react 클립보드에 저장한 이미지를 텍스트로 변환하기 (tesseract.js)

https://github.com/heehminh/react-image-to-text
수학 학원에서 아르바이트를 하는데 시험지를 보고 타자로 쳐 문서화하는 일이 주된 작업이다. 직접 치고 있는게 비효율적이라고 여겨 해당 서비스를 만들게되었다.
1. 클립보드에서 이미지 추출하기
클립보드에서 이미지를 추출하기 위해서는 브라우저에서 제공하는 Clipboard API를 사용할 수 있다. 이 API를 사용하여 클립보드에서 이미지를 추출한 후, 추출된 이미지를 사용하여 텍스트를 추출하는 OCR(광학 문자 인식) 기술을 이용할 수 있다.
-
클립보드에 데이터를 복사하는 방법
function copyToClipboard(text) { navigator.clipboard.writeText(text) .then(() => { console.log('Copied to clipboard') }) .catch((error) => { console.error('Failed to copy: ', error) }) } -
클립보드에서 데이터를 가져오는 방법
function pasteFromClipboard() { navigator.clipboard.readText() .then((text) => { console.log('Pasted from clipboard: ', text) }) .catch((error) => { console.error('Failed to paste: ', error) }) }

이 이미지를 클립보드에 저장한 뒤 수행하였다.
먼저, 클립보드에 저장한 이미지를 가져와 웹 페이지에 보여주는 작업을 수행하였다.
- 클립보드에서 이미지 가져오기:
navigator.clipboard.read()메서드를 사용하여DataTransfer객체를 가져와야 한다. DataTransfer객체에서 이미지 추출하기: 가져온DataTransfer객체에서 이미지 데이터를 추출하기 위해서는items배열에서type속성이image/*인 항목을 찾아서getAsFile()메서드를 호출하면 됩니다. 이렇게 추출된 이미지 데이터는Blob객체로 반환됩니다.- 추출된 이미지 데이터 처리하기: 추출된
Blob객체를 사용하여 원하는 위치에 이미지를 출력하는 방법은 여러 가지가 있습니다. 예를 들어, 추출된 이미지 데이터를URL.createObjectURL()메서드를 사용하여img요소의src속성에 할당하면 됩니다. - 이미지 데이터 리턴하기: 이미지 데이터를 리턴하기 위해서는 추출된
Blob객체를 사용하여Promise객체를 반환하면 됩니다.
import React, { useState } from "react";
const Image = () => {
const [image, setImage] = useState(null);
async function getImageFromClipboard() {
await navigator.clipboard.readText();
const clipboardItems = await navigator.clipboard.read();
for (const item of clipboardItems) {
for (const type of item.types) {
if (type.startsWith("image/")) {
const blob = await item.getType(type);
// 이미지 데이터가 null이 아닌 경우만 반환
if (blob) {
const img = document.createElement("img");
img.src = URL.createObjectURL(blob);
return img;
}
}
}
}
// 이미지 데이터가 없는 경우, 에러 발생
throw new Error("No image data found in clipboard.");
}
const handlePaste = () => {
getImageFromClipboard()
.then((img) => {
setImage(img);
})
.catch((error) => {
console.error(error);
});
};
return (
<div>
<button onClick={handlePaste}>Paste Image</button>
{image && <img src={image.src} alt="Pasted from clipboard" />}
</div>
);
};
export default Image;2. 이미지에서 텍스트 추출하기
Tesseract.js 라는 오픈소스 OCR 라이브러리를 사용하여 이미지에서 텍스트를 추출할 수 있다.
-
추출할 텍스트를 담아놓을 상태 선언
const [text, setText] = useState(""); -
image → text 추출
setImage(img); const worker = await createWorker({ logger: (m) => console.log(m), }); (async () => { await worker.loadLanguage("kor+eng"); await worker.initialize("kor+eng"); const { data: { text }, } = await worker.recognize(img); console.log(text); setText(text); await worker.terminate(); })();- 공식문서 참고
import { createWorker } from 'tesseract.js'; const worker = await createWorker({ logger: m => console.log(m) }); (async () => { await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();
공식문서에서 이미지를 앞에 클립보드의 이미지로 넣어주었고, 언어를 한국어와 영어로 설정해주었다.
이렇게 하면 한국어는 한글자 단위로 추출된다.

띄어쓰기 단위로 리팩토링해주었다.
- 공식문서 참고
3. 텍스트를 띄어쓰기 단위로 리팩토링하기
const {
data: { text },
} = await worker.recognize(img, {
preserve_interword_spaces: "1",
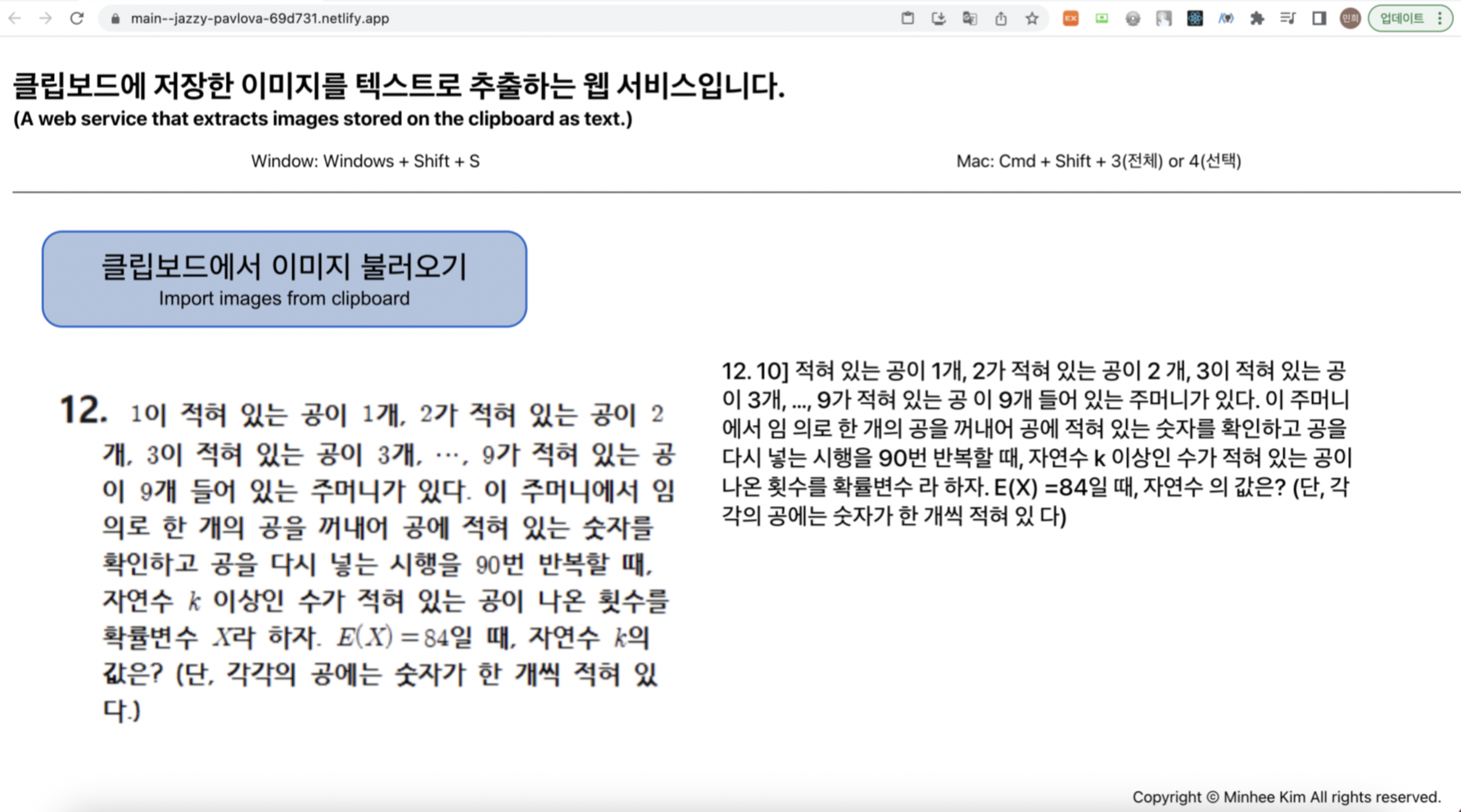
});
4. 내가 만난 에러
4-1. styled components 가 갑자기 설치가 안되었다.
원래 **npm instal styled-components** 로 했을 때 문제 없었는데, 갑자기 에러가 나서 아래와 같이 설치하였더니 해결되었다.
npm i styled-components --legacy-peer-deps4-2. 클립보드에서 이미지를 가져올 때
const img = new Image();
img.src = URL.createObjectURL(blob);
setImage(img);**Image()**를 사용하였더니 Image()도 hooks 중 하나이기 때문에, 상단에 사용하지 않아 에러가 났다.
에러 내용: act_devtools_backend_compact.js:2367 TypeError: Image is not a constructor
다음과 같이 수정해주면 에러가 해결된다.
const img = document.createElement("img");
img.src = URL.createObjectURL(blob);
setImage(img);