신경망의 하위층으로 진행될수록 그레디언트가 점점 작아지거나 커지는 것을 그레디언트 소실 혹은 폭주라고 부른다.
이러한 현상이 일어나면 알고리즘은 발산하게 되며 그레디언트 폭주는 주로 순환신경망에서 일어난다.
원인
1. 신경망 layer의 적절한 초기화
- Foward와 backward시 신호가 양방향으로 적절히 흘러야 신호가 소실 혹은 폭주하지 않는다.
- Understanding the difficulty of training deep feedforward neural networks 2010에서 각 층의 출력에 대한 분산이 입력에 대한 분산과 같아야 한다. + 역방향에서 층을 통과하기 전과 후의 그레디언트 분산이 같아야 한다.
-즉, 순전파와 역전파 시 층의 입력과 출력의 분포가 같아야 한다. - 하지만 입력과 출력의 분포가 같으려면 입출력 연결 개수 (ex.뉴런개수)가 같아야 한다.
세이비어 초기화 or 글로럿 초기화

실제로는 fan-in과 fan-out이 같지 않은경우가 많으므로 위의 분포로 가중치를 초기화 하면 실전에서 잘 작동한다 함. fan avg대신 fan in을 사용하면 르쿤 초기화
단, 세이비어 초기화는 시그모이드 함수나 하이퍼볼릭 탄젠트 함수와 같은 S자 형태인 활성화 함수와 함께 사용할 경우에는 좋은 성능을 보이지만, ReLU와 함께 사용할 경우에는 성능이 좋지 않다. -> HE 초기화
HE 초기화

Keras는 기본적으로 글로럿 초기화를 사용(dense)
pytorch는 르쿤 초기화 사용(Linear)
일반적인 초기화전략 - 활성화 함수
- 글로럿 - 하이퍼볼릭 탄젠트 , 로지스틱 , 소프트맥스
- HE - ReLU 및 ReLU변종
- 르쿤 - SELU
2. 적절한 활성화 함수
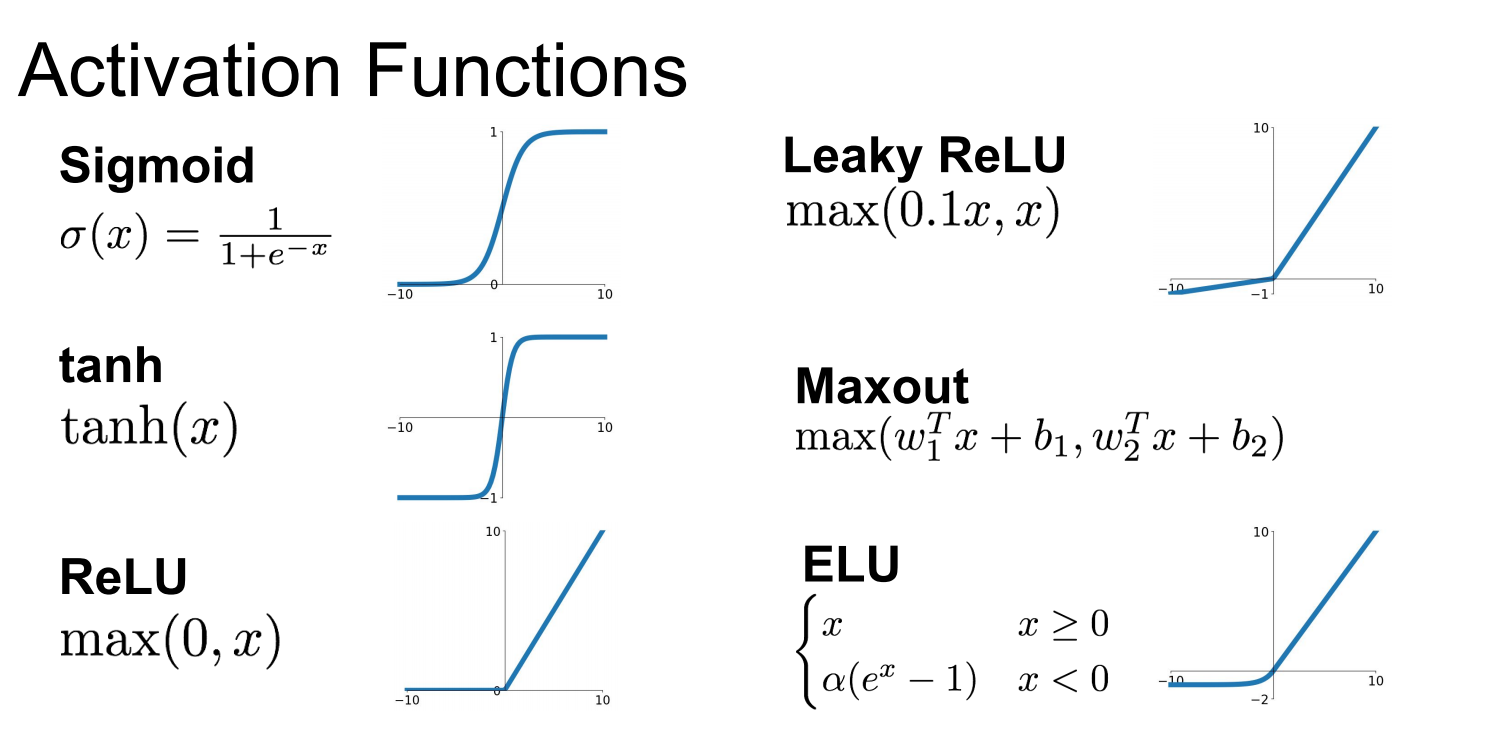
ReLU : 계산이 빠르며 특정 양숫값에 수렴하지 않음
- 단점 : 죽은 ReLU - 일부 뉴런이 0만 출력함, 큰 학습률 사용시 뉴런 절반이 죽음
LeakyReLU : 여러 논문에서 LeakyReLU는 항상 ReLU보다 성능이 좋음
- 이유 : 작은 기울기가 LeakyReLU를 절대 죽지 않게 만듦, 혼수상태에 오래 있을 수 있지만 다시 깨어날 가능성이 있음
ELU : 모든 ReLU변종의 성능을 앞지름 , 적은 훈련시간 , 성능도 높음
- 특징1 : z<0일 때 그래디언트가 0이 아니므로 죽은 뉴런을 만들지 않음
- 특징2 : 알파=1이면 z=0일 때 급격하게 변동하지 않으므로 모든 구간에서 매끄러워 경사하강법의 속도를 높임
- 단점 : 지수함수이므로 계싼이 느림 , 훈련시는 수렴속도가 빨라져서 상쇄되도 Inference할 땐 계산량이 많아 느려짐
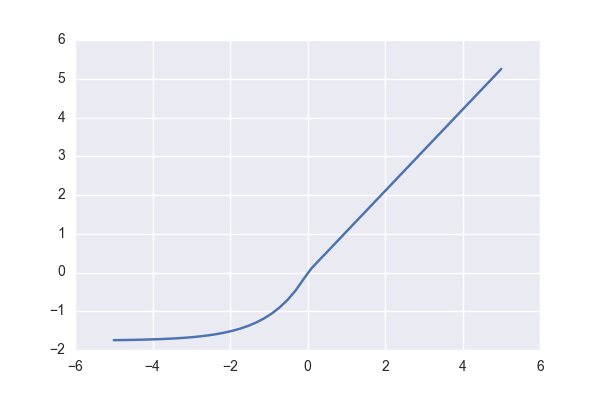
SELU : 모든 층이 완전 연결 층일 때 모두 SELU를 사용하면 self-normalize가 됨 -> 그레디언트의 소실과 폭주를 막음
활성화 함수 선택
SELU > ELU > LeakyReLU > ReLU > tanh > 로지스틱 순
일반적인 순서지만 네트워크가 자기 정규화가 되지 못하는 구조라면 ELU가 성능이 더 좋음
실행 속도가 중요하다면 LeakyReLU를 선택!
신경망이 과대적합됬다면 RReLU , 훈련셋이 아주 크다면 PReLU
많은 라이브러리와 하드웨어 가속기가 ReLU에 최적화 되어있으므로 속도가 중요하다면 ReLU!!
3. 배치 정규화
2015 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
신경망의 첫번째 층에 배치정규화를 추가하면 StandardScaler같이 표준화 할 필요가 없다.
- 배치정규화를 사용하면 에포크마다 훈련시간이 더 오래걸리지만 수렴이 훨씬 빨라지므로 상쇄됨
- 미니배치마다 평균과 표준편차를 계산하므로 훈련셋에 일종의 노이즈를 넣는다 -> 과대적합방지 & 규제
- 이러한 규제효과는 미니배치의 크기가 클수록 효과가 줄어듦
배치정규화층의 학습 파라미터 4개
- 출력 스케일 벡터 , 출력 이동 벡터 : 일반적으로 역전파를 통해 학습
- 최종 입력 평균 벡터 , 최종 입력 표준편차 벡터 : 지수 이동 평균을 사용하여 추정 - 훈련하는동안 학습하며 훈련이 끝난뒤에 사용됨
배치정규화 과정에서 이동파라미터가 있으므로 layer에서 편향(bias)을 뺄 수 있다.
그리고 활성화 함수 이전에서 정규화를 함
ex)
Dense(300,use_bias=False)
BatchNoralization()
Activation('ReLU')
4. 그레디언트 클리핑
- 역전파될 때 그레디언트를 일정 임계값을 넘지 못하게 자르는 것
- 주로 순환 신경망은 배치 정규화를 적용하기 힘들어서 클리핑을 많이 사용함
5. 그외
5.1 softmax 와 log_softmax
- log_softmax는 단순히 softmax에 log를 취한 것
- 일반적인 softmax는 gradient vanishing(기울기 소멸)에 취약함 -> log를 씌움
- CrossEntropyLoss는 log_softmax 후 NLLLoss와 같음
- 따라서 CrossEntropyLoss를 사용할 때는 log_softmax를 쓰지말자 같은 연산 두번 하므로 결과는 같더라도 느림
- NLLLoss를 사용할거면 log_softmax 후 사용하자
- 일반적인 softmax는 사람이 인식하기 편하므로 설명하고자 할 때만 사용하고 log_softmax를 사용하자!
5.2 Residual 학습
- ResNet과 같이 이전 학습정보를 잔여학습에 더해서 넘기자! F(x) + x
