Clustering
클러스터링(Clustering)이란 동일한 데이터베이스를 여러 대의 서버가 관리하도록 클러스터를 구축하는 것을 말한다. 즉, 여러 개의 DB를 '수평적인 구조'로 구축하는 방식이다. 이처럼 분산 환경을 구성함으로써 장애 극목 시스템(Failover system)을 구축할 수 있다.
클러스터를 사용하면 다음과 같은 장점이 있다.
- 데이터베이스 서버(노드) 간의 동기(Synchronous) 방식 동기화를 통해 일관성 있는 데이터의 획득이 가능
- 로드 밸런싱 : 작업을 각 서버에서 나눠서 처리함으로써 트래픽을 감소시킴
- 하나의 서버가 고장 나더라도 다른 서버에 접근할 수 있어 DB에 항상 접근이 가능함
클러스터링에서 데이터를 처리하는 방식은 다음과 같다.
- 하나의 노드(A)에 쓰기 트랜잭션이 수행되고 COMMIT된다.
- 실제 디스크에 데이터를 쓰기 전, 다른 노드(B)로 데이터의 복제를 요청한다.
- 다른 노드(B)에서 복제 요청을 수락했다는 신호(OK)를 보내고, 디스크에 쓰기를 시작한다.
- 노드(A)는 다른 노드(B)로부터 신호(OK)를 받으면 실제 디스크에 데이터를 저장한다.
클러스터링에는 크게 Active-Active 방식과 Active-StandBy 방식이 있다.
Active-Active
다음과 같이 모든 데이터베이스의 서버가 Active 상태로 운영되는 방식을 말한다. 앞서 언급한 장애 극복 시스템 구현, 로드 밸런싱을 통한 트래픽 감소 등의 장점을 얻을 수 있다.
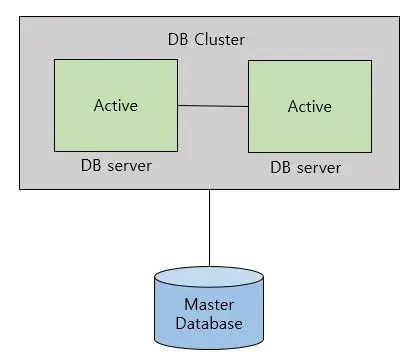
다만 여러 대의 DB 서버가 하나의 DB 스토리지를 공유하므로 병목현상이 발생할 수 있다. 이러한 단점을 완화할 수 있는 방식이 Active-StandBy 방식이다.
Active-StandBy
Active-StandBy 방식은 다음과 같이 Active 상태의 서버와 Stand-by 상태의 서버를 나누어 운영하는 것이다. Stand-by 상태의 서버는 준비 상태로 대기하다가 Active 서버에 문제가 발생할 경우 Active 상태로 전환되어 사용된다. 이러한 방식을 통해 Active-Active 방식의 병목현상을 해결할 수 있다.
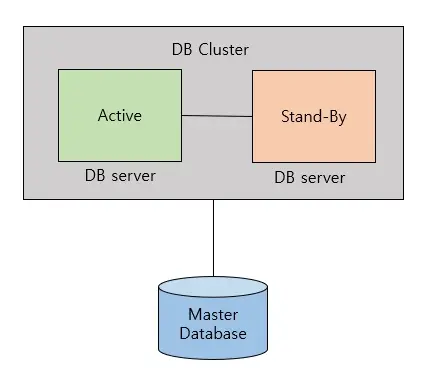
다만 이 경우 장애 발생 시 Stand-by 상태에서 Active 상태로 전환하는 시간 동안 서비스를 사용할 수 없게 되며, 여러 대의 서버 사용을 통한 트래픽의 감소 효과 역시 그 효율이 줄어든다는 단점이 있다.
Replication
리플리케이션(Replication)은 여러 개의 DB를 권한에 따라 '수직적인 구조(Master-Slave)'로 구축하는 방식이다. 리플리케이션에서 Master node는 쓰기(Write/Update/Delete) 작업을 처리하고, 읽기 작업은 Slave node에서 처리한다.
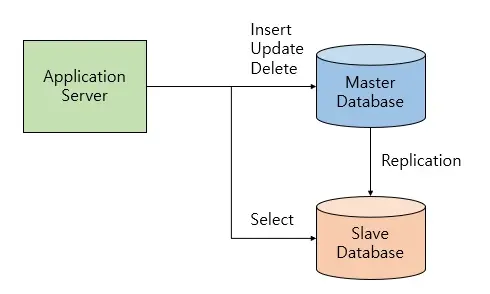
리플리케이션에서 데리터를 처리하는 방식은 다음과 같다.
- Master 노드에 쓰기 트랜잭션이 수행된다.
- Master 노드는 데이터를 저장하고 트랜잭션에 대한 로그를 파일(BIN LOG)에 기록한다.
- Slave 노드의 IO Thread는 Master 노드의 로그 파일(BIN LOG)을 파일(Replay log)에 복사한다.
- Slave 노드의 SQL Thread는 파일(Replay log)을 한 줄씩 읽으면서 데이터를 저장한다.
리플리케이션을 이용하면 다음과 같은 장점을 얻을 수 있다.
- 마스터 노드와 슬레이브 노드가 각기 다른 명령을 수행하도록 함으로써 데이터베이스의 부하 분산
- 마스터 노드의 데이터 손상 시 슬레이브 노드의 데이터를 이용해 복구가 가능하므로 데이터 안정성 확보
그러나 리플리케이션에는 다음과 같은 단점도 존재한다.
- 데이터가 비동기(Asynchronous) 방식으로 동기화되므로 데이터베이스 간 동기화가 완전히 보장되지 않아 일관성에 문제가 발생할 수 있음
- 마스터 노드가 정상 작동하지 않을 경우 복구 및 대처가 까다로움
복제 지연(Replication lag)
리플리케이션의 복제 지연(Replication lag)이란 Master 노드와 Slave 노드 간의 속도 차에 의한 병목 현상을 말한다. 이는 Master 노드는 다중 스레드로 쓰기 작업을 수행하는 반면, Slave 노드는 단일 스레드로 쓰기 작업을 수행하므로 속도 차가 발생하여 나타나는 현상이며, 리플리케이션의 구조적인 문제에서 발생하는 현상이다.
다만 복제 지연을 직접적으로 유발하는 원인들도 있으며, 각각의 원인들과 해결 방법을 정리하면 다음과 같다.
-
장기 실행 쿼리
SBR(Statement Based Replication, SQL을 전송하여 복제하는 방식)의 문제이기도 한 것으로, 예를 들어 1시간 동안 수행되는 쿼리는 복제본에서 replay되는 시간도 1시간이므로 총 2시간의 지연 시간을 갖게 된다.
이는 SBR 방식의 문제이기도 하므로 RBR(Row Base Replication, 변경된 결과를 복제하는 방식) 방식 혹은 MBR(Mixed Based Replication, 비결정적 동작의 경우에만 RBR 방식으로 동작하는 방식) 방식을 통해 해결하기도 한다. 또는 튜닝이나 인덱스를 활용하여 쿼리의 성능 자체를 향상시키는 방법도 있다. -
쓰기 쿼리량 증가
트래픽이 증가하거나 특정 배치 작업으로 인하여 쓰기 사용이 많아지면서 복제 지연이 발생할 수도있다. 특히 트래픽 증가로 인한 복제 지연의 경우 바쁜 시간대에는 갭이 커졌다가 한가한 시간대에 다시 좁혀지는 현상이 반복될 수도 있다.
이는 Multi-Threded Replication 설정을 통해 복제를 적용하는 worker의 스레드 개수를 늘려 처리 속도를 향상시킴으로써 해결할 수 있다. 만약 데이터의 양 자체가 많고 사용량도 계속 증가하는 경우 샤딩이나 도메인 자체의 분리 등을 통하여 경량화하는 것도 도움이 될 수 있다. -
Slave의 로드 증가
Slave에서 실행되는 서비스 조회 트래픽으로 인해 처리 성능이 지연되면서 복제 지연이 발생하는 경우를 말한다.
이 경우는 조회 트래픽을 감당할 Slave의 양이 부족하다는 의미이므로 Slave를 추가 구성함으로써 해결할 수 있다.
Partitioning vs Sharding
데이터베이스의 볼륨이 커지면 커질수록 데이터베이스의 읽기/쓰기 성능은 저하되며, 데이터베이스가 병목 지점이 될 수 있다. 따라서 데이터베이스를 적절히 분할하는 것이 필요한데, 데이터베이스의 분할 방법은 크게 파티셔닝(Partitioning)과 샤딩(Sharding)으로 구분할 수 있다.
Partitioning
파티셔닝은 매우 큰 테이블을 여러 개의 테이블로 분할하는 작업으로, 이때 데이터는 물리적으로 여러 테이블로 분산되어 저장되지만 사용자는 하나의 테이블에 접근하는 것처럼 사용할 수 있다는 점이 특징이다.
파티셔닝은 다음과 같이 4가지 방식이 있다.
-
List partitioning
데이터 값이 특정 목록에 포함되는 경우 데이터를 분리하는 방식으로, 예를 들어 특정 지역별로 데이터를 분할할 때 사용할 수 있다. -
Range partitioning
데이터를 특정 범위 기준으로 분할하는 방식으로, 예를 들어 1~2월, 3~4월, 5~6월 등과 같이 시기별로 데이터를 분할할 때 사용할 수 있다. -
Hash partitioning
해시 함수를 사용하여 데이터를 분할하는 방법으로, 특정 컬럼의 값을 해싱하여 저장할 파티션을 선택한다. -
Compose partitioning
앞의 1~3번 파티셔닝 방식 중 두 가지 이상을 사용하는 방식이다.
Sharding
샤딩은 동일한 스키마를 가지고 있는 여러 대의 데이터베이스 서버들에 데이터를 작은 단위로 분산 저장하는 기법이며, 이때 이 '작은 단위'를 샤드(Shard)라고 한다.
샤딩은 수평 파티셔닝의 일종이라고 할 수도 있는데, 파티셔닝은 모든 데이터를 동일한 서버에 저장하지만 샤딩은 데이터를 서로 다른 서버에 분산한다는 차이가 있다. 물리적으로 서로 다른 서버에 데이터를 저장하므로 쿼리의 성능이 향상됨과 동시에 부하가 분산되는 효과까지 얻을 수 있는, 일종의 수평 확장(Scale-out)과 같은 방법이다.
다만 샤딩은 데이터를 물리적으로 독립된 서버에 각각 분할하여 저장하기 때문에 여러 샤드에 걸친 데이터를 조인하는 것이 어렵다. 또한 하나의 데이터베이스에 데이터가 집중되면 성능이 저하될 수 있어 데이터를 여러 샤드로 고르게 분배하는 것이 중요하다.
샤딩의 종류는 크게 다음과 같이 정리할 수 있다
-
Hash sharding
샤드 키(Shard key, 데이터를 어떤 샤드에 저장할지 결정하는 키)를 결정하는 데 Hash 알고리즘을 이용하는 방식으로, Hash 방법으로는 Modular 연산 등이 있으며, 주로 데이터의 양이 일정 수준으로 유지될 것으로 예상될 때 적용한다.
이 방식은 구현이 매우 간단하지만, 샤드가 늘어날 경우 해시 함수가 바뀌어야 하는데, 이 경우 기존에 저장된 데이터의 정합성이 깨지게 되므로 확장성은 좋지 않다. -
Dynamic(Range based) sharding
Hash sharding의 확장성을 해결하기 위해 등장한 방식으로, locator service를 이용해 shard key를 특정 범위 기준으로 분할한다. 데이터의 트래픽에 따라 기준을 동적으로 변경할 수 있으며, 증설 시 샤드 키만 추가하면 되기 때문에 재정렬 비용이 들지 않는다는 장점이 있다.
다만 일부 DB에 데이터가 몰릴 수 있으므로 데이터의 분할 범위 기준을 적절하게 설정하여야 하며, Locator에 대한 의존성이 커져 Locator의 장애 시 샤드 전체에 영향을 미칠 수도 있다는 단점이 있따. -
Entity group
테이블이 Key-Value 관계가 아니라 다양한 객체로 구성되어 있는 경우, 일정한 관계에 있는 Entity들을 같은 샤드 내에 구성하는 방식이다.
물리적으로 동일한 샤드 내에서 쿼리를 수행하는 경우 효율적이며 사용자의 증가에 따른 확장성도 좋다. 다만 특정 파티션 간의 쿼리 수행 시 비효율적일 수 있다는 단점도 존재한다.
참고 자료
