- 새롭게 작업을 시작하며 그간 쌓여온 데이터들을 전처리할 필요가 생겼고 겸사겸사 파이썬 dataframe, csv를 다루는 것에 대해 정리하려함
-
csv
csv는 xlsx처럼 엑셀에서 사용하는 형식 중 하나로 comma-separated values 로 comma로 구분된다 (tsv는 tab)
csv를 읽기 위해선 간단하게
이와 같은 형식으로 읽는 방법이 있다. (방법은 다양) -
pandas
pandas는 최근 파이썬에서 핫한 빅데이터, AI등에서 사용되는 행렬 계산을 편하게 제공하는 외부라이브러리로 csv를 쉽게 dataframe으로 변경해 이를 더 쉽게 편집하고 가공할 수 있는 기능을 제공한다. -
data 처리
- columns 추가 - dataframe.columns = [컬럼명 리스트]
- column type 변경 - df[col] = df[col].astype(변경할 타입)
- Nan 처리 방법
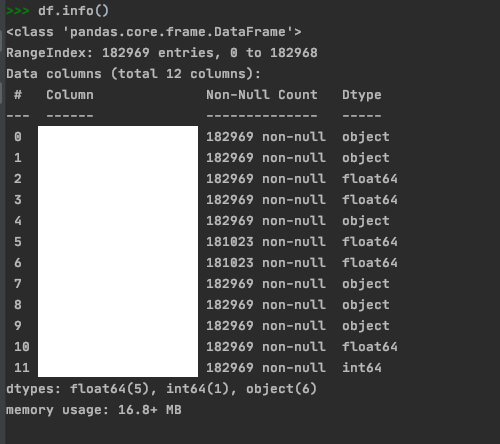
df.info()를 통해 null 값을 확인할 수 있고 이를 처리해줘야 나중에 데이터 처리과정에서 문제가 발생하지 않는다.
- dropna() : 모든 Nan값을 삭제하는 것 간단하지만 row를 모두 삭제 dropna(axis=1)을 할 경우 열을 삭제해버린다.
thresh = 500 - Nan값이 500개 이상인 열을 모두 삭제하는 옵션 - fillna() - 누락 data 치환
ex) - df[col].fillna( value, inplace=True)
/// ls = list(df.index[df['receiver_longitude'].isnull()]) 와 같은 형태로 표현할 수 있다. ## inplace는 원본 dataframe을 바로 변경하는 것!!
--> Nan의 처리는 굉장히 다양하므로 그때그때 상황에 맞춰서 진행
-
columns이 없을 경우엔 df.columns = columns(list로)
-
df.to_csv -> csv로 추출
Pandas 행에 접근 방법
-
pd.iterrows() -- 제일 느린방법, 단순히 row를 반복해서 몇번째, row 자체를 리턴
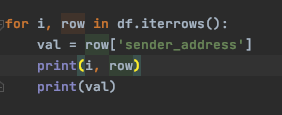
이러한 형태.. -
pd.loc[]/pd/iloc
해당 방법은 index를 통해 for문을 돌면서 loc, iloc 함수를 통해 df의 row에 접근하는 방법
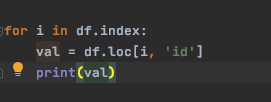

이러한 형태..
- get_value(), set_value()
- 이 역시 index를 통해 for문을 돌면서 메소드를 이용하는 방법인데 앞에 _ 를 붙이지 않으니 적용되지 않음. (_get.value() 와 같은 형태로 사용)
_get_value(i, column)으로 사용하고 set 역시 마찬가지!
위의 세가지 방법 모두를 사용해 시간을 측정했는데 (대략 1800만건 데이터 읽기) 확실히 제일 마지막 방법이 속도가 좋았음.
apply라는 메서드도 있다고 하는데 해당 방법은 사용해보지 않음

///