Kafka란
보다 큰 규모의 데이터를 모으고, 처리하고, 저장하고 받아서 전달하는 이벤트 스트리밍 플랫폼.
데이터를 받아서 전달하는 데이터 버스 역할을 한다. 즉, 대량의 데이터를 분산 관리해주는 미들웨어이다.
이벤트 스트리밍 : ???
데이터 스트리밍 : ???
미들웨어 : 운영 체제에서 제공하지 않는 일반적인 서비스와 기능을 애플리케이션에 제공하는 소프트웨어.
이벤트 : 소프트웨어 또는 응용 프로그램에서 식별하거나 기록 하는 모든 유형의 작업, 사건 또는 변경 사항.
핵심 개념
높은 처리량, 빠른 응답 속도, 안정성
카프카를 사용하는 대표적인 이유는 위의 세 가지를 보장해주기 때문이다.
이를 보장해주는 구체적인 카프카의 핵심 개념은 아래와 같다.
- 분산 시스템 : 네트워크 상에서 연결된 컴퓨터들의 그룹. 높은 성능을 낼 수 있으며 장애 대응과 시스템 확장에 용이함.
- 페이지 캐시 : OS의 페이지 캐시를 활용하여 처리량을 높인다.
- 배치전송처리 : 네트워크 오버헤드를 줄이고 빠르고 효율적인 처리를 가능하게 함.
- 압축 전송 : 배치전송과 같이 하여 효율성을 극대화 시킬 수 있다.
- 고가용성 보장 : 파티션의 복제를 통하여 고가용성을 보장한다. 이를 위한 리플리케이션 기능을 제공함.
- 주키퍼 의존성 : 여러 대의 서버를 앙상블(클러스터)로 구성하고, 살아있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능하다. 이를 위해 반드시 홀수로 구성되어야 한다. znode를 이용해 카프카 메타 정보가 주키퍼에 기록된다. 브로커 노드, 토픽, 컨트롤러를 관리한다. 메타데이터 저장소라고 보면 된다. 카프카를 어려워 하는 이유 중 하나는 주키퍼 때문일 것인데...v3.0부터는 브로커와 통합된다고 한다. 하지만 아직 운영환경에 사용하기엔 무리가 있는 듯 하다.
- Topic : 이메일에서 주소 정도의 개념.
- Partition : 토픽은 병렬 처리를 위해 파티션으로 나뉜다.
- Offset : 파티션의 메시지가 저장되는 위치이다. 숫차적으로 증가하는 64비트의 고유한 정수. 오프셋을 통해 메시지의 순서를 보장하며, 컨슈머에서는 마지막 읽은 위치를 알 수 있다. 여기서 메시지의 순서를 보장한다라는건 같은 파티션 내에서의 순서를 보장한다는 뜻이다.
특징
Kafka의 핵심 개념과 연관 되며, 이는 곧 기업에서 사용할만한 충분한 이유가 된다.
1. 높은 처리량과 낮은 지연율
2. 높은 확장성
3. 고가용성
4. 내구성
5. 개발 편의성
6. 운영 및 관리 편의성
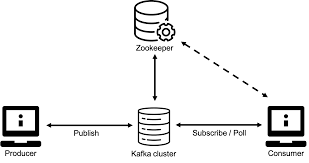
기본 구조
프로듀서 -> 카프카(Broker) -> 컨슈머
이와 같은 흐름을 가진다. 화살표는 메시지가 흐르는 방향.
주키퍼는 카프카의 정상 동작을 보장하기 위해 메타데이터를 관리하는 코디네이터이다.
클러스터는 브로커로 구성 되며, 브로커 안에는 토픽이 존재한다.
토픽은 파티션으로 구성된다. 파티션은 세그먼트 형태로 파티션에 저장된다. xxx.log와 같은 파일로 hexdump에 저장된다.
linux 명령어인 xxd를 이용하여 파일을 볼 수 있다. 저장 경로는 브로커 속성 중 하나인 log.dirs이다.
즉, 프로듀서에 의해 브로커로 전송된 메시지는 토픽의 파티션에 저장되며, 각 메시지들은 세그먼트라는 로그 파일 형태로 브로커의 로컬 디스크에 저장된다.
Apache Kafka vs Conluent Kafka
https://www.knowledgenile.com/blogs/confluent-kafka-vs-apache-kafka/
출처) 실전 카프카 개발부터 운영까지 (고승범 저)
