RDB 를 사용하다 보면 중복된 데이터들을 많이 마주할 수 있다. 이는 보기에 지저분할뿐만 아니라 이상현상 (Anomaly) 를 일으킬 수도 있으니 필히 제거해주어야 한다.
anomaly? → Modification Anomaly(갱신이상)
→ Insertion Anomaly (삽입이상)
→ Deletion Anomaly (삭제이상)
overview
- 1차 정규형 ⇒ 속성 하나는 하나의 속성값을 가져야한다. → 이를 위해 제 1 정규화 실시.
- 2차 정규형 ⇒ 기본키중에 특정 칼럼에만 종속된 칼럼이 있으면 안된다. → 이를 위해 제 2 정규화 실시.
- 3차 정규형 ⇒ 2차 정규형을 만족할때, 이행함수 종속성이 있으면 안된다. → 이를 위해 제 3차 정규화 실시.
- 종속성 ex) X Y Z A B 의 칼럼이 있다 가정하자.
- 완전함수 종속 ⇒ X 가 Y,Z,A,B 에 대해 모두 종속성을 가지고 있는것. 따라서 Y,Z,A,B는 각각 종속성을 가지지 않고, X 에만 종속되어 있는것이다.
- 부분함수 종속 ⇒ 만약 X,Y 가 둘이 합쳐 기본키가 되는 복합키라고 하자. 여기서 완전함수 종속이라면 Z,A,B 가 (X,Y) 에 종속되어야 하지만 만약 Z 는 X 에만 종속되는 그런 경우를 부분함수 종속이라 한다.
- 이행함수 종속 ⇒ X→Y, Y→Z 의 종속성을 가지고있는것이라 보면 된다. (X 를 보고 Z 를 알 수 있을때)
1차 정규형
속성을 분리하는 작업…
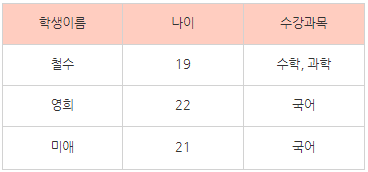
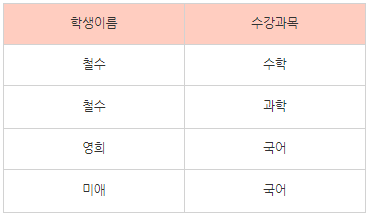
이 표를 보자. 철수는 수학과 과학을 수강한다. 하지만 이러한 정보를 이런식으로 저장하게 되면 나중에 검색을 할때 where 수강과목 = “수학” 이런식이 아닌, where 수강과목 like “%수학%” 처럼 찾아야하기 때문에 불필요한 오버헤드가 발생하게 된다.
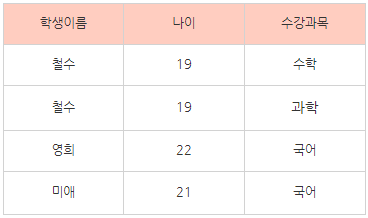
그래서 이렇게 각각의 속성을 분리해서 관리하게 된다 (원자값을 갖게 한다). 이를 1차 정규형이라고 한다.
2차 정규형 → 부분함수 종속 제거
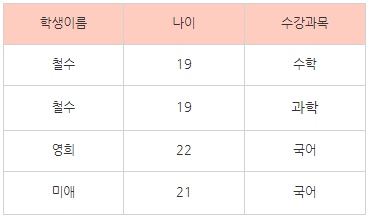
1차 정규형이 적용된 테이블을 보자. 여기서 “철수”가 데이터의 키라고 할 수 있나? 아니다.
이 테이블은 하나의 칼럼이 키의 역할을 할 수 없어서 컴포지트 키 (Composite key) 를 사용해야 한다. 이경우에는 (학생이름, 수강과목) 을 키로 사용할 수 있을것이다. 제 2정규화는 이 컴포지트키를 종속하는 칼럼들의 부분함수 종속을 제거하는 것이다.
하지만 철수의 나이는 수강과목과는 관계없이 19로 알 수있다. 나이를 찾기 위해 굳이 2개의 키를 사용할 필요는 또 있을까? 이렇게 특정 칼럼에만 종속된 칼럼이 있는것은 2차 정규형에 위반된다 (이름 - 나이)
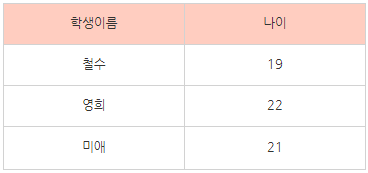
이처럼 분리한다면
특정 칼럼에만 종속되어있는 “나이” 칼럼을 분리할 수있다.
3차 정규형 → 이행함수 종속 제거
3차 정규형은 2차 정규화가 완료된 데이터베이스에서 이행함수 종속을 제거하는것이다. 아래 그림을 보자.
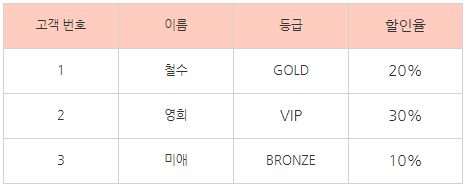
여기서 할인율은 사실 등급에 종속된다 (Y→Z) 하지만 각 등급은 고객번호에 종속되어 있다 (X → Y) 그래서 결론적으로 고객번호에 할인율이 종속되어버리는 요상한 상황이 생긴다. (X → Z)
이러한 현상을 제거하기위해 이행함수 종속성을 제거해준다.
각각의 X → Y , Y → 를 각각의 테이블로 구분해보자.
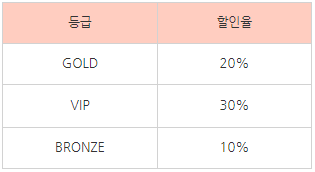
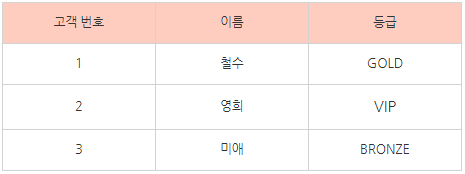
이렇게 분리를 한다면 고객번호에 등급이 종속되고, 할인율은 등급에만 종속되는, 이행함수 종속이 없는 데이터베이스를 만들 수 있다.
