
💡버블정렬
데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식
간단하게 구현할 순 있지만, 시간 복잡도는 n^으로 다른 정렬 알고리즘보다 속도가 느린 편이다.
핵심 이론
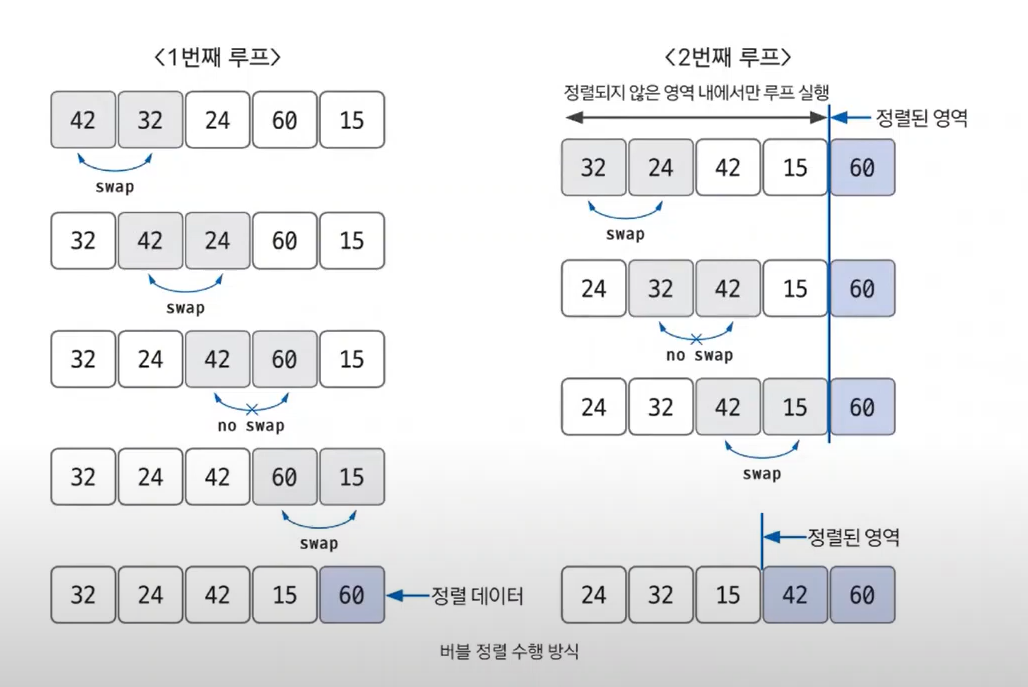
만약 특정한 루프의 전체 영역에서 swap이 한 번도 발생하지 않았다면, 그 영역 뒤에 있는 데이터가 모두 정렬되었다는 뜻이므로 프로세스를 종료해도 된다.
-> 더 이상 정렬 알고리즘을 수행할 필요가 없다는 의미
💡선택정렬
대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법
구현 방법이 복잡하고, 시간 복잡도도 n^으로 효율적이지 않다.
핵심 이론
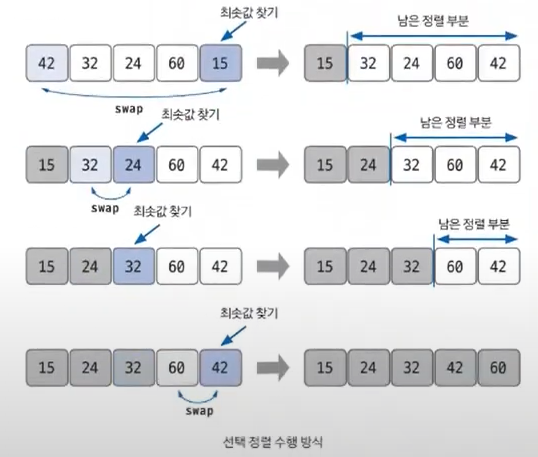
최솟값 또는 최댓값을 찾고, 남은 정렬 부분이 가장 앞에 있는 데이터와 swap하는 것이 선택 정렬의 핵심이다.
💡삽입정렬
이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식
시간 복잡도는 n^이지만 구현하기가 쉽다.
핵심 이론
선택 데이터를 현재 정렬된 데이터 범위 내에서 적절한 위치에 삽입하는 것
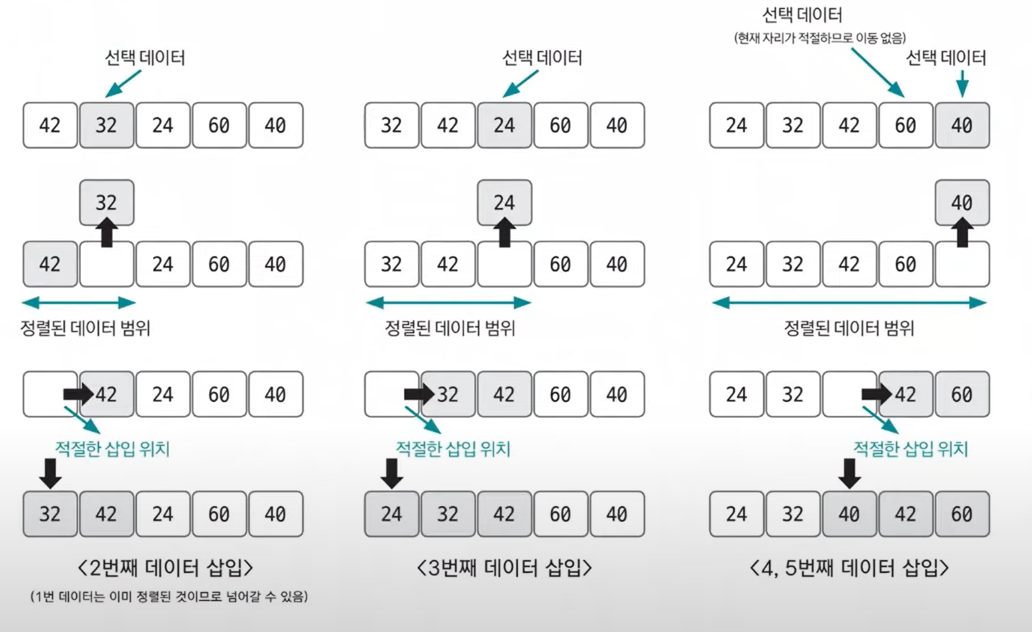
적절한 삽입 위치를 탐색하는 부분에서 이진 탐색 등과 같은 탐색 알고리즘을 사용하면 시간 복잡도를 줄일 수 있다.
하지만 그럼에도 시간 복잡도를 많이 줄일 수는 없다. 삽입 위치를 빨리 찾았다고 해도, 그 이후 데이터를 옮기는 것이 오래 걸리기 때문이다.
💡병합정렬
분할 정복 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘
병합 정렬은 코딩테스트의 정렬 관련 문제에서 자주 등장한다.
시간 복잡도는 nlogn이다.
분할 정복 방식
분할 정복(Divide and Conquer)은 여러 알고리즘의 기본이 되는 해결방법이다.
분할 정복법은 재귀적으로 자신을 호출하면서 그 연산의 단위를 조금씩 줄어가는 방식이다.
핵심 이론
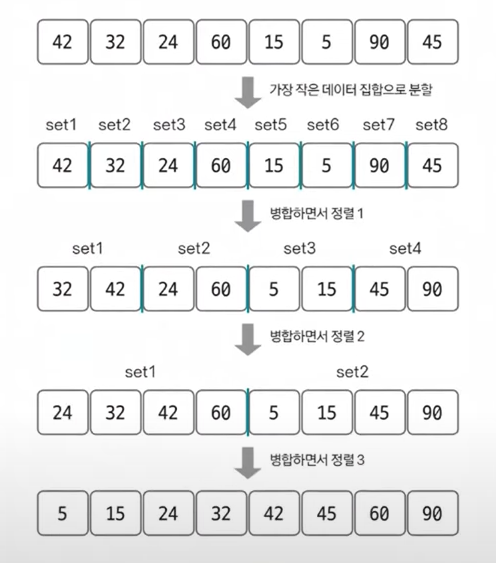
(부분그룹은 setN으로 표시)
가장 작은 데이터 집합으로 분할 -> n번 데이터 접근 (8번)
병합하면서 정렬을 logN번 (3번 = log8 = log2^3)
=> 결론: 시간복잡도는 nlogn
2개의 그룹을 병합하는 과정
2개의 그룹을 병합하는 원리는 꼭 숙지해야 한다.
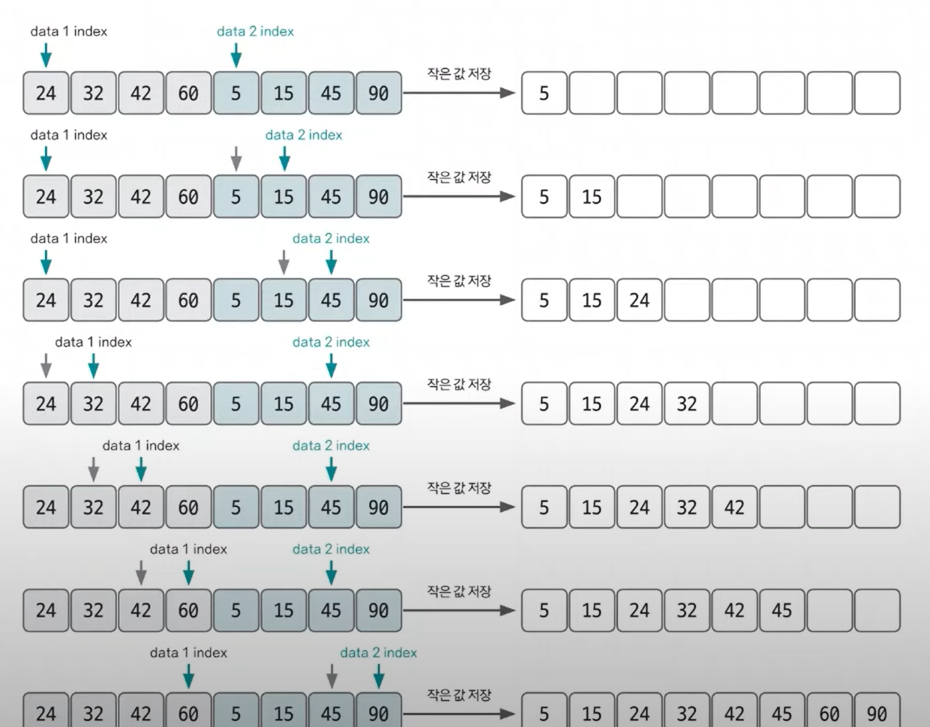
투 포인터 개념을 사용하여 왼쪽, 오른쪽 그룹을 병합한다.
왼쪽 포인터와 오른쪽 포인터의 값을 비교하여 작은 값(오름차순 기준)을 결과 배열에 추가하고 포인터를 오른쪽으로 1칸 이동시킨다.
