Hadoop 실습


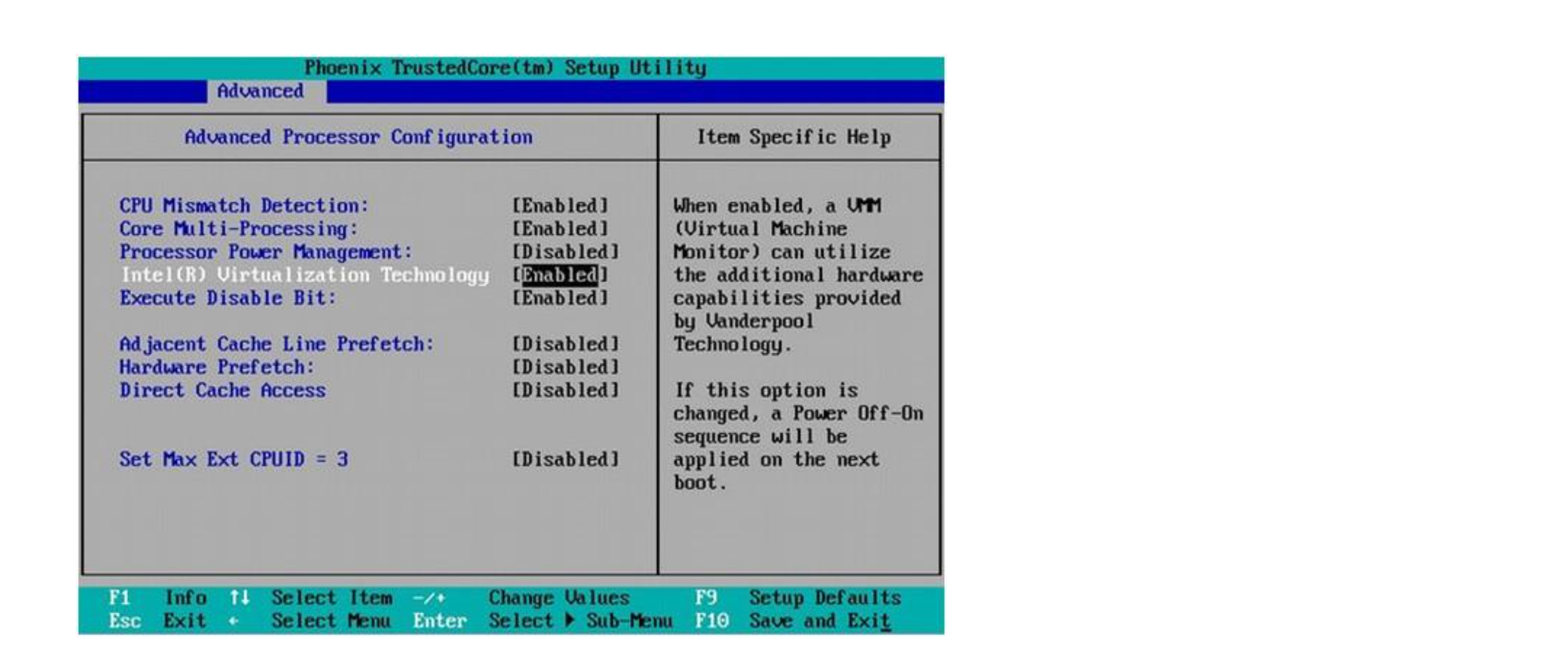
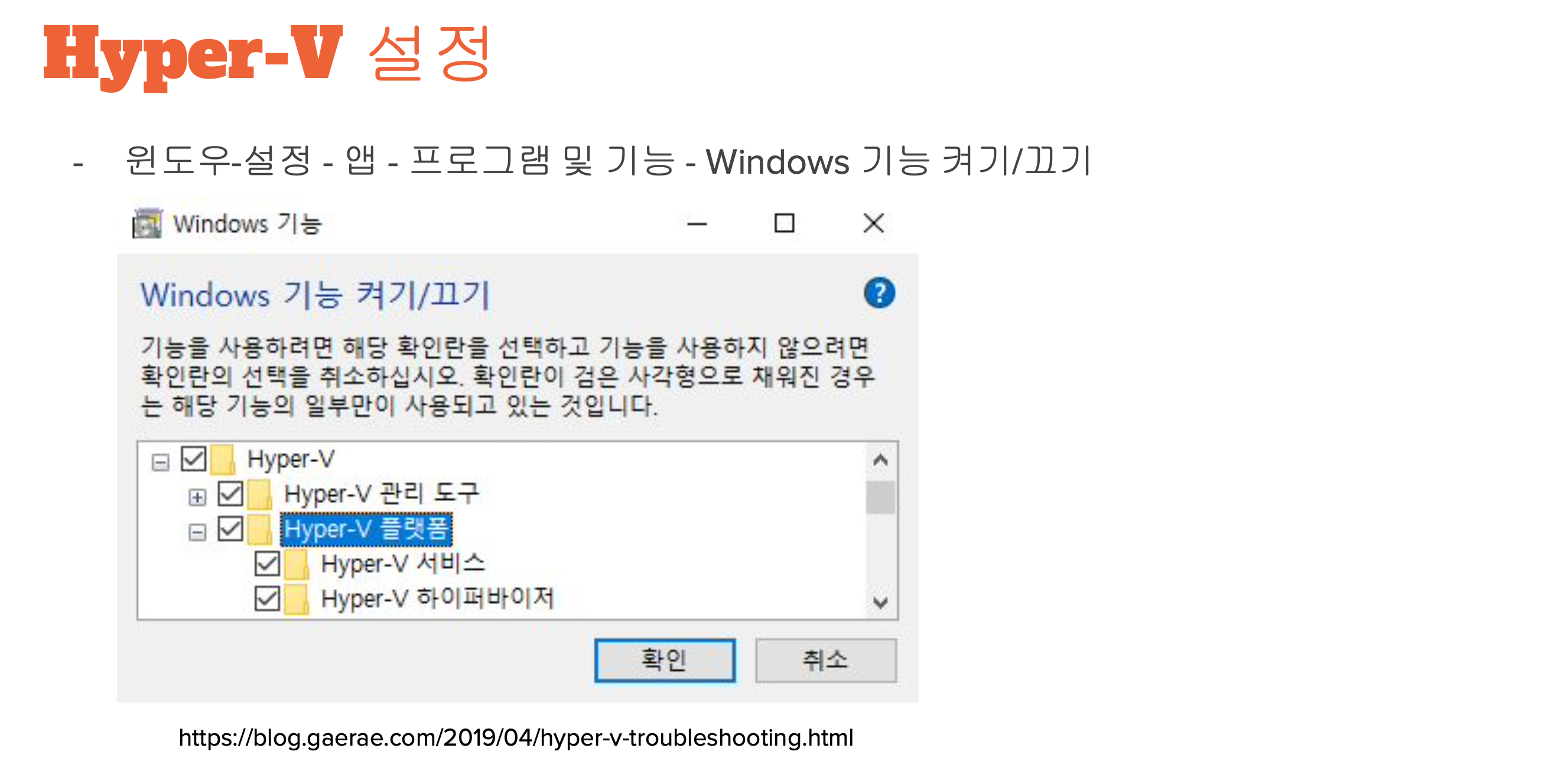




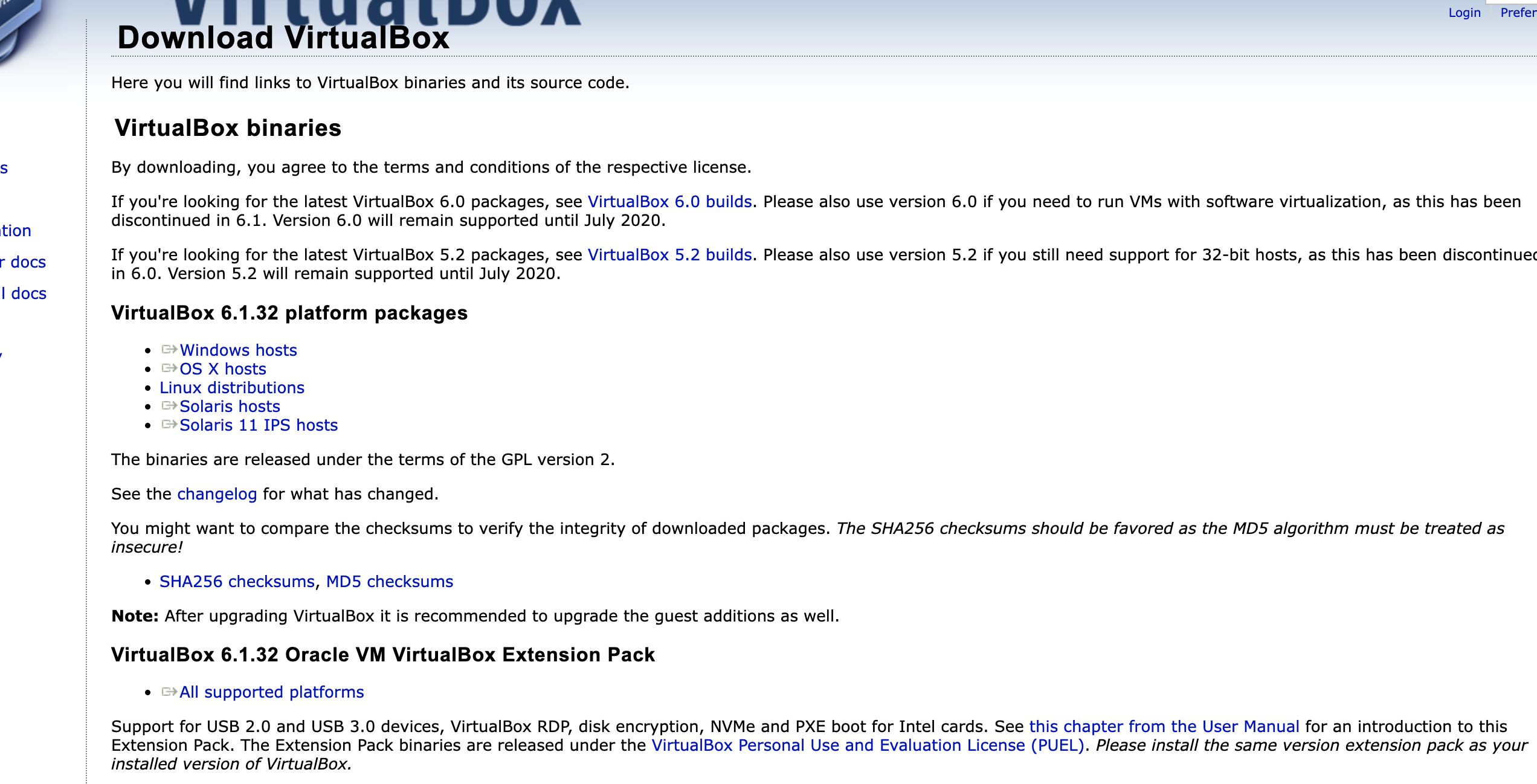
virtualbox 6.1.32 platform package 랑 Extension pack 설치

mac 기준 Virtual Box 구성
- .dmg로 virtual box 설치 > extension pack 더블클릭으로 설치 > .ova 가상머신가져오기
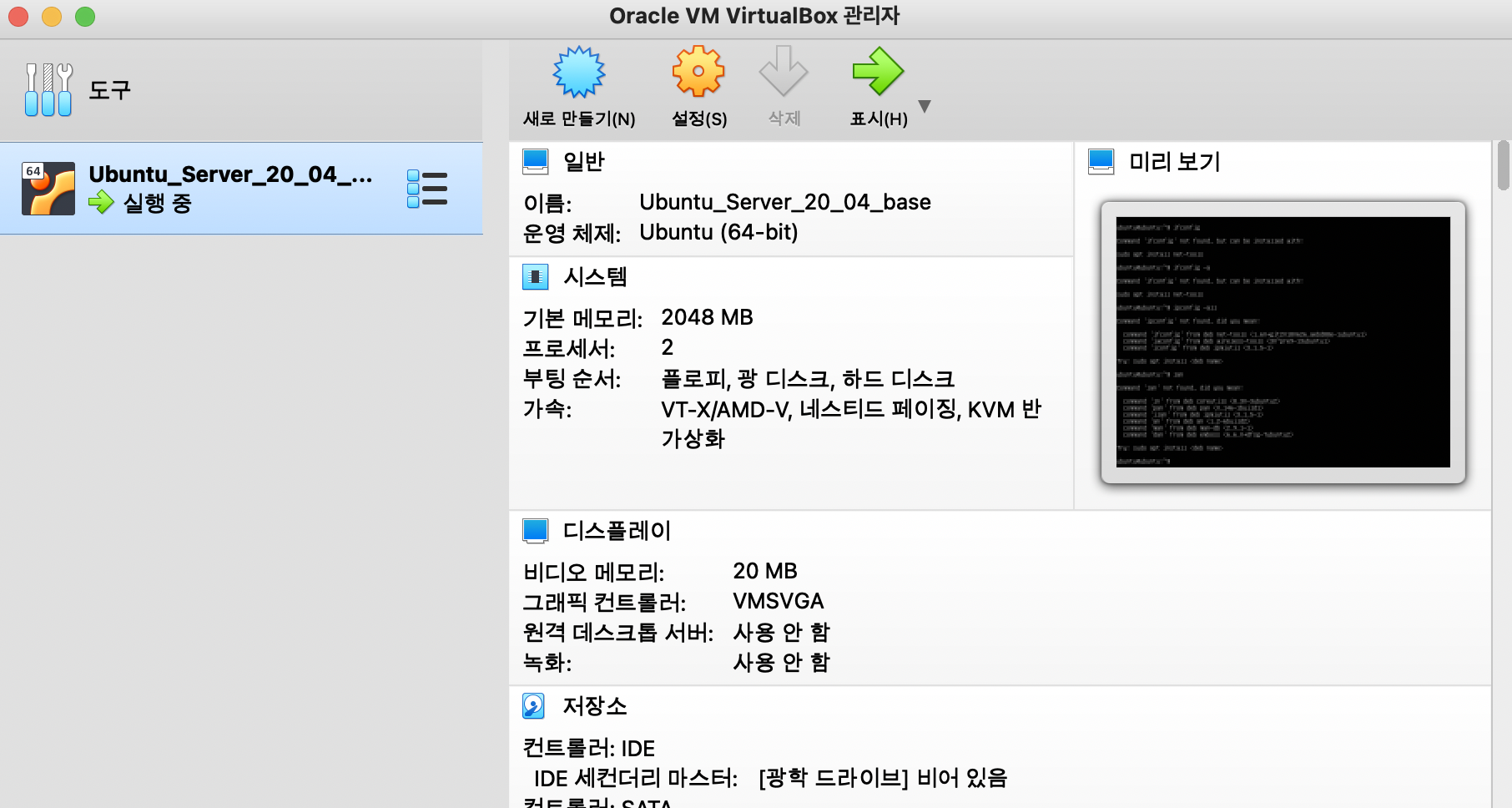
실행하고 로그인/비밀번호 ubuntun/ubuntu 로 접속하면 성공!
mac은 보안설정때문에 오류날수있는데 해결법
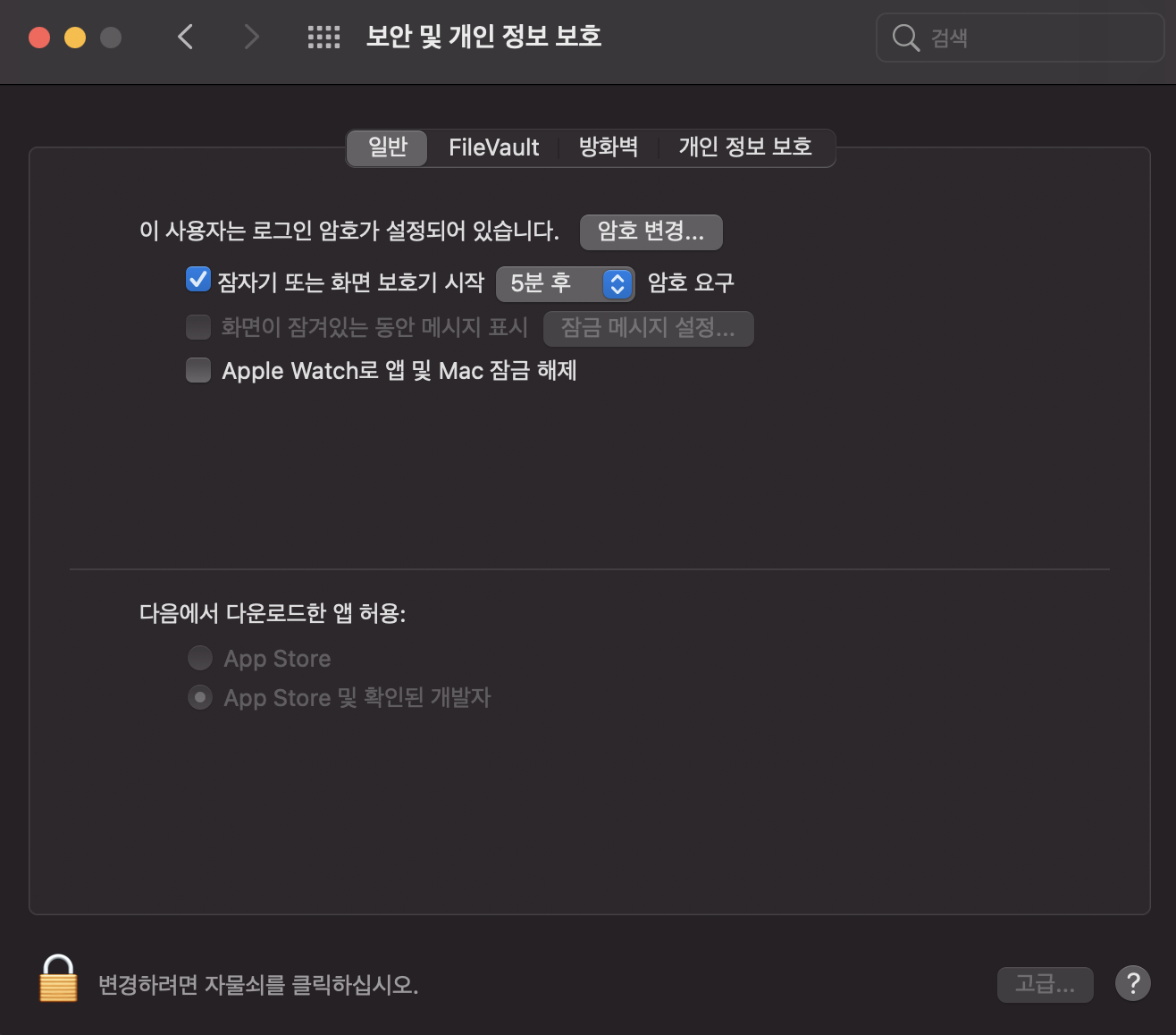
자물쇠 해제하고 oracle 어쩌구 허용하시겠습니까? 화면이 아래에뜬다. 그거 허용처리하고 리부팅하면 해결됨.


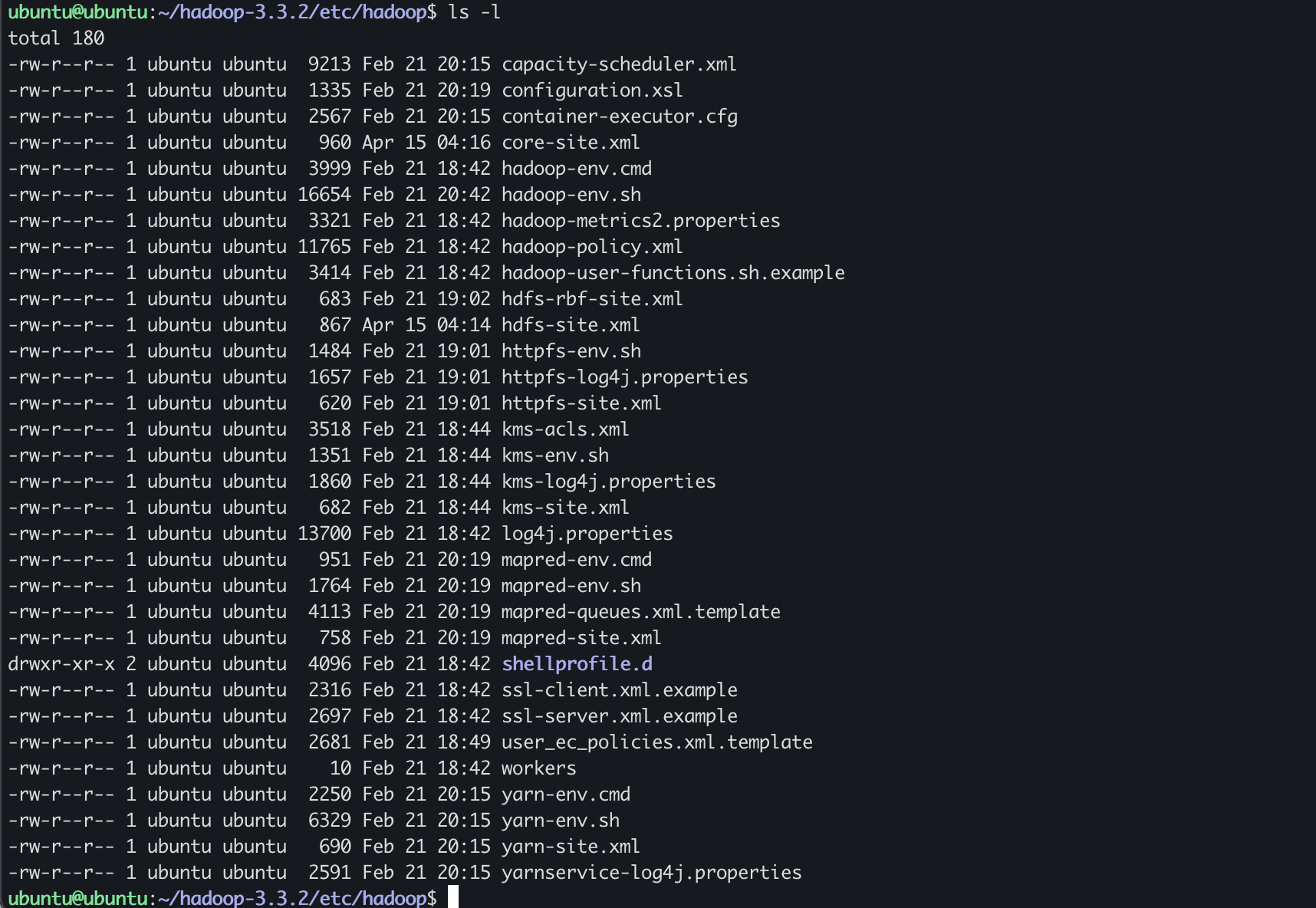
ubuntu 머신 내에서 수행
$ sudo apt install
$ sudo apt install openjdk-11-jdk 





$ nano ~/.profile 또는 $ nano ~/.bashrc
export HADOOP_HOME=/home/ubuntu/hadoop-3.3.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
$ source $HOME/.profile 또는 source $HOME/.bashrc
$ echo $HADOOP_HOME / $ echo $PATH
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
$ tar xvfz hadoop-3.3.2.tar.gz
$ cd hadoop-3.3.2

$HADOOP_HOME/etc/hadoop/mapred-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
$HADOOP_HOME/etc/hadoop/core-site.xml
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar wordcount $HADOOP_HOME/README.txt $HOME/outputwordcount 를 하는 프로그램을 수행해서 홈디렉토리 output 에 저장하겠다.!
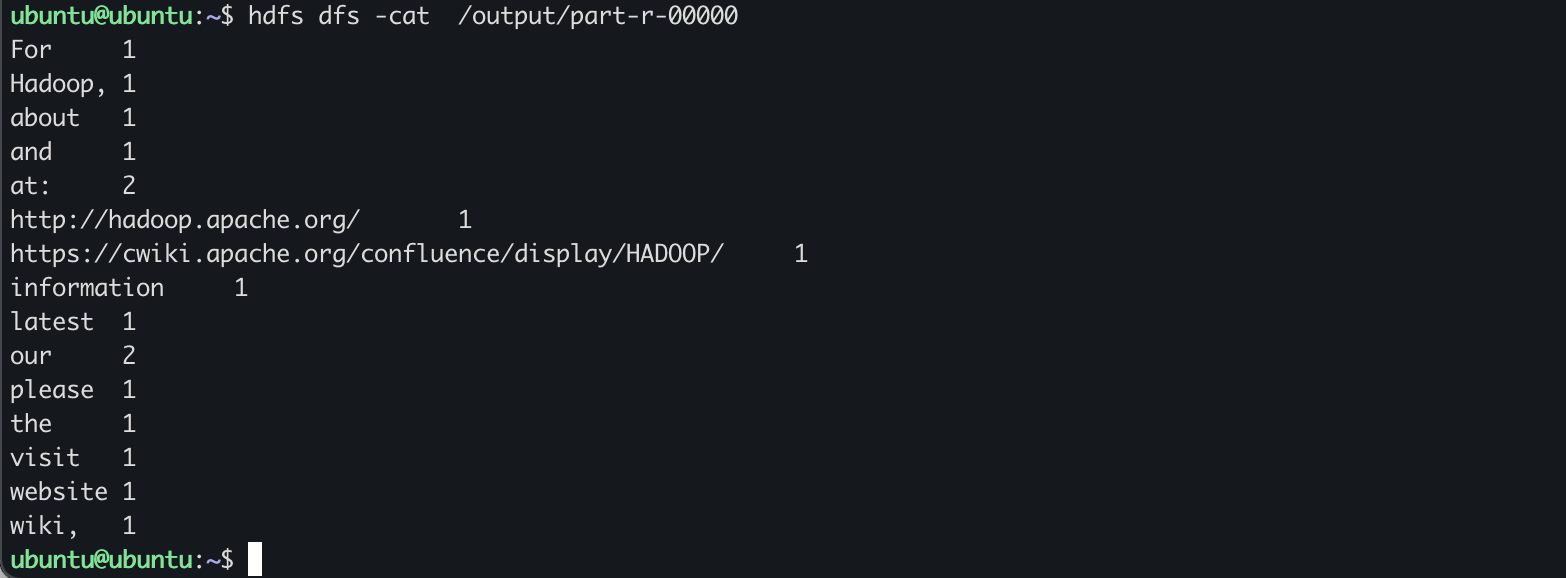
output 디렉토리로 들어가보면 part-r-00000 이라는 파일이 생성되어있음!
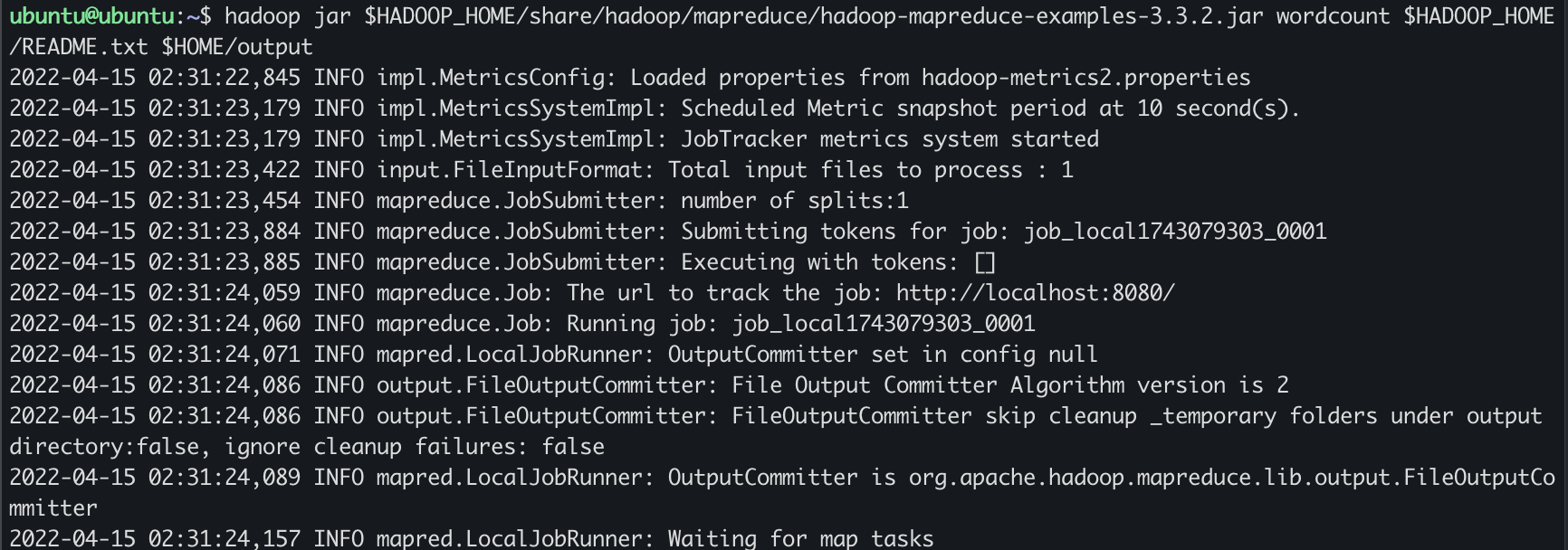
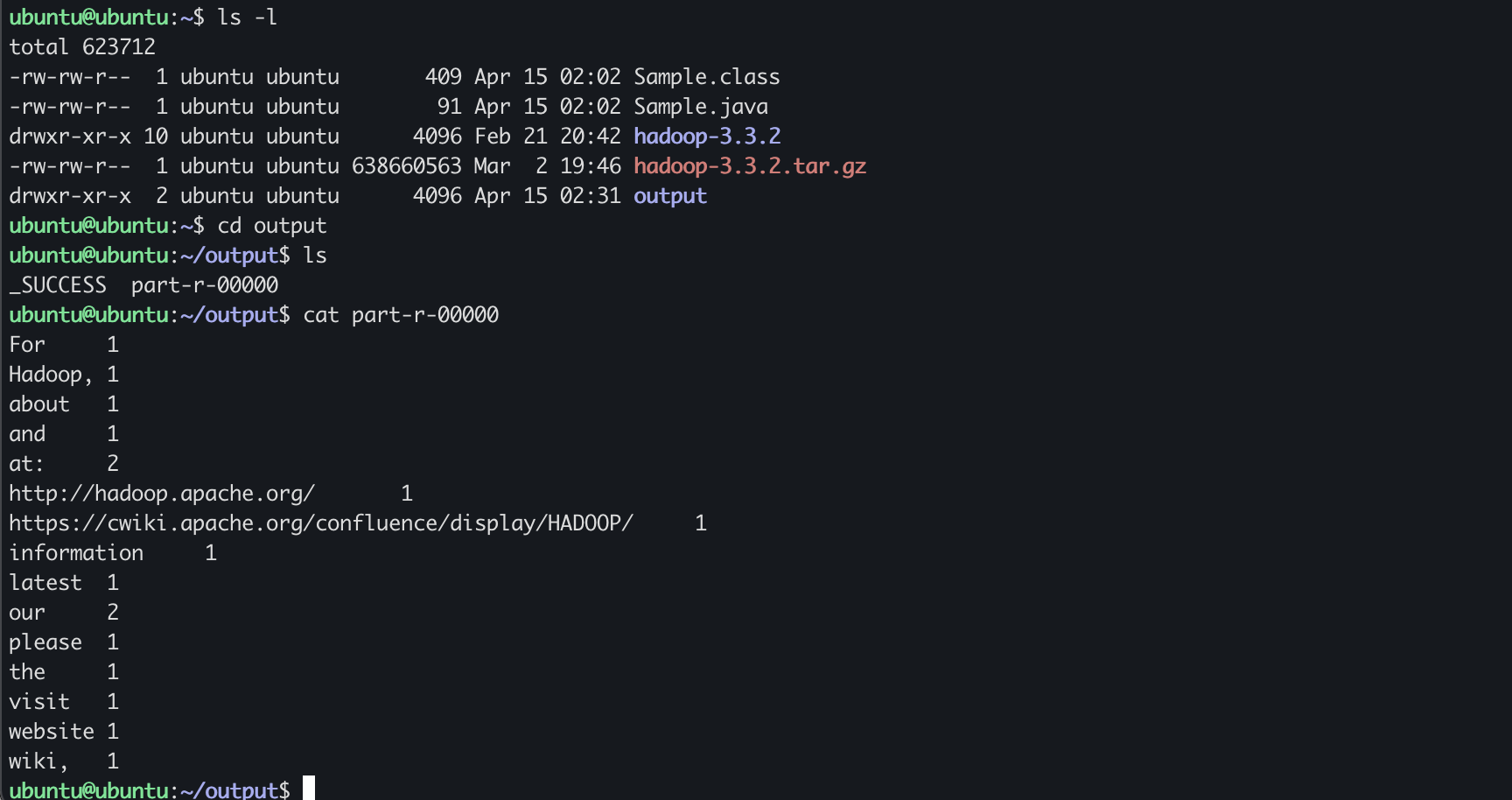
- Standalone : 프로그램만 실행하는 방식






https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html




core-site.xml , hdfs-site.xml 수정
Ubuntu 는 리부팅후에 tmp 디렉토리 내부를 날려버리므로 실습한 내용이 날라가지 않도록 temp폴더를 새로 만들어서 거기로 지정하자.


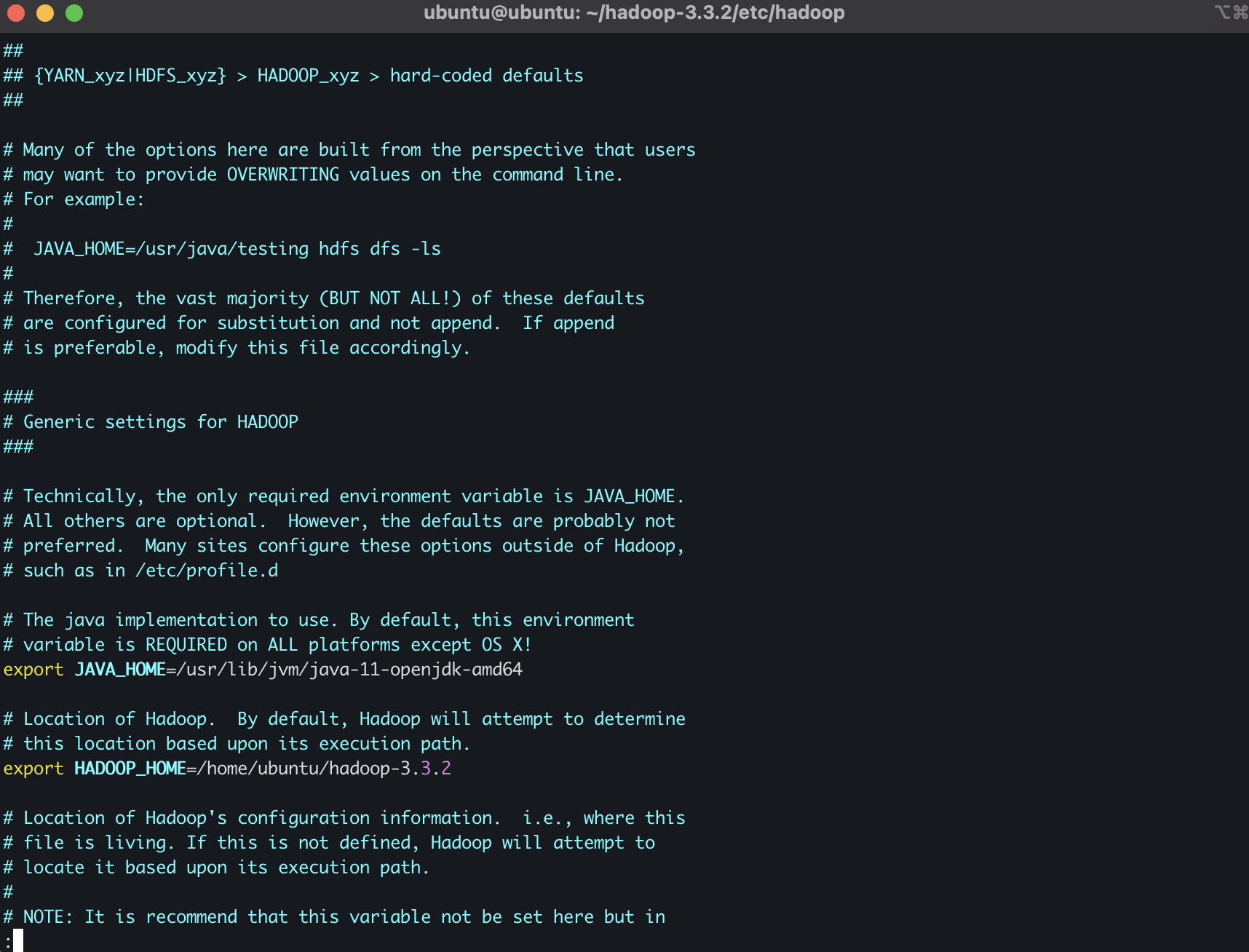
- hadoop-env.sh 파일 내용 수정

ssh 자동로그인 설정
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
테스트
$ ssh localhost비밀번호 입력 없이 접속되면 성공인것!

https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
여기 사이트에서 갖다 붙여넣어도 된다~~



$ hdfs namenode -format 또는 $ hadoop namenode -format

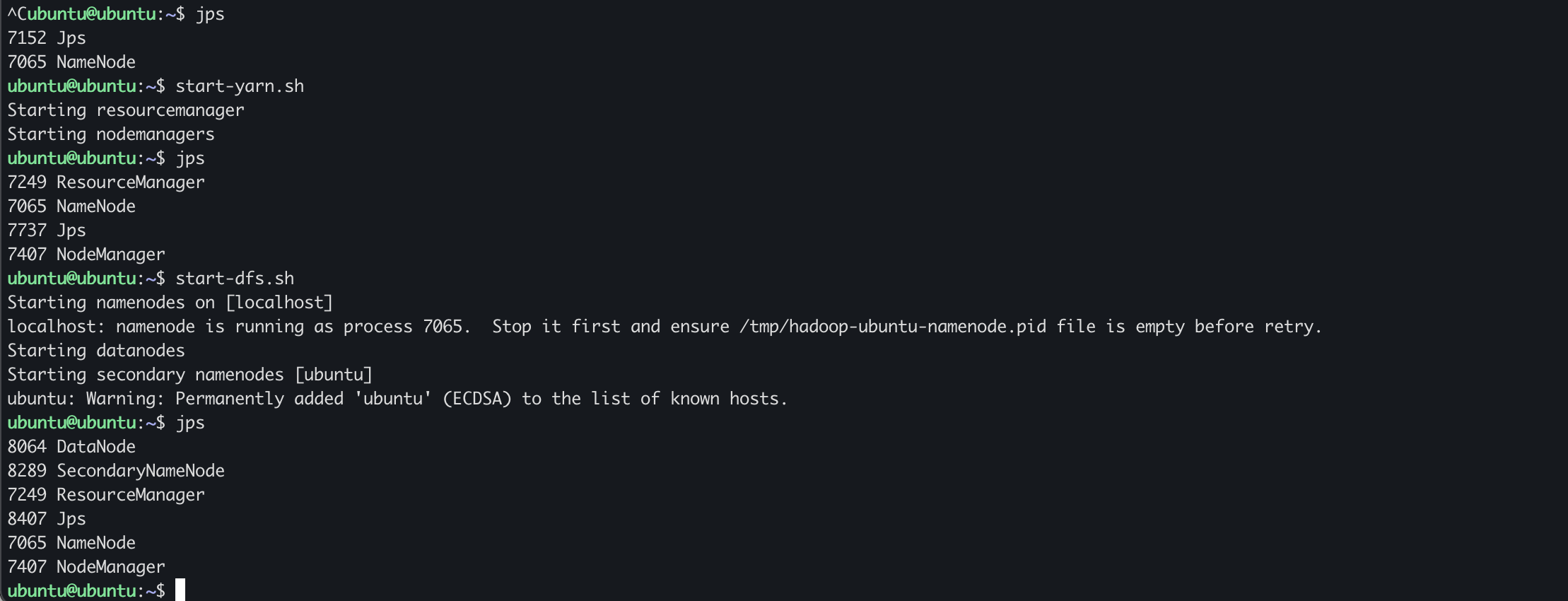
jps 를 입력했을 때 jps 제외하고 5개가 떠있으면 된다.

ubuntu@ubuntu:~$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - ubuntu supergroup 0 2022-04-15 05:04 /input
ubuntu@ubuntu:~$ hdfs dfs -put $HADOOP_HOME/README.txt /input
ubuntu@ubuntu:~$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - ubuntu supergroup 0 2022-04-15 05:05 /input
ubuntu@ubuntu:~$
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar wordcount /input/README.txt /output
$ hdfs dfs -cat /output/part-r-00000 | more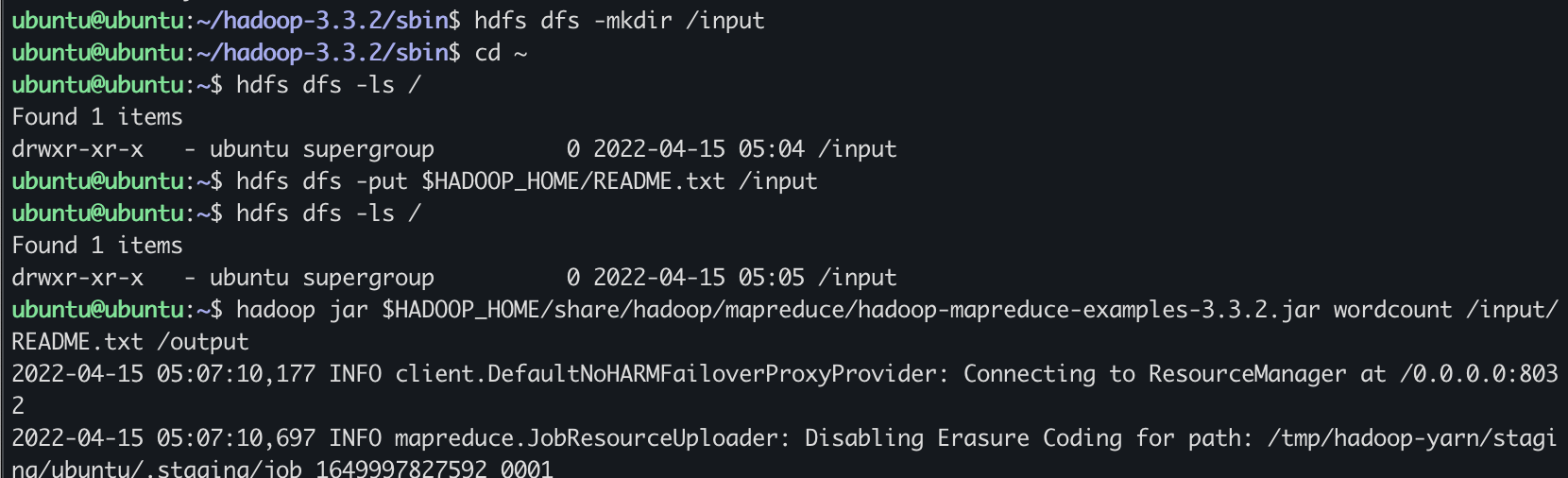

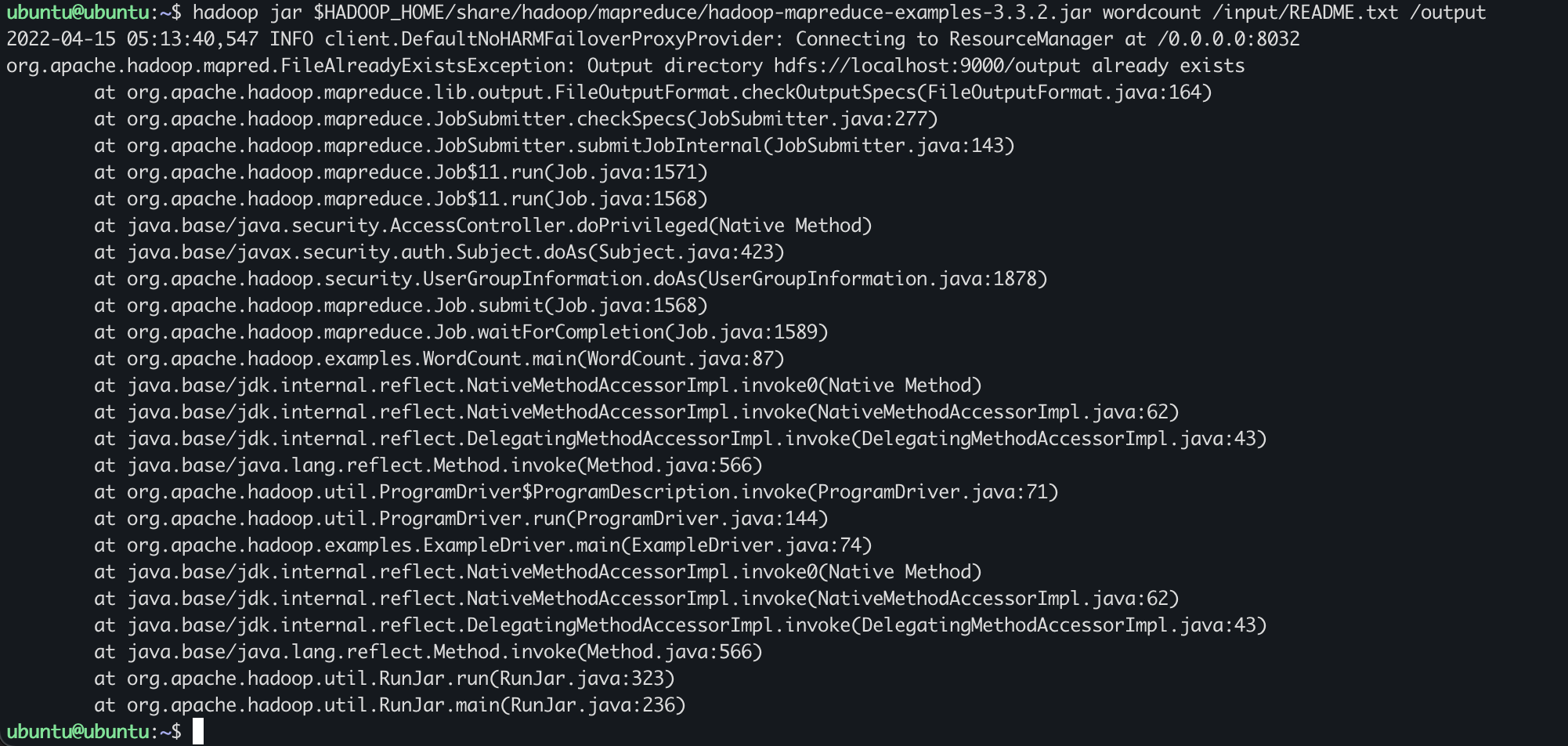
똑같은 프로그램을 두번 실행하면 오류가 발생한다.!
똑같은 /output 폴더로 하면 덮어써질거같지만 그렇지않음.
덮어쓰기가 안되므로 똑같은 출력폴더를 이름으로 지정하면 에러가 난다.!




wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1oaq1XvmPSyLBrtZkpncuC7YpG10tQi8U' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1oaq1XvmPSyLBrtZkpncuC7YpG10tQi8U" -O data.tar.gz && rm -rf /tmp/cookies.txt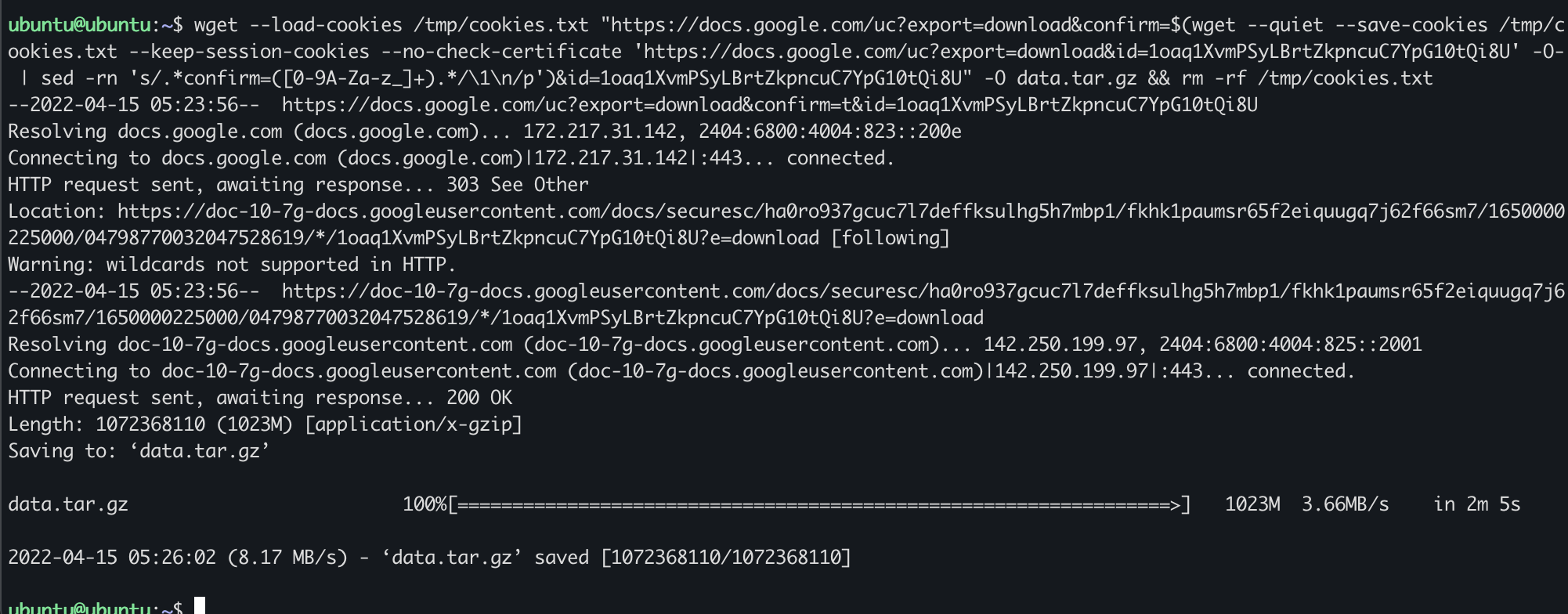
$ tar xvfz data.tar.gz
$ cd data
$ hdfs dfs -put 2M.ID.CONTENTS /input
$ hdfs dfs -ls /input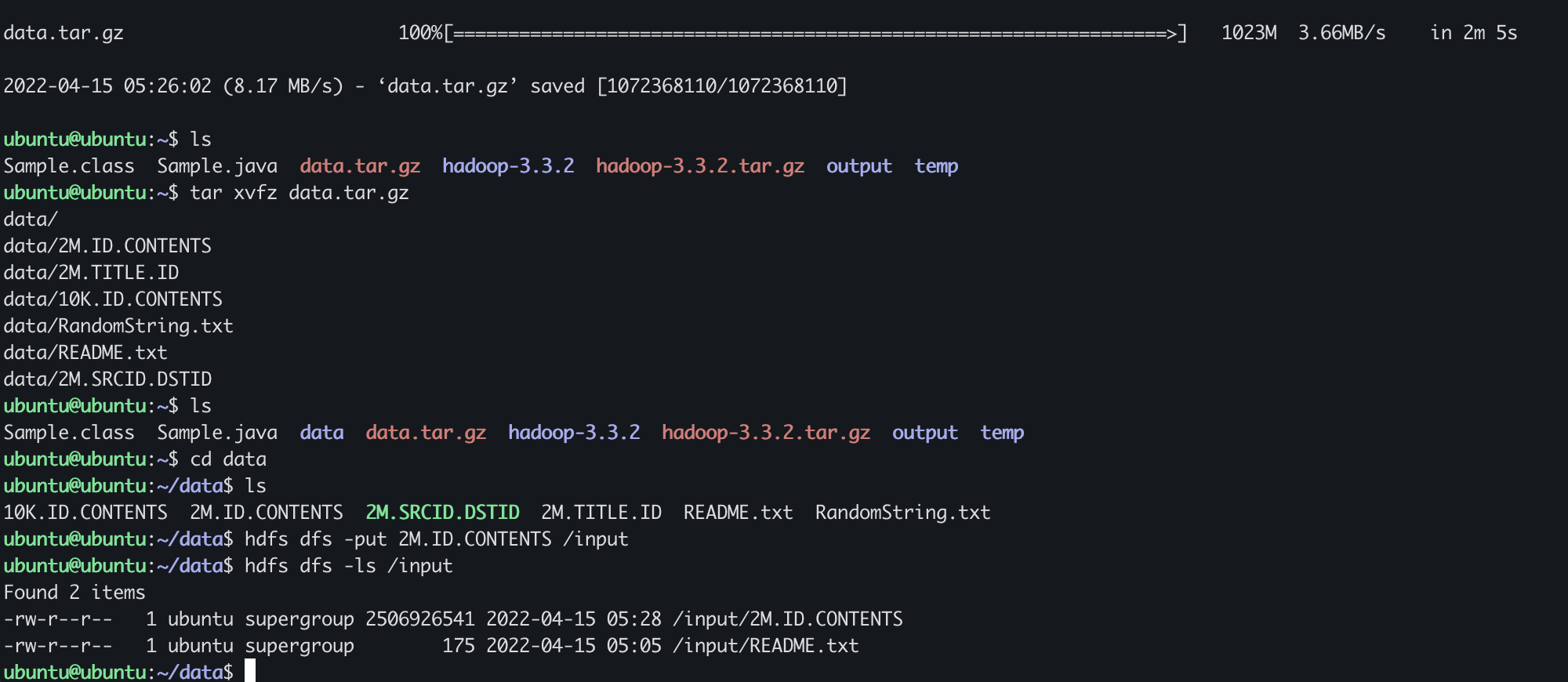

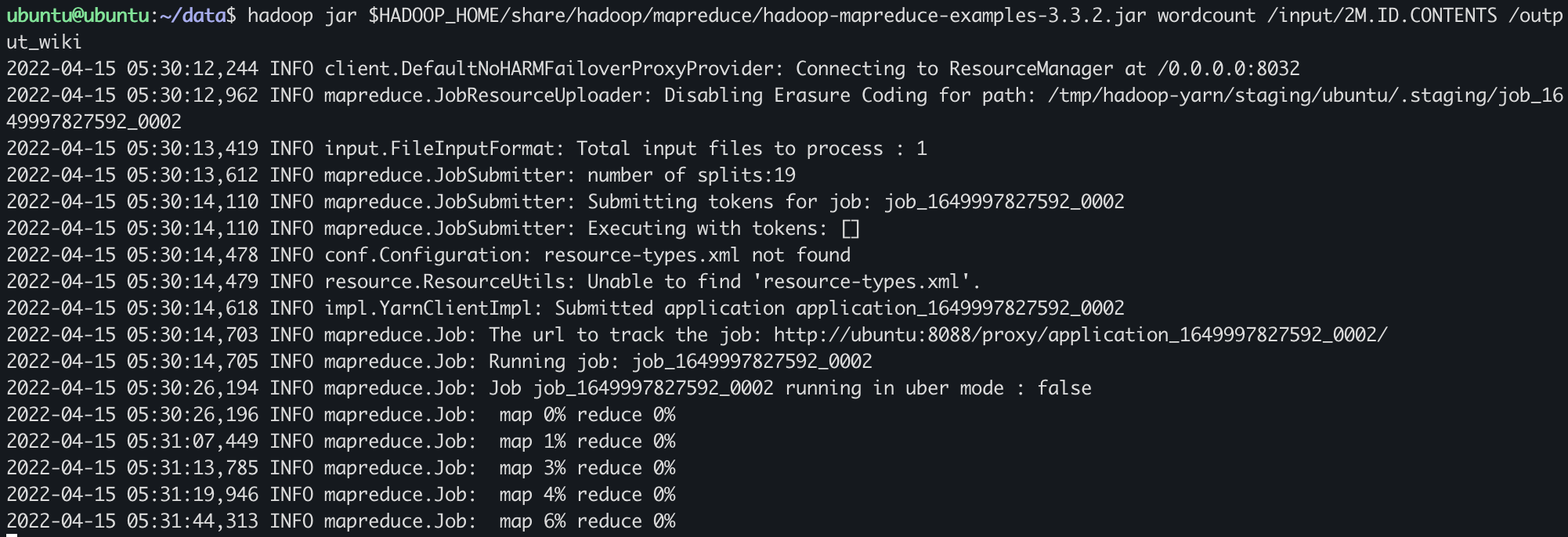
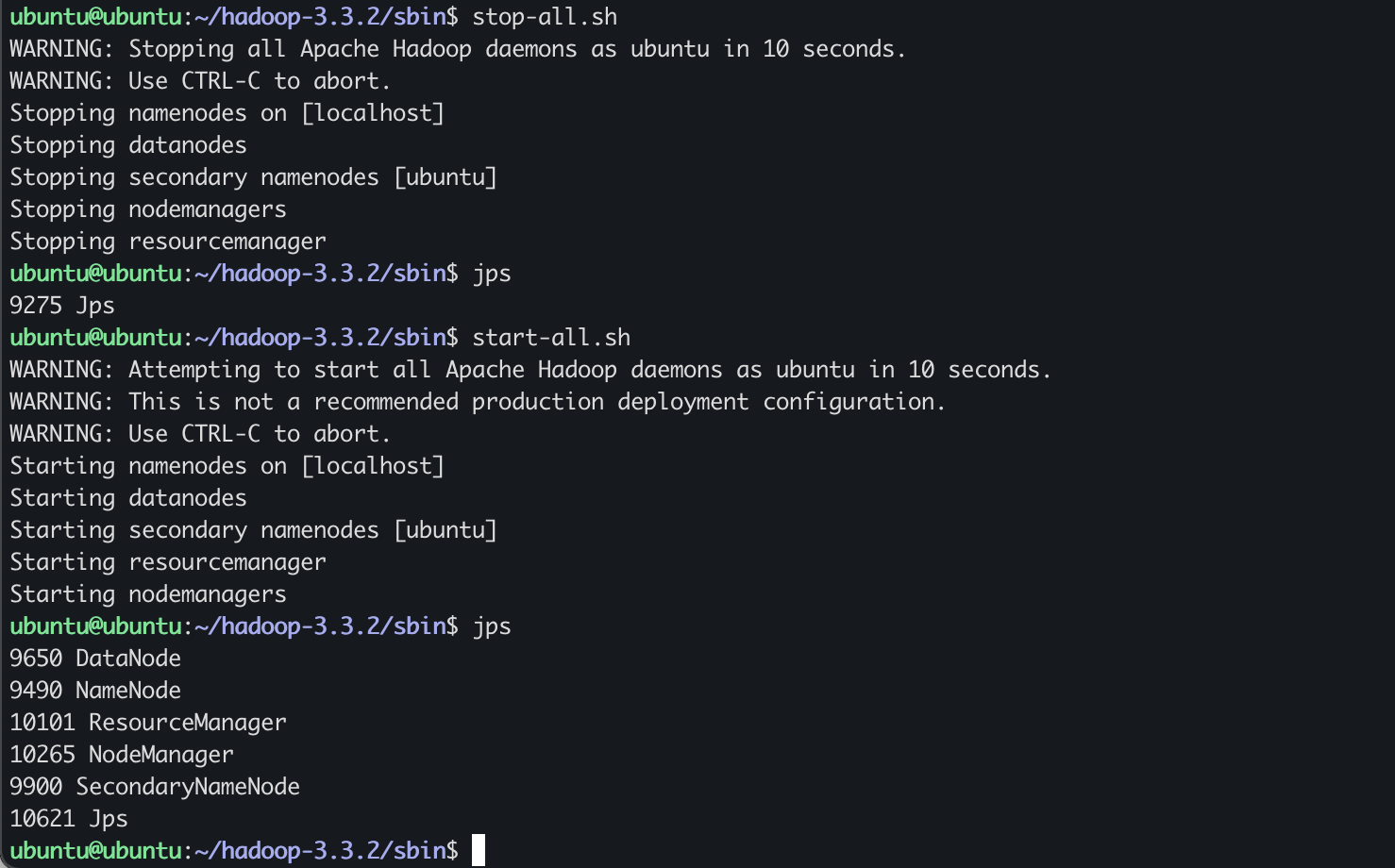
만약 0%, 0% 에서 계속멈춰있으면 가상머신을 껐다 키고 해보기
껐다켰을때 start-dfs.sh jps start-yarn.sh 해야함
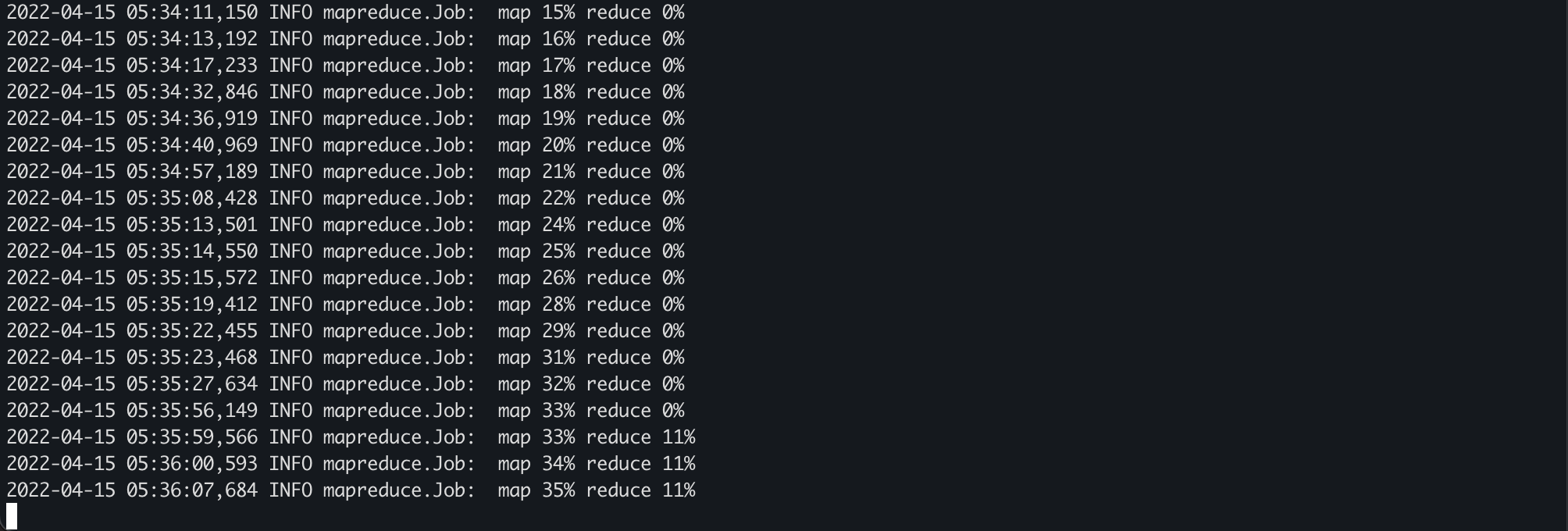
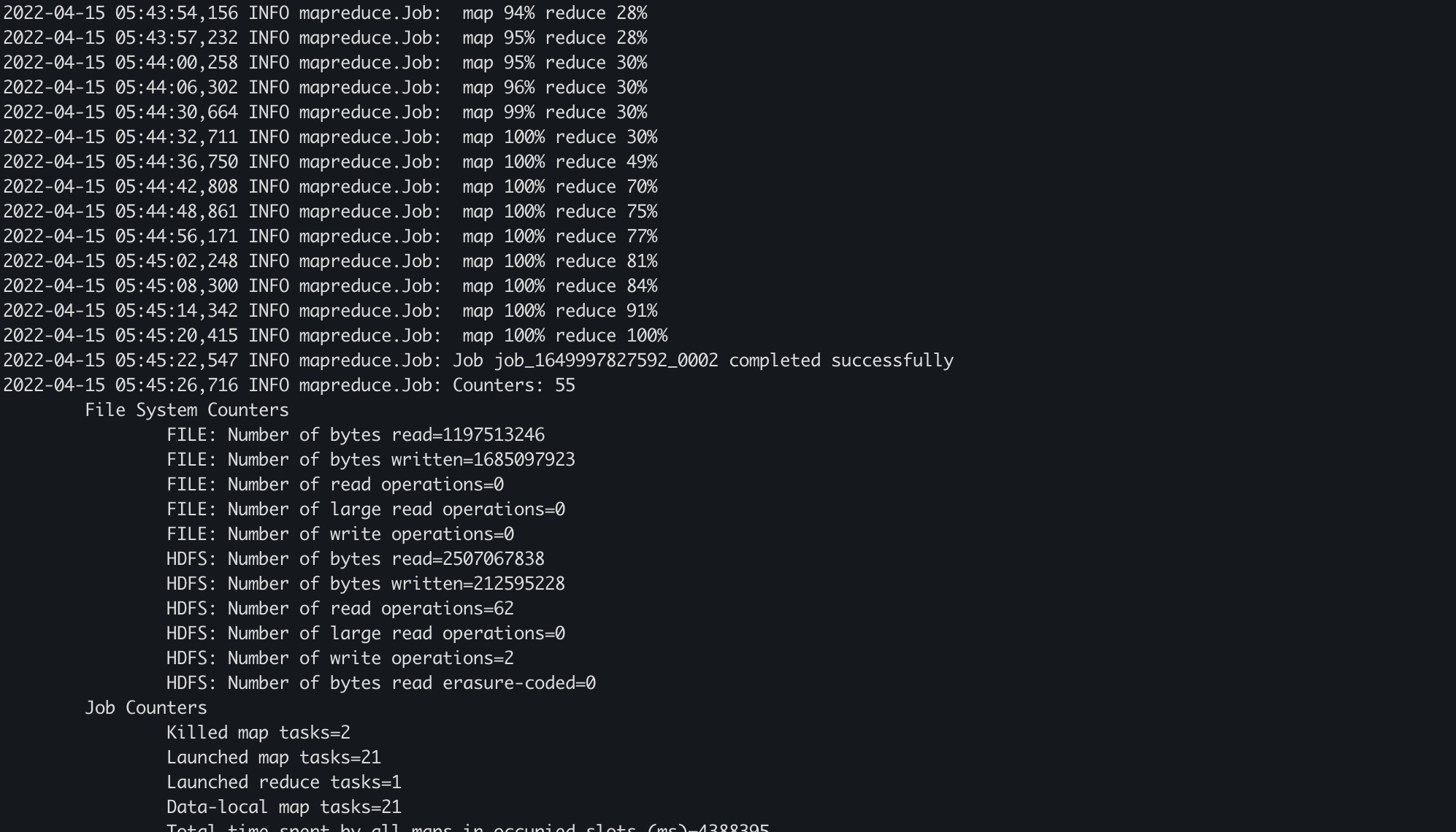
% 값이 점점 올라가는게 보인다.
Virtual box 종료하기
sudo shutdown -h now 빅데이터 프로세스
- 수집
- 저장 - HDFS
- 처리/쿼리 - MapReduce, Spark RDD/Spark SQL
- 분석 - R / 딥러닝 / 데이터사이언스
- 시각화
빅데이터 분석이 진짜 빅데이터인가?
총 830만 라인중에서 sample 에 해당하는거만 출력해서 보여준다.


Hadoop의 Mapreduce 보다 똑같은작업인데 더 빠른애가 나왔다!!!
걔가 바로 스파크임!!!
끝.
