
[SQLD 시험 대비] 2과목. SQL 기본 및 활용 : 2장. SQL 활용 - 5. 그룹 함수(Group 함수)
ANSI/ISO SQL 표준은 데이터 분석을 위해서 다음 세 가지 함수를 정의하고 있다.
- AGGREGATE FUNCTION
- GROUP FUNCTION
- WINDOW FUNCTION
이 중에서 GROUP FUNCTION에 대해 알아보자.
Group 함수
- 그룹 함수를 사용한다면 하나의 SQL로 테이블을 한 번만 읽어서 빠르게 원하는 리포트를 작성할 수 있다.
- 소계/합계를 표시하기 위해 GROUPING 함수와 CASE 함수를 이용하면 쉽게 원하는 포맷의 보고서 작성도 가능하다
- 그룹 함수로는 집계 함수를 제외하고, 소그룹 간의 소계를 계산하는 ROLLUP 함수, GROUP BY 항목들 간 다차원적인 소계를 계산 할 수 있는 CUBE 함수, 특정 항목에 대한 소계를 계산하는 GROUPING SETS 함수가 있다.
ROLLUP 함수
- ROLLUP에 지정된 Grouping Columns의 List는 Subtotal을 생성하기 위해 사용
- GROUP BY의 확장된 형태
- 병렬로 수행이 가능하기 때문에 매우 효과적일 뿐 아니라 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하다.
- Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성된다.
- ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 되므 로 인수의 순서에도 주의해야 한다.
예제를 통해 ROLLUP 함수를 이해해보자
예제 1 - ROLLUP 함수 사용
- 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ROLLUP 함수를 사용해보자.
SELECT DNAME, JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);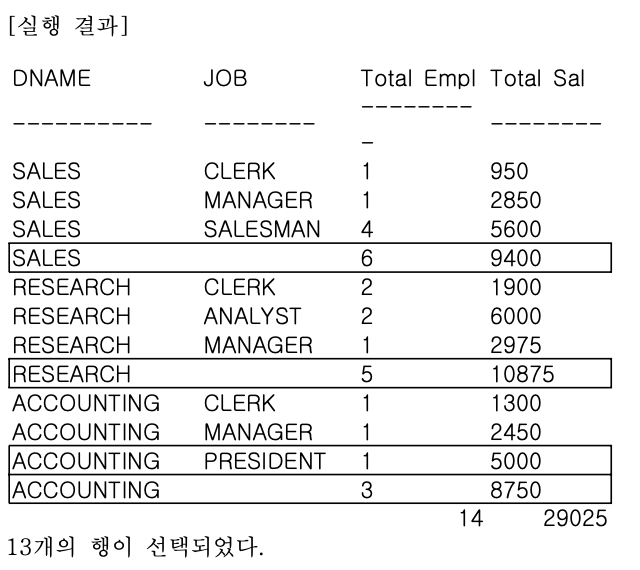
- 실행 결과에서 2개의 GROUPING COLUMNS(DNAME, JOB)에 대하여 다음과 같은 추가 LEVEL의 집계가 생성된 것을 볼 수 있다.
- L1 - GROUP BY 수행시 생성되는 표준 집계 (9건)
- L2 - DNAME 별 모든 JOB의 SUBTOTAL (3건)
- L3 - GRAND TOTAL (마지막 행, 1건)
예제 2 - ROLLUP 함수 + ORDER BY 절 사용
- ROLLUP의 경우 계층 간 집계에 대해서는 LEVEL 별 순서(L1→L2→L3)를 정렬 하지만, 계층 내 GROUP BY 수행시 생성되는 표준 집계에는 별도의 정렬을 지원하지 않는다.
- L1, L2, L3 계층 내 정렬을 위해서는 별도의 ORDER BY 절을 사용해야 한다.
- 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ROLLUP 함수를 사용해보자.
- 추가로 ORDER BY 절을 사용해서 부서, 업무별로 정렬한다.
SELECT DNAME, JOB, COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
ORDER BY DNAME, JOB ;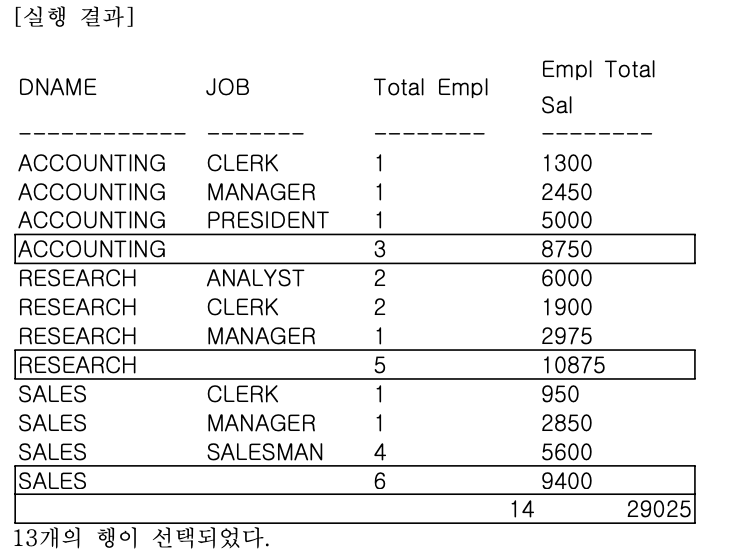
예제 3 - GROUPING 함수 사용
- 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가할 수 있다.
- ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1 이 표시되고,
- 그 외의 결과에는 GROUPING(EXPR) = 0 이 표시된다.
- GROUPING 함수와 CASE/DECODE를 이용해, 소계를 나타내는 필드에 원하는 문자열을 지정할 수 있어, 보고서 작성시 유용하게 사용할 수 있다.
- ROLLUP 함수를 추가한 집계 보고서에서 집계 레코드를 구분할 수 있는 GROUPING 함수를 추가해보자.
SELECT DNAME, GROUPING(DNAME),
JOB, GROUPING(JOB),
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);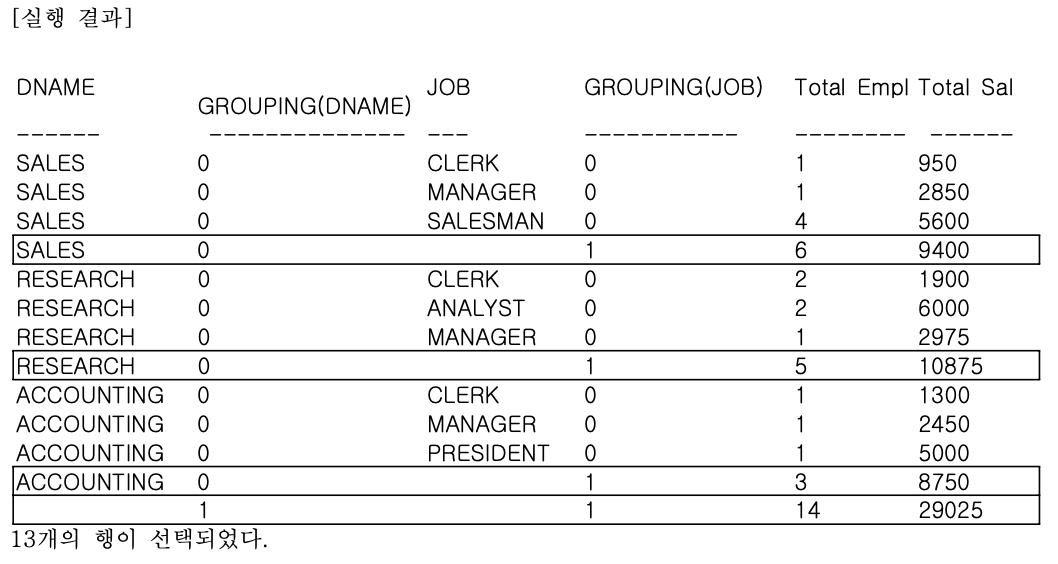
예제 4 - GROUPING 함수 + CASE 사용
- ROLLUP 함수를 추가한 집계 보고서에서 집계 레코드를 구분할 수 있는 GROUPING 함수와 CASE 함수를 함께 사용한 SQL 문장을 작성해보자.
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);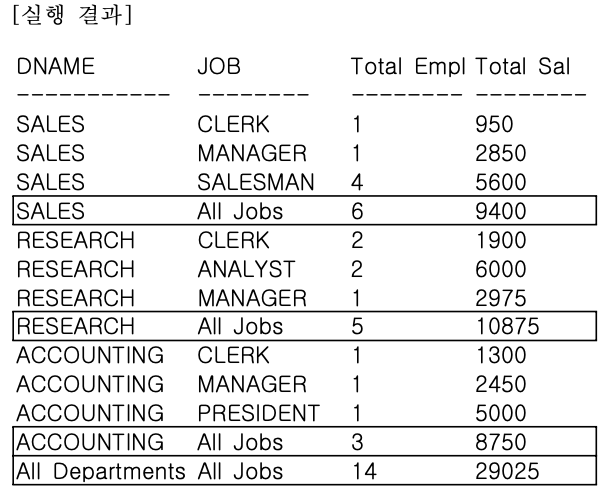
- 부서별과 전체 집계를 표시한 레코드에서 ‘ALL JOBS’와 ‘ALL DEPARTMENTS’라는 사용자 정의 텍스트를 확인할 수 있다.
예제 5 - ROLLUP 함수 일부 사용
- GROUP BY ROLLUP (DNAME, JOB) 조건에서 GROUP BY DNAME, ROLLUP(JOB) 조건으로 변경해보자.
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, ROLLUP(JOB)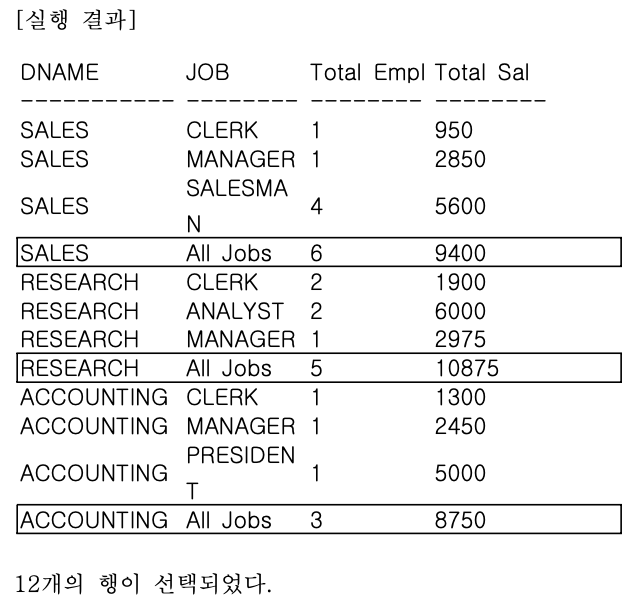
- 결과는 마지막 ALL DEPARTMENTS &ALL JOBS 줄만 계산이 되지 않았다.
- ROLLUP이 JOB 칼럼에만 사용되었기 때문에 DNAME에 대한 집계는 필요하지 않기 때문이다.
CUBE 함수
- ROLLUP에서는 단지 가능한 Subtotal만을 생성하였지만, CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
- CUBE를 사용할 경우에는 내부적으로는 Grouping Columns의 순서를 바꾸어서 또 한 번의 Query를 추가 수행해야 한다.
- Grand Total은 양쪽의 Query 에서 모두 생성이 되므로 한 번의 Query에서는 제거되어야만 하므로 ROLLUP에 비해 시스템의 연산 대상이 많다.
- 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔 수 있어도 데이터 결과는 같다.
- 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬 칼럼이 표시가 되어야 한다.
- CUBE는 GROUPING COLUMNS이 가질 수 있는 모든 경우의 수에 대하여 Subtotal을 생성한다.
- GROUPING COLUMNS의 수가 N이라고 가정하면, 2의 N승 LEVEL의 Subtotal을 생성하게 된다.
예제를 통해 CUBE 함수를 이해해보자.
예제 6 - CUBE 함수 이용
- 예제 4의 SQL의 GROUP BY ROLLUP (DNAME, JOB) 조건에서 GROUP BY CUBE (DNAME, JOB) 조건으로 변경해보자.
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB) ;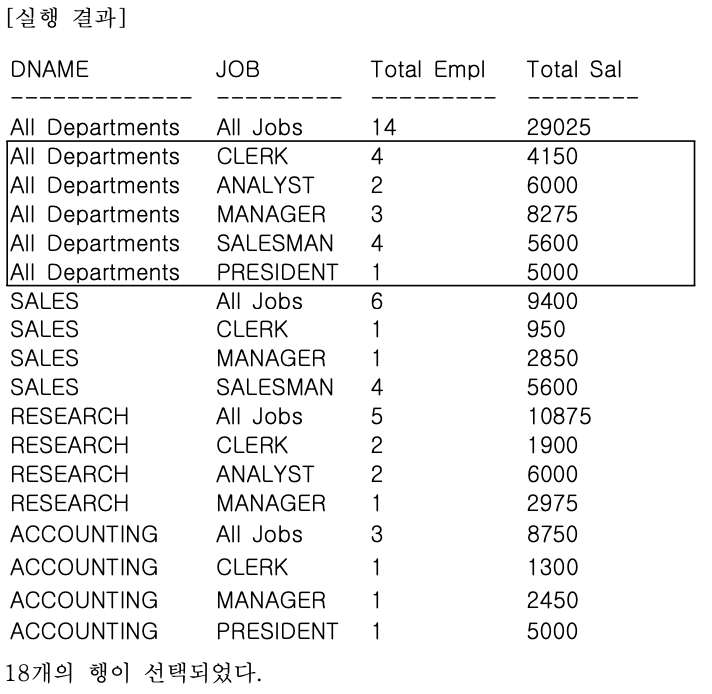
- 실행 결과에서 CUBE 함수 사용으로 ROLLUP 함수의 결과에다 업무별 집계까지 추가해서 출력할 수 있는데, ROLLUP 함수에 비해 업무별 집계를 표시한 5건의 레코드가 추가된 것을 확인할 수 있다.
- All Departments - CLERK, ANALYST, MANAGER, SALESMAN, PRESIDENT 별 집계가 5건 추가되었다.
GROUPING SETS 함수
- GROUPING SETS를 이용해 더욱 다양한 소계 집합을 만들 수 있다.
- GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있다.
- 이 때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
- GROUPING SETS 함수도 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬 칼럼이 표시가 되어야 한다.
예제
- GROUPING SETS 함수를 사용하여 부서별, JOB별 인원수와 급여 합을 구해보자.
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);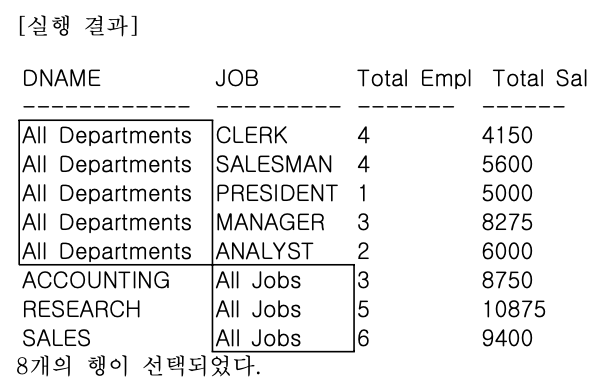
- GROUPING SETS 함수 사용시 UNION ALL을 사용한 일반 그룹함수를 사용한 SQL과 같은 결과를 얻을 수 있다.
SELECT DNAME, 'All Jobs' JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments' DNAME, JOB, COUNT(*) "Total Empl",
SUM(SAL) "Total Sal" FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY JOB ;
코드로 꿈을 펼치는 개발자의 이야기, 노력과 열정이 가득한 곳 🌈