고정되지 않은 길이의 input을 다루기 위해 convoluton network를 응용한 grConv를 소개하고, GRU와 machine translation 측면에서 성능을 비교하는 논문입니다.
[Abstract]
Nueral machine translation은 순전히 신경망을 기반으로하는 statistical machine translation의 새로운 접근방법입니다. Nueral machine translation model은 encoder-decoder로 이루어져 있는 경우가 있습니다. Encoder는 고정되지 않은 길이의 input sentece로부터 고정된 길이의 representation을 추출합니다. Decoder는 encoder에서 추출된 representation으로부터 적절한 translation을 만들어냅니다.
해당 논문에서는 2개의 neural machine translation model의 특징을 분석합니다.
- RNN Encoder-Decoder
- Gated Recursive convolutional neural network
해당 논문에서는 neural machine translation이 unknown word가 없는 짧은 문장일 때 좋은 성능을 갖는다는 것을 보였습니다. 성능은 문장의 길이가 길어지고 unknown word의 수가 많아질수록 급격하게 떨어졌습니다. 더 나아가 해당 논문에서는 gated recursive convolutional neural network가 스스로 문법구조를 학습한다는 것을 보였습니다.
1. Introduction
순전히 신경망에 의존하는 statistical machine translation의 새로운 접근법을 neural machine translation이라고 합니다. Nueral machine translation은 encoder와 decoder로 이루어져 있습니다. Encoder는 고정되지 않은 길이의 input sentence로부터 고정된 길이의 vector representation을 추출합니다. Decoder는 encoder에서 만들어진 vector representation으로 부터 적절하고 길이가 고정되지 않은 translation을 만들어냅니다.
Nueral machine translation은 전통적인 statistical machine translation model이 사용하는 memory의 일부만을 필요로 합니다. 적은 양의 메모리 사용은 실제 사용에서 큰 장점이 됩니다. 기존의 translation system과는 달리 neural translation model의 component들은 translation 성능을 향상시키는 방향으로 같이 학습됩니다.
상대적으로 알려진지 얼마되지 않았기에 neural translation model의 특징을 분석한 연구는 많지 않습니다.
해당 논문에서는 2개의 neural translation model을 분석합니다. 하나는 RNN Encoder-Decoder이고 또 다른 하나는 해당 논문에서 새롭게 소개하는 RNN Encdoer-Decoder의 encoder를 변경한 grConv(gated recursive convolutional neural network)입니다.
해당 논문에서는 neural machine translation model의 성능이 source sentence의 길이가 늘어날수록 감소한다는 것을 보였습니다. 이에 더해, vocabulary size가 translation 성능에 큰 영향을 준다는 것을 보였습니다. 또한, grConv가 따로 labeling이 되어 있지 않더라도 스스로 source language의 문법적인 구조 등의 내용을 학습할 수 있다는 것을 보였습니다.
2. Neural Networks for Variable-Length Sequences
2.1 Recurrent Neural Network with Gated Hidden Neurons
RNN은 고정되지 않은 길이의 input sequence x = (x_1 ~ x_T)를 활용하여 hidden state H를 유지하며 작동합니다. 각 timestep t마다 hidden state h^(t)는 아래 식을 통해 갱신됩니다.

위 식의 f는 activation function입니다. f는 input vector의 linear transformation을 취한 후 합하여 element-wise하게 logisitic sigmoid 함수를 적용하는 것과 같이 단순할 수도 있습니다.
RNN은 next input의 p(x_(t+1) | x_t ~ x_1)의 분포를 학습하는 것을 통해 고정되지 않은 길이의 sequence의 분포를 효율적으로 학습할 수 있습니다.

(Cho et al., 2014) 논문에서 RNN의 새로운 activation 함수를 소개하였습니다. 새로운 activation 함수는 일반적인 logistic sigmoid activation 함수를 reset gate, update gate라고 불리는 2개의 gate unit으로 이루어진 activation 함수로 바꾸었습니다. 각 gate는 이전 상태의 hidden state h^(t-1)에 의존하고 현재의 input x_t는 information의 flow를 조절합니다.

2.2 Gated Recursive Convolutional Neural Network
고정되지 않은 길이의 sequence를 다루는 또 다른 접근법은 parameter들이 전체 network에서 각 level마다 공유되는 recursive convolutional neural network를 활용하는 것입니다.
해당 논문에서는 고정된 길이의 vector를 output으로 가질때까지 input sequence에 weighits가 recurisve하게 적용되는 binary convolutional neural network를 소개합니다. 일반적인 convolutional 구조에 더해 해당 논문에서는 gating mechanism을 활용하여 recursive network가 source sentence의 구조를 학습할 수 있도록합니다.
Input sequence x = (x_1 ~ x_T), 각 x_i들은 d차원 vector입니다. grConv는 4개의 weight matrix W^l, W^r, G^l, G^r로 이루어져 있습니다. 각 recurslive level t에서 j번째 hidden unit의 activation (h_j)^(t)는 아래 식과 같이 계산됩니다.

새로운 activation (~(h_j))^(t)는 일반적으로 아래와 같이 계산됩니다.

이러한 activation에 따르면 recursive level t에서 single node의 activation은 left, righit childer을 모두 사용하거나 둘 중 하나만을 사용한 activation으로부터 계산되는 것 중 하나라고 생각할 수 있습니다.

3. Purely Neural Machine Translation
3.1 Encoder-Decoder Approach
Machine learning 관점으로 보았을 때, translation task는 source sentence s가 주어졌을 때 target sentence(translation) f의 조건부 분포를 학습하는 것으로 생각할 수 있습니다.
이러한 조건부 분포를 학습하는 다양한 방법을 과거 연구에서 소개했었습니다.
(Kalchbrenner and Blunsom, 2013)에서는 source sentence로부터 고정된 길이의 vector를 만들기 위해 convolutional n-gram model을 활용하고 inverse convolutional n-gram model을 RNN에 더하여 decode하는 방식을 소개하였습니다.
(Sutskever et al., 2014)에서는 source sentence를 encode하기 위해 LSTM unit을 RNN에 활용하였고, target sentence를 decode하기 위해 last hidden state에서부터 출발하였습니다.
(Cho et al., 2014)에서는 source, target phrase 쌍을 encode, deocde하기 위해 RNN을 사용하는 것을 제안하였습니다.
과겨 연구들의 핵심은 encoder-decoder 구조를 활용했다는 것입니다.

Encoder는 고정되지 않은 길이의 input(source sentence)를 처리하여 고정된 길이의 vector representation z를 만듭니다. Encoded representation을 받아, decoder는 고정되지 않은 길이의 sequence를 만듭니다.
해당 논문에서는 2개 model의 조건 하에서 translation 성능을 직접 분석합니다. 첫 번째 model은 (Cho et al., 2014)에서 소개된 RNN Encoder-Decoder이고, 두 번째 모델은 앞서 해당 논문에서 제안한 grConv를 사용한 model입니다.
4. Experiment Settings
4.1 Dataset
- task : English-to-French translation
- 계산상의 효율을 위해 신경망 학습을 위해 30 단어 이하의 문장 pair를 활용
- 30,000개의 최빈 단어 활용
4.2 Models
- RNN Encoder-Decoder와 grConv는 모두 encoder로 활용하고 decoder는 RNN with gated hidden unit을 사용
- Minibatch stochastic gradient descent with AdaDelta
- grConv : 2000 hidden neurons
- RNNenc : 1000 hidden neurons
- word embedding : 620 dimension
4.2.1 Translation using Beam-Search
주어진 모델별 조건부 확률을 최대화하는 translation을 찾기 위해 beam-search를 활용합니다.
k-best translation을 찾기 위해 beam-search를 활용할 때, 일반적인 log-probability를 사용하지 않고 tranlsation의 길이로 normalize한 값을 활용합니다. 이는 RNN decoder가 길이가 짧은 translation을 선호하는 것을 방지해줍니다.
5. Results and Analysis
5.1 Quantitative Analysis
해당 논문에서는 neural machine translation model의 특징에 관심을 둡니다. 특히 soruce and/or target sentence 길이와 unknown word 측면에서 translation 성능에 관심을 둡니다.

위 결과는 translation 성능을 나타내는 BLEU score가 sentence 길이에 따라 어떻게 변화하는 지 나타냅니다. 두 모델 모두 짧은 문장에 대해서는 좋은 성능을 보이지만 문장의 길이가 길어질수록 성능이 떨어지고 있습니다.
Unknown word에서도 유사한 경향을 보이고 있습니다. Unknown word의 수가 많아질수록 translation의 성능이 감소하고 있습니다.
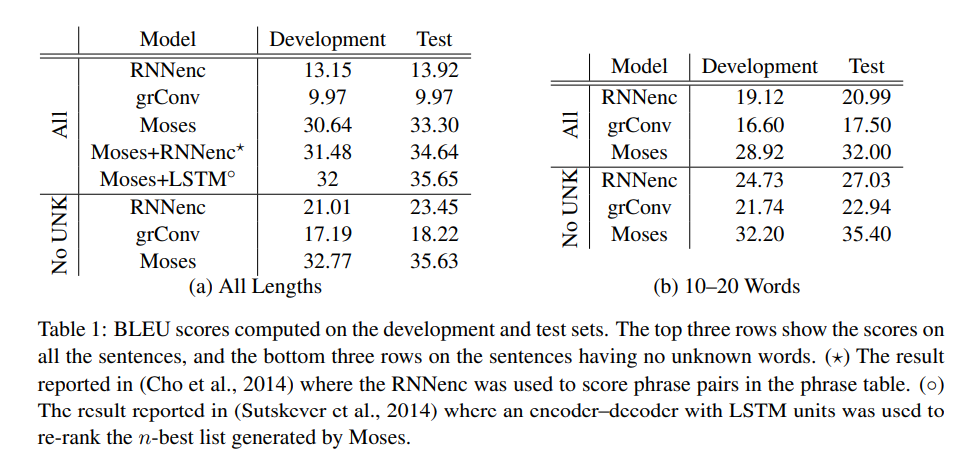
Phrase-based SMT system은 순전히 신경망으로만 구성된 neural machine translation system보다 좋은 성능을 보입니다. 하지만 unknwon word가 source and target sentence 양쪽 모두에 없는 조건일 때는 이들의 성능 차이는 거의 없습니다. 짧은 문장에 대해서 본다면 성능 차이는 더더욱 줄어듭니다.
이러한 분석은 neural translation 방식이 긴 문장을 다루는데 어려움이 있다는 방증입니다. 생각해볼 수 있는 가설은 고정된 길이의 vector representation은 긴 문장의 복잡한 구조와 의미를 모두 담기에는 무리가 있다는 것입니다. 고정되지 않은 길이의 sequence를 encode하기 위해 신경망은 input sentence의 몇몇 중요한 topic을 희생하여 다른 특징을 포함할 것입니다.
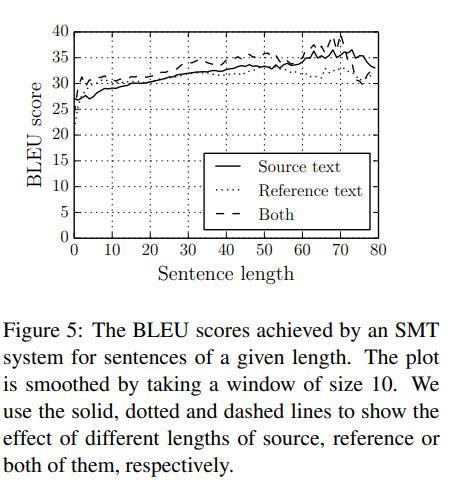
위 결과는 전통적인 phrase-based machine translation system은 같은 dataset에 대해 문장이 길어질수록 더 높은 BLEU score를 보여줍니다.
5.2 Qualitative Analysis
BLEU score가 일반적으로 많이 쓰이는 지표이긴 하지만 완벽한 지표라고 할 수 는 없습니다. 그렇기에 해당 논문에서는 실제 translation 결과를 보여줍니다.
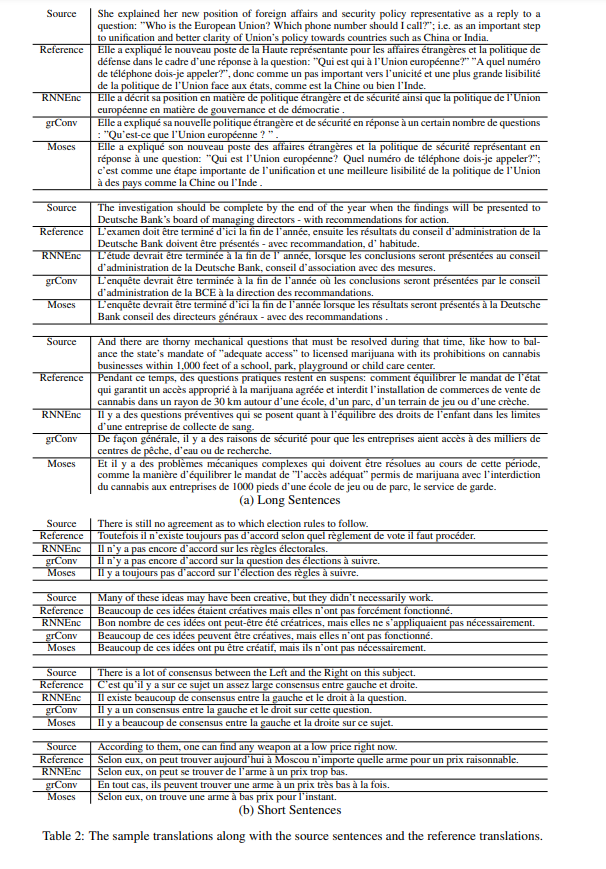

위 결과를 통해 grConv가 vector representation을 얻기 위해 가장 먼저 "of the United State"를 합치고, 그 후 "is the President of"를 합쳐 앞선 결과와 합치고 가장 마지막으로 "Obama is"와 "." 합쳐 우리가 일반적으로 하는 과정과 유사하다는 것을 볼 수 있습니다.
이를 통해 grConv가 문법 구조를 스스로 학습한다는 특징을 알 수 있습니다.
6. Conclusion and Discussion
해당 논문에서는 순전히 신경망으로만 이루어진 machine translation system에 관한 연구를 수행하였습니다. 그 중 RNN Encoder-Decoder, gated recursive convolutional neural network 2가지 모델을 중점적으로 다루었습니다.
해당 논문에서는 neural machine translation model들의 BLEU score를 문장의 길이와 unknwon word의 여부에 따라 어떻게 변화하는 지 분석하였습니다. 이 분석을 통해 neural machine translation은 문장의 길이가 길어질수록 성능이 저하된다는 것을 알게되었습니다. 하지만 정성적으로는 두 모델 모두 적절한 translation 결과를 만들어낸다는 것을 확인하였습니다.
신경망으로만 이루어진 machine translation의 향후 연구 방향에 몇 가지 방향성을 제안합니다.
첫째, 계산과 메모리 측면에서 신경망 학습 scale up을 통해 더욱 큰 size의 vocabulary를 사용할 수 있어야 할 것입니다.
둘째, 긴 문장에 대해 성능이 떨어지는 것을 방지하기 위한 연구가 필요할 것입니다.
마지막으로 해당 논문에서는 모두 동일한 decoder를 사용해서 the curse of sentence length에 영향을 받은 것이 decoder의 representational power가 제한적일 수도 있다는 것을 방증하기 때문에 다른 decoder를 사용하는 다른 neural acrhitecture에 대한 연구가 필요합니다.
