SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
Paper_review
BERT에 대표적으로 활용되는 Subword Segmentation인 SentecePiece를 소개하는 논문입니다. 기본적인 Concept을 확인할 수 있으며 SentecePiece에서 공개한 Git을 통해 코드를 확인할 수 있습니다.
[Abstract]
해당 논문은 신경망 기반의 언어 처리를 위해 고안된 언어에 의존하지 않는(language-independent) subword tokenizer와 detokenizer인
SentencePiece를 소개합니다. 기존에 있던 subword segmentation tool들은 input을 단어들로 pre-tokenized하는 것을 가정하고 있지만 SentencePiece는 raw 문장에서 subword 모델을 직접 학습할 수 있습니다. 영어-일본어 기계번역 실험을 통해 검증 과정을 거쳤으며, raw 문장에서 높은 정확도를 학습할 수 있는 것이 밝혀졌습니다.
1. Introdcution
딥러닝은 자연어 처리에 큰 영향을 미쳤으며 신경망 기계번역(Neural machine translation, NMT)은 높은 성능을 위해 신경망을 활용하기 때문에 유명세를 얻기 시작했습니다. NMT는 몇몇 shared-task에서 두드러진 결과를 보여주었으며, 관련 자연어처리 task에 긍정적인 영향을 주었습니다.
많은 NMT 시스템들은 여전히 전통적인 통계학 기반 기계 번역(Statistical machine translation, SMT)에 활용되던 언어 의존적인(language-dependent) pre- and postprocessor(전, 후처리)를 사용하고 있습니다. Moses는 SMT에 있어서는 대표적인 도구이지만, 수작업으로 만들어졌으며 언어 의존적인 특성이 있기 때문에 NMT에서도 좋은 성능을 보이는지는 밝혀진 바가 없습니다. 또한 Moses는 공백을 기준으로 나뉘어지는 European 언어에 특화되어 개발되었기 때문에 중국어, 한국어, 일본어와 같은 non-segment 언어에는 제대로 적용할 수 없습니다. NMT가 표준화되고, 언어에 국한되지 않은 구조로 나아가고 있기 때문에 NLP community에서 단순하고 효과적이며 신경망 기반 NLP 시스템에 쉽게 통합될 수 있는 언어에 의존하지 않는 pre- and post-processor에 대한 중요도가 높아지고 있습니다.
해당 논문(demo paper)에서는 단순하며 언어에 독립적인 text tokenizer and detokenizer인 SentencePiece를 소개합니다. SentencePiece는 신경망 모델이 학습되기 전에 미리 정해진 단어의 수를 갖는 사전을 바탕으로 한 신경만 기반 text generation 시스템에 주로 활용됩니다. SentencePiece는 2개의 subword segmentation 알고리즘(BPE, uni-gram language model)을 활용합니다.
2. System Overview
SentencePiece는 Normalizer, Trainer, Encoder, Decoder 4가지로 구성되어 있습니다.
Normalizer는 Unicode 문자를 의미적으로 동일한 canonical 형태로 변환합니다.
Trainer는 normalized된 말뭉치에서 subword segmentation 모델을 학습합니다.
Encoder는 내부적으로 Normalizer를 사용하여 input text를 normalize하고 Trainer를 통해 학습된 subword sequece로 tokenize 합니다.
Decoder는 subword sequence를 normalized text로 되돌립니다.
Encoder와 Decoder는 각각 preprocessing(tokenization)과 postprocessing(detokenization) 역할을 합니다.
3. Library Design
3.1 Lossless Tokenization
아래의 예시는 언어 의존적인 preprocessing입니다. 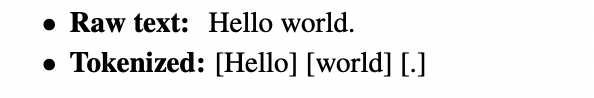
'word'와 '.' 사이에 공백이 없다는 정보가 Tokenized된 결과에서는 알 수 없습니다. Tokenized된 결과를 원본으로 되돌리는 과정인 Detokenization 이러한 irreversible operation때문에 언어 의존적이게 됩니다.
SentencePiece에서는 Decoder는 Encoder의 역변환 역할을 합니다.

위와 같은 구조를 Lossless tokenization라고 합니다. Lossless tokenization에서 normalized text를 복원할 때 필요한 모든 정보들이 사라지지 않습니다. lossless tokenization의 기본 아이디어는 input text를 Unicode 단어들의 sequence로 생각하는 것입니다. SentencePiece에서 공백은 meta symbol _ 를 붙여 표현합니다. 공백의 위치가 유지되기 때문에 명백하게 원본 text로 복원할 수 있습니다.
3.2 Efficient subword training and segmentation
기존에 존재하던 subword segmentation tool들은 subword 모델을 pre-tokenized sentence로부터 학습했습니다. SentencePiece를 사용한다면 pre-tokenization을 반드시 사용할 필요는 없습니다. Pre-tokenization은 때로 lossless tokenization을 어렵게합니다.
SentecePiece는 학습과 segmentation의 속도를 높이기 위한 다양한 기술들을 사용합니다.
3.3 Vocabulary id management
SentencePiece는 단어를 id로 바꾸거나 반대 과정도 가능하게 하도록 사전을 id로 mapping하는 것을 다룹니다. 기존의 subword-nmt들이 merge operation의 횟수를 정해둔 반면, SentencePiece는 사전의 최종 크기를 미리 정해둡니다.
3.4 Customizable character normalization
Character normalization은 의미적으로 동일한 Unicode 단어들로 이루어진 실제 text data를 다루기 위해 매우 중요한 preprocessing입니다. Lowercasing(소문자로 모두 바꾸는 과정)은 효과적인 normalization의 하나입니다.
SentencePiece는 기본적으로 Unicode NFKC normalization을 활용하여 input text를 normalize합니다. SentencePiece의 normalization은 string-to-string mapping과 leftmost longest matching을 통해 이루어집니다.
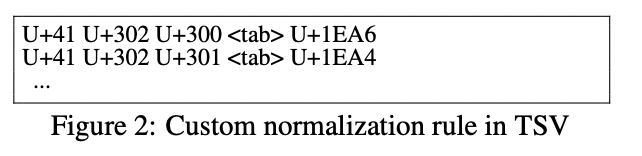
SentecePiece는 TSV 파일을 통해 정의된 규칙을 기반으로 하는 custom normalization을 활용할 수 있습니다.
3.5 Self-contained models
최근들어 많은 연구가들은 본인들의 실험결과의 수월한 재현을 위해 pre-trained NMT 모델들을 제공합니다. 하지만 실험을 위해 data를 어떻게 preprocess 했는지는 밝히지 않는 경우가 많습니다. 사소한 preprocess의 차이를 통해 BLEU 점수에 큰 차이가 발생할 수 있다는 연구 역시 존재합니다.
이상적으로는 동일한 모델 파일을 사용한다면 언제든지 동일한 실험 세팅을 재현할 수 있도록 preprocessing을 위한 규칙과 파라미터들이 self-contained manner 방식으로 model file에 포함되도록 해야 합니다.
SentencePiece는 self-contained되도록 구성되었습니다. 모델 파일은 사전과 segmentation parameters뿐만 아니라 pre-compiled finite state transducer 역시 포함합니다.
3.6 Library API for on-the-fly processing
main NMT 학습 이전에 raw input은 전처리되고 id sequence로 변환됩니다. 이 때 사용되는 standalone preprocessor는 user-facing NMT에 바로 합쳐질 수 없다는 문제점과 sub-sentence level data augmentation과 모델의 성능과 robustness를 높이기 위한 noise injection을 어렵게 한다는 문제점이 있습니다.


4. Experiments
4.1 Comparison of different preprocessing
영어-일본어 번역을 통해 서로 다른 preprocessing의 성능을 비교합니다.
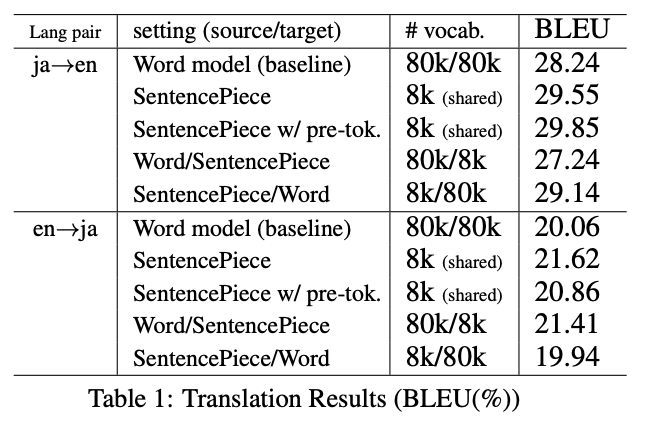
subword segmentation with SentencePiece는 word model과 비교하였을 때 항상 좋은 성능을 보여줍니다.
pre-tokenization은 반드시 좋은 성능을 보여주는 것은 아닙니다.
일본어는 non-segmented 언어이기 때문에 pre-tokenization은 최종 사전을 결정하는 데 큰 영향을 줍니다.
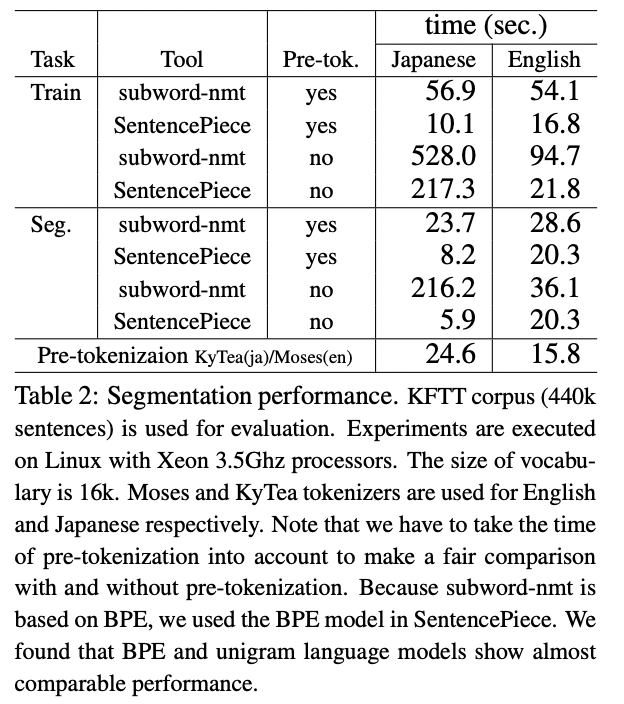
4.2 Segmentation performance
5. Conclusions
해당 논문에서는 신경만 기반의 text processing을 위해 고안된 open-source subword tokenizer and detokenizer인 SentencePiece를 소개합니다. SentecePiece는 subword tokenization을 수행할뿐만 아니라 text를 id sequece로 바꿔주기도 합니다. Normalization과 subword segmentaion의 완벽한 재현을 위해 SentencePiece의 모델 파일은 self-contained되도록 구성되었습니다.
