프로그램의 실행 순서
사용자가 프로그램의 실행을 요청하면 운영체제(OS)는 보조기억장치(HDD, SDD 등)로부터 해당 프로그램의 정보를 읽어 주기억장치(메모리)에 로드한다. 그리고 CPU는 프로그램 코드로 메모리를 관리하고 메모리에 로드된 명령문을 실행한다.
메모리는 크게 커널(Kernel) 영역과 유저(User) 영역으로 나뉘며, 커널 영역에는 운영체제가 적재된다. 따라서 사용자가 실행하는 프로그램 등은 일반 프로세스로서 유저 영역에 적재된다. 그리고 유저 영역의 프로세스 메모리 구조는 다시 몇 가지 구조로 나뉘어진다.
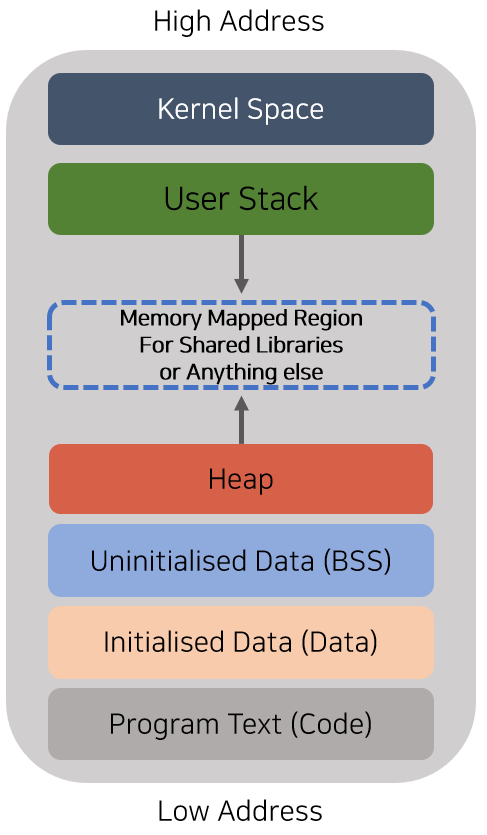
프로세스 메모리의 구조
프로세스의 주소 공간은 크게 Code, data, heap, stack 네 가지 영역으로 이루어져 있으며, 순서대로 낮은 메모리 주소부터 높은 메모리 주소 순으로 배정된다. 단, Stack 영역은 유일하게 높은 메모리 주소부터 낮은 메모리 주소 순으로 쌓여 나간다.
코드(Code) 영역
- 실제 소스 코드를 CPU가 실행할 수 있는 형태(기계어)로 변환하여 저장하는 공간
- 컴파일 시 영역의 크기가 결정되며, 수정할 수 없도록 Read-only의 형태를 띤다.
- CPU의 Program counter에 저장된 주소가 바로 이 영역의 주소에 해당한다.
데이터(Data) 영역
- 전역 변수나 Static 변수 등 프로그램에 사용되는 데이터가 저장되는 공간
- 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸된다.
- 전역 변수 값은 변경 가능하므로 Read-Write의 형태로 만들어진다.
- BSS와 GVAR 영역으로 나누어지는데, BSS 영역에는 초기화되지 않은 데이터가, GVAR 영역에는 초기화된 데이터가 저장된다.
힙(Heap) 영역
- 사용자가 생성한 객체들이 저장되는 공간
- 사용자에 의해 동적으로 공간이 할당되고 해제되며, 따라서 사용자가 직접 관리할 수 있는(또한 관리해야 하는) 영역이다.
- 런타임에 의해 크기가 결정된다.
- 메모리의 낮은 주소로부터 높은 주소의 방향으로 할당되며, 따라서 FIFO 방식으로 동작한다.
스택(Stack) 영역
- 함수의 호출과 관계되는 지역변수와 매개변수가 저장되는 공간
- 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸된다.
- LIFO 방식으로서 푸시(Push)로 데이터를 저장하고 팝(Pop)으로 데이터를 인출한다.
- 메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
힙 영역과 스택 영역
장단점
| 스택 영역 | 힙 영역 | |
|---|---|---|
| 장점 | 데이터 액세스가 빠르다. 변수를 사용자가 관리하지 않아도 된다. 하나의 명령으로 메모리 조작과 어드레스 조작이 가능하다. OS가 직접 메모리를 관리하기 때문에 메모리 단편화에 대한 걱정이 없다. | 변수를 전역적으로 액세스할 수 있다. 메모리 크기에 제한이 없다. 객체의 개수나 크기를 알 수 없어도 사용 가능하다. |
| 단점 | 지역변수만 저장된다. 스택 크기가 제한되어 있다. 변수의 크기를 조정할 수 없다. | 상대적으로 데이터 액세스가 느리다. 메모리를 직접 관리해야 한다. |
오버플로우(Overflow)
힙 영역과 스택 영역은 사실상 동일한 공간을 사용하며, 따라서 스택 영역이 클수록 힙 영역이 작아지고, 반대로 힙 영역이 커지면 스택 영역이 작아진다.
이때 스택 영역은 높은 주소에서 낮은 주소 순으로, 힙 영역은 낮은 주소에서 높은 주소 순으로 주소가 할당되므로 자신의 영역이 상대의 영역을 침범하는 경우가 발생할 수도 있다. 이를 각각 스택 오버플로우, 힙 오버플로우라고 한다.
참고 자료

AI, NLP, Data analysis로 나아가고자 하는 개발자 지망생