Unsupervised 방법으로 문장 embedding을 효율적으로 수행할 수 있는 SimCSE를 소개하는 논문입니다. Random dropout mask를 활용하여 input 스스로를 예측할 수 있도록 학습을 수행합니다.
[Abstract]
해당 논문은 문장 embedding 에서 SOTA를 달성한 간단한 contrastive learning framework인 SimCSE를 소개합니다. 먼저 input 문장을 넣어 input 문장에 standard droput을 noise로 활용한 결과를 contrastive 목적식에 따라 예측하는 unsupervised SimCSE를 소개합니다. 해당 논문에서는 dropout을 미묘한 data augmentation으로 생각하였고 이를 제거했을 시 representation collapase가 발생할 수 있다고 생각하였습니다. 그 후 라벨링이되어 있는 NLI dataset을 contrastive learning에 활용하여 supervised SimCSE를 소개합니다. 마지막으로 해당 논문에서 contrastive learning이 이론적으로 anisotropic한 pretrained embedding 공간을 unifrom하게 만들어준다는 것을 보였습니다.
1. Introduction
문장 embedding은 NLP의 주된 과제 중 하나이고, 다양하게 연구되고 있습니다. 해당 논문에서는 SOTA 성능의 문장 embedding을 소개하고 contrastive objective가 BERT, RoBERTa와 같은 pre-trained 언어모델과 같이 사용되었을 때 문장 embedding 학습에 효율적이라는 것을 보여줍니다. 해당 논문은 SimCSE(Simple Contrastive Sentence Embedding) framework를 제안합니다. SimCSE는 라벨링 유무와 관계없이 문장 embedding에서 좋은 성능을 보였습니다.
Unsupervised SimCSE는 noise로 dropout을 활용한 input sentence 스스로를 예측합니다. 즉, 동일한 문장을 pre-trained encoder에 2번 넣어준 후 결과로 나온 독립적으로 sampled된 drop mask를 활용한 2개의 embedding을 positive pair로 활용합니다. 해당 논문에서는 dropout이 본질적으로 약간의 data augmentation 역할을 했다는 것을 발견하였고, dropout을 사용하지 않는다면 representation collapse가 발생하게 됩니다.
Supervised SimCSE는 문장 embedding에서 NLI dataset을 활용한 것이 성공적이었다는 사실을 활용하여 NLI dataset을 contrastive learning의 supervised 문장 pair로 활용하였습니다.
SimCSE의 좋은 성능을 더 잘 이해하기 위하여 해당 논문에서는 이전 연구에서 소개된 positive 쌍 사이의 의미적인 관계를 나타내는 alignment와 학습된 embedding의 질을 측정할 수 있는 uniformity를 활용하였습니다. Contrastive learning은 문장 embedding 공간의 singular value 분포를 flatten 해주었으며 이를 통해 uniformity를 향상시킬 수 있었습니다. 또한 pre-trained 단어 embedding이 anisotropy로 좋지 않은 영향을 받고 있다는 사실과 관련성을 찾기도 하였습니다. Unsupervised SimCSE가 본질적으로 dropout noise를 통해 degenerated alignment를 피해 uniformity를 향상시켰고, 결과적으로 representation의 표현력을 높일 수 있었습니다. 또한 NLI training은 positive pair 사이의 alignment를 높여주었고 더 좋은 문장 embedding을 얻을 수 있도록 해주었습니다.
2. Background: Contrastive Learning
Contrastive learning은 의미적으로 가까운 것들은 가깝게, 그렇지 않은 것들은 멀리 떨어질 수 있는 representation 학습을 목적으로 합니다. h_i와 h_i+를 N개 쌍의 mini-batch의 의미적으로 연관있는 쌍이라고 했을 때 학습 목적식은 아래와 같습니다.

해당 논문에서는 input 문장을 BERT, RoBERTa와 같은 pre-trained 언어모델을 활용하여 encoding을 하였습니다. 그리고 contrastive learning 목적에 따라 파인튜닝을 수행합니다.
Positive instances
Contrastive learning의 주된 문제는 관련있는 쌍을 어떻게 구성하는 방법입니다. 과거 연구에서는 단어 제거, 단어 순서 변경, 단어 대체 등의 augmentation 기법들을 적용하였습니다. 하지만 NLP의 data augmentation은 NLP의 discrete nature 특성 때문에 제대로 적용되지 않습니다. 이러한 방법들 보다는 standard dropout을 적용하는 것이 더 나은 결과를 보였습니다.
Alignment and Uniformity
최근 연구에서 contrastive learning과 관련 있는 2가지 주된 특성(Alignment,Uniformity)과 representation의 질을 측정할 수 있는 지표가 제안되었습니다. Positive pair p_pos의 분포가 주어졌을 때 alignment는 pair들의 embedding 사이의 기대 거리값으로 계산됩니다.
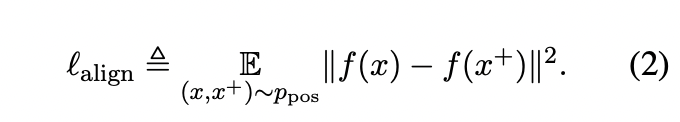
Uniformity는 embedding이 얼마나 uniformly distributed되었는지 측정합니다.
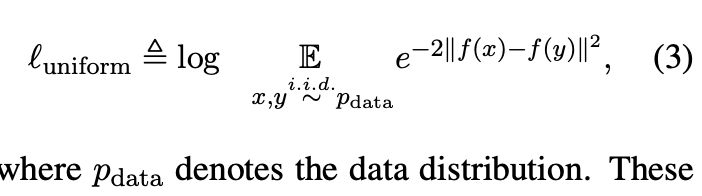
위 2가지 지표는 contrastive learning의 목적과 궤를 같이합니다. 관련이 있는 것들은 가깝게 두고, 관련이 없는(random) 것들은 hypersphere 상에서 흩뿌려 놓습니다.
3. Unsupervised SimCSE
Unsupervised SimCSE의 아이디어는 간단합니다. 문장들에 대해서 positive pair로 자기 자신을 활용합니다. 이 아이디어가 실현 가능하도록 한 주된 요소는 독립적으로 sampling된 dropout mask입니다. Transformers가 학습될 때 attention probabilities뿐만 아니라 fully-connected layer에 dropout mask가 존재합니다. z를 dropout을 위한 random mask라고 할 때, 동일한 input을 encoder에 2번 넣은 후 서로 다른 drop mask z와 z'를 적용시켜 나온 output을 아래의 목적식에 사용합니다.

Dropout noise as data augmentation
동일한 문장에 대해 positive pair embedding이 서로 다른 dropout mask를 사용하기 때문에 data augmentation 역할을 한다고 생각할 수 있습니다.
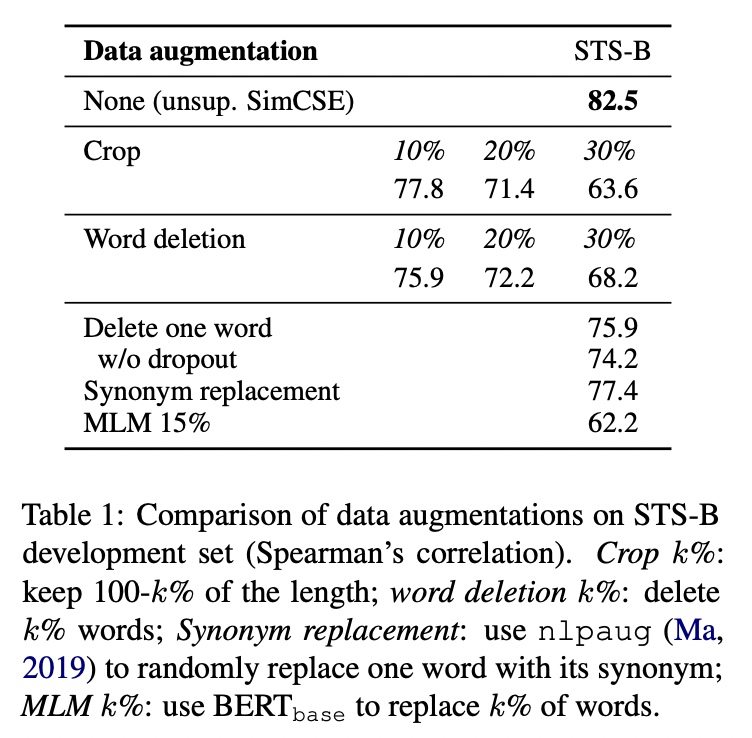
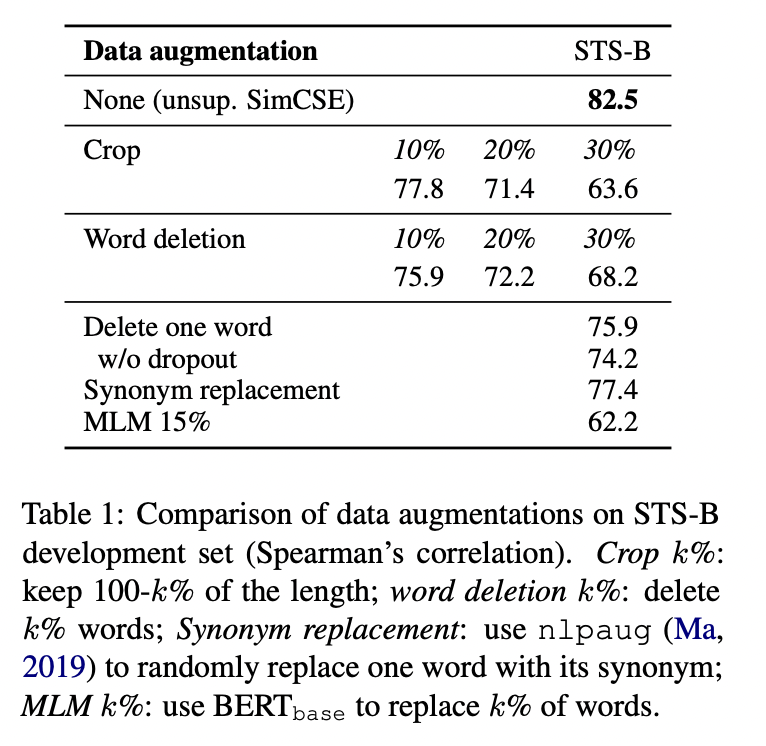
위의 결과에서 단어 하나를 제거하는 것만으로도 성능이 매우 감소하는 것을 볼 수 있고, discrete augmentation 중 그 어떤 것도 basic dropout noise 성능을 넘어서는 것이 없었습니다.
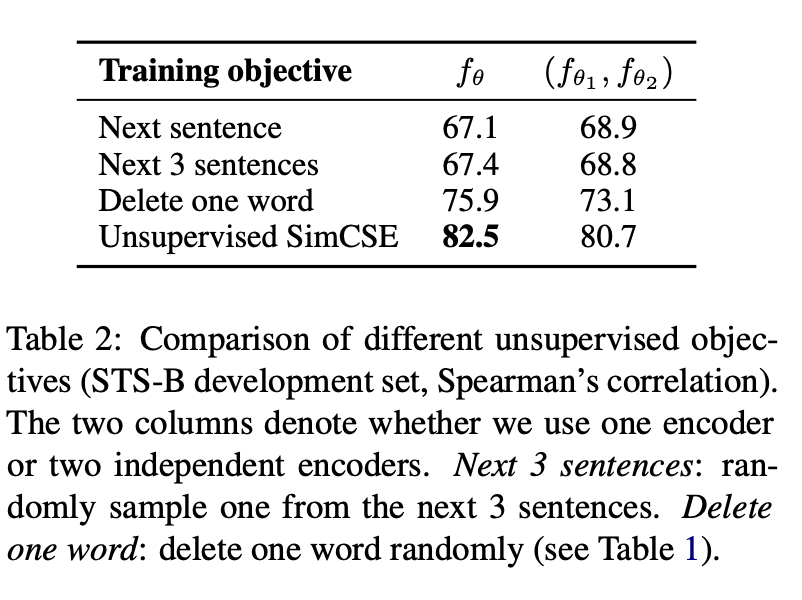
Why does it work?
Unsupervised SimCSE에서 dropout noise의 역할을 더욱 잘 이해하기 위해 아래 표처럼 다양한 dropout rate를 사용했습니다.
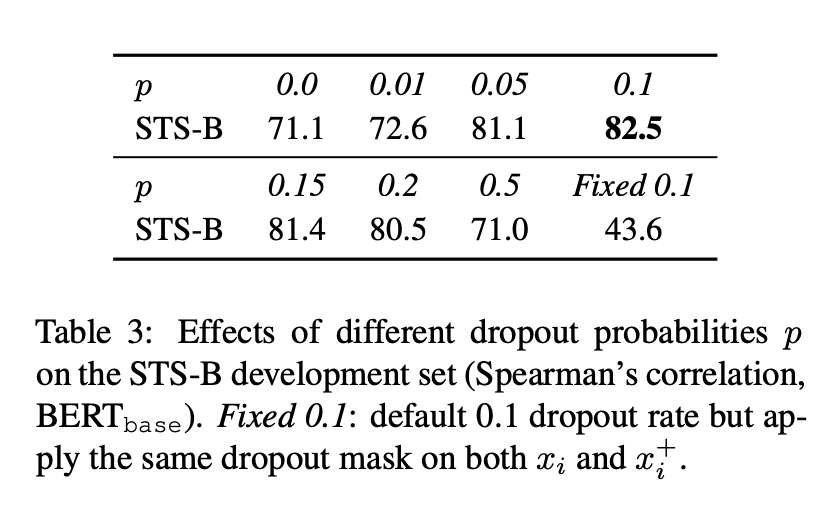
Transformers의 p=0.1을 넘어서는 dropout rate는 없었습니다.
4. Supervised SimCSE
Dropout noise를 추가하는 것이 positive pair의 좋은 alignment를 학습할 수 있도록 해준다는 것을 보였습니다. 과거 연구에서 문장 embedding을 위해 NLI dataset을 활용하는 것이 효율적이었다는 것이 밝혀졌습니다.
Choices of labeled data
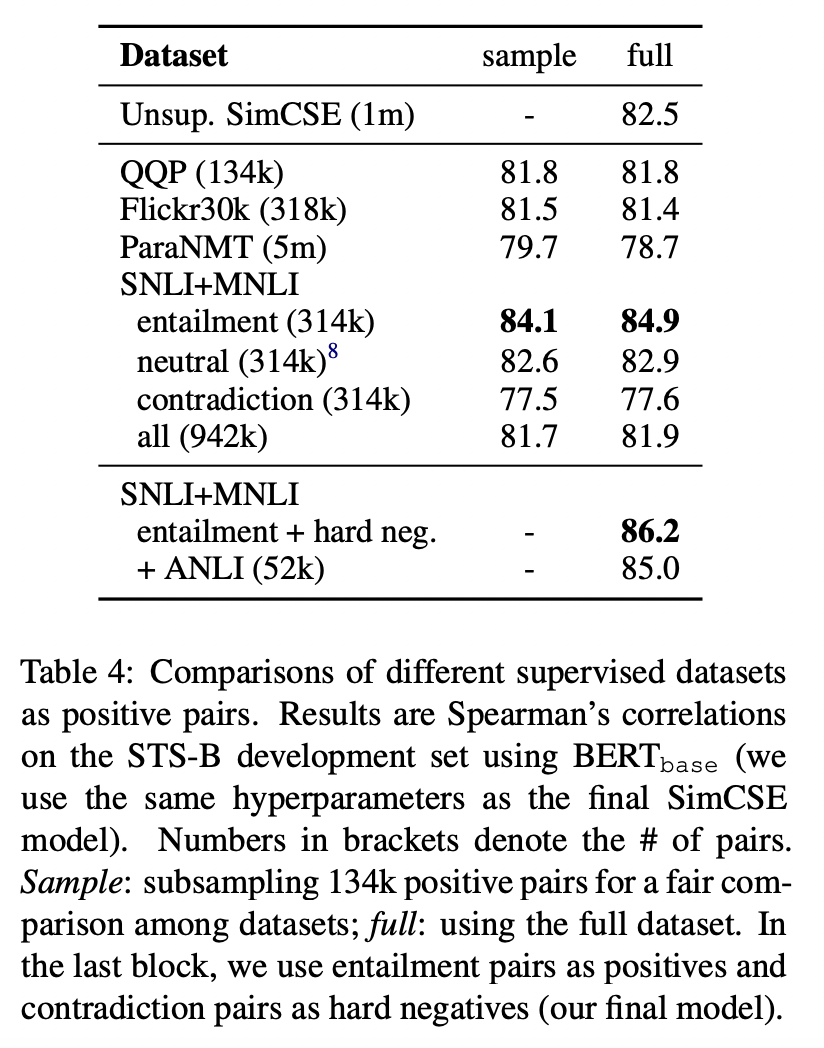
Contradiction as hard negatives
NLI dataset에서 contradiction 쌍을 hard negative로 활용하였습니다. 그 결과 학습 목적식을 아래와 같이 확장시킬 수 있었습니다.

5. Connection to Anisotropy
최근 연구들에서 laguage representation에서 anisotropy 문제가 발생하는 것이 밝혀졌습니다. 이는 학습된 embedding들이 vector 공간에서 narrow cone 형태로 존재하며 이는 embedding들의 표현력을 제한합니다. 한 연구에서 이러한 현상을 representation degeneration 문제라고 부르며 tied input/output embedding으로 학습된 언어모델들이 anisotropic word embedding을 갖게된다고 설명하였습니다. 또 다른 연구에서는 word embedding 행렬의 singular value가 급격하게 감소한다고 하였습니다. 즉, 몇개의 주된 singular value를 제외하고서는 대부분이 0에 가깝다는 것을 의미합니다.
이를 해결할 수 있는 간단한 방법은 post-processing 입니다. 주된 principal components를 제거하거나 embedding을 isotropic 분포로 mapping하는 것입니다. Contrastive objective는 sentence-embedding 행렬의 singular value 분포를 flatten 시켜줍니다
과거 연구에 따르면 negative instance가 매우 많을 때, contrastive learning의 목적식은 아래와 같이 근사할 수 있습니다.

6. Experiments
6.1 Evaluation setup
문장 embedding의 주된 목표는 의미적으로 유사한 문장들을 묶는 것입니다.
Semantic textual similarity tasks
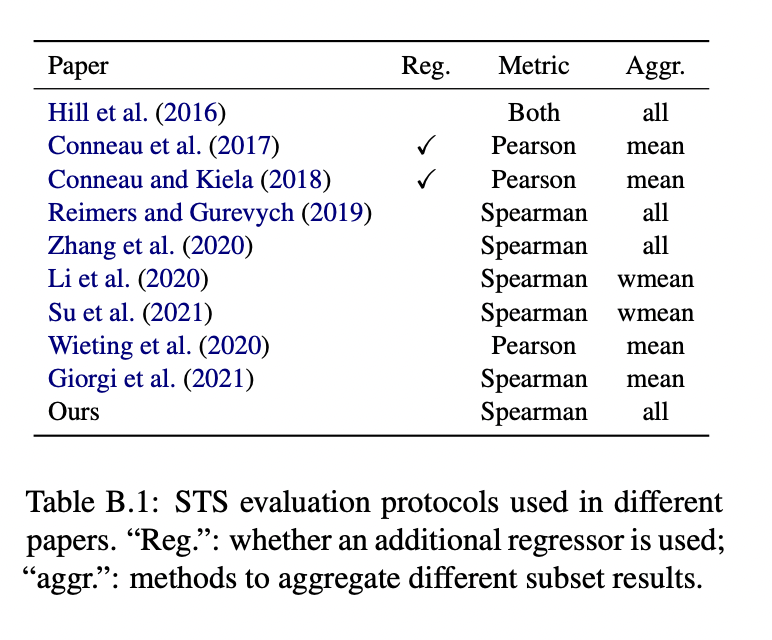
Training details
6.2 Main Results
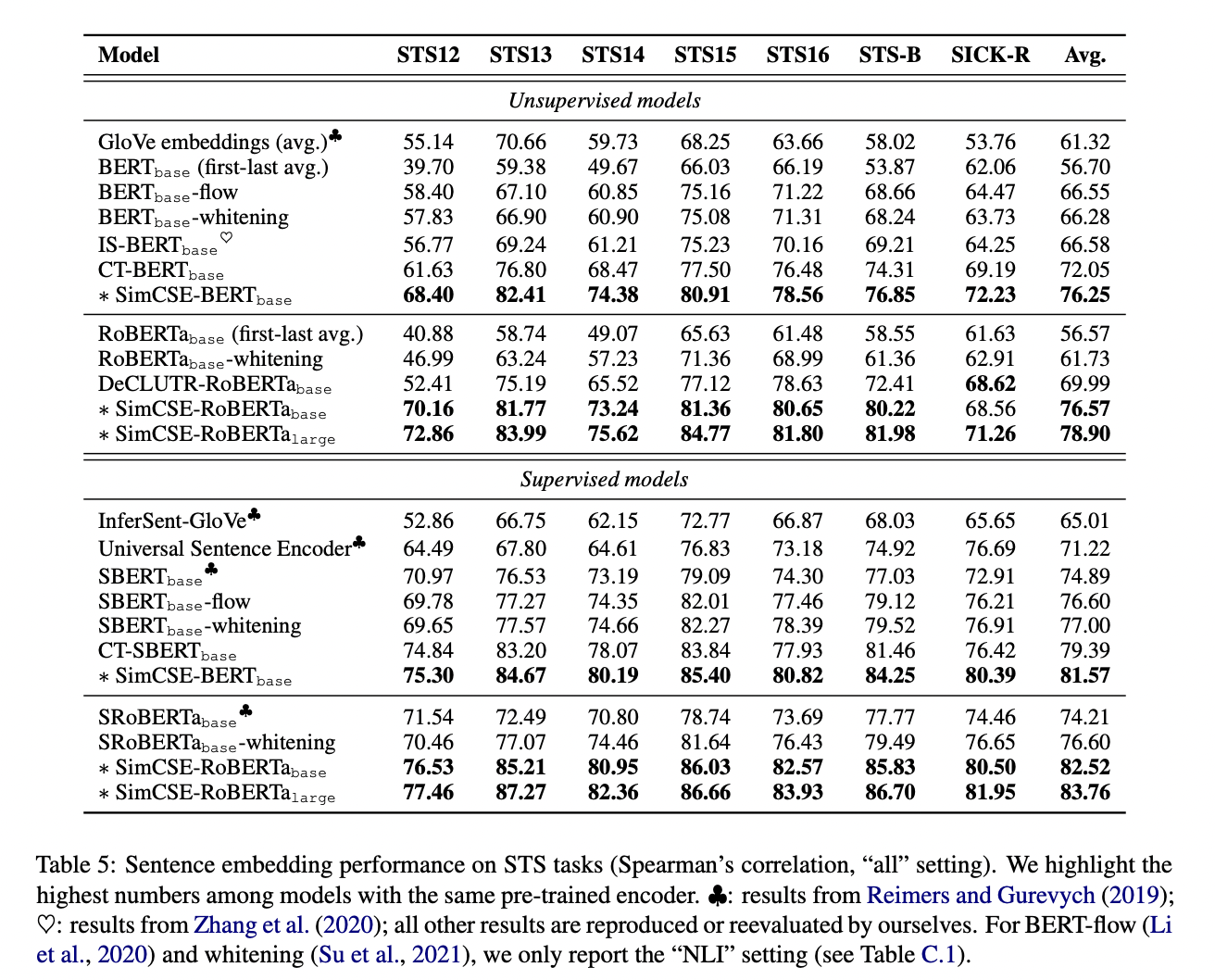
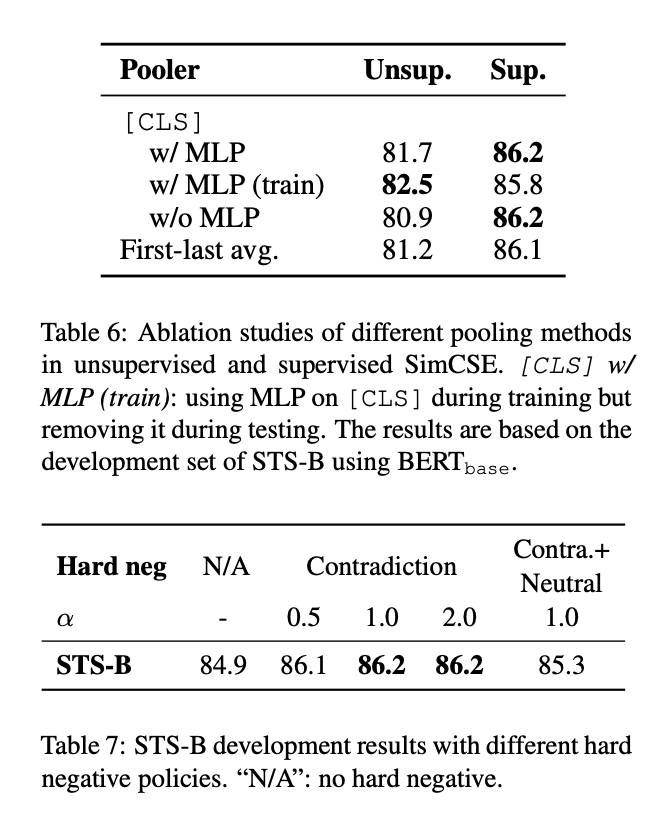
6.3 Ablation Study
7. Analysis
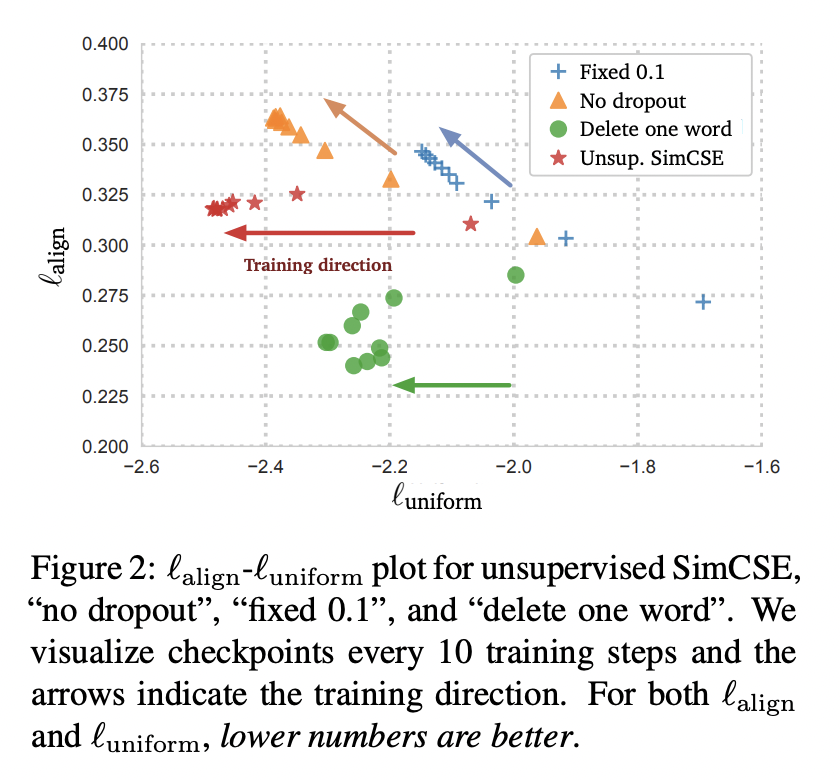
Uniformity and alignment
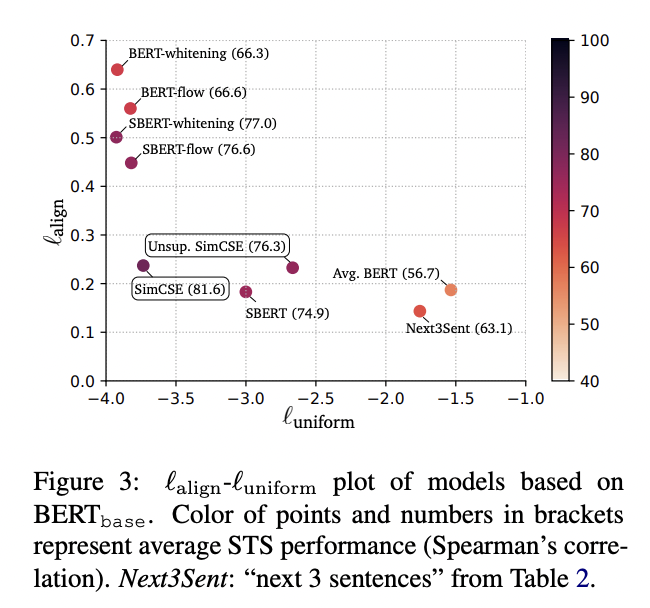
(1) Pre-trained embedding은 alignment는 좋지만, uniformity는 좋지 않습니다.
(2) BERT-flow, BERT-whitening과 같은 post-processing은 uniformity를 크게 향상시키지만 alignment에 있어서 여전히 degeneration의 영향을 받습니다.
(3) Unsupervised SimCSE는 good alignment를 유지하면서 uniformity 역시 향상시킵니다.
(4) SimCSE에 supervised data를 추가하는 것은 alignment 향상에 도움을 줍니다.
Qualitative comparison

8. Related Work
문장이 주어졌을 때 주변 문장을 예측하는 분포 가설을 기반에 둔 이전의 문장 embedding은 n-gram embedding이 더 나은 결과를 보인다는 word2vec의 아이디어를 약간 변형한 것입니다.
9. Conclusion
해당 논문에서는 문장 embedding에서 SOTA를 보인 단순한 contrastive learning framework인 SimCSE를 소개하였습니다. Dropout을 noise로 활용하여 input 문장 스스로를 예측에 활용하는 unsupervised SimCSE와 NLI dataset을 활용한 supervised SimCSE 2가지가 있었습니다. Alignment와 uniformity 2가지 측면에서 SimCSE가 다른 모델들과 비교하였을 때 어떠한 점이 다른지 분석을 진행하였습니다.
해당 논문에서 제안한 unsupervised 방법은 다양한 NLP task에 적용될 수 있을 것이라 생각합니다.
