Hidden-to-hidden weight matrix에 DropConnect mask를 적용하여 기존 LSTM 수행에 변화를 주지 않아도 되는 weight-dropped LSTM과 학습 최적화 방식으로 NT-ASGD를 소개하는 논문입니다.
[Abstract]
LSTM(Long Short-term memory network)와 같은 RNN(Recurrent Neural Network)는 많은 sequence learning task의 기반이 되는 block 역할을 합니다. 해당 논문에서는 단어 수준의 language modeling의 문제를 다루고, LSTM based model을 제한하고 최적화하는 방법을 찾습니다. 해당 논문에서는 hidden-to-hidden 가중치에 DropConnect를 사용하는 weight-dropped LSTM을 소개합니다. 더 나아가 average stochastic gradient 방법의 변형인 NT-ASGD를 소개합니다.
1. Introduction
딥러닝에서 효과적인 regularization 방법은 많은 연구 대상이었습니다. Neural network이 over-parameterization일 때 generalization 성능은 모델을 효율적으로 regularzie할 수 있는 정도에 의존하게 됩니다. Dropout, batch normalization 등이 좋은 결과를 보였고, feed-forward와 CNN에서 널리 사용되고 있습니다. RNN에서 이러한 방식을 단순하게 활용하는 것은 성공적이지 못했습니다. 최근 많은 연구들에서 RNN으로 이러한 regulaization 방법을 확장하는 것에 초점을 맞추고 있습니다.
Dropout을 RNN의 hidden state에 단순히 적용하는 것은 RNN이 long term dependency를 보유하는 특징을 저해하기때문에 효율적이지 못합니다. 과거 한 연구에서는 이러한 문제를 매 timestep마다 새로운 binary mask를 sampling하지 않고 동일한 dropout을 여러 timestep들에 걸쳐 적용하여 해결하고자 했습니다. 또 다른 접근방법으로는 RNN의 hidden state를 제한적으로 갱신하여 regularize하고자 했습니다.
RNN의 hidden state에 적용하는 대신 또 다른 연구에서는 recurrent matrix에 restriction을 통해 regulaize를 시도하였습니다.
또 다른 형식의 방식은 batch normalization, recurrent batch normalization, layer normaliztion과 같이 activation에 regularization을 수행하는 것입니다. 이러한 방식들은 추가적인 training parameter를 필요로하기 때문에 학습 과정이 복잡해지게 됩니다.
해당 논문에서는 효율적일뿐만 아니라 기존 LSTM의 연산 방식을 변경하지 않도록 하는 다양한 regularization 방법들은 연구합니다. Weight-dropped LSTM은 hidden-to-hidden recurrent weight에 DropConnect mask를 적용하여 recurrent regularization을 수행합니다. 또 다른 방법으로는 randomized-length BTPP(Backpropagation through time), embedding dropout, AR(activation regularization), TAR(temporal activation regularization) 등이 있습니다.
기존 LSTM의 연산 방식에 수정이 필요없기 때문에 소개하는 regularization은 NVIDIA cuDNN과 같은 black box 라이브러리에도 적용할 수 있습니다.
Deep recurrent network를 효율적으로 학습하는 방법은 최근 주목받는 주제입니다. 모델이 정의되면 학습 알고리즘은 loss function의 최솟값을 잘 찾을 수 있는 것 뿐만아니라 최솟값까지 빠르게 수렴할 수 있어야 합니다. Dropout을 사용하게 되면 학습을 지연할 수도 있기 때문에 optimizer를 선택하는 문제는 regularized model의 맥락에서 매우 중요한 사항입니다. SGD(Stochastic gradient descent)와 Adam, RMSprop와 같은 변형버전들은 학습에 있어 널리사용되는 방식들입니다. 이 방법들은 모두 scaled(stochastic) gradient step을 통해 반복적으로 training loss를 줄여갑니다. 단어 수준의 language modeling에서 과거 연구들은 SGD가 다른 방식들에 비해 최종 loss뿐만 아니라 수렴 속도 측면까지도 더욱 좋은 성능을 보인다는 것을 보였습니다.
해당 논문에서는 ASGD(averaged SGD)를 사용합니다. ASGD는 SGD와 유사한 반복과정을 수행하지만 SGD는 마지막 반복 결과를 결과로 제시하는 반면 ASGD는 조정될 수 있는 threshold T 기간 만큼의 과거 반복 결과들의 평균을 사용합니다. Threshold T는 조정될 수 있고 성능에 큰 영향을 끼칩니다. 해당 논문에서는 T 값이 non-monotonic criterion을 통해 결정될 수 있는 ASGD의 변형 방식을 소개하고 이 방식이 SGD보다 좋은 학습 결과를 갖는 다는 것을 보여줍니다.
2. Weight-dropped LSTM

RNN의 recurrent connection에서의 overfitting을 막는 것은 language modeling의 extensive research 영역이었습니다. 이전에 주로 사용되던 recurrent regularization 방법은 hidden state vector h_(t-1)에 regularize를 하는 것과 timestep 사이에 dropout을 적용하는 것, 혹은 memory state c_t의 update시 dropout을 적용하는 것입니다. 기본 LSTM을 이와 같이 바꾸는 것은 low-level hardware-specific하게 최적화 되어 있어 매우 빠른 속도를 갖는 black box RNN을 사용할 수 없게합니다.
해당 논문에서는 DropConnect를 RNN formulation에 변화를 줄 필요가 없는 recurrent hidden to hidden weight matrix에 적용하는 것을 제안합니다. Forward, backward pass 이전에 weight matrix에 dropout이 일단 적용되면 학습 속도에 영향은 최소화되고 어떠한 standard RNN 연산을 활용할 수 있기 때문에 대표적인 black box LSTM 연산인 NVIDIA's cuDNN LSTM 역시 활용할 수 있게 됩니다.
[U^i, U^f, U^o, U^c]등의 hidden-to-hidden weight matrix들에 DropConnect를 적용함으로써 LSTM의 recurrent connection에서 발생하는 overfitting을 막을 수 있었습니다. 이러한 방식은 또 다른 RNN cell의 recurrent weight matrix에 적용하여 overfitting을 막을 수 있습니다.
여러 timestep에 대해 동일한 weight가 재사용되기 때문에 전체 forward, backward pass에서 동일한 weight가 drop된 채로 유지됩니다.
3. Optimization
SGD는 다양한 분야에서 딥러닝 모델을 학습할 때 널리 사용되는 방법입니다. Deep network를 학습하는 것은 아래 식과 같은 non-convex 최적화 문제로 볼 수 있습니다.

SGD는 실제로 잘 적용되고 linear convergence, saddle point avoidance, better generalization performance와 같은 이론적인 특징도 지니고 있습니다. Neural language modeling과 같은 특정 task에서 momentum이 없는 전통적인 SGD는 momentum SGD, Adam, Adagrad, RMSProp와 같은 방식들 보다 통계적으로 유의미한 차이만큼의 더 나은 성능을 보였습니다.
이러한 결과로부터 해당 논문에서는 ASGD를 학습 과정에 있어서 더욱 발전시켰습니다. ASGD는 이론적으로 많이 분석되었고 asymptotic second-order convergence를 포함하여 놀라운 결과를 보여왔습니다. ASGD는 위 (1) 식과 동일한 과정을 수행하지만 마지막 결과를 해결책으로 제시하는 대신 아래와 같은 식을 최종 해결책으로 제시합니다.

이론적인 매력이 있지만, ASGD는 deep network를 학습할 때 제한적으로만 사용되어 왔습니다. 이는 learning-rate schedule과 averagin trigger T를 tuning하는 가이드라인이 제대로 없는 것이 한 원인입니다. T값이 너무 클 때는 해당 방식의 효율성에 영향을 받게되고 T값이 작을 때는 해결책을 위해 너무 많은 iteration들이 converge되어야만 합니다. 해당 논문에서는 T를 tuning할 필요가 없는 NT-ASGD(Non-monotonically triggered variant of ASGD)를 소개합니다. 더 나아가 해당 방식은 고정된 learning rate를 사용하여 decay scheduling을 위해 tuning을 할 필요가 없게됩니다.
Language modeling에서 일반적으로 사용되는 방식은 모델의 성능이 이전보다 나빠지거나 성능 개선이 없을 때 고정된 비율로 learning rate를 감소시키는 것입니다. Validation metirc이 나빠진 즉시 적용하는 대신 해당 논문에서는 몇 차례의 반복에서 성능 개선이 없을 때만 보수적으로 적용할 수 있는 non-monotonic criterion을 제안합니다. 이는 아래와 같이 표현할 수 있습니다.

4. Extended regularization techniques
학습이 진행되는 동안 data efficiency를 향상시키는 목적을 지닌 추가적인 regularization 방법들을 살펴봅니다.
4.1 Variable length backpropagation sequences
Data set을 고정된 길이의 batch로 자르기 위해 고정된 sequence 길이를 사용한다면 data set이 효율적으로 사용되지 못합니다.
이러한 비효율을 방지하기 위해서 2 step으로 forward와 backward pass의 sequence length를 임의로 선택합니다. 먼저 base sequence length가 확률 p(1에 매우 근접한 값)로 seq가 되게하거나 (1-p) 확률로 seq/2가 되게합니다. 그 후 sequence length를 N(seq, s) 분포에 따라 선택합니다. seq는 base sequence length이고 s는 standard deviation입니다.
학습이 진행되는 동안 learning rate를 기존의 특정 sequence legnth와 비교하여 결과적으로 얻은 sequence의 길이에 의존하여 rescale해줍니다.
4.2 Variational dropout
기본적인 dropout에서 새로운 binary dropout mask가 drop이 적용되어야 하는 매 time 마다 sampling됩니다. Variational dropout은 최초로 call 되었을 때 binary dropout mask를 추출하고 매 반복마다 동일하게 사용합니다.
Variational dropout보다 DropConnect를 hidden-to-hidden에서 사용하는 것을 해당 논문에서는 제안하고 있지만 LSTM의 모든 input과 output에 동일한 dropout mask를 적용하는 것과 같이 hidden-to-hidden을 제외한 곳에서는 vaiational dropout을 활용합니다.
4.3 Embedding dropout
과거연구에 따라 해당 논문에서는 embedding dropout을 사용합니다. 이는 단어 수준의 embedding matrix에 dropout을 적용하여 dropout이 모든 word vector embedding 차원으로 broadcast되는 것입니다. Dropout 되지 않은 남아있는 word embedding 들은 1/(1-p_e)만큼 rescale됩니다. p_e는 embedding dropout 확률입니다.
4.4 Weight tying
Weight tying은 embedding과 softmax layer 사이의 weight를 공유하여 model의 parameter 수를 줄여줍니다.
4.5 Independent embedding size and hidden size
Word embedding size를 줄이는 것이 overfitting을 방지하는 것에 큰 이점이 없다고 하더라도 language model의 전체 parameter를 줄이는 가장 쉬운 방법은 word vector size를 줄이는 것입니다. 이를 위해 LSTM의 첫번째, 마지막 layer는 input, output 차원이 줄어든 embedding size에 맞춰줘야 합니다.
4.6 Activation Regularization(AR) and Temporal Activation Regularization(TAR)
L2-regulaization은 network의 가중치에 적용되어 resulting model의 norm을 조절하고 overfitting을 막아줍니다. 추가적으로 L2 decay는 각 unit activation에 적용될 수 있고 time step마다 RNN의 output에 다르게 적용될 수 있습니다. 이러한 방식을 AR, TAR이라고 합니다.


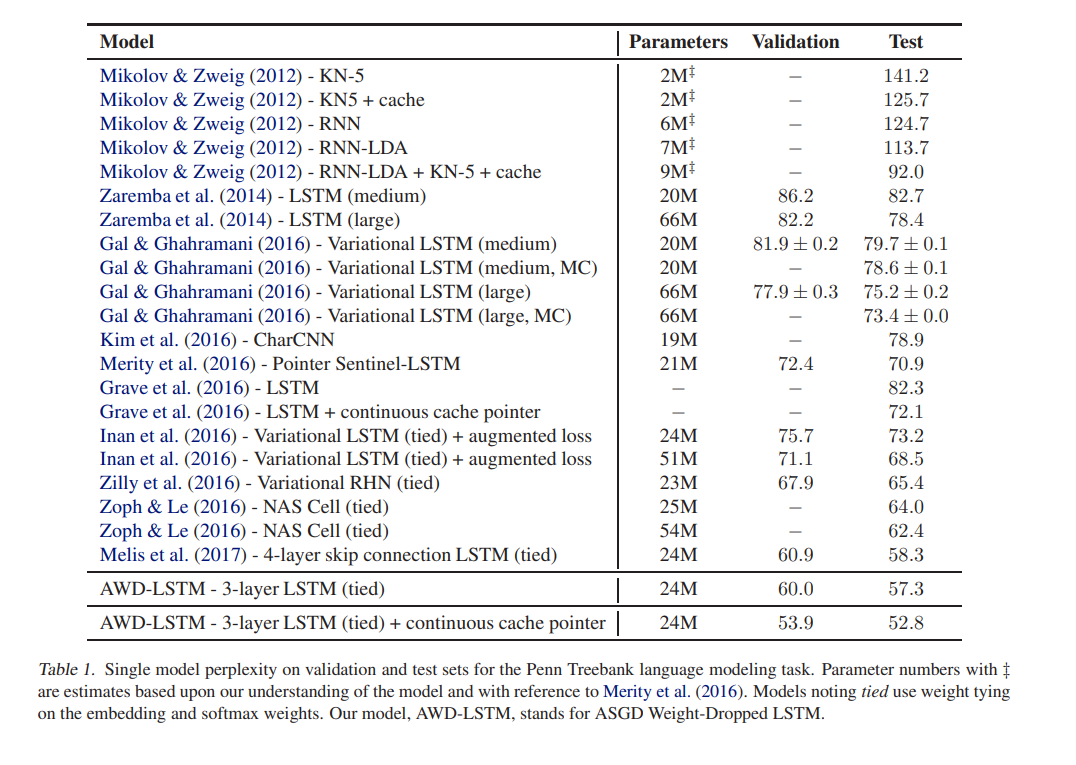
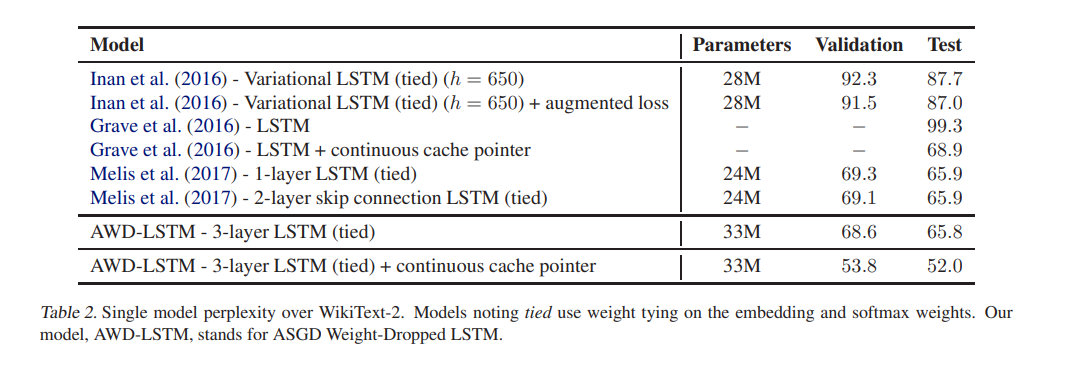
5. Experiment Details
PTB / WT2
모든 실험은 hidden layer에 1150개의 unit을 지닌 3-layer LSTM을 활용하고 embedding size는 400입니다. Loss는 모든 example과 timestep마다 평균을 취합니다. 모든 embedding weight들은 [-0.1, 0.1] 사이의 값으로 uniformly하게 initialized 되고 그 외 다른 weight들은 hidden size H를 기준으로 [-1/(sqrt(H)), 1/(sqrt(H))] 사이의 값으로 초기화됩니다.
학습에는 NT-ASGD를 활용하였고 WT2에는 80, PTB에는 40의 batch size를 사용하였습니다.
6. Experimental Analysis
7. Pointer models
과거 연구에서 pointer based attention model은 language model 성능을 높이는 데 도움을 주었다고 밝혔습니다.
Neural cache model은 pre-trained language model 적은 cost로 가장 상단에 추가될 수 있습니다. Neural cache store는 이전 hidden state를 memory cell에 저장할 수 있으며 cahce와 language model이 제안하는 확률분포의 결합을 예측에 활용할 수 있습니다. Cache model은 3가지 hyperparameter가 있습니다.
- the memory size(window) for cache
- the flatness of the cache distribution
- the coefficient of the combination
Neural cache model의 단순함과 추가 학습적인 요소가 없음을 고려하였을 때 존재하는 neural language model은 여전히 long-term dependency를 제대로 잡아내지 못하고 최근에 본 단어들만 제대로 활용하고 있다는 것을 알 수 있습니다.

8. Model Ablation Analysis

Perplexity 값이 가장 크게 증가한 경우는 hidden-to-hidden LSTM regularization을 제거했을 때입니다.
9. Conclusion
해당 논문에서는 neural language model을 위한 regularization, optimization 방법들을 다루었습니다. 해당 논문에서는 recurrent connection을 통해 발생할 수 있는 overfitting을 방지하는 방법으로 hidden-to-hidden weight matrix에 DropConnect mask를 적용하는 weight-dropped LSTM을 소개하였습니다. 더 나아가 해당 논문에서는 language model을 학습하기 위해 non-monotonic trigger를 가진 ASGD(NT-ASGD)를 활용하였고 유의한 차이만큼 SGD보다 나은 성능을 갖는 다는 것을 보였습니다.
마지막으로 해당 논문에서는 제안한 모델에 neural cache를 사용하는 것이 성능 향상에 추가적으로 도움이 되는 것을 보였습니다.
