MVVM의 Model에 대하여
전편에서 repository와 data source에 대해 잠깐 언급하였다.
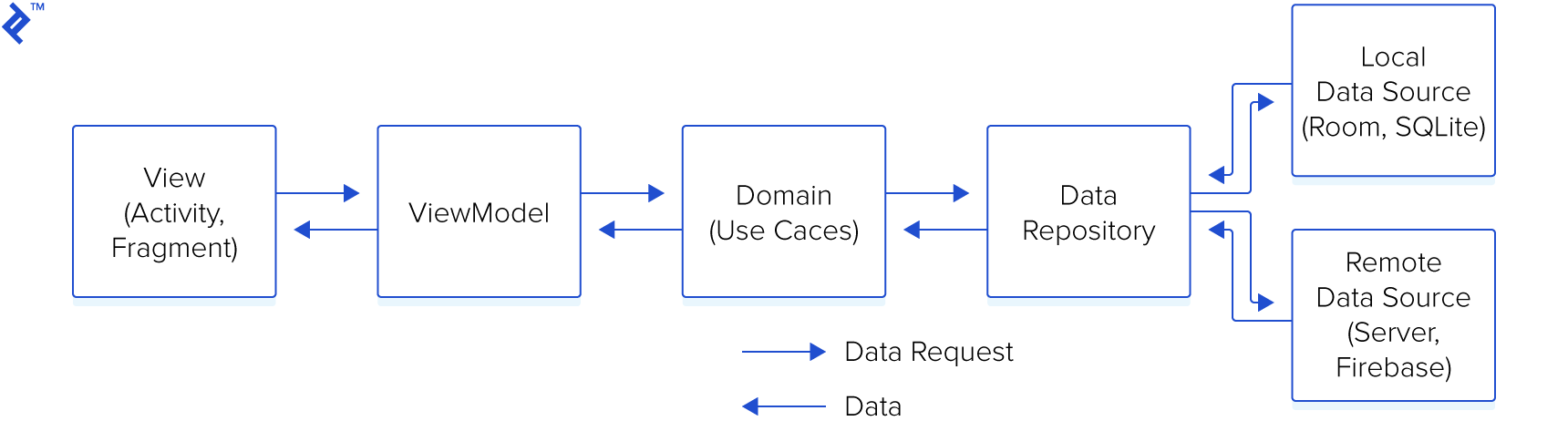
앱의 규모가 크다면 해당 이미지의 흐름으로 설계할 수 있다. 이번 편에서는 Domain(Use Cases)과 Data Repository, Data Source에 대해서 살펴보자.
(이 부분은 클린아키텍처 패턴의 Domain Layer와 Data Layer라고도 볼 수 있다. 클린 아키텍처에 관한 글은 따로 작성할 예정..)
데이터를 저장하고 불러오는 기능을 구현하려면, 서버와 통신하거나 db에 접근하는 기능은 반드시 있어야 한다.
그렇다면 이 기능들은 어디에 있어야 할까?
일단 각각의 개념은 다음과 같다.
Usecases
UseCases는 애플리케이션의 비즈니스 로직을 캡슐화합니다. UseCase는 Domain 레이어에서 정의됩니다. 뷰모델은 UseCase를 호출하고 UseCase는 Repository를 사용하여 데이터를 가져옵니다. 이를 통해 뷰모델은 비즈니스 로직과 데이터 액세스를 분리할 수 있습니다.
Repository
Repository는 데이터를 가져오거나 저장하는 데 사용됩니다. Repository는 다른 데이터 원본, 예를 들어 로컬 데이터베이스, 원격 데이터베이스 또는 API와 상호 작용할 수 있습니다. Repository는 데이터 액세스에 대한 인터페이스를 제공하며, 실제 데이터 원본에 대한 구현 세부 정보를 숨깁니다.
DataSource
DataSource는 Repository에서 데이터를 가져오는 데 사용되는 실제 데이터 원본입니다. DataSource는 데이터를 검색하고, 필터링하고, 정렬하는 등의 일을 수행합니다. Repository는 다양한 DataSource를 가질 수 있으며, 이는 애플리케이션의 성능과 확장성에 큰 영향을 미칩니다.
더 쉽게 풀어서 생각해보자.
파이어베이스를 통해 이미지 전송 및 로드, 삭제 기능을 하는 뷰모델을 제작하려고 한다. ImageViewModel은 다음과 같다.
class ImageViewModel {
final FirebaseStorage _storage = FirebaseStorage.instance;
Future<String> uploadImage(File file, String path) async {
try {
// Upload file to Firebase Storage
final snapshot = await _storage.ref(path).putFile(file);
// Get download URL
final downloadUrl = await snapshot.ref.getDownloadURL();
return downloadUrl;
} catch (e) {
print('Failed to upload image: $e');
return null;
}
}
Future<File> loadImage(String url) async {
try {
// Load image from Firebase Storage
final ref = _storage.refFromURL(url);
final bytes = await ref.getData();
return File.fromBytes(bytes);
} catch (e) {
print('Failed to load image: $e');
return null;
}
}
Future<void> deleteImage(String url) async {
try {
// Delete image from Firebase Storage
final ref = _storage.refFromURL(url);
await ref.delete();
} catch (e) {
print('Failed to delete image: $e');
}
}
...
}이렇게 뷰모델에서 모든 걸 해결해버리면 당연히 안 된당.
위의 구조를 따라서 다시 리팩토링 해보자.
Usecase는, 특정한 하나의 기능만을 담당한다. 즉 위의 뷰모델이라면, 이미지 전송, 로드, 삭제 각각의 유즈케이스를 만들어 뷰모델에서는 유즈케이스 호출만 하면 된다.
유즈 케이스의 각 기능들은 또 레포지토리의 함수를 호출한다.
Repository는 다양한 기능의 함수들이 모여있다. 이것 역시 데이터소스의 함수를 호출한다.
마지막으로 Date Source에서는 직접적으로 api나 파이어베이스에 접근하는 메서드를 작성하면 됨!!!
코드로 확인해보자.
뷰모델은 아래와 같이 깔끔하게 바뀐다.
class ImageViewModel {
final CreateImageUseCase _createImageUseCase;
final LoadImageUseCase _loadImageUseCase;
final DeleteImageUseCase _deleteImageUseCase;
ImageViewModel(
this._createImageUseCase,
this._loadImageUseCase,
this._deleteImageUseCase
);
Future<void> createImage(String filePath) async {
try {
await _createImageUseCase(filePath);
} catch (e) {
// handle error
}
}
Future<String> loadImage(String imagePath) async {
try {
final url = await _loadImageUseCase(imagePath);
return url;
} catch (e) {
// handle error
}
}
Future<void> deleteImage(String imagePath) async {
try {
await _deleteImageUseCase(imagePath);
} catch (e) {
// handle error
}
}
}또 각각의 유즈케이스는 아래처럼 작성된다. 예시로 하나만 보자.
class CreateImageUseCase {
final ImageRepository _repository;
CreateImageUseCase(this._repository);
Future<void> call(String filePath) async {
await _repository.createImage(filePath);
}방금 알게된 건데 call을 호출하지 않아도 된다고 한다.
usecase.call(param)과 usecase(param)는 같은 명령어
라고한다 오홍
usecase.call(param)은 usecase의 call 메서드를 호출하는 방법 중 하나이고, usecase(param)은 usecase 객체에 직접 매개변수를 전달하는 방법입니다
이유는 Dart 언어에서는 객체를 함수처럼 사용할 수 있도록 Function 타입을 지원하기 때문입니다. 이러한 개념을 Callable class라고도 합니다. 그래서 usecase는 Callable class를 구현한 클래스이기 때문에 usecase.call(param)과 usecase(param) 두 가지 방법으로 호출할 수 있습니다. 다만, 보통의 경우 .call을 생략하여 usecase(param) 형태로 호출하는 것이 일반적인 사용 방법입니다.
그렇다면 레포지토리와 데이터소스는 아래처럼 생겼을 것이다.
ImageRepository
abstract class ImageRepository {
Future<String> createImage(File imageFile);
Future<String> loadImage(String imagePath);
Future<void> deleteImage(String imagePath);
}
class ImageRepositoryImpl implements ImageRepository {
final ImageDataSource _dataSource;
ImageRepositoryImpl(this._dataSource);
@override
Future<String> createImage(File imageFile) async {
return _dataSource.uploadImage(imageFile);
}
@override
Future<String> loadImage(String imagePath) async {
return _dataSource.loadImage(imagePath);
}
@override
Future<void> deleteImage(String imagePath) async {
return _dataSource.deleteImage(imagePath);
}
}근데..레포지토리 단계는 굳이 필요한가?
데이터 소스의 메소드들을 레포지토리에 넣으면 안돼?
추상화와 모듈성: 데이터 원본에 대한 구현 세부정보를 숨기면, 다른 부분에서 이를 참조할 때 추상화된 인터페이스만 사용하면 됩니다. 이는 코드의 모듈성을 높여줍니다. 또한, 추상화된 인터페이스를 이용해 다른 데이터 원본으로의 교체가 용이해집니다.
보안: 실제 데이터 원본에 대한 구현 세부정보를 외부에 노출시키지 않으면, 보안상의 이슈가 줄어듭니다.
단일책임의 원칙: Repository는 데이터 원본에서 데이터를 가져오는 역할만 담당합니다. 따라서, 이를 구현하는 세부적인 부분은 Repository의 책임이 아닙니다. 이를 구현하는 세부적인 부분은 DataSource에서 처리하게 되므로, 코드의 단일책임의 원칙을 지킬 수 있습니다.
라고 합니다. 알겠습니다..
Image Data Source
abstract class ImageDataSource {
Future<String> uploadImage(File imageFile);
Future<String> loadImage(String imagePath);
Future<void> deleteImage(String imagePath);
}
class FirebaseImageDataSource implements ImageDataSource {
final FirebaseStorage _storage = FirebaseStorage.instance;
@override
Future<String> uploadImage(File imageFile) async {
final fileName = basename(imageFile.path);
final storageRef = _storage.ref().child('images/$fileName');
final uploadTask = storageRef.putFile(imageFile);
final snapshot = await uploadTask.whenComplete(() {});
final downloadUrl = await snapshot.ref.getDownloadURL();
return downloadUrl;
}
@override
Future<String> loadImage(String imagePath) async {
final storageRef = _storage.ref().child(imagePath);
final downloadUrl = await storageRef.getDownloadURL();
return downloadUrl;
}
@override
Future<void> deleteImage(String imagePath) async {
final storageRef = _storage.ref().child(imagePath);
await storageRef.delete();
}
}항상 궁금했던 것 추상 클래스는 굳이 왜 써야하지?
추상 클래스를 사용하는 이유 중 하나는 다형성을 구현하기 위해서입니다. 즉, 여러 클래스가 동일한 기능을 수행하지만 세부적인 구현 방법이 다를 때, 추상 클래스를 상속하여 기능을 구현하면 코드의 재사용성과 유지보수성을 높일 수 있습니다.
예를 들어, 여러 데이터 소스가 있을 때 (예: 로컬 데이터베이스, 원격 서버, 캐시 등), 이 데이터 소스들은 같은 데이터를 다루지만, 각각의 데이터 소스는 그 데이터를 다루는 방식이 조금씩 다릅니다. 추상 클래스를 사용하여 이러한 데이터 소스들이 동일한 메서드를 구현하도록 강제하고, 실제 데이터 소스 클래스에서 추상 클래스를 상속하여 구체적인 기능을 구현하면 코드의 일관성과 가독성을 유지할 수 있습니다.
아하... 이해완
보통 프로젝트에서 추상클래스를 만들어도 그것을 상속하는 클래스가 하나뿐이라 이해하기 어려웠었다.
위의 코드에서는 ImageDataSource에서 파이어베이스에 접근하는 FirebaseImageDataSource 이외에도 다른 서버나 로컬에 접속하는 LocalImageDataSource 같은 클래스를 만들어도 같은 모냥으로 함수 내용만 달라지게 해서 만들 수 있다!
결론은
아무튼 이렇게 뷰 -> 뷰모델 -> 유즈케이스 -> 레포지토리 -> 데이터소스 까지의 구조와 흐름을 알아보았다.
화살표는 호출의 방향이고, 반대로 데이터는 화살표 반대방향으로 흘러온다. 뷰는 뷰모델에 간섭해서는 안되고, 뷰모델은 유즈케이스에 간섭해서는 안된다.
그런데 결국 뷰모델에서는 유즈케이스, 레포지토리, 데이터소스 파라미터를 모두 가져와야하잖아요
넹... 유즈 케이스만 해도
CreateImageUseCase(ImageRepositoryImpl(FirebaseImageDataSource()))
모 이렇게 끝없이 되겠죠?
그래서 다음시간에는 DI에 대해서 알아봅시다
안뇽
