Layer의 activation에 drop을 적용하는 dropout의 일반화인 Layer weight에 drop을 적용하는 DropConnect를 소개하는 논문입니다. DropConnect가 dropout의 일반화 버전임을 보이고 성능이 더 좋다는 것도 보여줍니다.
[Abstract]
해당 논문에서는 큰 size의 fully-connected layer를 regularizing하는 Dropout의 일반화인 DropConnect를 소개합니다. Dropout을 활용하여 학습을 할 때는 각 layer의 activation 중 일부를 0으로 만듭니다. DropConnect는 activation이 아닌 network의 weights 중 일부를 0으로 만듭니다. 각 unit들은 결과적으로 이전 layer의 unit의 임의의 부분집합을 input으로 받게됩니다.
1. Introduction
Neural network model은 label이 있는 큰 size의 dataset을 갖고 있는 domain에 적합합니다. 왜냐하면 Neurl network model은 layer의 수가 늘어나거나 각 layer의 unit의 수가 많아질수록 성능이 좋아지기 때문입니다. 하지만 수백, 수억개의 parameter를 지닌 network는 dataset의 크기가 크더라도 쉽게 overfit이 되어버립니다. 이를 해결하기 위해 다양한 regularizing 방법들이 만들어졌습니다. Network weight에 L2 penalty를 추가하는 것은 단순한 방법 중 하나입니다. 또 다른 방법들로는 bayesian method, weight elimination, early stopping of training 등이 있습니다. Regularization이 없는 크기가 작은 network를 학습하는 것보다 regularization이 있는 크기가 큰 network를 학습하는 것이 성능 측면에서 좋다는 것이 알려졌습니다.
(Hinton et al, 2012)에서는 Dropout이라는 새로운 regularization 방법을 소개하였습니다. Dropout을 활용하면 순전파를 통해 각 layer의 activation 결과 중 일부를 제거합니다. Error는 남아있는 activation을 통해서면 역전파로 전달되게 됩니다. Dropout을 통해 overfitting을 획기적으로 줄일 수 있었고 test set에 대해서 성능도 좋아졌습니다. 직관적으로 생각해본다면 dropout은 network weight들이 서로 연관이 되어 training example을 기억하는 것을 막아주는 역할을 한다고 볼 수 있습니다.
해당 논문에서는 activation을 제거하는 것이 아닌 weight의 일부를 제거하는 dropout의 일반화된 DropConnect를 소개합니다. DropConnect 역시 dropout과 마찬가지로 fully connected layer에 대해서 잘 적용이됩니다.
2. Motivation
DropConnection을 소개하기 위해 fully connected layer를 생각합니다.
- Input v : [v_1 ~ v_n]^T
- Weight parameter W : (d x n) matrix
- Output r : [r_1 ~ r_d]^T
Output r은 아래 식과 같이 input v와 weight matrix W를 곱한 값에 activation function a를 적용하여 구해집니다.
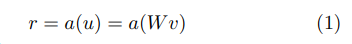
2.1 Dropout
Dropout은 fully connected neural network layer의 regularization을 위한 방법으로 소개되었습니다. Layer output의 요소들은 p 확률로 유지되고 (1-p) 확률로 0의 값으로 변경됩니다. 여러 실험을 통해 dropout이 network의 generalization을 잘 할 수 있도록 만들어주고 test set에 대해서 성능이 증가하는데 도움을 주었다고 밝혀졌습니다.
Dropout이 fully connected layer의 output에 적용되는 것은 아래 식과 같이 표현할 수 있습니다.

Tanh, centered sigmoid, relu와 같은 많은 activation function들은 a(0)=0을 만족하기 때문에 위 (2) 식은 r = a(m ★ Wv) 로 다시 쓸 수 있으며, 이는 Dropout이 activation function의 input에 적용되는 것을 의미합니다.
2.2 DropConnect
DropConnect는 dropout의 일반화로써 각 output unit에서 drop이 이루어지는 것이 아닌 각 connection(weight)에서 (1-p) 확률로 drop이 이루어지게 됩니다. DropConnect는 모델에 dynamic sparsity를 부여한다는 점에서 dropout과 유사한 면을 지닙니다. 하지만 sparsity가 layer의 output activation이 아닌 weight에서 이루어진다는 것이 차이점입니다. 학습이 진행되는 동안 W가 고정된 fixed sparse matrix로 유지되는 것과는 다릅니다.
DropConnect layer에서 output은 아래 식과 같이 구해집니다.

bias 또한 학습이 진행될 때 drop 될 수 있습니다. (2), (3) 식을 통해 DropConnect가 dropout의 일반화 버전임을 알 수 있습니다.
3. Model Description
해당 논문에서는 아래 그림과 같이 4개의 요소로 이루어진 model architecture를 고려합니다.
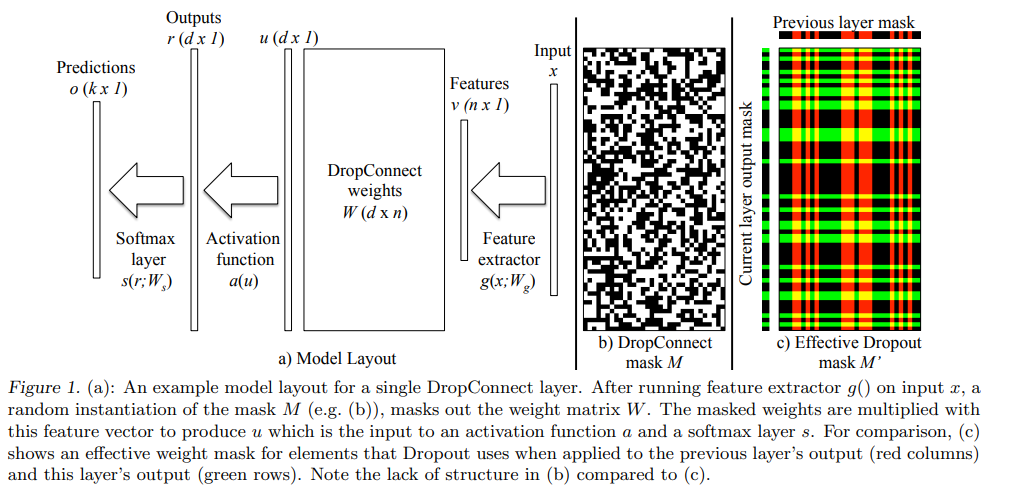
- Feature Extractor : v = g(x; W_g), v는 output feature이고, x는 input data입니다. W_g는 featrue extractor의 parameter이며 해당 논문에서는 g()를 multi-layered CNN을 활용합니다. 결과적으로 W_g는 CNN의 convolutional filter와 biases가 됩니다.
- DropConnect Layer : r = a(u) = a((M ★ W)v), v는 feature extractor의 output이고 W는 fully connected weight matrix입니다. a는 non-linear activation function, M은 binary mask matrix입니다.
- Softmax Classification Layer : o = s(r;W_s), r은 DropConnect Layer의 output이고 W_s는 r을 클래스 개수인 k 차원의 output으로 mapping 시켜주는 parameter 입니다.
- Cross Entropy Loss : A(y, o) = -(Summation(y_i*log(o_i)))
전체 model f(x; theta, M)은 input data x은 여러 계산을 통해 주어진 parameter theta = {W_g, W, W_s}들과 임의로 뽑힌 matrix M에 의해 output o로 나오게됩니다. o의 correct value는 아래 식과 같이 얻을 수 있습니다.

3.1 Training
학습은 example x를 training set에서 뽑고 x로부터 feature v를 만들어내는 것에서 시작됩니다. Featrue v는 DropConnet layer의 input으로 들어가고 이 때 mask matrix M은 weight와 bias를 drop 시키기 위해 Bernoulli(p) 분포를 통해 만들어집니다. DropConnect를 활용한 학습이 성공적으로 수행되기 위한 중요한 요소는 각 training example마다 서로 다른 mask를 사용해야 된다는 것입니다. Training example 여러개에 대해 하나의 mask를 사용하게 된다면 model을 충분히 regularize할 수 없습니다.
일단 mask가 선택이되면 activation function의 input을 계산하기 위해 weight와 bias에 적용됩니다. 결과적으로 얻은 r은 soft-max layer의 input으로 사용되어 soft-max layer의 output은 실제 결과값의 예측값의 역할을 하여 cross entropy값을 구하는 데 활용됩니다. Model의 parameter theta는 loss function의 gradient 역전파를 활용하여 SGD를 통해 갱신됩니다. DropConnect layer의 weight matrix W를 갱신하기 위해 mask는 gradient에도 적용이되어 drop 되지 않은 요소들에 대해서만 갱신됩니다.

3.2 Inference
Inference를 위해 아래와 같은 값을 계산해야만 합니다.

마지막 식이 실질적으로는 잘 활용될 수 있지만, 수학적으로는 relu activation 일 때는 성립하지 않습니다.
해당 논문에서는 다른 접근법을 사용하였습니다. Activation function a() 이전의 single unit u_i에 대해 u_i는 아래 식으로 표현할 수 있습니다.
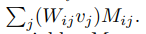
이는 Bernoulli variable M_ij의 가중합이며 Gaussian으로 근사할 수 있습니다.
결과적으로 Bernoulli 대신 Gaussian에서 sample을 뽑은 후 activation function a()에 적용할 수 있습니다.

4. Model Generalization Bound

5. Implementation Details
해당 논문의 case에서 각 학습 example마다 다른 random mask matrix가 필요하다는 점이 어려움으로 작용합니다. 이는 아래 2가지 문제를 야기합니다.
- (d x n) weight matrix에 대해 이에 대응하는 mask matrix는 mini batch size b에 대해 총 (d x n x b) size를 갖게된다는 것이며 이는 memory 문제를 발생시킬 수 있습니다.
- Mask의 random instantiation이 만들어지면 performance 최대화를 위해 matrix 곱이 진행되는 동안 모든 원소에 접근하는 것이 쉽지 않습니다.
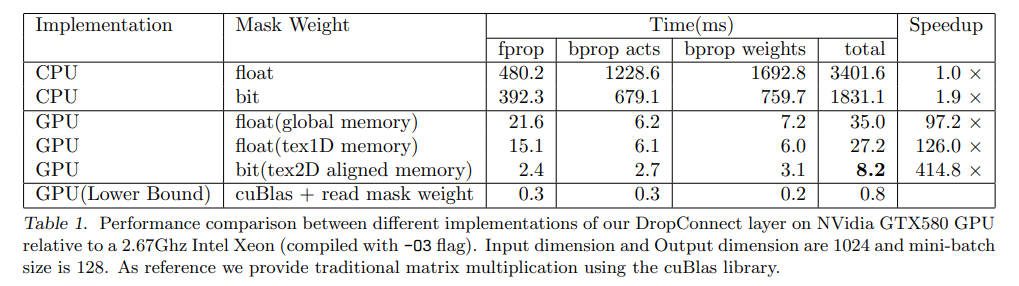
6. Experiments
해당 논문에서는 mini-batch SGD with momentum on batches of 128 images with the momentum parameter fixed at 0.9를 활용하였습니다.
- Augment the dataset
- Train 5 independent networks with random permutations of training sequence
- Manully decrease the learning rate
- DropConnect, Dropout, No-drop
5개의 network가 학습이 되면 아래 2가지를 계산합니다.
- 각 5개 network의 mean, standard deviation of the classification error
- classification error that results when averaging the output probabilities from the 5 networks before making a prediction
6.1 MNIST
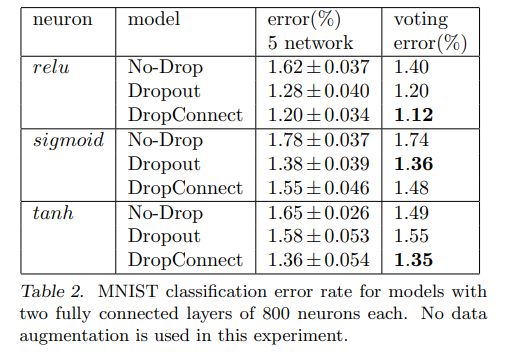
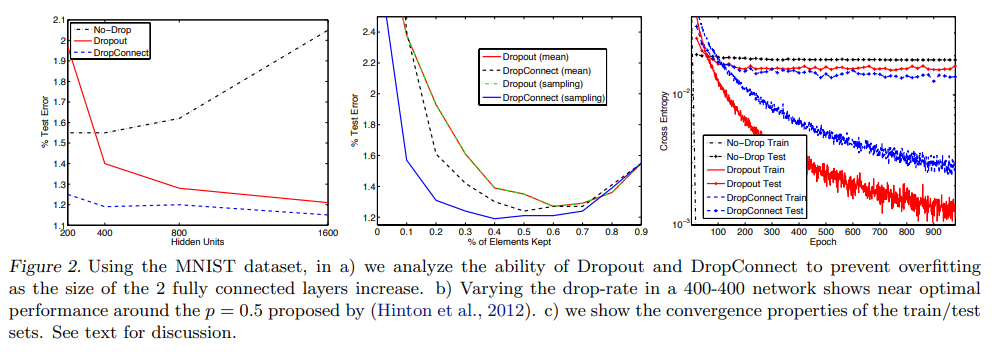
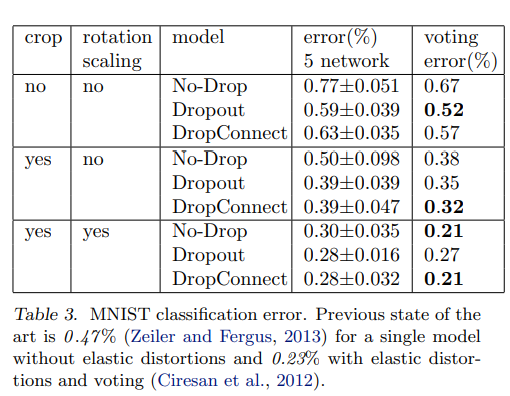
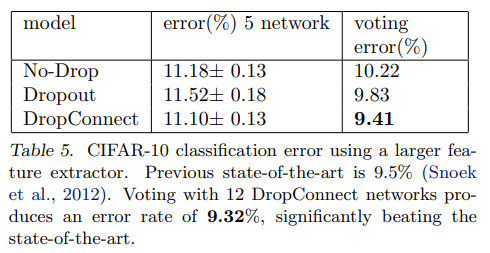
6.2 CIFAR-10
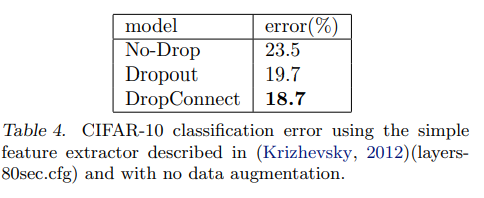
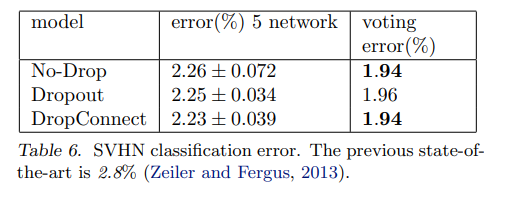
6.3 SVHN
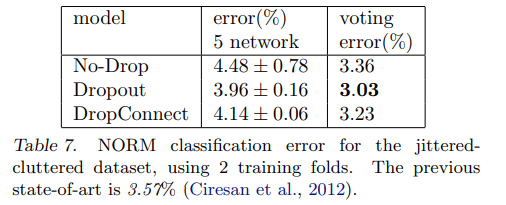
6.4 NORB
7. Discussion
해당 논문에서는 fully connected neural network를 regularizing하는 dropout의 일반화인 DropConnect를 소개합니다. 해당 논문에서는 DropConnect가 large neural network model regularizing에 도움이 된다는 이론적 증명과 실험적 결과를 모두 보였습니다. DropConnect는 dropout보다 좋은 성능을 보이기도 했습니다. Feature extractor에서 bottleneck이 걸려 no-drop이나 dropout보다 DropConnect가 속도가 약간 느리긴 했지만 전체 학습 시간을 고려한다면 그렇게 큰 차이는 아니었습니다. DropConnect를 통해 overfitting을 줄이면서 large model을 학습할 수 있게 되었습니다.
