Search service
검색 서비스는 사용자가 입력한 검색어에 대한 검색 결과를 제공하는 서비스로, 검색 엔진, 검색 시스템, 검색 서비스 등의 용어로 불린다. 일반적으로 혼용되는 경향이 있으나, 엄밀하게는 조금씩 차이가 있는 개념이므로 간단히 정리하고 넘어가자.
검색 엔진(Search engine)
- 웹에서 정보를 수집해 검색 결과를 제공하는 프로그램
- 검색 결과로 제공되는 데이터의 특성에 따라 구현 형태가 달라짐
검색 시스템(Search system)
- 대용량 데이터를 기반으로 신뢰성 있는 검색 결과를 제공하기 위하여 검색 엔진을 기반으로 구축된 시스템
- 수집기를 이용하여 방대한 데이터를 수집하고, 이를 다수의 검색 엔진을 이용해 색인한 뒤 검색 결과를 UI로 제공
- 시스템 내부 정책을 통해 관련도가 높은 문서를 상위에 배치하거나, 특정 필드 혹은 문서에 가중치를 두어 검색 정확도를 제고할 수 있음
검색 서비스(Search service)
- 검색 엔진을 기반으로 구축한 검색 시스템을 활용하여 검색 결과를 제공하는 서비스
Components of Search system
- 수집기
- 웹 사이트, 블로그, 카페 등 웹에서 필요한 정보를 수집하는 프로그램
- 크롤러 혹은 스파이더 등으로도 불림
- 파일, 데이터베이스 등 대부분의 정보를 수집 대상으로 함
- 색인기
- 수집한 데이터를 검색에 적절한 형태로 변환하는 역할
- 다양한 형태소 분석기를 조합해 정보에서 유의미한 용어를 추출하고, 이를 검색에 유리한 역색인 구조로 변환함
- 스토리지
- 수집하여 색인한 정보를 저장하는 물리적 저장소
- 검색기
- 사용자의 질의를 입력받아 색인기에서 저장한 역색인 구조로부터 일치하는 문서를 찾아 결과로 반환하는 역할
- 질의와 문서의 일치 여부는 유사도 기반의 검색 순위 알고리즘을 사용하여 판단함

Elastic Search
Lucene & Elastic Search
루씬(Lucene)은 모든 검색 엔진의 시초라고 할 수 있는 라이브러리로서, 더그 커팅이 고안한 역색인(Inverted index) 구조를 지닌다. 이 루씬을 기반으로 분산 처리를 가능케 한 아파치 솔라(Solr)가 검색 엔진 시장을 장악했었고, 몇 년 후 마찬가지로 루씬을 기반으로 한 Elastic search가 등장하여 현재 검색 엔진 분야에서 지배적인 위치에 있다.
Elastic Search(ES) vs Relational DataBase Management System(RDBMS)
현재 가장 많이 사용되고 있는 DBMS인 RDBMS와 ES의 데이터 구조를 서로 매핑하여 비교하면 다음과 같이 정리할 수 있다.
| RDBMS | ES |
|---|---|
| Database | Index |
| Partition | Shard |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Query DSL |
앞서 RDBMS & NoSQL 포스트에서도 살펴보았듯, RDBMS는 정형 데이터를 다루고 트랜잭션 및 복잡한 쿼리를 다루는 데 더 적합한 반면 ES는 비정형 데이터를 다루고 전체 데이터의 검색이나 실시간 분석에 더 적합하다.
또한 ES는 기본적으로 http로 접근 가능한 REST API를 통해 데이터 조작을 지원한다. 이를 마찬가지로 RDBMS의 SQL과 매핑하면 다음과 같이 비교할 수 있다.
| CRUD | RDBMS SQL | ES HTTP method |
|---|---|---|
| READ | SELECT | GET |
| UPDATE | INSERT | PUT |
| CREATE | UPDATE | POST |
| DELETE | DELETE | DELETE |
| - | - | HEAD(Index 정보 확인) |
역색인(Inverted index)과 형태소 분석
역색인과 형태소 분석은 검색 엔진의 핵심 기능으로서 키워드(Term)를 기반으로 빠르게 원하는 문서를 탐색하기 위한 기능이다.
RDBMS를 비롯한 일반적인 데이터베이스는 단방향 색인을 사용한다. 즉 특정 키워드를 포함하는 문서를 찾기 위해서는 모든 문서의 내용을 확인한 뒤 해당 문서가 검색 키워드를 포함하고 있는지 검사해야 한다. 당연히 상당한 연산이 필요한 작업이며, 데이터가 많아질수록 검색에 필요한 시간도 증가하게 된다.
역색인은 이러한 문제를 해결하기 위해 만들어진 색인 구조이다. 역색인은 특정 키워드를 포함하고 있는 문서들에 대한 Primary key를 매핑하는 인덱스 테이블을 생성하고, 이를 활용하여 빠른 문서 탐색을 가능하게 한다. 그리고 이 역색인 인덱스 테이블은 봍통 BTree, Trie, Hash table 등의 자료 구조를 활용해 구현된다.
다음 예시를 통해 이 역색인 구조를 간단히 이해할 수 있다. 각 문서에서 불용어(Stopword)를 제거한 뒤 해당 각각의 키워드에 대하여 해당 키워드가 포함된 문서들의 index를 매칭하여 저장하는 것이다. 예를 들어 bright라는 키워드는 document 1과 3에서 등장하므로 인덱스 테이블에 'bright - 1, 3'과 같은 형태로 인덱스를 매치시켜 저장해 두는 식이다.
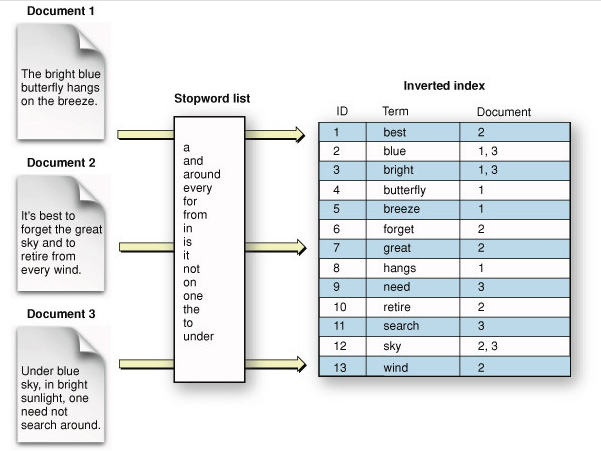
쉽게 예를 들면 일반적인 색인(Forward index)은 '책의 목차'와 같은 것이고 역색인은 책 말미에 있는 '단어별 색인'과 같은 것으로 이해할 수도 있을 것이다.
그리고 형태소 분석은 문서의 키워드를 추출할 때(그리고 사용자의 검색어로부터 핵심 키워드를 추출할 때에도) 사용되는 기능으로, 형태소 분석 성능은 검색 엔진의 성능과도 직결되는 부분이다.
Elastic Search의 장단점
장점
- 오픈 소스(Open source) : 엘라스틱 서치는 오픈 소스 소프트웨어로서 크고 활발한 커뮤니티가 존재한다. 따라서 사용자는 다양한 플러그인은 물론 버그 수정 및 기능 업데이트 등의 혜택을 받을 수 있다.
- 확장성(Scalability) : 엘라스틱 서치는 클러스터에 노드를 추가함으로써 수평적으로 확장할 수 있는 분산 시스템이며, 이를 통해 데이터 및 트래픽 증가에 효과적으로 대응할 수 있다.
- 통계 분석(Statistical Analtics) : 비정형 로그 데이터를 수집하여 통계 분석에 활용할 수 있으며, Kibana를 연결하면 실시간으로 로그를 분석하고 시각화하는 것도 가능하다.
- RESTful API : HTTP 기반의 RESTful API를 지원하며, 요청뿐만 아니라 응답에서 JSON 형식을 사용해 개발 언어나 OS, 시스템에 관계없이 다양한 플랫폼에서 활용할 수 있다.
- 멀티 테넌시(Multi-Tenancy) : 서로 상이한 인덱스라 하더라도 검색할 필드명만 동일하다면 여러 개의 인덱스를 한 번에 조회할 수 있다.
- 스키마리스(Schemaless) : 비정형 문서도 자동으로 색인하고 검색할 수 있다.
- 전문 검색(Full-text search) : 엘라스틱 서치는 전문 검색(내용 전체를 색인하여 특정 단어가 포함된 문서를 검색하는 것)이 가능하다.
- 문서 기반(Document-oriented) : 여러 계층 구조의 문서로 저장하는 것이 가능하며, 계층 구조로 구성된 문서도 한 번의 쿼리로 쉽게 조회할 수 있다.
단점
- 준실시간성 : 색인된 데이터는 통상적으로 1초 뒤에나 검색이 가능한데, 이는 색인된 데이터에 대하여 내부적으로 커밋 및 플러시 등의 복잡한 과정을 거치기 때문이다. 따라서 완전 실시간이라고 할 수는 없다.
- 트랜젝션 및 롤백 미지원 : 롤백과 트랜젝션은 시스템 비용의 소모가 크며, 엘라스틱 서치는 전체 클러스터의 성능 향상을 위해 이를 지원하지 않는다. 따라서 최악의 경우 데이터 손실의 위험이 있다.
- 데이터 업데이트 미지원 : 엘라스틱 서치는 업데이트 명령이 요청되면 기존의 문서를 삭제하고 변경된 내용으로 새로운 문서를 생성하는 방식을 사용한다. 따라서 업데이트에 비해 많은 비용이 소모된다.
※ 단, 이는 불변성(Immutable)이라는 이점을 취할 수도 있는 부분이므로 장점이 될 수도 있다.
Elastic search 기본 용어
기본 구성
- Cluster
- ES에서 가장 큰 단위로서, 하나 이상의 노드로 이루어진 노드들의 집합
- 독립적이며 서로 다른 클러스터에 접근할 수 없음
- 여러 대의 서버가 하나의 클러스터를 구성하는 것도 가능하며, 하나의 서버에 여러 개의 클러스터를 구성하는 것도 가능함
- Node
- ES를 구성하는 하나의 인스턴스
- 클러스터 이름을 통해 특정 클러스터의 일부로 구성될 수 있음
Type of Node
- Master node
- 클러스터를 관리하는 노드로서 인덱스를 생성, 삭제하는 등 클러스터와 관련된 전반적인 작업을 담당
- 다수의 노드 설정이 가능하나, 하나의 노드만 선출되어 동작함
- Data node
- 실질적인 데이터(문서)가 저장되는 노드로, 검색 및 통계 등의 데이터 관련 작업을 수행
- 리소스를 많이 소모하므로 마스터와 분리해서 구성하는 것이 권장됨

- Coordinating node
- 입력된 요청을 받아 마스터 노드에 전달하고 데이터 관련 요청은 데이터 노드에 전달하는 역할
- 검색 및 집계 시의 분산 처리만을 목적으로 하며, 분산 시 Round-Robin 방식을 사용함

- Ingest node
- 문서의 전처리 작업을 담당
- 인덱스 생성 전 문서의 데이터 포맷을 변경하기 위해 스크립트로 전처리 파이프라인을 구성하고 실행하는 것이 가능
- 데이터가 많을 경우 성능 향상에 도움이 됨

- Master node
- Index
- 데이터가 저장되는 공간
- 하나의 물리 노드에 여러 개의 논리 인덱스를 생성
- 하나의 인덱스는 여러 노드에 분산 저장됨(M:N)
- Shard
- 인덱스 내부의 색인된 데이터들은 하나의 덩어리가 아니라 물리적으로 여러 공간에 나뉘어 저장되는데 이를 샤드라 함
프라이머리(Primary) 샤드와레플리카(Replica) 샤드로 구분- 프라이머리 샤드 : 데이터의 원본과 같은 개념
- 레플리카 샤드 : 프라이머리 샤드의 복제본과 같은 개념
- Type
- 인덱스의 논리적 구조
- 현재는 인덱스 하나당 하나의 타입을 갖게 되어 의미가 없으며, 7.0부터 완전히 사라짐
- Document
- 엘라스틱 서치의 데이터가 저장되는 최소 단위
- JSON 포맷으로 저장됨
- Field
- 문서를 구성하는 속성
- 하나의 필드는 목적에 따라 다수의 데이터 타입을 가질 수 있음
- Mapping
- 문서의 필드와 필드 속성을 정의하고 그에 따른 색인 방법을 정의하는 프로세스
- 매핑 정보에 여러 데이터 타입을 지정할 수 있으나 필드명 자체는 중복이 불가함
Elastic search의 주요 API
ES는 RESTful API를 제공하며, 이를 통해 JSON 기반으로 통신한다. 일반적으로 4개의 API로 분류한다.
인덱스 관리 API(Indices API)
- 인덱스 생성
- PUT method를 사용
- 인덱스 생성 시 매핑을 이용해 문서에 포함된 필드 및 필드 타입을 설정
- 매핑 정보가 한번 생성되면 변경이 불가능하다는 점에 주의
- 인덱스 삭제
- DELETE method를 사용
- 취소가 불가능함에 유의할 것
문서 관리 API(Document API)
- 문서 생성
- POST method 사용
- 'index 이름/_doc/문서 id' 순으로 입력
- 문서 id 미입력 시 무작위 값이 입력됨
- 문서 조회
- GET method 사용
- 문서 생성 형식과 동일함
- 문서 삭제
- DELETE method 사용
- 문서 생성 형식과 동일함
검색 API(Search API)
검색 API의 사용 방식은 크게 두 가지로 나뉜다.
1. HTTP URI 형태의 파라미터를 URI에 추가하여 검색
2. RESTful API 방식인 Query DSL을 사용하여 Request body에 내용을 추가
일반적으로 RESTful API 방식이 URI 방식에 비해 제약 사항이 적어 더 많이 사용되며, 경우에 따라 둘을 섞어서 사용하는 것도 가능하다.
집계 API(Aggregation API)
데이터의 집계 타입에 따라 다양하게 구분할 수 있다.
- 버킷 집계(Bucket aggregation) : 문서의 필드를 기준으로 버킷을 집계
- 매트릭 집계(Metric aggregation) : 문서에서 추출된 값을 이용하여 합계, 최댓값, 최솟값, 평균값 등을 계산
- 매트릭스 집계(Metrix aggregation) : 행렬 값을 합하거나 곱함
- 파이프라인 집계(Pipeline aggregation) : 일반적인 파이프 라인 개념으로, 집계에 의해 생성된 집계 결과를 이용해 또 다시 집계
참고 자료
