Stream이란 무엇인가?
스트림은 FP 언어에서 얘기하는 sequence와 동일한 용어이다. Sequence는 task의 순서를 나열한
것이다. 이런 순서, sequence대로 일을 처리하라고 함수를 파라미터로 넘기는 행위를 우리는 Sequential Programming 이라고 부른다.
OOP 관점에서는 Internal Iterator Pattern, 내부 반복자 패턴이라고 명명할 수 있다. GoF 디자인 패턴에서 등장하는 개념인데, 컬렉션 내부에서 요소들을 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 코드 패턴 이라고 한다. 즉, 처리 함수를 제공하면 Collection을 순회하는 것을 외부가 아닌, Stream을 만들어 스트림 내부에서 순회하는 것이다. Client 입장(Collection을 사용하는 입장)에서 iterator를 관리할 것인가, 아니면 iterator가 스스로 iterating하는 로직을 관리할 것인가의 차이로
보인다.
Stream을 활용하는 보편적인 형태는 메서드 체이닝의 형태이다.
List<Member> members = new ArrayList<>();
List<String> soloMemberNmaes = members.stream()
.filter(Member::isSolo)
.map(Member::getName)
.collect(Collectors.toList());Member들중 솔로인 놈들 이름을 골라내는 코드다
위와 같이 Stream에 적용할 수 있는 연산은 연산의 결과로 스트림을 반환하는 중간 연산 과 스트림이 아닌 최종 결과물을 반환하는 최종 연산이 존재한다. 중간 연산은 최종 연산이 실행될 때 수행된다. 스트림의 반환한다는 것은 연산의 파이프라인을 반환한다는 의미로, 스트림은 lazy하여 매 중간
연산을 각기 실행하지 않는다. 대신 중간 연산마다 연산 파이프라인을 구축한 후, 최종 연산에
이르러서야 이전 중간 연산들을 모두 합쳐 최종 연산에 돌입한다. Stream은 이미 존재하는 컬렉션
내에서 새 스트림을 생성할 뿐, 기존 데이터를 수정하거나 바꾸지 않는다.
한편, 보편적으로 for-loop가 Stream보다 더 빠르다고 알려져 있는데 그렇다면 Stream을 왜
사용해야 하는 지에 관해 탐구해보자.
For-loop vs Stream
for-loop와 Stream을 비교하기 위해 길이 500_000의 int 타입 배열을 설정하고 순회 작업을
실행하며 수행 시간을 측정해보았다.
import java.util.Arrays;
import java.util.Random;
public class Solution {
public static void main(String[] args) {
int[] arr = generateArr();
long start = System.currentTimeMillis();
forLoop(arr);
long end = System.currentTimeMillis();
System.out.println((end - start) / 1_000.0);
start = System.currentTimeMillis();
forEach(arr);
end = System.currentTimeMillis();
System.out.println((end - start) / 1_000.0);
}
public static int[] generateArr() {
int[] arr = new int[500_000];
Arrays.fill(arr, new Random().nextInt());
return arr;
}
public static void forLoop(int[] arr) {
for (int i : arr) {
i++;
}
}
public static void forEach(int[] arr) {
Arrays.stream(arr).forEach(i -> i++);
}
}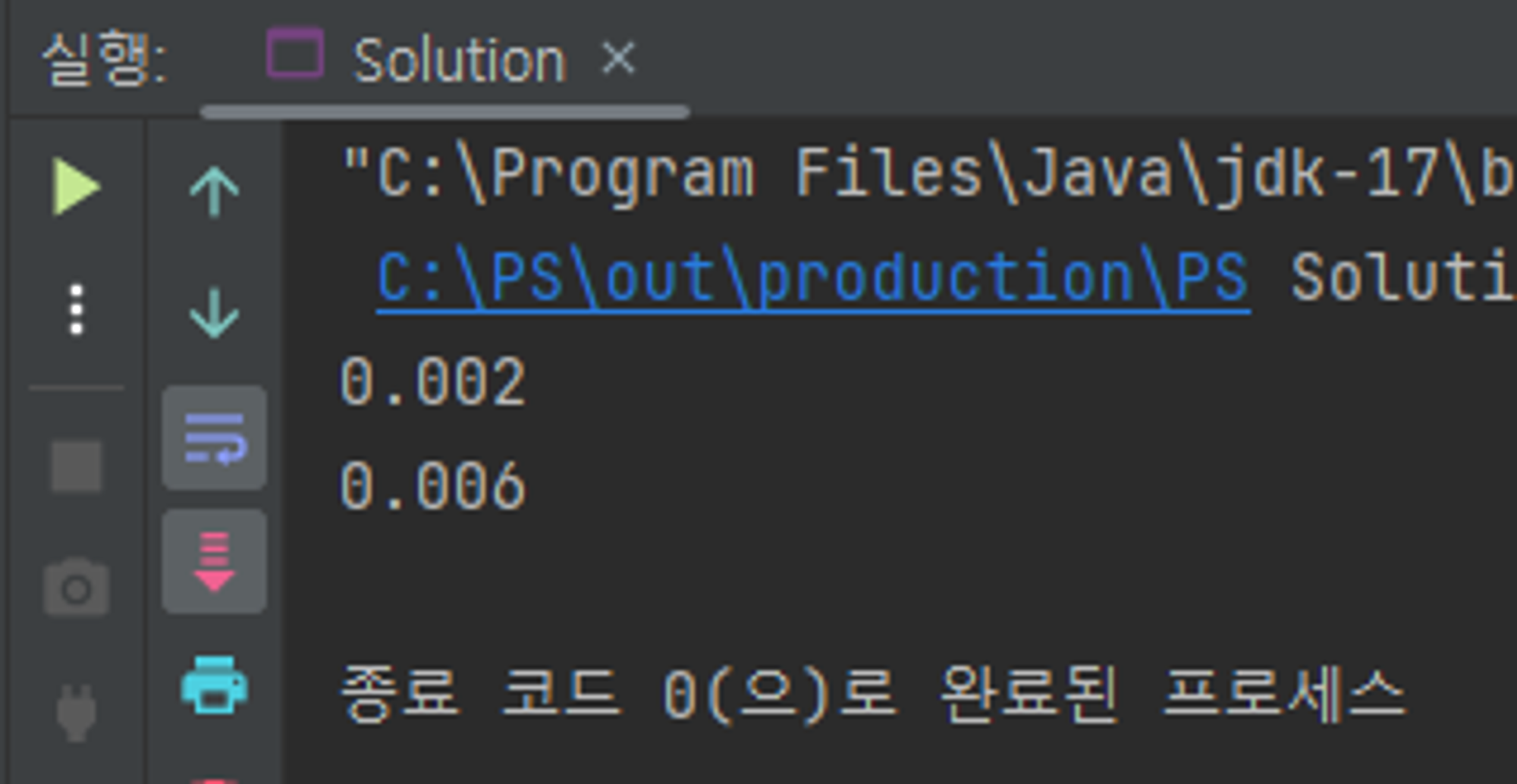
for-loop가 3배정도 빠른 것으로 측정된다. 이는 JIT Compiler가 for-loop를 40년 이상 다루다 보니 for-loop에 대한 최적화가 잘 되어있기 때문이라고 한다. 하지만 스트림은 2015년 이후에
도입되었다 보니 아직 최적화가 덜 진행되었다는 것이다.
다음 예시에서는 기본 타입이 아닌 레퍼런스 타입으로 실험을 진행해보자.
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class Solution {
public static void main(String[] args) {
List<Integer> list = generateList();
long start = System.currentTimeMillis();
forLoop(list);
long end = System.currentTimeMillis();
System.out.println((end - start) / 1_000.0);
start = System.currentTimeMillis();
forEach(list);
end = System.currentTimeMillis();
System.out.println((end - start) / 1_000.0);
}
public static List<Integer> generateList(){
List<Integer> list = new ArrayList<>();
for(int i=0; i<500_000; i++)
list.add(new Random().nextInt());
return list;
}
public static void forLoop(List<Integer> list){
for (Integer integer : list) {
integer++;
}
}
public static void forEach(List<Integer> list){
list.forEach(i->i++);
}
}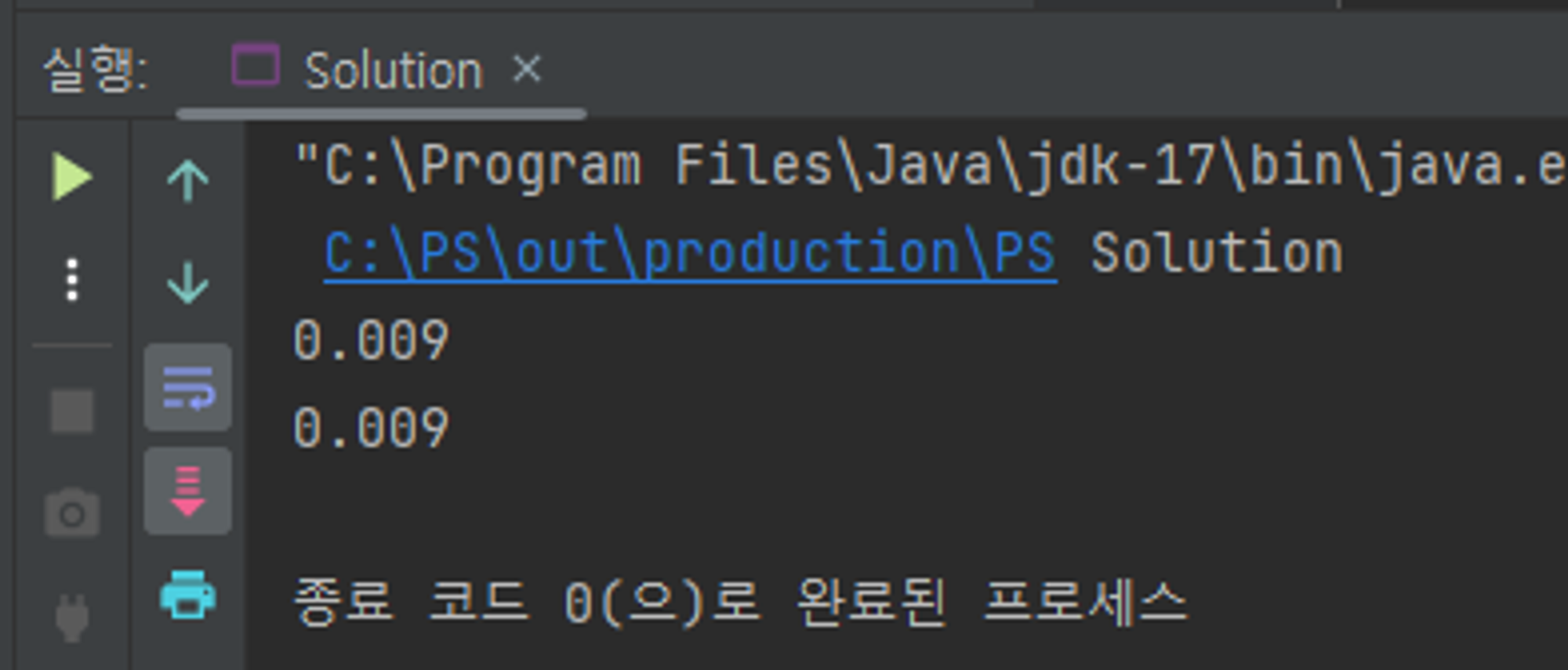
거의 수행 시간이 비슷해진다. 레퍼런스 타입(wrapper type을 포함한)의 경우 기본 타입과 달리
스택이 아닌 힙 영역에 저장되기 때문에, List를 순회하는 비용가 자체가 커서 두 순회 방식간 성능
차이를 압도해버린다.
JVM에서 스택에 있는 직접 참조의 경우 스택에 있는 변수가 실제 주소를 가지고 있지만 힙에
저장되는 간접 참조의 경우 그곳을 가리키는 중간 메모리 영역(핸들 메모리)가 있고 스택에 있는
변수가 핸들 메모리를 참조해서 실제 힙의 주소를 얻은 후 힙의 내용을 참조하게 되는 방식이다.
그러므로 자주 참조되는 변수의 경우 직접 참조 방식이 훨씬 뛰어난 성능이 보인다. 따라서
레퍼런스 타입의 경우 힙에 저장되어 간접 참조되기 때문에 순회비용 자체가 높아 for-loop의 최적화 이점이 사라지게 된다.
위 예제는 순회비용이 계산비용보다 높은 경우이다. 한편, 만약 순회 비용보다 원소 각각에 대한 계산 비용이 더 높다면 어떨까? 스트림 내부에 개발자가 복잡한 로직을 투입하여 계산 비용이 높다면?
// for-loop
int[] a = ints;
int e = a.length;
double m = Double.MIN_VALUE;
for (int i = 0; i < e; i++) {
double d = Sine.slowSin(a[i]);
if (d > m) m = d;
}
// sequential stream
Arrays.stream(ints).mapToDouble(Sine::slowSin).reduce(Double.MIN_VALUE, Math::max);위 코드에서 slowSin() 은 계산 비용이 굉장히 큰 함수라고 보면 된다.

코드의 수행 결과는 stream의 사용해도 for-loop에 비해 속도 손실이 없다는 것을 알려준다.
결론적으로 순회 비용과 계산 비용의 합이 충분히 클 때, 순차 스트림의 속도는 for-loop와
유사해진다고 볼 수 있다.
순차 스트림 vs 병렬 스트림
일반적으로 병렬 스트림은 순차 스트림보다 빠른 것으로 생각된다. 다만, 병렬 스트림은 순차
스트림과 다르게 공유 자원 이슈에 대해 고려해야 한다. Java의 멀티 스레드 구현체인 parellelStream() 은 thread-safe를 보장하지 않기 때문에 개발자가 별도의 처리를 해주어야 한다.
Java8부터 병렬 스트림을 위하여 parellelStream API를 제공하며, 스트림에 .parellel() 을
붙여주면, fork-join 을 바탕으로 하나의 스레드를 재귀적으로 특정 depth까지 반복하며 여러 개의 스레드로 잘게 나눈 뒤, 자식 스레드의 결과값을 취합해 최종 스레드의 결과값을 만들어 리턴하는
방식으로 구현되었다.
세부적인 병렬 스트릠의 작동은 아래 링크를 참고하자
이제 순차 스트림과 병렬 스트림의 성능을 확인해보자.
// sequential stream
int m = Arrays.stream(ints).reduce(Integer.MIN_VALUE, Math::max);
int m = myCollection.stream().reduce(Integer.MIN_VALUE, Math::max);
// parallel stream
int m = Arrays.stream(ints).parallel().reduce(Integer.MIN_VALUE, Math::max);
int m = myCollection.parallelStream().reduce(Integer.MIN_VALUE, Math::max);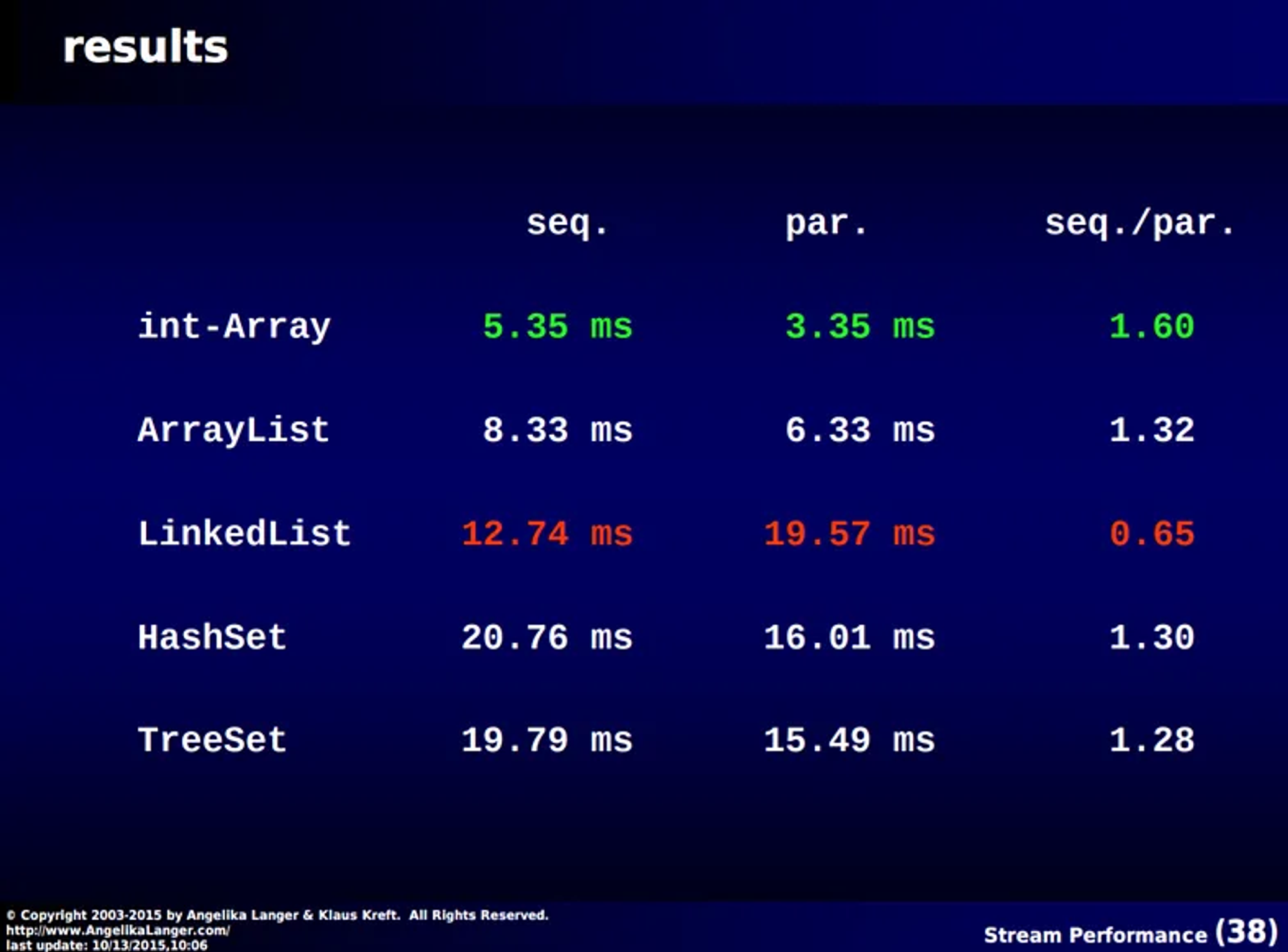
병렬 스트림이 순차 스트림보다 빠르지만, 그 차이가 극적이진 않다. 계산 비용이 작을 경우 스레드를 나누는 비용이 훨씬 비싸기 때문이다. 심지어 LinkedList 와 같이 작업을 split 하기 어려운 경우 순회 비용이 비싸 병렬 스트림이 더 느리게 측정되기도 한다. 이 예시는 계산 비용이 크지 않은 경우였으며, 연산 비용이 높은 경우를 살펴보자.
// for-loop
Arrays.stream(ints).parallel().mapToDouble(Sine::slowSin ) .reduce(Double.MIN_VALUE, (i, j) -> Math.max(i, j);
// collection
myCollection.parallelStream().mapToDouble(Sine::slowSin ) .reduce(Double.MIN_VALUE, (i, j) -> Math.max(i, j);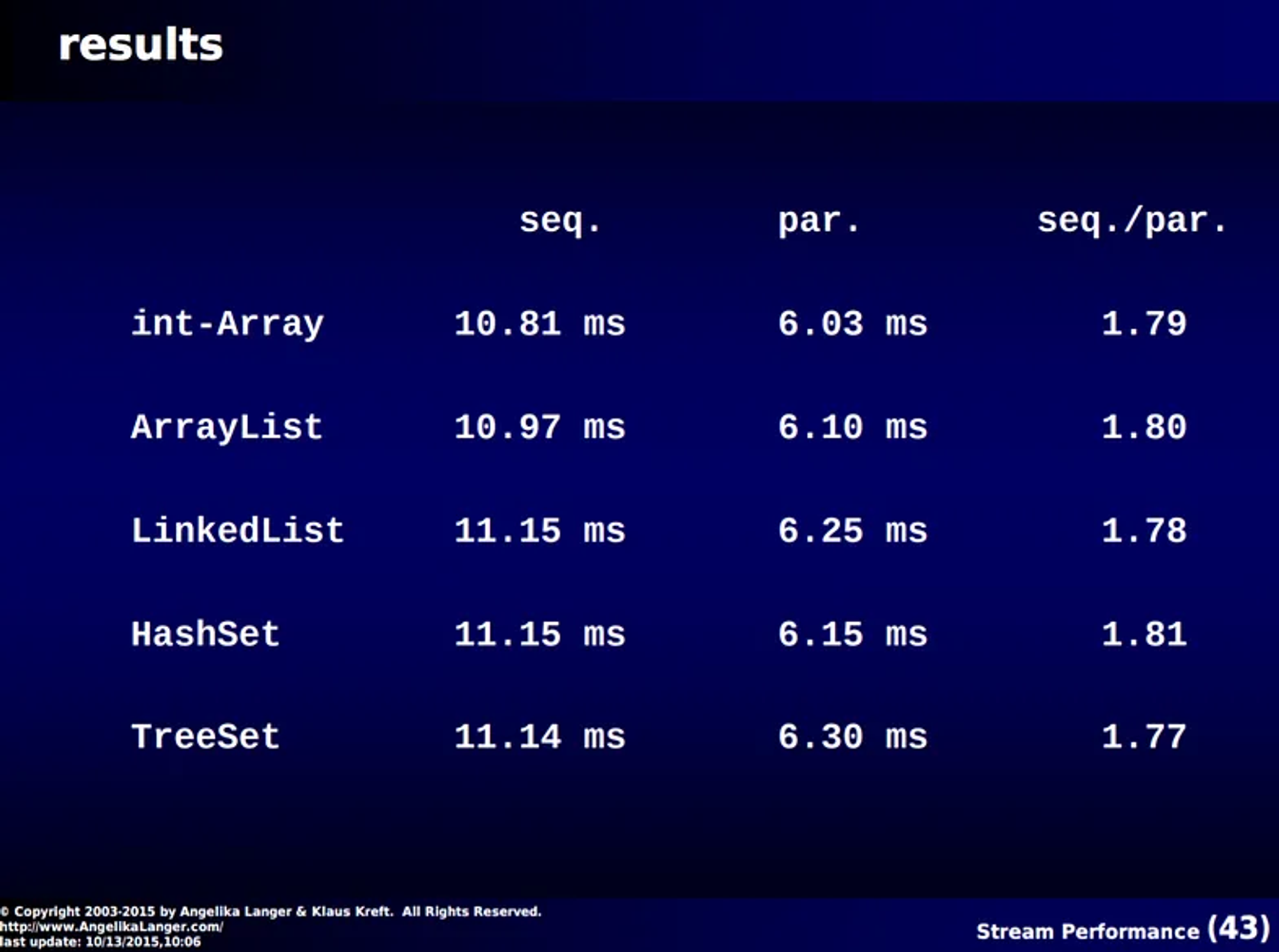
병렬 스트림이 순차 스트림보다 1.8배 빠른 것으로 측정된다. 차이가 얼마 안 나는 이유로는 병렬
알고리즘의 오버헤드 비용이나 병렬 스트림의 속도를 높일 수 있는 한계점을 생각해볼 수 있다.
정리하자면 병렬 스트림 처리가 의미 있으려면 데이터가 충분히 커야 한다. Collection 에 있는
원소 개수가 1000개는 있어야 한다. 컴퓨팅 연산 비용이 큰 경우에는 크기가 조금 더 작아도 된다고 한다.
Stateless Functionaltiy vs Stateful Functionality
만약 상태를 관리해야 하는 stateful이라면 어떨까? 각 스레드마다 참조해야 하는 변경 가능한 값 이존재하는 경우다. 다른 Pure Functional Language에서는 이런 경우 병렬 스트림을 지원하지 않는다.동기화 문제 등 큰 비용이 발생하기에 적합하지 않다는 판단떄문이다. 하지만 Java8에서는 지원한다.
이를테면 distinct() 같은 경우, 중복된 값을 추출하는 중간 연산인데 원소의 처리 상태를 매
작업마다 기록해야 정상 처리가 가능하다. stateful stream의 경우 상태를 저장하고 비교하는
오버헤드 비용이 발생하며, 이것을 barrier 또는 알고리즘적 오버헤드라고 부른다. 따라서 stateful한 경우에는 병렬 스트림의 속도 향상을 체감하기 어렵다. 게다가 멀티 스레드의 경우 반환되는 원소
순서가 보장되지 않으므로 별도의 ordering 처리도 필요하다. 순서가 중요할 경우, 정렬 비용도
고려해야 한다.
결론
스트림 사용이 for-loop보다 의미가 있으려면 Collection이 되는 스트림 소스의 크기가 충분히
크거나 컴퓨팅 연산이 CPU-intensive할 정도로 비용이 매우 비싸야 한다. 병렬 스트림을 사용하려면, 스트림 소스인 Collection이 split하기 쉬운 구조여야 하며, 왠만해서는 연산이 stateful하지 않아야
한다.
한편, 성능은 개발자의 작업 환경에 따라 상이할 수 있으므로, for-loop나 순차 스트림, 병렬 스트림 중 사용할 것을 고려할 때 미리 테스트해보는 지혜가 필요하다.
다만 개발자 간 매끄러운 협업을 위해 가독성이 중요하고, 이 점에서 스트림 사용은 탁월한 강점을 가진다. 이는 코드의 유지보수가 용이하다는 장점 또한 동반한다. 극단의 성능을 요구하는 특이
상황이 아니면 스트림의 도입은 상당히 많은 이점을 가진다.
참고
