를 의미한다. 여기서 배수(Multiple)는 하나의 수에 정수를 곱한 수이다. 반대로 말해서, 배수는 그 수에 의해 나누어 떨어지는 수라고 볼 수 있다.

여기 12와 18 두 수가 있다. 두 수의 공배수는 이런 식으로 해당 수의 배수를 나열해 겹쳐지는 수를 찾는 방식으로 구할 수 있을 것이다. 공배수의 경우 배수이기 때문에 무수히 많으므로 가장 큰 공배수는 구할 수 없다. 그러므로 최소공배수를 찾아야 하는데, 여기서 최소 공배수는 36임을 알 수 있다.
GCD와 LCM을 구하는 방식
유클리드 호제법
GCD와 LCM 개념이 쓰이는 문제를 풀 때 가장 많이 쓰이는 방법
유클리드 호제법을 알고 있게 되면 최대공약수와 최소공배수를 구하는 모든 문제에 일단 적용해보고 시작할 수 있게 된다. 유클리드 호제법은 최대공약수와 관련이 깊은 공식이다.
2개의 자연수 a와 b가 있을 때, a를 b로 나눈 나머지를 r이라 하면 a와 b의 최대공약수는 b와 r의 최대공약수와 같다는 이론이다.
이러한 성질에 따라 b를 r로 나눈 나머지 r’를 구하고, 다시 r을 r’로 나누는 과정을 반복해, 나머지가 0이 되었을 때 나누는 수가 a와 b의 최대공약수임을 알 수 있게 된다.

해당 수식을 보며 다시 이해해보자. 여기 2개의 자연수 a와 b가 있다. 단 a가 b보다 커야 한다는 조건(절대적 조건)이 있다. 왜냐하면 나누었을 때 음수가 나오면 안 되기 때문.
이제 a와 b를 나누었을 때 q와 r이 나온다. q는 몫(Quotient)을 의미하고, r은 나머지(Rest)를 의미한다.
여기서 다시 b를 r로 나눈다. 그러면 다시 몫인 q와 나머지인 r’가 나올 것이다.
r을 다시 r’와 나누게 되면 언젠가 몫인 q와 나머지인 r이 0이 되는 상황이 도출이 된다.
나머지가 0일때, 이 때의 나누는 수인 r’가 바로 최대공약수라는 의미이다.
이번에는 실제 자연수를 이용해 확인해보자.
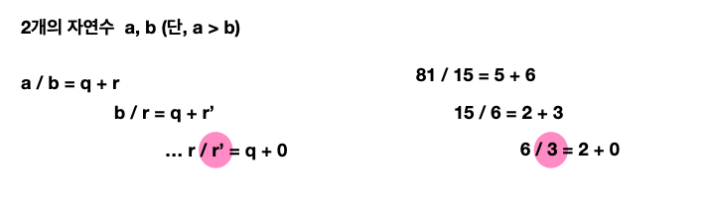
여기 81과 15가 있다. 같은 방식으로 쭉 나눴을 때, 마지막 나눗셈에서 나누는 수인 3이 최대공약수임을 확인할 수 있다.
이런 식으로 유클리드 호제법을 이용하게 되면 최대공약수를 쉽게 구할 수 있게 되고, 최대공약수를 구할 수 있게 되면 최소공배수는 자연스럽게 구할 수 있게 된다.
Chapter4-3. 멱집합
집합 {1, 2, 3}의 모든 부분집합은 {}, {1}, {2}, {3}, {1, 2}, {1, 3}, {2, 3}, {1, 2, 3} 으로 나열할 수 있고, 이 부분집합의 총 개수는 8개이다. 그리고 이 모든 부분집합을 통틀어 멱집합이라고 한다.
즉, 이렇게 어떤 집합이 있을 때, 이 집합의 모든 부분집합을 멱집합 이라고 한다. 모든 부분집합을 나열하는 방법은 다음과 같이 몇 단계로 구분할 수 있다. 부분집합을 나열하는 방법에서 가장 앞 원소(혹은 임의의 집합 원소)가 있는지, 없는지에 따라 단계를 나누는 기준을 결정한다.
*stepA까지만 이해함
원소가 있는지, 없는지 2가지 경우를 고려하기 때문에 집합의 요소가 n 개일 때 모든 부분집합의 개수는 2^n개 이다. 예를 들어 집합의 원소가 4개라면 모든 부분집합의 개수는 2^4, 집합의 원소가 5개라면 2^5가 된다.
간단히 {1, 2, 3}의 모든 부분집합을 구하는 단계는 다소 복잡해 보일 수 있다. 그러나 이 단계를 자세히 보면, 이 순서는, 트리구조와 비슷한 형태라는 사실을 떠올릴 수 있다.
이 순서는, 트리구조와 비슷한 형태라는 사실을 떠올릴 수 있다.
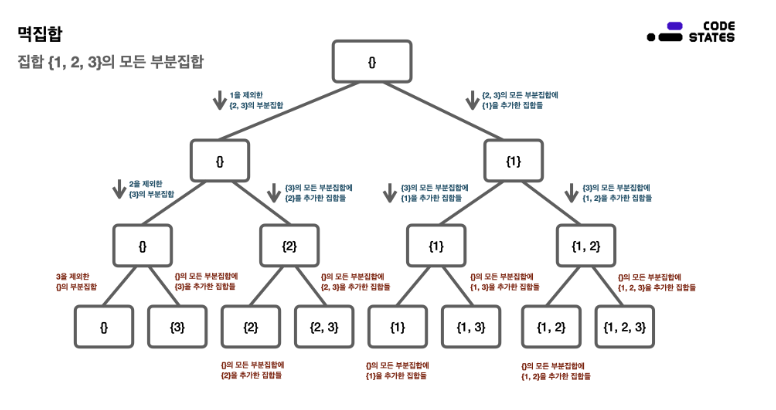
[그림] 멱집합을 찾는 과정 모식도
단, 멱집합 문제는 트리 문제는 아님.
멱집합을 구하는 방법에서 각 단계를 유심히 살펴보면, 순환 구조를 띠는 것을 확인할 수 있다. 여기서 순환구조는 임의의 원소를 제외하면서 집합을 작은 단위로 줄여나가는 방법이다. 따라서, 문제를 작은 단위로 줄여나가는 재귀를 응용할 수 있다.
예를 들어 PowerSet 이라는 멱집합의 개수를 리턴하는 함수를 작성한다면, PowerSet 함수에서 자기 자신을 호출하며 문제를 더 작은 문제로 문제의 크기를 줄여 해결할 수 있다. 문제가 가장 작은 단위로 줄어들고, 함수가 리턴될 때 카운트를 올리는 방식으로 멱집합의 개수를 구할 수 있다.
Chapter4-4. Algorithm with Math 예제
순열과 조합 - 순열과 조합을 이용한 문제들
순열: 요소 n개 중에 m개를 선택하여 순서에 상관 있게 뽑는 경우의 수.
조합 : 순서에 상관없이 요소 n개 중에 m개를 뽑는 경우의 수.
! (factorial, 팩토리얼): n! 은 n에서부터 1씩 감소하여 1까지의 모든 정수의 곱. (n 보다 작거나 같은 모든 양의 정수의 곱입니다.) 팩토리얼에서, 0!과 1!은 모두 1.
문제1: 카드 뽑기
[A, B, C, D, E]로 이뤄진 5장의 카드가 있다. 이 5장의 카드 중 3장을 선택하여 나열하려고 한다. 이때, 다음의 조건을 각각 만족하는 경우를 찾아야 한다.
1. 순서를 생각하며 3장을 선택합니다.
2. 순서를 생각하지 않고 3장을 선택합니다.
각 조건을 만족시키며 카드를 나열하는 방법은 각각 몇 가지일까?
case 1. 순서를 생각하며 3장을 선택할 때의 모든 경우의 수(순열)
모든 카드를 1장씩 나열하면서, 나열된 카드가 3장에 도달하면 카드의 나열을 중지한다.
해당 조건을 만족하려면, 다음과 같은 방법으로 경우의 수를 구한다.
- 첫번째 나열하는 카드를 선택하는 방법에는 다섯 가지가 있다.
- 첫번째 카드를 나열하고 난 다음, 두번째 카드를 선택하는 방법에는 네 가지가 있다.
- 두번째 카드를 나열하고 난 다음, 세번째 카드를 선택하는 방법에는 세 가지가 있다.
따라서5 X 4 X 3 = 60가지의 방법이 있다.
이렇게 n 개 중에서 일부만을 선택하여 나열하는 것을 순열이라고 한다. 순열은 순서를 지키며 나열해야 한다.
예를 들어 카드를 3장 뽑을 때, [A, B, D]와 [A, D, B] 두 경우 모두 A, B, 그리고 D라는 같은 카드를 3장 선택했지만, 나열하는 순서가 다르므로 서로 다른 경우로 파악해야 한다.
- 5장에서 3장을 선택하는 모든 순열의 수 = 5P3 =
(5 X 4 X 3 X 2 X 1) / (2 X 1)=60
일반식 : nPr =n! / (n - r)!
순열의 모든 경우의 수를 나열하고 싶다면 어떻게 해야 할까?
// 반복문 코드
function permutationLoop() {
// 순열 요소가 인자로 주어질 경우, 인자 그대로 사용하면 되지만, 인자가 주어지지 않고
// 문제 안에 포함되어 있을 경우 이런 식으로 직접 적어서 사용합니다.
let lookup = ['A', 'B', 'C', 'D', 'E'];
let result = [];
for (let i = 0; i < lookup.length; i++) {
for (let j = 0; j < lookup.length; j++) {
for (let k = 0; k < lookup.length; k++) {
if(i === j || j === k || k === i) continue;
result.push([[lookup[i], lookup[j], lookup[k]]])
}
}
}
return result;
}
permutationLoop();result 배열 안에 순열의 경우의 수를 삽입한 뒤, 반환하는 함수이다.
반복문 3개로 구성된 이 순열 코드는
반복문의 개수===요소를 뽑는 개수- 5개의 요소 중 3개를 뽑는 조건 : 하나의 반복문당 5 개의 요소(
lookup.length)를 순회하고, 반복문을 3번 중첩하여 3개의 요소를 뽑는다. 조금 더 풀어서 쓰자면 이러한 식이 됩니다:
- 5개의 요소 중 3개를 뽑는 조건 : 하나의 반복문당 5 개의 요소(
// 반복문 1개당 1개의 요소를 뽑습니다.
for (let i = 0; i < lookup.length; i++) {
let pick1 = lookup[i];
for (let j = 0; j < lookup.length; j++) {
let pick2 = lookup[j];
for (let k = 0; k < lookup.length; k++) {
let pick3 = lookup[k];
if(i === j || j === k || k === i) continue;
result.push([pick1, pick2, pick3])
}
}
}- 중복된 요소는 제거
- 같은 인덱스를 선택하는 것은, 중복된 요소를 선택한다는 것과 같다. 하지만 순열은 중복된 요소를 허용하지 않기 때문에, result에 넣기 전에, 동일한 인덱스인지 검사하고, 동일하다면 삽입하지 않고 다음으로 넘어간다.
- AAA부터 EEE까지 전부 만드는 코드이지만, 마지막에 중복 요소를 제거함으로써 순열이 완성된다.
결과
/*
[
[ 'A', 'B', 'C' ], [ 'A', 'B', 'D' ], [ 'A', 'B', 'E' ],
[ 'A', 'C', 'B' ], [ 'A', 'C', 'D' ], [ 'A', 'C', 'E' ],
[ 'A', 'D', 'B' ], [ 'A', 'D', 'C' ], [ 'A', 'D', 'E' ],
[ 'A', 'E', 'B' ], [ 'A', 'E', 'C' ], [ 'A', 'E', 'D' ],
[ 'B', 'A', 'C' ], [ 'B', 'A', 'D' ], [ 'B', 'A', 'E' ],
[ 'B', 'C', 'A' ], [ 'B', 'C', 'D' ], [ 'B', 'C', 'E' ],
[ 'B', 'D', 'A' ], [ 'B', 'D', 'C' ], [ 'B', 'D', 'E' ],
[ 'B', 'E', 'A' ], [ 'B', 'E', 'C' ], [ 'B', 'E', 'D' ],
[ 'C', 'A', 'B' ], [ 'C', 'A', 'D' ], [ 'C', 'A', 'E' ],
[ 'C', 'B', 'A' ], [ 'C', 'B', 'D' ], [ 'C', 'B', 'E' ],
[ 'C', 'D', 'A' ], [ 'C', 'D', 'B' ], [ 'C', 'D', 'E' ],
[ 'C', 'E', 'A' ], [ 'C', 'E', 'B' ], [ 'C', 'E', 'D' ],
[ 'D', 'A', 'B' ], [ 'D', 'A', 'C' ], [ 'D', 'A', 'E' ],
[ 'D', 'B', 'A' ], [ 'D', 'B', 'C' ], [ 'D', 'B', 'E' ],
[ 'D', 'C', 'A' ], [ 'D', 'C', 'B' ], [ 'D', 'C', 'E' ],
[ 'D', 'E', 'A' ], [ 'D', 'E', 'B' ], [ 'D', 'E', 'C' ],
[ 'E', 'A', 'B' ], [ 'E', 'A', 'C' ], [ 'E', 'A', 'D' ],
[ 'E', 'B', 'A' ], [ 'E', 'B', 'C' ], [ 'E', 'B', 'D' ],
[ 'E', 'C', 'A' ], [ 'E', 'C', 'B' ], [ 'E', 'C', 'D' ],
[ 'E', 'D', 'A' ], [ 'E', 'D', 'B' ], [ 'E', 'D', 'C' ]
]
*/case 2. 순서를 생각하지 않고 3장을 선택할 때의 모든 경우의 수(조합)
3장을 하나의 그룹으로 선택해야 한다.
다음과 같은 방법으로 경우의 수를 구한다.
- 순열로 구할 수 있는 경우를 찾는다.
- 순열로 구할 수 있는 경우에서 중복된 경우의 수를 나눈다.
먼저, 조합은 순열과 달리 순서를 고려하지 않습니다.
예를 들어 순열에서는 [A, B, C], [A, C, B], [B, A, C], [B, C, A], [C, A, B], [C, B, A]의 여섯 가지는 모두 다른 경우로 취급하지만, 조합에서는 이 여섯 가지를 하나의 경우로 취급한다. 다시 말해 순열에서처럼 순서를 생각하여 선택하면, 중복된 경우가 6배 발생한다.
순서를 생각하느라 중복된 부분이 발생한 순열의 모든 가짓수를, 중복된 경우의 수로 나누어 주면 조합의 모든 경우의 수를 얻을 수 있다.
- 5장에서 3장을 무작위로 선택하는 조합에서 모든 경우의 수 = 5C3 =
5! / (3! * 2!)=10
일반식: nCr =n! / (r! * (n - r)!)
조합의 모든 경우의 수를 나열해보자
// 반복문 코드
function combinationLoop() {
// 조합 요소가 인자로 주어질 경우, 인자 그대로 사용하면 되지만, 인자가 주어지지 않고
// 문제 안에 포함되어 있을 경우 이런 식으로 직접 적어서 사용합니다.
let lookup = ['A', 'B', 'C', 'D', 'E'];
let result = [];
console.log(lookup);
for (let i = 0; i < lookup.length; i++) {
for (let j = i + 1; j < lookup.length; j++) {
for (let k = j + 1; k < lookup.length; k++) {
result.push([lookup[i], lookup[j], lookup[k]]);
}
}
}
return result;
}
combinationLoop();순열과 마찬가지로 result 배열 안에 순열의 경우의 수를 삽입한 뒤, 반환하는 함수이다.
- 순열과 다른 점은, 반복의 조건에 있다. (
i = 0, j = i + 1, k = j + 1)- 한 번 조합한 요소는 다시 조합하지 않는다. 하나의 요소로 만들 수 있는 모든 경우의 수를 다 구한 다음, 그 요소를 반복에 포함하지 않고 다음 요소부터 시작한다.
결과
/*
[
[ 'A', 'B', 'C' ], [ 'A', 'B', 'D' ], [ 'A', 'B', 'E' ],
[ 'A', 'C', 'D' ], [ 'A', 'C', 'E' ], [ 'A', 'D', 'E' ],
[ 'B', 'C', 'D' ], [ 'B', 'C', 'E' ], [ 'B', 'D', 'E' ],
[ 'C', 'D', 'E' ]
]
*/반복문으로 순열과 조합을 만들어낼 수는 있다. 하지만, 분명한 한계점이 존재한다.
- 개수가 늘어나면 반복문의 수도 늘어난다.
- 만약, 11개의 요소 중 10개를 뽑아야 한다면, 10중 반복문을 구현해야 한다. 이는 굉장히 비효율적일 뿐더러 보기 좋은(쉬운) 코드에 부합하지도 않는다.
- 뽑아야 되는 개수가 n개처럼 변수로 들어왔을 때 대응이 어렵다.
- 요소 개수를 변수로 받는 건
요소.length를 사용하여 대응할 수 있지만, 뽑아야 되는 개수도 변수로 받게 된다면 몇 개의 반복문을 설정해야 하는지, 설정은 어떻게 하는지 굉장히 까다로워질 것이다..
- 요소 개수를 변수로 받는 건
📌 그렇기에 순열과 조합은 재귀를 사용하여 풀이하는 경우가 많다. 재귀를 사용한 순열과 조합 코드 제작을 직접 시도해보자.
문제2: 소수 찾기
한 자리 숫자가 적힌 종잇조각이 흩어져 있습니다. 흩어진 종잇조각을 붙여 소수를 몇 개 만들 수 있는지 알아내려 합니다. 종이에 기록된 모든 숫자가 배열로 주어진다면, 이 종잇조각으로 만들 수 있는 소수는 몇 개인가요?
이 문제에는 순열이 숨어 있다. 만약 이 사실을 알아차린다면, 문제를 보다 쉽게 해결할 수 있다. 순열을 이용한다면, 다음과 같이 전략을 세울 수 있다.
- n 개의 숫자 중에 1~k 개를 뽑아서 순열을 생성한다.
- 각 순열을 정수로 변환하고, 해당 정수가 중복되지 않으면서 동시에 소수인지 검사한다.
- 소수라면 개수를 센다.
숫자는 순서에 의해 전혀 다른 값이 될 수 있다. 예를 들어 123과 321은 전혀 다른 숫자이다.
만약 이 문제를 조합으로 접근하게 된다면, 123과 321은 같은 경우로 취급한다. 따라서, 순서를 고려하지 않고 k 개를 뽑아내는 조합으로는 이 문제를 해결할 수 없다.
문제3: 일곱 난쟁이
왕비를 피해 일곱 난쟁이와 함께 평화롭게 생활하고 있던 백설 공주에게 위기가 찾아왔습니다. 하루일과를 마치고 돌아온 "일곱" 난쟁이가 "아홉" 명이었던 겁니다. 아홉 명의 난쟁이는 모두 자신이 "백설 공주와 일곱 난쟁이"의 주인공이라고 주장했습니다. (뛰어난 수학적 직관력을 가지고 있던) 백설 공주는 일곱 난쟁이의 키의 합이 100임을 기억해 냈습니다. 아홉 난쟁이 각각의 키가 주어질 때, 원래 백설 공주와 평화롭게 생활하던 일곱 난쟁이를 찾는 방법은 무엇인가요?
위 문제는 조합을 이용해서 일곱 난쟁이를 찾을 수 있다. 모든 일곱 난쟁이의 키를 합했을 때 100이 된다고 주어졌기 때문에, 9명의 난쟁이 중 7명의 난쟁이를 순서를 생각하지 않고, 난쟁이 7명의 키를 합했을 때 100이 되는 경우를 찾으면 된다.
위 두 문제와 같이 순열과 조합을 활용하는 문제는, 문제를 먼저 이해하고 지문 속에서 힌트를 얻어 활용할 수 있어야 한다.
GCD와 LCM - GCD와 LCM을 이용한 문제들
- 약수: 어떤 수를 나누어떨어지게 하는 수
- 배수: 어떤 수의 1, 2, 3, ...n 배하여 얻는 수
- 공약수: 둘 이상의 수의 공통인 약수
- 공배수: 둘 이상의 수의 공통인 배수
- 최대공약수(GCD. Greatest Common Divisor): 둘 이상의 공약수 중에서 최대인 수
- 최소공배수(LCM. Least Common Multiple): 둘 이상의 공배수 중에서 최소인 수
유클리드 호제법을 이용한 공식
유클리드 호제법을 이용해 최대공약수를 구하는 로직
function gcd(a, b){
while(b !== 0){
let r = a % b;
a = b;
b = r;
}
return a;
}함수 gcd 는 유클리드 호제법을 적용한 로직이다.
함수 선언을 한 뒤 a와 b를 매개변수로 받고 있으며, 그 안에 while문으로 이루어진 중심 로직이 있다.
while문은 b는 0이 아니어야 함을 조건으로 받고 있는데, 왜 0이 아니어야 하냐면 모든 자연수를 0으로 나누게 되면 리턴되는 값이 Infinity이기 때문입니다. 값이 무한대로 나오면 안 되기 때문에 해당 조건을 걸어둠으로써 값이 제대로 나오지 않는 상황을 방지한다.
해당 조건을 지키며 b가 0이 될 때까지 계속 while문은 돌아간다. 변수 r 은 a와 b의 나머지로 할당되고, a는 b로 재할당을 시키고, b는 r로 재할당을 시키고 있습니다. 그리고 마지막으로 리턴하는 값은 a로, 이 a를 리턴하는 이유는 while문이 돌아가면서 나누는 수를 재할당을 하기 때문.
유클리드 호제법을 이용해 최소공배수를 구하는 로직
function lcm(a, b){
return a * (b / gcd(a, b));
}해당 함수 lcm 은 마찬가지로 a와 b를 매개변수로 받고 있으며, 리턴되는 값으로 a에 b를 최대공약수로 나눈 값을 곱하고 있다. 여기서 최대공약수의 값은 위에서 만들었던 함수 gcd를 이용해 구할 수 있다. 최소공배수는 최대공약수를 이용해서 만들어지는 수이다. 그러므로 최대공약수를 만들 줄 알면 최소공배수 또한 만들 수 있게 됨.
GCD와 LCM의 개념이 적용된 문제
방역용 마스크를 제작/판매하는 Mask States 사는 이례적인 전염성 독감 예방을 위해 기존 가격을 유지하며 약속된 물량의 방역용 마스크를 제공하고 있습니다. 이 회사는 사장을 포함하여 A, B, C 세 명뿐이고, 이들 모두 마스크를 제작합니다. 각각의 제작 속도는 다음과 같습니다.
A는 55분마다 9개를, B는 70분마다 15개를, C는 85분마다 25개의 방역용 마스크를 만들 수 있습니다. 이 회사의 사람들은 05:00 시부터 동시에 마스크를 만들기 시작하여 각 55분, 70분, 85분 동안 연속으로 마스크를 제작한 후, 5분씩 휴식을 취합니다. 이들 세 명이 처음으로 동시에 쉬는 시점이 퇴근 시간이라면, 이날 하루에 제작한 마스크는 모두 몇 개인가요?
(휴식시간과 퇴근시간이 겹치는 경우, 휴식을 취한 뒤 퇴근합니다.)
풀이 방법은 다양하다. 그러나 이 문제에서 최소 공배수를 떠올릴 수 있다면, 더 쉽고 빠르게 문제를 해결할 수 있다.
| 사람 | 작업 시간 + 쉬는 시간 5분 |
|---|---|
| A | 60분에 9개 |
| B | 75분에 15개 |
| C | 90분에 25개 |
세 명이 동시에 휴식을 취하는 시점은 세 명이 쉬고 난 직후가 같을 시점이 된다. 따라서 쉬고 난 직후가 처음으로 같을 시점을 구해야 하므로, 앞서 학습했던 최소공배수의 개념을 알아야 한다.
결과적으로, LCM(60, 75, 90)은 900이다. (LCM; Least Common Multiple, 최소 공배수)
- A는 B, C와 휴식을 취한 직후가 처음으로 같을 시점까지 900/60 = 15 번 작업하고, 15번 X 9개 = 135개의 마스크를 만들어 낸다.
- B는 900/75 = 12번의 작업을 반복하고 12턴 X 15개 = 180개,
- C는 900/90 = 10번의 작업을 반복하고 10턴 X 25개 = 250개의 마스크를 만들어 낸다.
따라서, A, B, C가 하루에 제작한 마스크의 총 개수는 135개 + 180개 + 250개 = 565개가 된다.
최소공배수를 쉽게 알아내는 법은 앞서 소개한 유클리드 호제법을 사용하는 것. 세 수의 최소 공배수를 구하는 방식은 첫 번째 수와 두 번째 수의 최소 공배수를 구한 뒤, 그 값과 세 번째 수의 최소 공배수를 구하는 형식.
멱집합 - Power Set
집합 S가 있을 때, Power Set인 P(S)는 집합 S의 거듭제곱 집합으로, S의 모든 부분 집합의 집합을 의미한다..
예를 들어 집합 S가 {a, b, c} 으로 요소가 3개일 때,
P(S)는 {{}, {a}, {b}, {c}, {a,b}, {a, c}, {b, c}, {a, b, c}} 으로 요소가 8개임을 알 수 있다.
즉 S에 n개의 요소가 있다면 P(S)에는 2^n의 요소가 있음을 의미한다.
Set = [a, b, c]
power_set_size = pow(2, 3) = 8
Run for binary counter = 000 to 111
Value of Counter Subset
000 Empty set
001 a
010 b
011 ab
100 c
101 ac
110 bc
111 abc이제 알고리즘 로직을 보자
(이해x)
Input : Set[], set_size
- 모든 집합의 크기를 가져온다.
power_set_size = pow(2, set_size) 0에서부터power_set_size까지의 반복문 실행i = 0에서set_size까지 크기를 지정해 반복문을 돌린다. 그리고 집합에서 i번째 요소에 해당하는 하위 집합을 출력한다.- 하위 집합을 구하면 개행을 통해 집합을 구분한다.
주어진 집합 S에 대해 거듭제곱 집합은 0과 2^n-1 사이의 모든 이진수를 생성하여 찾을 수 있다. 여기서 n은 집합의 크기이다. 예를 들어 집합 S {x, y, z}에 대해 0부터 2^3-1까지의 모든 이진수를 생성하고, 생성된 각 숫자에대해 해당 숫자의 집합 비트를 고려하여 해당 집합을 찾을 수 있다.
let inputSet = ['a', 'b', 'c'];
function powerSet (arr) {
const result = [];
function recursion (subset, start) {
result.push(subset);
for(let i = start; i < arr.length; i++){
recursion([...subset, arr[i]], i+1);
//이렇게도 구현할 수 있습니다.
recursion(subset.concat(arr[i]), i+1);
}
}
recursion([], 0);
return result;
}
powerSet(inputSet);[
[],
[ 'a' ],
[ 'a', 'b' ],
[ 'a', 'b', 'c' ],
[ 'a', 'c' ],
[ 'b' ],
[ 'b', 'c' ],
[ 'c' ]
]위의 powerSet 로직은 재귀함수를 이용하여 구현한 것이다. 재귀함수에 부분집합을 만들기 위한 빈배열과 시작할 숫자를 지정하고 이어 숫자가 커지게끔 하면서 중심 로직인 반복문을 돌려 부분집합을 만든 뒤, 최종적으로 배열 result에 push한다.
연습문제 - Algorithm with Math
Chapter5. 정규표현식
대부분의 회원 가입이 필요한 서비스는 비밀번호 설정 시 특정 조건에 맞추어 입력하라고 요구한다. 보통의 비밀번호 조건은 영문 대문자, 소문자를 한 번씩 써야 하며 12 자 이상이어야 하고, 특수 문자는 1 개 이상 들어가야 하는 등 까다롭게 설정되어 있다.
사용자는 본인이 생각한 하나의 비밀번호 패턴만 사용하기 때문에 어렵지 않게 조건에 맞는 비밀번호를 생성할 수 있지만, 관리자의 경우 적게는 열 개, 많게는 수억 개에 달하는 이 수많은 패턴의 유효성을 어떻게 설정하고 관리할까?
문자를 하나하나 검사하거나, 모든 조건에 대해 조건문을 설정하는 등 다양한 방법이 있겠지만, 문자열 관리를 간편하게 하는 방법중엔 대표적으로 정규표현식을 사용한다.
- 정규표현식이 무엇인지 학습하고, 해당 개념을 적용한 유효성 검사에 대해 이해합니다.
- 정규표현식을 사용하기 위한 리터럴 패턴과 생성자 함수 호출 패턴에 대해 학습하고 이해합니다.
- 정규식 패턴에 어떤 것이 있는지 학습하고 이해합니다.
- 정규표현식을 활용한 알고리즘 예제에 대해 학습하고 로직을 이해합니다.
- 정규표현식의 실제 예시를 보고 이해합니다.
정규 표현식이란?
정규표현식(정규식:正規式)은 문자열에서 특정한 규칙에 따른 문자열 집합을 표현하기 위해 사용되는 형식 언어이다. 정규표현식을 이용한다면 수십 줄이 필요한 코딩 작업을 간단하게 한두 줄로 끝낼 수 있다.
정규표현식은 특정한 규칙을 갖는 문자열로 이루어진 표현식이며, 정규표현식에서의 특수 문자는 각각의 고유한 규칙을 갖고 있다. 우리는 이러한 규칙들을 조합하여 원하는 패턴을 만들고, 특정 문자열에서 해당 패턴과 대응하는 문자를 찾을 수 있다.
정규 표현식 예시
아래의 코드는 사용자가 입력한 이메일이나 휴대전화 번호가 유효한지 확인하고자 할 때 사용하는 정규표현식이다. 정규표현식을 사용한다면, 한 줄의 코드만으로 이메일이나 휴대전화 번호의 유효성을 검사할 수 있지만, 만약 그렇지 않으면 같은 결과를 얻기 위해서는 굉장히 긴 코드가 필요함.
이메일 유효성 검사
const email = 'kimcoding@codestates.com';
let result = '올바릅니다.';
// 1. 정규표현식 사용
let regExp = /^[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*.[a-zA-Z]{2,3}$/i;
if(regExp.test(email) === false) result = '올바르지 않습니다.';
result; // '올바르지 않습니다.'
-----------------------------------------------------------------------------
// 2. 정규표현식이 아닌 경우, 이메일 아이디가 영문 소문자인지 확인하는 코드
let idx = email.indexOf('@');
if(idx === -1) result = '영문 소문자가 아닙니다.';
let ID = email.slice(0,idx);
ID.split('').forEach(e => {
e = e.charCodeAt(0);
if(e < 97 || e > 122){
result = '영문 소문자가 아닙니다.';
}
});
result; // '올바릅니다.'휴대전화 번호 유효성 검사
let regExp = /^01([0|1|6|7|8|9]?)-?([0-9]{3,4})-?([0-9]{4})$/;정규표현식 사용하기
정규표현식은 두 가지 방법으로 사용할 수 있다.
리터럴 패턴
정규표현식 규칙을 슬래시(/)로 감싸 사용한다. 슬래시 안에 들어온 문자열이 찾고자 하는 문자열이며, 컴퓨터에게 '슬래시 사이에 있는 문자열을 찾고 싶어!'라고 명령을 내리는 것이다.
let pattern = /c/;
// 'c 를 찾을 거야!' 라고 컴퓨터에게 명령을 내리는 것이다.
// 찾고 싶은 c를 pattern 이라는 변수에 담아놨기 때문에 이 변수를 이용하여 c 를 찾을 수 있다.생성자 함수 호출 패턴
RegExp 객체의 생성자 함수를 호출하여 사용한다.
정규식 패턴
정규표현식에 다양한 특수기호를 함께 사용하면 문자열을 다룰 때에 더 많은 옵션을 설정할 수 있다.
| 정규식 패턴 | 설명 |
|---|---|
| ^ | 줄(Line)의 시작에서 일치 /^abc/ |
| $ | 줄(Line)의 끝에서 일치 /xyz$/ |
| . | (특수기호, 띄어쓰기를 포함한) 임의의 한 문자 |
| a바b | a or b 와 일치, 인덱스가 작은 것을 우선 반환 |
| * | 0회 이상 연속으로 반복되는 문자와 가능한 많이 일치. {0,} 와 동일 |
| *? | 0회 이상 연속으로 반복되는 문자와 가능한 적게 일치. {0} 와 동일 |
| + | 1회 이상 연속으로 반복되는 문자와 가능한 많이 일치. {1,} 와 동일 |
| +? | 1회 이상 연속으로 반복되는 문자와 가능한 적게 일치. {1} 와 동일 |
| {3} | 숫자 3개 연속 일치 |
| {3,} | 3개 이상 연속 일치 |
| {3, 5} | 3개 이상 5개 이하 연속 일치 |
| () | 캡쳐(capture)할 그룹 |
| [a-z] | a부터 z 사이의 문자 구간에 일치(영어 소문자) |
| [A-Z] | A부터 Z 사이의 문자 구간에 일치(영어 대문자) |
| [0-9] | 0부터 9 사이의 문자 구간에 일치(숫자) |
| (역슬래쉬) | escape 문자. 특수 기호 앞에 \를 붙이면 정규식 패턴이 아닌, 기호 자체로 인식 |
| \d | 숫자를 검색함. /[0-9]/와 동일 |
| \D | 숫자가 아닌 문자를 검색함. /[^0-9]/와 동일 |
| \w | 영어대소문자, 숫자, (underscore)를 검색함. /[A-Za-z0-9]/ 와 동일 |
| \W | 영어대소문자, 숫자, (underscore)가 아닌 문자를 검색함. /[^A-Za-z0-9]/ 와 동일 |
| [^] | []안의 문자열 앞에 ^이 쓰이면, []안에 없는 문자를 검색함 |
정규표현식을 활용한 알고리즘 예제
알고리즘 문제를 풀 때에도 정규표현식을 유용하게 사용할 수 있다. 예시 문제를 통해 정규표현식을 알고리즘 문제에 적용했을 때의 이점을 확인해보자
문자열
str이 주어질 때,str의 길이가 5 또는 7이면서 숫자(0~9)로만 구성되어 있는지를 확인해 주는 함수를 작성하세요. 결과는 Boolean으로 리턴됩니다. 예를 들어str가c2021이면false,20212이면true를 리턴합니다.
정규표현식을 사용하지 않고 이 문제를 해결하기 위한 코드를 작성한다면, 보통은 조건문을 통해 문자열 str의 길이와 문자의 포함 여부를 확인하는 방식으로 문제 풀이 코드를 작성했을 것이다. 하지만 정규표현식을 이용하면 이 과정을 아래와 같이 한 줄로 줄일 수 있다.
// 정규표현식 사용
function solution(str) {
return /^\d{5}$|^\d{7}$/.test(str);
}
// 정규표현식 미사용
function solution(str) {
if(str.length === 5 || str.length === 7) {
for(let i = 0; i < str.length; i++) {
if(typeof Number(str[i]) !== 'number') return false;
}
return true;
}
return false;
}이처럼 정규표현식을 알아두면 문자열을 다룰 때 코드를 간결하게 줄일 수 있는 유리한 상황이 있다.
정규표현식의 실례
정규표현식 내장 메소드
JavaScript 에서 정규표현식은 객체로서 내장 메소드를 가지고 있으며, String 객체에서도 정규표현식을 사용할 수 있는 내장메소드를 가지고 있다.
내장 메소드를 이용하면 어떤 문자열 안에 원하는 정보를 찾거나 특정 패턴에 대응하는 문자열을 검색, 추출, 다른 문자열로 치환할 수 있다.
RegExp 객체의 메소드
exec()
exec 는 execution 의 줄임말로, 원하는 정보를 뽑아내고자 할 때 사용한다. 검색의 대상이, 찾고자 하는 문자열에 대한 정보를 가지고 있다면 이를 배열로 반환하며, 찾는 문자열이 없다면 null을 반환한다.
let pattern = /c/; // 찾고자 하는 문자열
pattern.exec('codestates') // 검색하려는 대상을 exec 메소드의 첫 번째 인자로 전달합니다.
// 즉, 'codestates' 가 'c' 를 포함하고 있는지를 확인합니다.
// 이 경우 'c' 가 포함되어 있으므로, ['c'] 를 반환합니다.test()
찾고자 하는 문자열이, 대상 안에 있는지의 여부를 boolean 으로 리턴한다.
let pattern = /c/;
pattern.test('codestates');
// 이 경우는 'codestates'가 'c'를 포함하고 있으므로 true 를 리턴합니다.String 객체의 메소드
