Redis에 대해 간략하게 알아보자
- In-Memory Data Structure Store
- 데이터가 메모리가 저장되기에 일반적으로 쓰고 있는 DISK I/O를 요하는 DB보다 훨씬 빠르게 데이터를 다룰 수 있다.
-
Open Source(BSD3 License)
- 수정과 배포가 자유롭다. -
지원하는 자료 구조
- Redis Collections : Strings, set, sorted-set, hashes, list
- Hyperloglog, bitmap, getspatial Index
- Stream -
Only 1 Committer
- Redis는 Single Thread 기반으로 동작하기에 Atomicity를 보장한다고 한다.
Sorted set에 대해서 알아보자
redis collection 중 string, set, hash, list 등은 어느 정도 알고 있다고 가정한다.
sorted set은 자료의 중복을 허용하지 않는 set의 형태를 지님과 동시에 정렬되어 있다는 특성이 있다. sorted set은 redis를 사용하는 개발자에게 특히나 자주 사용되는 녀석이다.
기본 사용법으로는 다음과 같다.
-
ZADD <KEY><SCORE> <VALUE>
- Value가 이미 key에 있으면 해당 Score로 변경된다. -
ZRANGE <KEY> <StartIndex> <EndIndex>
- 해당 Index 범위 값을 모두 조회한다.
-Zrange testkey 0 -1: 모든 범위를 가져온다. -
유저 랭킹 보드로 사용할 수 있다.
-
Sorted set의 score는 정수형이 아닌 double(실수) 타입이기 때문에, 값이 정확하지 않을 수 있다. (
실수를 할 수 있다) -> 컴퓨터에는 실수가 표현할 수 없는 정수값들이 존재한다.
정렬이 필요한 값이 필요하거나, Score 기준으로 뽑을 수도 있다. 자세한 사용법으로는 찾아보자...🙇♂️
Cache
- 무거운 연산 결과나 자주 참조되는 데이터를 사용자에게 빨리 제공하기 위한 임시 장소
Cache의 Write Through와 Write back에 대해 간단하게 짚고 넘어가자.
Write Through는 데이터를 캐시에 저장함과 동시에 memory 혹은 disk에 동시에 update하는 방식이며, 데이터의 일관성을 유지할 수 있다는 장점이 있다.
하지만, 속도가 느린 memory 혹은 disk에 데이터를 기록할 때, CPU가 대기하는 시간이 필요하기에 성능이 떨어진다.
Write back은 캐시로부터 해제되는 때(캐시안에 있는 내용을 버릴시) 에만 memory 혹은 disk에 기록되는 방식이다. write through보다 훨씬 빠르다는 장점이 있지만, 데이터의 일관성을 항상 보장 못한다.
왜 Collection이 중요한가?
개발의 편의성이 상승하고 개발의 난이도가 낮아진다.
-
개발의 편의성
- 예를 들어, 랭킹 서버를 구현한다고 해보자. 기존 관계형 데이터베이스를 사용할 경우, DB에 유저의 Score를 저장하고, Score를 order by를 사용하여 정렬 후 읽어올 것이다.
- 개수가 많아진다면 결국 속도가 느린 디스크 I/O가 일어나기에 퍼포먼스에 영향을 주게 될 것이다.
- In-Memory DB를 이용한다면 조금 더 쉽게 만들 수 있다.
- Redis의 Sorted Set을 이용하면, 랭킹을 구현 할 수 있다.- 덤으로, Replication도 가능하다.
- 다만, 가져다 쓴다면 거기의 한계에 종속적이게 된다.
- 랭킹에 저장해야 할 id가 1개당 100byte라고 할 때, 10명이면 1K, 10,000명이면 1M, 10,000,000이라면 1G...
-
개발의 난이도
Redis는 자료구조가 Atomic 하기 때문에, Race Condition을 피할 수 있으나, 잘못 짤 경우 에러가 발생할 수도 있다.
외부의 Collection을 잘 이용하는 것으로 여러가지 개발 시간을 단축시키고 문제를 줄여줄 수 있기 때문에 Collection이 중요하다.
Collections 사용시 주의 사항
-
하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다.
- 10000개 이하의 몇천개 수준으로 유지하는게 좋다. -
Expire는 Collection의 Item 개별로 걸리지 않고 전체 collection에 대해서만 걸린다.
- 즉 해당 10000개의 아이템을 가진 collection에 expire가 걸려있다면 그 시간 후에 10000개의 아이템이 모두 삭제된다.
- 개별로 걸 수 있는 방법도 존재하지만, 효율상 좋지 못하다고 한다.
Redis를 사용하는 곳
-
Remote Data Store
- 서버 A, 서버 B, 서버 C에서 데이터를 공유하고 싶을 때 -
한 대에서만 필요하다면, 전역 변수를 쓰면 되지 않을까?
- Redis 자체가 싱글 스레드이기에 Atomic을 보장해준다.
-
주로 많이 쓰는 곳들
- 인증 토큰 등을 저장(Strings 또는 hash)
- Ranking 보드로 사용(Sorted Set)
- 유저 API Limit
- 잡 큐(list)
Redis 운영
1. 메모리 관리를 잘해야 한다.
Redis는 In-Memory Data Store이다. 이에 유의하여 읽어보자.
-
Physical Memory 이상을 사용하면 문제가 발생한다.
- 예를 들어, Swap이 있다면 Swap 사용으로 해당 메모리 Page 접근시 마다 늦어진다. Swap이 한번 이상이라도 일어난 page는 지속적으로 swap이 일어난다.
- 즉, In-memory의 장점을 살리지 못하고 disk i/o가 지속적으로 일어나는 것이다. -
Maxmemory를 설정하더라도 이보다 더 사용할 가능성이 크다.
- jemalloc에 대해서 알아두자. -
RSS 값을 모니터링 해야한다.
RSS?
RSS(Really Simple Syndication, Rich Site Summary)란 블로그처럼 컨텐츠 업데이트가 자주 일어나는 웹사이트에서, 업데이트된 정보를 쉽게 구독자들에게 제공하기 위해 XML을 기초로 만들어진 데이터 형식
-
많은 업체가 현재 메모리를 사용해서 Swap을 쓰고 있다는 것을 모를 때가 많다.
-
큰 메모리를 사용하는 instance 하나보다는 적은 메모리를 사용하는 instance 여러 개가 안전하다.
- 예를 들어, 24GB의 instance를 하나 사용하는 것보다 8GB Instance를 3개 사용하는 것이 낫다.
- read 연산에는 문제가 없지만, write가 무거울 경우 메모리를 더 사용 할 경우가 있다. -
다양한 사이즈를 가지는 데이터 보다는 유사한 크기의 데이터를 가지는 경우가 더욱 유리하다.
- 메모리가 부족할 때는?
- 좀 더 메모리가 많은 장비로 Migration 해야한다. 메모리가 빡빡하다면 Migration 중에 문제가 발생할 수도 있다.
- 기존 데이터를 줄여야 한다.
- 데이터를 일정 수준에서만 사용하도록 특정 데이터를 줄여야 한다.
- 다만 이미 Swap을 사용중이라면, 프로세스를 재시작해야한다.
- 메모리를 줄이기 위한 설정
기본적으로 Collection 들은 다음과 같은 자료구조를 사용한다.
- Hash -> HashTable을 하나 더 사용
- Sorted set -> skiplist와 hashtable을 이용한다.
- set -> hashtable을 사용
- 해당 자료구조들은 메모리를 많이 사용한다.
Ziplist를 이용해야 한다.
- Ziplist?
- Ziplist 구조
- 데이터를 선형으로 저장하는 구조이다.
- In-Memory 특성 상, 적은 개수라면 선형 탐색을 하더라도 빠르다.
- redis는 List, hash, sorted set 등을 ziplist로 대체해서 처리를 하는 설정이 존재한다.
2. O(N) 관련 명령어는 주의하자
Redis는 single thread이다. 즉, 한번에 하나의 명령을 수행한다는 것인데, packet으로 하나의 command가 완성되면 processCommand에서 실제로 실행된다.
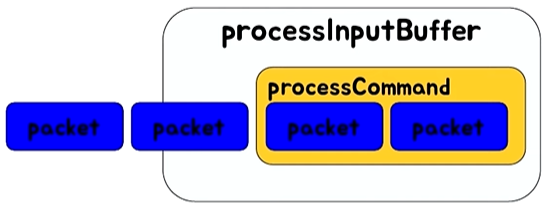
그렇다면, Redis가 동시에 여러 개의 명령이나 긴 시간이 필요한 명령을 처리할 수 있을까? 참고로 단순한 get/set의 경우, 이는 CPU 속도에향을 받기에 초당 10만 TPS(transaction per second) 이상이 가능하다고 한다.
정답으로는, 사용할 수는 있지만 지양한다고 한다. 대표적인 O(N) 명령어들은 다음과 같다.
- KEYS
- FLUSHALL, FLUSHDB
- Delete Collections
- Get All Collections
대표적인 실수 사례로는 다음과 같다.
-
Key가 백만개 이상인데 확인을 위해 KEYS 명령을 사용하는 경우
- KEYS는 한번에 모든 데이터를 다 가져온다.
- scan 명령을 권장한다. scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러번의 명령으로 바꿀 수 있다. -
아이템이 몇 만개 든 hash, sorted set, set에서 모든 데이터를 가져오는 경우
- Sorted set을 이용하여 Collection의 일부만 가져오거나, 큰 Collection을 작은 여러 개의 Collection으로 나눠서 관리해야 한다.
- 예전의 Spring security oauth RedisTokenStore (현재 버전에서는 문제가 없다고 한다.)
3. Replication
복제를 의미하는 Replication은 master server와 slave server를 필요로 한다. 여기서 master server는 주로 read/write 용이고, slave server는 master의 데이터를 미러링 하는 read 전용이다.
서비스를 제공하던 master server가 다운되더라도, slave server에서 서비스를 계속해서 진행할 수 있다. (failover)
redis replication은 async replication으로 replication lag이 발생할 수 있다.
DBMS로 보면 statement replication과 유사하다.
Redis replication 설정 과정
- slave서버에는
replicaoforslaveof명령을 전달한다. - slave서버는 master서버에 sync 명령을 전달한다.
- master서버는 현재 메모리 상태를 저장하기 위해 fork한다.
- fork한 프로세서는 현재 메모리 정보를 disk에 dump한다.
- 해당 정보를 slave에 전달한다.
- fork 이후의 데이터를 계속 slave에 전달한다.
redis replication 시 주의할 점
- replication 과정에서 fork가 발생하므로 메모리 부족이 발생할 수 있다.
redis-cli --rdb명령은 현재 상태의 메모리 스냅샷을 가져오므로 메모리 부족이 발생한다.- aws나 클라우드의 redis는 다르게 구현되어서 위의 부분들이 더 안정적이다. 즉 fork 없이 replication을 지원하도록 구현되어있다.
- 많은 대수의 redis 서버가 replica를 두고 있다면?
- 네트워크 이슈나, 사람의 작업으로 동시에 replication이 재시도 되도록 하면 문제가 발생할 수 있음
- ex) 같은 네트워크 안에서 30GB를 쓰는 redis master 100대 정도가 replication을 동시에 재시작하면 어떤 일이 벌어질까?
4. 권장 설정 TIP
- maxclient 설정 50000
- RDB(Redis Database) / AOF(Append Only File) 설정 off
- 특정 commands disable
- Keys
- AWS의 ElasticCache는 이미 하고 있음 - 전체 장애의 90% 이상이 KEYS와 SAVE 설정을 사용해서 발생 -> 적절한 ziplist 설정
Redis 데이터 분산
데이터의 특성에 따라서 선택할 수 있는 방법이 달라진다.
Cache일 때는 이상적인 Redis이지만, 저장하는 데이터가 영속적이라면 효율성이 좋지 않은 redis가 된다.
Redis as Cache
- Cache일 경우에는 문제가 적게 발생한다.
- Redis가 문제가 있을 때 DB등의 부하가 어느정도 증가하는지 확인이 필요하다
- 안정 해시(consistent hashing)도 실제 부하를 아주 균등하게 나누지는 않는다. Adaptive Consistent hashing을 이용해 볼 수도 있다.
Redis as Persistent Store
- 무조건 Primary/Secondary(Master/Slave) 구조로 구성이 필요하다.
- 메모리를 절대로 빡빡하게 쓰면 안된다.
- 정기적인 migration이 필요하며, 가능하면 자동화 툴을 만들어서 이용해야 한다. - RDB/AOF가 필요하다면 secondary에서만 구동한다.
데이터 분산 방법
Application에서 나눌 것이냐 Redis Cluster에서 나눌 것이냐에 따라 다르다.
Application
Consistent Hashing(안정 해시)
Sharding
Redis Cluster
Redis Cluster는 Hash 기반으로 16384개의 Slot으로 구분된다.
- hash 알고리즘은 CRC16을 사용한다.
- slot = crc16(key) % 16384
- key가 key{hashKey} 패턴이면 실제 crc16에 hashkey가 사용된다.
- redis cluster는 기본적으로 최소 3개의 노드가 필요하다.
- 특정 redis 서버는 이 slot range를 가지고 있고, 데이터 migration은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다. (migrateCommand 이용)
Redis Cluster pros/cons
-
장점
- 자체적인 Primary, Secondary Failover
- Slot 단위의 데이터 관리 -
단점
- 메모리 사용량이 더 많음
- Migration 자체는 관리자가 시점을 결정해야 함
- Library 구현이 필요함
Redis Failover
Redis에서 장애를 극복하는 방법들은 다음과 같다.
- Coordinator 기반 Failover
- VIP(Virtual IP) / DNS 기반 Failover
- Redis Cluster 사용
자세한 동작 방법은 찾아보자...!
Coordinator 기반 Failover
Coordinator 기반으로 설정을 관리한다면 동일한 방식으로 관리가 가능하며, 해당 기능을 이용하도록 개발이 필요하다.
Zookeeper, etcd, consul 등의 Coordinator을 사용한다.
VIP/DNS 기반 Failover
특징은 다음과 같다.
- 클라이언트에 추가적인 구현이 필요없다.
- VIP 기반은 외부로 서비스를 제공해야 하는 클라우드 업체와 같은 서비스 업자에 유리하다
- DNS 기반은 DNS Cache TTL을 관리해야 한다.
- 사용하는 언어별 DNS 캐싱 정책을 잘 알아야 한다.
- 툴에 따라서 한번 가져온 DNS 정보를 다시 호출 하지 않는 경우도 존재한다.
TTL(Time to live)
TTL은 다음 레코드 변경사항이 적용될 때까지 걸리는 시간(초)을 결정하는 DNS 레코드 값입니다.
REF.
