NLP에서도 CNN을 활용하는 것도 좋은 성능을 보이며, pre-trained vector는 univeral feature extractor임을 다시 한 번 보여주는 논문입니다.
[Abstract]
해당 논문에서는 문장 분류 task를 위해 pre-trained word vector의 최상단에 convolutional neural network(CNN) 층을 사용한 실험을 다룹니다. 약간의 hyperparameter tuning과 static vector를 사용한 simple CNN만으로도 많은 평가지표에서 좋은 결과를 얻었습니다. fine-tuning을 사용한 task-specific vector 학습을 통해 더 좋은 결과를 얻기도 했습니다.
1. Introduction
자연어 처리에서 언어모델을 활용하여 word vector 학습과 학습된 word vector를 활용한 구문분석을 통해 분류문제를 해결 방식을 포함한 딥러닝을 활용한 많은 연구들이 있습니다. Hidden layer를 단어를 활용하여 좀 더 낮은 차원으로 projection시킨 word vector는 단어의 의미적 특성을 지닌채로 encoding된 feature extractor 입니다. 이런 방식을 통해서 유사한 의미를 지닌 단어들은 낮은 차원의 공간에서 유사한 공간에 위치합니다.
CNN은 local feature에 적용되는 convolving filter를 사용하는 layer를 활용합니다. 비전 영역에서 활용되기 위해 만들어졌지만 CNN 모델은 NLP에서도 좋은 성능을 보이고 있습니다.
해당 논문에서는 unsupervised neral language model을 통해 학습된 word vector들의 최상단에 하나의 simple CNN를 가진 모델을 학습합니다. 처음에는 word vector들은 static하게 두고 모델의 다른 parameter들만 학습될 수 있도록 하였습니다. 약간의 hyperparameter tuning에도 불구하고 많은 benchmark에서 좋은 결과를 보였습니다. 이러한 결과는 pre-trained word vector들은 universal한 feature extractor로써 다양한 분류 task에서 사용될 수 있음을 보여줍니다.
최종적으로 pre-trained된 vector와 task-specific vector를 동시에 사용하기 위해 약간의 architecture 수정을 합니다.
이 논문은 pre-trained deep learning model에서 얻은 feature extractor는 이미지 분류의 다양한 task에서 좋은 성능을 보인 결과와 유사한 철학을 지닙니다.
2. Model
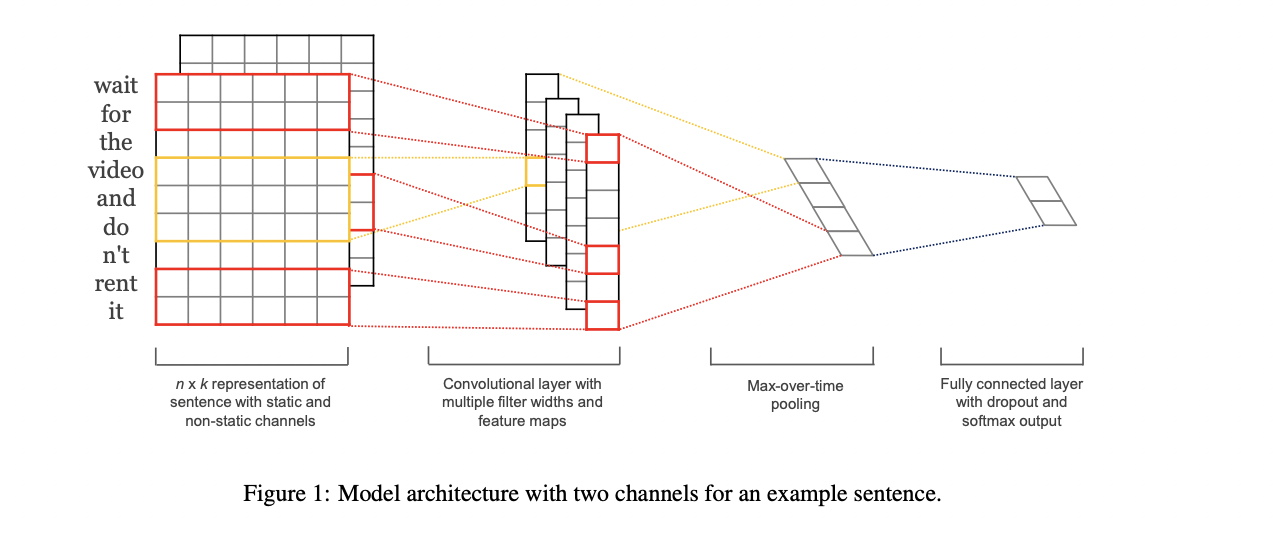
x_i는 k차원을 가지며 i번째 단어의 Word vector입니다. 길이가 n인(필요시 padding 수행) 문장은 다음과 같이 표현할 수 있습니다.
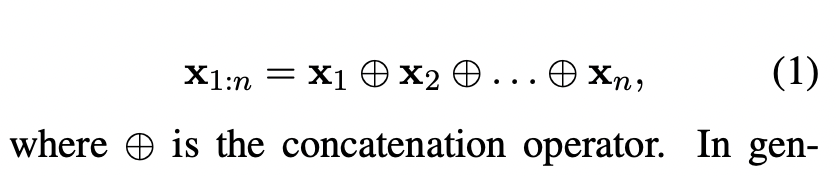
Window 크기 h를 지닌 필터 w를 사용하여 convolution 연산을 통해 얻은 featrue는 다음과 같이 표현할 수 있습니다.

해당 논문에서는 max-over-time pooling을 활용합니다. 가장 큰 값을 선택함으로써 가장 중요한 feature를 뽑아낸다고 볼 수 있습니다.
하나의 filter에서 하나의 feature를 얻어냅니다. 따라서 여러개의 feature를 위해서 여러개의 filter를 활용합니다. 이렇게 뽑인 feature들은 penultimate layer와 fully connected softmax layer를 통과하여 분류 task를 수행합니다.
하나의 변형으로 2개의 word vector 채널을 활용하여 하나는 학습되지 않은 채 유지하며, 하나는 역전파를 통해 parameter 학습이 될 수 있도록 합니다.
2.1 Regularization
Regularization을 위해 가중치벡터들의 l2 norm을 제약으로 사용하는 penultimate layer에 dropout을 활용합니다.

Gradient들은 masking되지 않은 것들만 역전파 계산이 이루어집니다.
3. Datasets and Experimental Setup
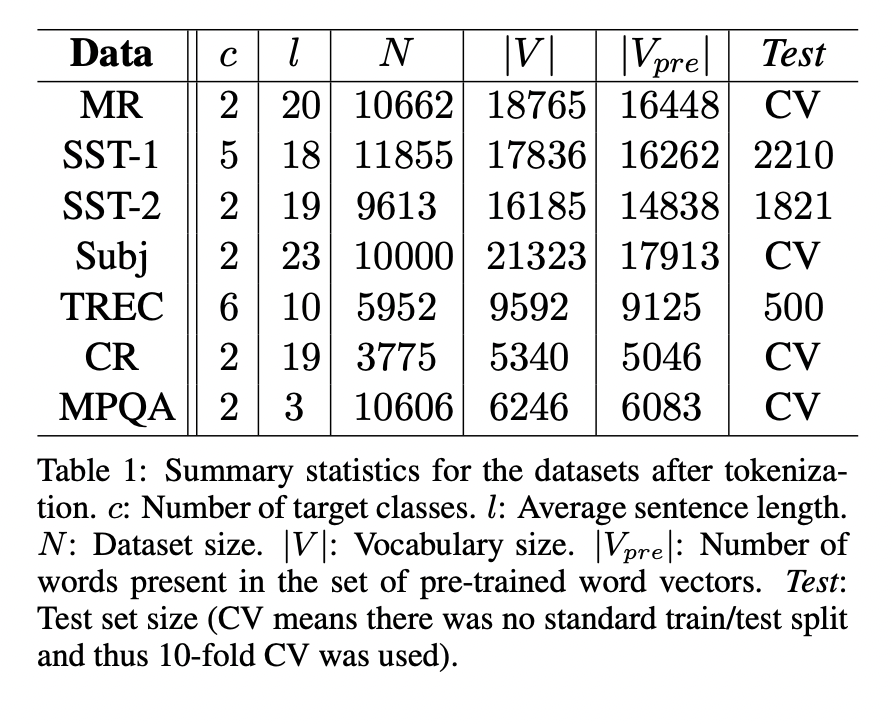
3.1 Hyperparameters and Training
- ReLU
- Filter window = 3, 4, 5
- Feature maps = 100
- Dropout rate = 0.5
- L2 constraint = 3
- Mini-batch size = 50
- SGD, Adadelta
3.2 Pre-trained Word Vectors
- 100M Google News를 통해 학습된 dimension 300의 Word2Vec
3.3 Model Variation
- CNN-rand : 모든 단어들이 random하게 초기화, 학습을 통해 수정
- CNN-static : word2vec pretrained vector사용, unknown 단어는 random하게 초기화, 단어 벡터들은 학습되지 않으면 그 외 parameter들만 학습
- CNN-non-static : CNN-static과 모두 동일하지만, pre-trained vector 역시 학습
- CNN-multichannel : 2쌍의 Word vector 활용, 한 쌍의 word vector만 학습되고 다른 한쌍은 학습되지 않음, 초기값은 word2vec 활용
4. Results and Discussion
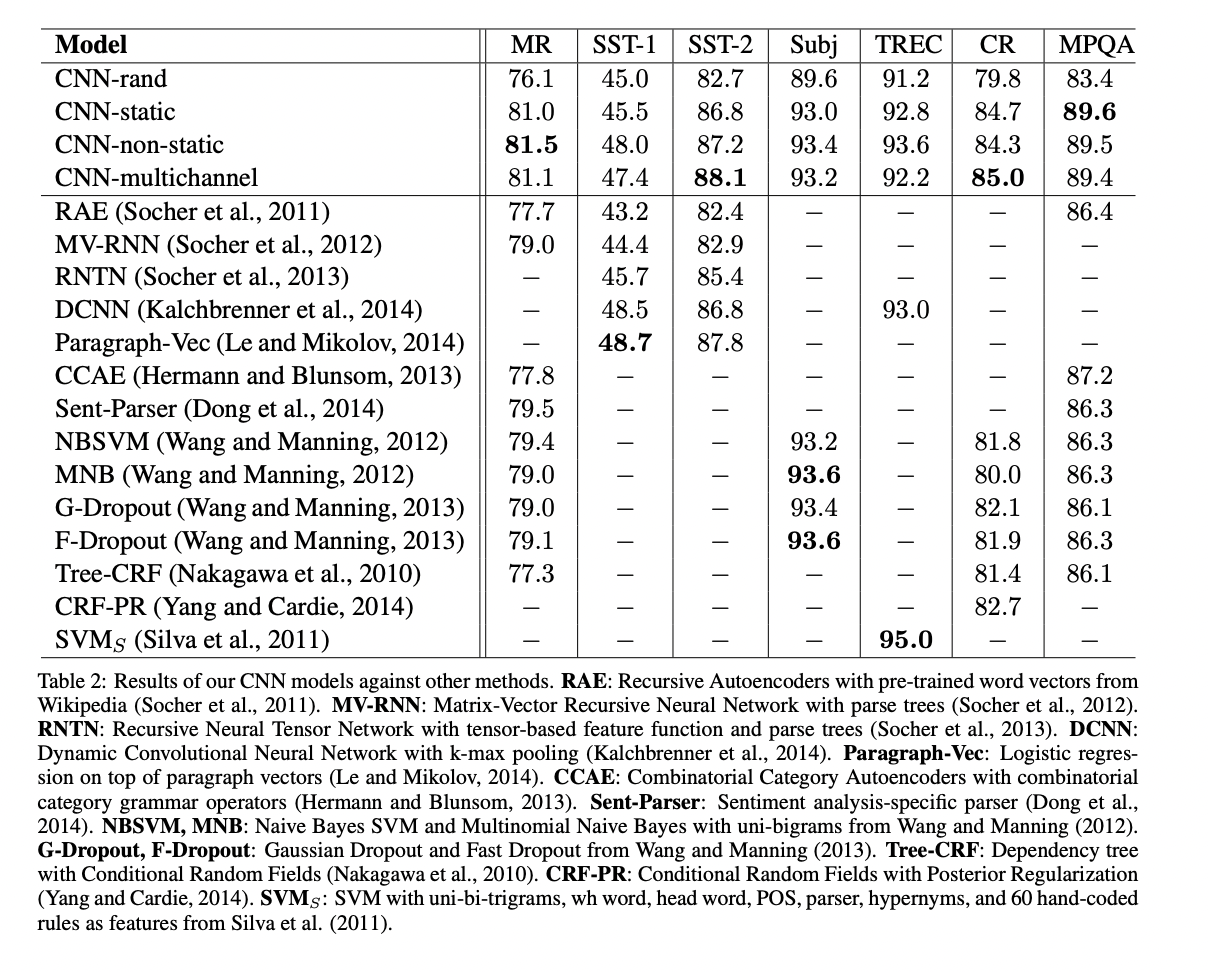
위의 결과를 통해 Pretrained word vector는 다양한 dataset에서 활용할 수 있는 좋은 universal feature extractor임을 알 수 있습니다.
4.1 Multichannel vs Sing Channel Models
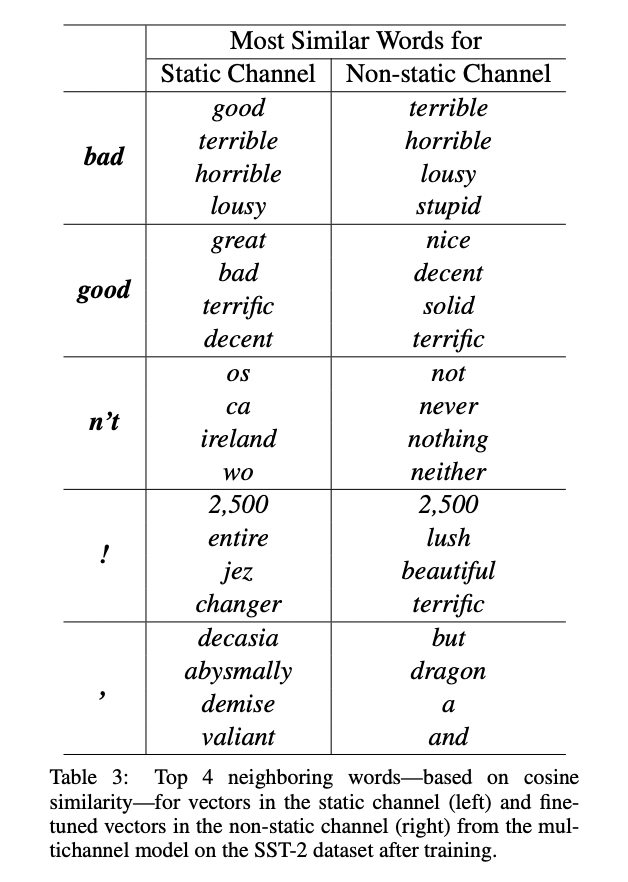
4.2 Static vs Non-static Representaion
5. Conclusion
해당 논문에서는 word2vec의 최상단에 CNN을 사용한 실험을 진행하였습니다. 약간의 hyperparameter 수정만 했을뿐인데도, simple CNN은 의미있는 성능 향상을 보였습니다. 또한 이번 실험은 NLP를 위한 deep learning에서 unsupervised pre-trained word vector는 중요한 요소라는 주장의 하나의 근거가 되고 있습니다.
