RNN의 reccurent unit으로 tanh, LSTM, GRU 성능을 비교하는 논문입니다. LSTM에서 간소화된 GRU가 LSTM과 큰 성능 차이가 없다고 볼 수 있는 논문입니다.
[Abstract]
해당 논문에서는 RNN(Recurrent Neural Network)의 서로 다른 recurrent unit간의 비교를 수행합니다. 그 중에서도 특히 LSTM(Long Short-Term Memory)와 GRU(Gated Recurrent Unit)과 같은 복잡한 구조의 unit을 주된 주제로 다룹니다. 실험을 통해 이러한 발전된 recurrent unit이 실제로 tanh unit과 같은 기존의 recurrent unit보다 성능이 좋다는 것을 보였습니다. 또한, GRU의 성능이 LSTM과 크게 차이 나지 않는 것 또한 보였습니다.
1. Introduction
RNN은 input과(또는) output의 길이가 고정되지 않는 machine learning task에서 좋은 성능을 보였습니다. 최근 연구에서는 RNN이 기계번역 task에서 잘 만들어진 기존의 system과 유사한 성능을 갖는다고 보였습니다.
최근의 이러한 성능에서 확인할 수 있는 중요한 사실 중 하나는 이러한 성공이 vanila RNN으로 이루어지지 않았다는 점입니다. 오히려 LSTM, GRU와 같은 복잡한 recurrent hidden unit을 활용한 RNN을 사용하였을 때 좋은 결과를 얻을 수 있었습니다. LSTM은 long-term dependency가 존재하는 sequence-based task에서 좋은 성능을 보인 반면, GRU는 소개 된지 얼마 되지 않았으며 기계번역 분야에서만 좋은 성능을 보였습니다.
해당 논문에서는 LSTM과 GRU, tanh unit까지 3개의 recurrent hidden unit을 sequence modeling task를 통해 비교합니다.
해당 논문의 실험 결과, 모든 model들의 parameter 수를 고정하였을 때, GRU는 몇몇 dataset에서 LSTM보다 수렴 시간과 parameter update, generlization에서 우위를 보이기도 하였습니다.
2. Backagroud : Recurrent Neural Network
RNN은 기존의 feedforward neural network의 확장된 버전으로 길이가 고정되지 않은 input 을 다룰 수 있게 해주었습니다. RNN은 이전 시간에 의존하여 얻을 수 있는 activation 값인 recurrent hidden state를 통해 길이가 고정되지 않은 sequence를 다룰 수 있었습니다.
일반적으로 sequence x = (x_1 ~ x_T)가 주어졌을 때, RNN은 hidden state h_t를 아래 식을 통해 얻을 수 있습니다.
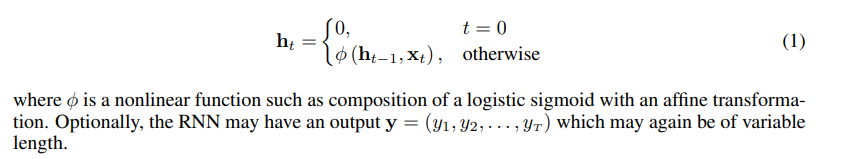
식 (1)의 recurrent hidden state는 아래 계산을 통해 update 됩니다.

Generative RNN은 현재 state h_t가 주어졌을 때 sequence의 다음 원소의 확률분포를 결과로뱉습니다. 그리고 generative RNN은 sequence의 끝을 나타내는 원소를 통해 길이가 고정되지 않은 sequence의 분포를 만들어낼 수도 있습니다. Sequence 분포는 아래 식과 같이 분해할 수 있습니다.

RNN을 학습하여 long-term dependency을 잡아내는 것은 매우 힘듭니다. 왜냐하면 gradient가 많은 경우 소실되거나 간혹 발산해버리기 떄문입니다. 이는 gradient-based optimization을 gradient magnitude의 변화 뿐만 아니라 long-term dependency가 가려지는 영향 때문에 어려워지게 만듭니다. 이러한 문제를 해결하기 위한 대표적인 방법이 2가지 있습니다. 첫째, simple stochastic gradient descent보다 발전된 학습 알고리즘을 활용하는 것입니다. 대표적으로 clipped gradient가 있습니다. 둘째, 해당 논문에서 주로 다룰 예정인 simple element-wise nonlinearity와 affine transformation을 사용하는 일반적인 activation function 대신 gating unit을 사용하여 좀 더 복잡한 activation function을 사용하는 방법입니다. 초기에 시도되었던 방법은 LSTM unit을 활용하는 것이었습니다. 최근에는 GRU라고 불리는 unit을 사용하기도 합니다. 이러한 recurrent unit을 사용하는 RNN은 long-term dependency를 포착해야 하는 task에서도 좋은 성능을 보여주었습니다.
3. Gated Recurrent Neural Networks
해당 논문에서는 LSTM과 GRU의 sequence modeling에서 성능을 평가하는 것을 주된 관심사로 갖습니다.
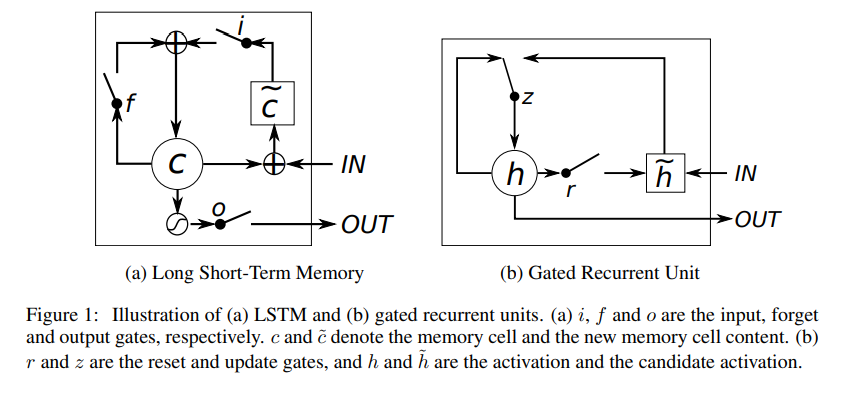
3.1 Long Short-Term Memory Unit
단순히 input signal의 가중 합을 계산하고 nonlinear 함수를 적용하는 단순한 recurrent unit과 달리 LSTM은 time t에서 memory (c_t)^j를 갖고 있습니다. LSTM의 output이자 activation 결과인 (h_t)^j는 아래 식과 같이 계산됩니다.

(o_t)^j는 output gate로써 memory의 내용을 얼만큼 전달할 지 결정하는 역할을 합니다. Output gate는 아래 식과 같이 계산합니다.

Memory cell (c_t)^j는 기존 memory의 일부를 잊고(foret) new memory content (c_t)~^j를 더하여 update 됩니다. new memory content (c_t)~^j의 해당 식은 아래와 같습니다.

Forget gate (f_t)^j는 기존의 memory를 얼만큼 잊을지 결정하는 역할을 합니다. Input gate (i_t)^j는 new memory content를 얼만큼 memory cell에 더해줄 지 결정하는 역할을 합니다. 둘은 아래 식과 같이 계산됩니다.

식 (2)처럼 각 time-step 마다 결과를 덮어쓰는 기존의 recurrent unit과는 달리 LSTM unit은 gate들을 활용하여 memory를 어느정도 유지할 지 결정할 수 있습니다. 만약 LSTM unit이 초기의 input sequence에서 중요한 feature를 찾아냈다면 LSTM은 gate를 활용하여 해당 feature를 멀리까지 전달하여 long-distance dependency를 다룰 수 있습니다.
3.2 Gated Recurrent Unit
GRU는 recurrent unit들이 서로 다른 time scale의 dependency를 잡아낼 수 있도록 적용하였습니다. LSTM과 비슷하게 GRU 역시 gating unit들을 갖고서 정보의 양을 조절하여 unit으로 흘리지만 따로 memory cell을 갖고 있지는 않습니다.
Time t에서 GRU의 activation (ht)^j는 이전의 activation (h(t-1))^j와 candidate activation (h_t)~^j의 linear interpolation으로 얻을 수 있습니다.

Update gate (z_i)^j는 unit에서 activation이나 content를 얼만큼 update 할 지 결정합니다. Update gate는 아래 식을 통해 계산됩니다.

Existing state와 새로 계산된 state 사이의 linear sum을 하는 과정은 LSTM unit과 유사합니다. 하지만 GRU에서는 어떤 state를 어느정도 반영할지 조절하는 mechanism이 없고, 각 시간의 state의 전체를 반영합니다.
Candidate activation (h_t)~^j는 기존의 traditional recurrent unit을 계산하는 것과 유사합니다.

3.3 Discussion
LSTM과 GRU가 공유하고 있는 중요한 특징은 t에서 (t+1)로 진행할 때 additive component가 있는 점입니다. 기존의 recurrent unit들은 항상 current input과 직전의 hidden state를 통해 계산된 값으로 activation을 덮어썼습니다. 하지만 LSTM과 GRU는 현재의 값도 갖고 있는 동시에 이 위에 새로운 값을 더해줍니다.
이러한 덧셈 과정은 2가지 장점이 있습니다. 첫째, 이는 각 unit들이 오랜 기간동안 input stream의 특정한 feature의 존재여부를 기억하기 쉽게해줍니다. LSTM unit의 forget gate와 GRU의 update gate에서 중요하다고 판단한 정보들은 덮어써져 사라지는 것이 아닌 오랜 기간 유지합니다.
둘째, 아마 더욱 중요할 지도 모르는 장점은 덧셈 과정은 여러 step을 건너뛸 수 있는 shortcut을 만들어 주고있습니다. 이러한 shortcut은 error가 너무 빨리 사라지지 않은 채 역전파로 전달될 수 있도록 해줍니다.
LSTM과 GRU는 하지만 많은 차이점들이 있습니다. GRU에는 없는 LSTM의 특징 하나는 memory content의 반영 여부를 조절할 수 있다는 것입니다. LSTN unit에서는 output gate를 통해서 memory content의 정보를 어느정도 사용할 지 정해줍니다. 하지만 GRU에서는 어떠한 조절도 없이 모든 content를 사용합니다.
또 다른 차이점은 input gate, reset gate의 위치입니다. LSTM unit은 직전 time step에서 넘어온 information flow의 양을 조절하는 과정 없이 new memory content를 계산합니다. 오히려 LSTM에서는 forget gate로부터 독립적으로 memory cell에 더해질 new memory content의 정도를 조절해줍니다. 반면에 GRU는 직전 activation의 information flow를 조절하여 new candidate activation을 계산하며 더해지는 candidatte activation의 정도를 독립적으로 조절하지는 않습니다.
유사한 점과 차이점들이 있기 때문에 어떠한 gating unit을 사용해야 할 지 결정하는 것은 어려워졌습니다. 해당 논문에서는 좀 더 철저한 실험을 통해 LSTM과 GRU의 비교를 수행하였습니다.
4. Experiments Setting
4.1 Tasks and Datasets
해당 논문에서는 LSTM unit, GRU unit, tanh unit을 sequence modeling task를 통해 비교하였습니다. Sequence modeling은 sequence의 확률 분포를 아래 주어진 식과 같은 log-likelihood를 최대화하여 학습하는 것을 목표로 합니다.

4.2 Models
3종류 unit의 공평한 비교를 하는 것이 해당 실험의 목적이기 때문에 각 모델 별 parameter 수를 최대한 비슷하게 맞춰주었습니다. 또한, 모델들이 overfitting 되는 것을 막기 위해 모델 크기를 너무 크게 하지는 않았습니다.

모델들은 RMSProp를 통해 학습하였으며 표준편차는 0.075로 고정하여 weight noise를 사용하였습니다. 매 update마다 gradient exploding을 방지하기 위해 gradient의 norm size를 1로 scaling 해주었습니다.
5. Results and Analysis

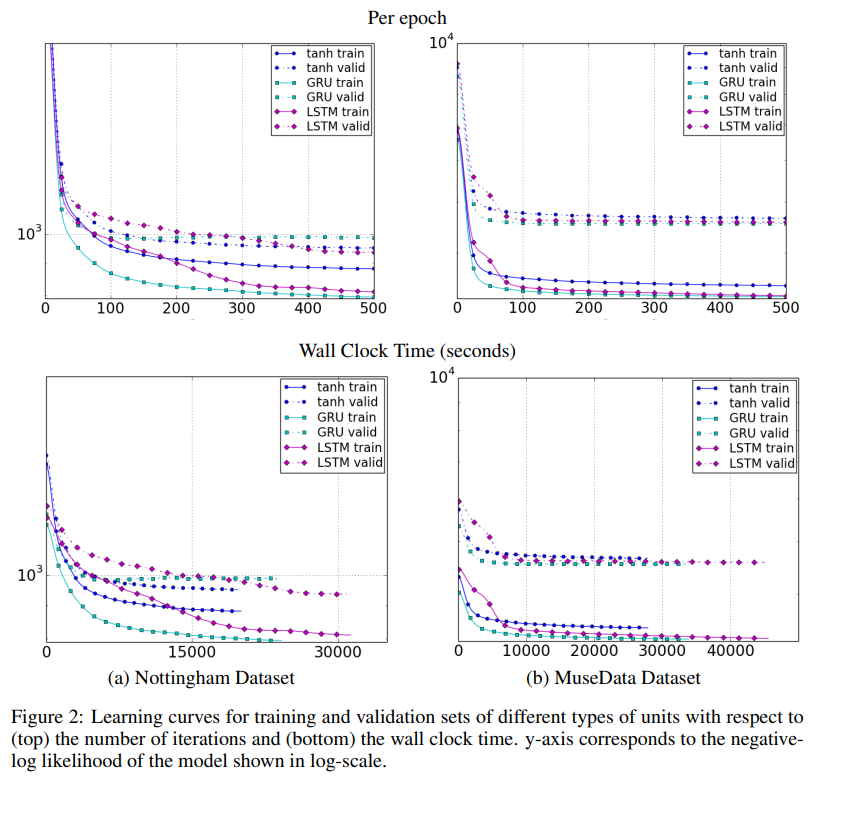
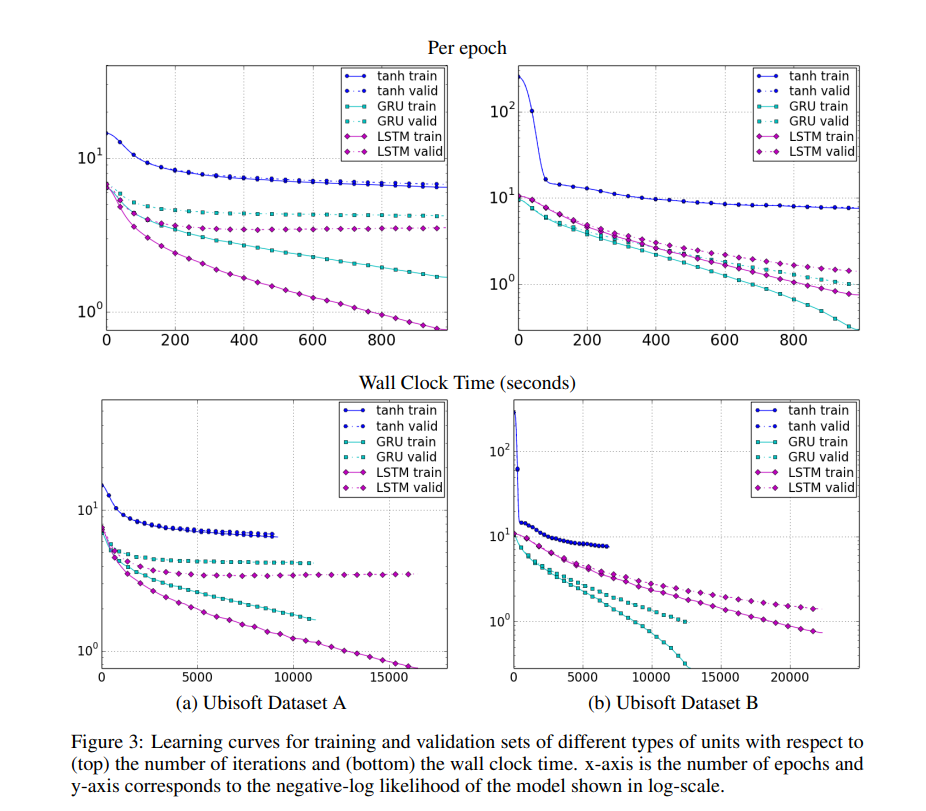
실험 결과들은 전통적인 recurrent unit과 비교하였을 때 gating unit들의 이점이 있다는 것을 명백하게 보여주었습니다. 수렴하는 속도가 빠르고 성능 역시 좋았습니다. 하지만 LSTM과 GRU를 비교하였을 때는 명백히 어떤 것이 더 나은지 결정할 수는 없었습니다. Gating unit을 선택하는 것은 dataset과 관련 task에 의존한다고 할 수밖에 없습니다.
6. Conclusion
해당 논문에서는 tanh unit, LSTM unit, GRU unit 널리 쓰이는 3가지 recurrent unit들을 비교하였습니다. 평가는 sequence modeling을 중심으로 이루어졌습니다.
LSTM과 GRU 둘 다 tanh보다는 매우 좋은 성능을 보인다는 것을 확인할 수 있었습니다. 하지만 LSTM과 GRU 중 어떠한 gating unit이 더 좋은 성능을 보이는 지 명확한 결론을 내릴 수는 없었습니다.
