
Classification 분류
: 학습 데이터로 주어진 데이터의 피처와 레이블 값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
<분류를 구현할 수 있는 머신러닝 알고리즘>
- 나이브 베이즈 Naive Bayes: 베이즈 통계와 생성 모델에 기반
- 로지스틱 회귀 Logistic Regression: 독립변수와 종속변수의 선형관계에 기반
- 결정 트리 Decision Tree: 데이터 균일도에 따름
- 서포트 벡터 머신 Support Vector Machine: 개별 클래스 간의 최대 분류 마진을 찾아줌
- 최소 근접 알고리즘 Nearest Neighbor: 근접 거리 기준
- 신경망 Neural Network: 심층 연결 기반
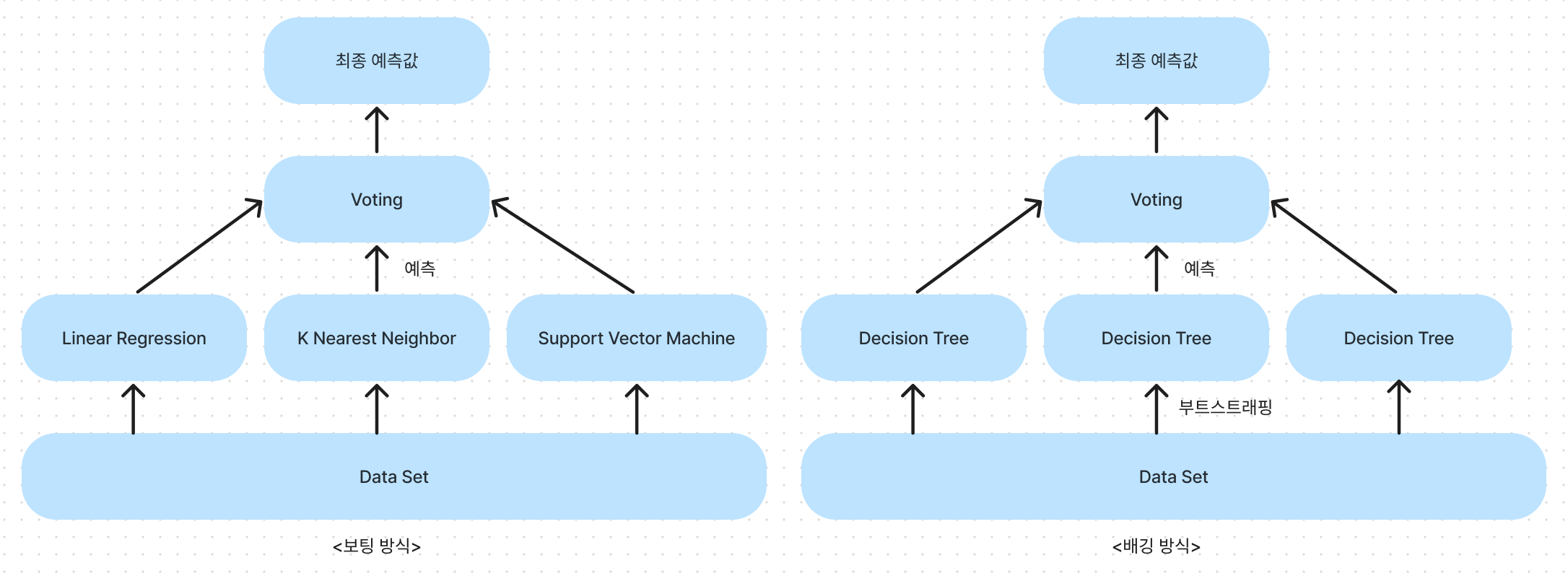
- 앙상블 Ensemble: 서로 같은(또는 다른) 머신러닝 알고리즘 결합
from sklearn.base import BaseEstimator
# : customized 형태의 Estimator를 개발자가 생성할 수 있다.2. 결정 트리 Decision Tree
: 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만든다.
→ (조건문) 따라서, 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘 성능을 좌우한다.
- 깊이(depth)가 깊어질 수록 예측 성능이 저하될 가능성이 커진다.
- 많은 규칙 존재 → 분류를 결정하는 방식이 복잡해진 것 → 과적합될 가능성 높음
- 데이터를 분류할 때 최대한 많은 데이터가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 한다.
(최대한 균일한 데이터세트를 구성할 수 있도록 분할 필요) - 결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만듦
- 정보 균일도를 측정하는 방법
- 정보이득 Information Gain
- 엔트로피 기반 : 주어진 데이터 집합의 혼잡도. 서로 다른 값이 섞여있으면 엔트로피 값 증가
- 정보이득 지수 = 1 - 엔트로피 지수
- 결정트리는 정보이득 지수로 분할. 즉, 정보이득이 높은 속성을 기준으로 분할
- 지니계수
- 0이 가장 평등하고 1로 갈수록 불평등
- 지니계수가 낮을수록 데이터터 균일도가 높은 것으로 해석. 지니계수가 낮은 속성을 기준으로 분할
- 그러면 정보이득 지수 같은 지표를 만들자면 = 1 - 지니계수 (?)
- 사이킷런 DecisionTreeClassifier은 기본으로 지니계수를 이용해 데이터 분할
from sklearn.tree import DecisionTreeClassifier
- 정보이득 Information Gain
결정 트리 모델의 특징
- 장점 : 정보의 ‘균일도’ 라는 룰을 기반으로 하고 있어 알고리즘이 직관적, 균일도만 신경쓰면 되므로 각 피처의 스케일링과 정규화 같은전처리 작업이 (일반적인 경우) 필요 없음
- 단점 : 과적합으로 (테스트) 정확도가 떨어짐 (트리가 계속 깊어질수록)
- (학습) 모델의 정확도를 높이기 위해 계속 조건을 추가하며 트리 깊이가 깊어지면, 테스트 정확도가 떨어질 것임
- 오히려 완벽한 규칙을 만들 수 없다고 먼저 인정하고, 트리의 크기를 사전에 제한하는 것이 오히려 성능 튜닝에 더 도움이 될 것
결정 트리의 파라미터
- 사이킷런 결정 트리 = DesicionTreeClassifier (for 분류) , DisicionTreeRegressor (for 회귀)
- 결정 트리 구현은 CART ( Classfication And Regression Trees ) 알고리즘 기반 ⇒ 분류뿐 아니라 회귀에서도 사용될 수 있음
- 하위의 파라미터는 동일함
min_samples_split- 노드를 분할하기 위한 최소한의 샘플 데이터 수
- 디폴트 = 2
- 작게 설정할 수록 분할되는 노드가 많아진다. (과적합 가능성 증가)
min_samples_leaf- 말단 노드(leaf)가 되기 위한 최소한의 샘플 데이터 수
- 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요
max_features- 최적의 분할을 위해 고려할 최대 피처 개수
- 디폴트 = None : 전체 피처 선정
- int 형으로 지정 : 대상 피처의 개수
- float 형으로 지정: 전체 피처 중 대상 피처의 퍼센트
- ‘sqrt’ : 만큼 선정 (=’auto’)
- ‘log’ : 만큼 선정
- ‘None’ : 전체 피처 선정
max_depth- 트리의 최대 깊이 규정
- 디폴트 = None : 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나, 노드가 가지는 데이터 갯수가 min_samples_split보다 작아질 대까지 계속 깊이를 증가시킴
- 깊이가 깊어지면 min_samples_split 설정대로 초대분할하여 과적합할 수 있으므로 적절한 값으로 제어 필요
max_leaf_nodes- 말단 노드의 최대 개수
결정 트리 모델의 시각화
from sklearn.tree import export_graphviz
export_graphviz(estimator, out_file='파일명', class_names=클래스 명칭,
feature_names=피처명칭, impurity=True, filled=True)# 위에서 생성한 파일을 graphviz가 읽어서 주피터 노트북 상에서 시각화
import graphviz
with open ('파일명') as f: dot_graph = f.read()graphviz.Source(dot_graph)- 시각화 결과의 구성들 :
- 조건 : 피처 조건이 있는 것은 자식 노드를 만들기 위한 조건 규칙, 이게 없으면 리프 노드
- gini(지니계수) : value=[ ] 로 주어진 데이터 분포에서의 지니 계수
- samples : 현 규칙에 해당하는(적용되는) 데이터 건수
- value=[ ] : 클래스 값 기반의 데이터 건수
- 색상 : 레이블 값, 선명도가 높을 수록 지니계수 낮음
feautre_importance_ 속성: ndarray로 반환, 피처 순서대로 값 할당, 값이 높을 수록 중요도 높음 :estimator.feature_importance_import seaborn as sns import numpy as np %matplotlib inline # feature importance 추출 print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3))) # feature별 importance 매핑 for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_): print('{0} : {1:.3f}'.format(name, value)) # feature importance를 column 별로 시각화 하기 sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)
- make_classification(): 분류를 위한 테스트용 데이터를 쉽게 만들 수 있다.
from sklearn.datasets import make_classification import matplotlib.pyplot as plt %matplotlib inline plt.title("3 Class values with 2 Features Sample data creation") # 2차원 시각화를 위해서 feature는 2개, 결정값 클래스는 3가지 유형의 classification 샘플 데이터 생성. X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2, n_classes=3, n_clusters_per_class=1,random_state=0) # plot 형태로 2개의 feature로 2차원 좌표 시각화, 각 클래스값은 다른 색깔로 표시됨. plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, cmap='rainbow', edgecolor='k') - 반환되는 객체: 피처 데이터 세트, 클래스 레이블 데이터 세트
- 예시: 피처 2개, 클래스 3가지 유형의 분류 샘플 데이터 생성
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2, n_classes=3, n_clusters_per_class=1, random_state=0)
- visualize_boundary(): 머신러닝 모델이 만든 결정 기준을 색상과 경계로 나타낸다.
visualize_boundary(estimator, X_features, y_labels)
mios의 데이터 놀이터 | Instagram@data.decision (하단 홈 아이콘 버튼)