- 데이터가 가지고 있는 특성을 파악하기 위해 해당 변수의 분포 등을 시각화하여 분석하는 것은 어떠한 분석방식에 포함되는가?
① 전처리 분석
② 탐색적 자료 분석(EDA)
③ 공간분석
④ 확증적 자료 분석(CDA)
01. 탐색적 자료분석(Exploratory Data Analysis)은 다양한 차원과 값을 조합해가며 특이한 점이나 의미있는 사실을 도출하고 분석의 최종목적을 달성해가는 과정이다.
- 탐색적 데이터 분석의 목적은 데이터를 이해하는 것이다. 다음 중 이에 대한 설명으로 가장 부적절한 것은?
① 데이터에 대한 전반적인 이해를 통해 분석 가능한 데이터인지 확인하는 단계이다.
② 탐색적 데이터 분석 과정은 데이터에 포함된 변수의 유형이 어떻게 되는지를 찾아가는과정이다.
③ 데이터를 시각화하는 것만으로는 이상점(outlier) 식별이 잘 되지 않는다.
④ 알고리즘이 학습을 얼마나 잘 하느냐 하는 것은 전적으로 데이터의 품질과 데이터에 담긴정보량에 달려 있다.
02. 상자그림(Box Plot)등의 그래프로 시각화를 한다면 이상치를 식별하기가 쉽다.
- 아래는 탐색적 자료분석과 확증적 자료분석을 비교한 표이다. 틀린 것은?
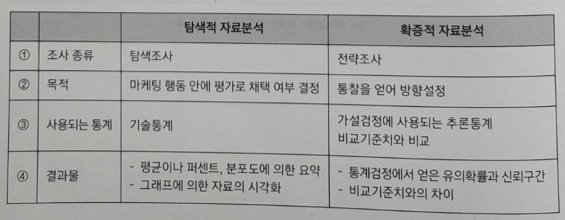
정답: 2번.
03. 탐색적 자료분석의 목적은 통찰을 얻어서 방향을 설정하는 것이고, 확증적 자료분석의 목적은 마케팅 행동 안에 평가로 채택여부를 결정하는 것이다.
- EDA의 4가지 주제 중 틀린 것은 무엇인가?
① 저항성 강조는 데이터의 이상치, 결측치 또는 입력 오류에 영향을 받는 도구를 사용한다는뜻이다.
② 잔차를 계산하면 어떤 특정 데이터가 다른 경향을 가지고 있는지 살펴볼 수 있다.
③ EDA의 시각화는 낮은 수준이지만 필수적이며 복잡한 분석보다 훨씬 직관적으로 데이터에대한 통찰을 얻을 수 있다.
④ 로그 변환이나 제곱근 변환 등을 통해 원래의 변수를 바꾸는 방법은 데이터의 재표현이라고한다.
04. 저항성 강조는 데이터의 이상치, 결측치 또는 입력 오류에 영향을 받지 않는 도구를 사용한다는 것을 뜻한다.
- 기술통계의 산포를 나타내는 도구의 설명이 틀린 것은?
① 평균(mean) - 데이터의 전체 합을 전체 개수로 나누어 산출하는 대표 값
② 중위수(median) - 데이터를 입력순서에 따라 나열하여 가장 중앙에 위치하는 값
③ 사분위수(quartile) - 데이터를 작은 수부터 큰 수까지 배열했을 때 전체 관측값을
4등분하는 위치에 오는 값을 n 사분위수라 함
④ 백분위수(percentile) - 크기가 있는 값들로 이루어진 자료를 순서대로 나열했을 때
전체 데이터 개수의 p%에 위치하는 값을 P 백분위 값이라고 함
05.중위수는 데이터를 크기 순서에 따라 나열하여 가장 중앙에 위치하는 값을 나타낸다.
- 아래의 데이터는 R 프로그램을 통해 두 종류의 수면유도제(group)에 대해 무작위로 선정된 20명의
환자를 대상으로 수면 시간의 증감(extra)을 측정한 자료이다. 다음 중 결과에 대한 설명으로 가장
부적절한 것은?


① 평균적으로 1.54 시간의 수면시간 증가를 가져왔다.
② 3.4시간 이상 수면이 증가한 환자는 약 25%이다.
③ 모든 환자들의 수면시간이 증가하였다.
④ 가장 많이 증가한 수면시간은 5.5시간이다.
06. extra 변수의 값들을 보면 음수가 있어 수면시간의 감소도 있음을 확인할 수 있다.
- 10개의 실수 관측값을 수집하여 평균과 표준편차를 구한 결과 10과 2의 값을 얻었다. 모든 관측치에 4를 더한 후에 평균과 표준편차를 구하면 그 값들은 얼마가 될까?
① 10과 2로 변화가 없다.
② 평균은 14가 되고 표준편차는 2가 된다.
③ 평균은 14가 되고 표준편차는 4가 된다.
④ 평균은 14가 되고 표준편차는 6이 된다.
07. 모든 관측치에 4를 더하여 평균을 구하면 평균은 기존의 평균 10에서 4가 증가된 14가 된다. 표준편차는 모든 값이 동일하게 증가했으므로 변화가 없어 표준편차는 2가 된다.
- 아래는 미국의 대학교와 관련된 데이터 중 Terminal 변수의 요약 통계를 R 프로그램을 활용해나타내었다. Terminal 변수의 약 몇 %가 92 보다 큰 값을 가지는가?
summary(College$Terminal)
Min. 1st Qu. Median Mean 3rd Qu. Max.
24.0 71.0. 82.0 79.7 92.0 100.0
① 100%
② 75%
③ 50%
④ 25%
08. 3d Qu.는 3사분위수를 의미하여 Terminal 변수를 크기순으로 나열했을 때, 75%에 해당하는 숫자가 92이다. 92가 75%이므로 92보다 큰 값을 가지려면 나머지 25%에 해당해야 한다.
- R 프로그램에서는 연속형 변수에 대해 요약통계량을 구하면 평균 등을 나타내 주고, 범주형변수에대해 빈도를 나타내준다. R 프로그램에 내장되어 있는 Wage 데이터셋에 대한 아래 요약통계량에 대한 설명으로 가장 부적절한 것은 무엇인가?

ⓘ wage의 최소값은 20.09이다.
② education은 5개의 그룹으로 구분된다.
③ wage는 범주형 변수이다.
④ education은 범주형 변수이다.
09. summary 결과에서 wage 변수는 최소, 최대값과 1, 3사분위수, 평균, 중앙값을 나타내 연속형 변수임을 알 수 있다.
- 모집단이나 표본에 속한 특성값들이 얼마나 흩어져서 분포하고 있는지를 나타내는 측도를 산포 측도라 한다. 다음 중 산포측도에 대한 설명이 부적절한 것은 무엇인가?
① 분산은 데이터의 값이 평균으로부터 떨어져 있는 정도를 나타내는 값이다.
② 범위는 자료의 최대값과 최소값의 차이이며, 이상치가 포함된 경우 범위가 매우 커질 수 있다는 단점이 있다.
③ 사분위수범위는 IQR 이라고도 하며, 데이터의 Q3 값과 Q1값의 차이를 나타내는 값이다.
④ 평균의 표준오차는 일반적으로 표본의 크기 n이 작아지면 표준오차도 작아진다.
10. 평균의 표준오차는 일반적으로 표본의 크기인 n이 커지면 표준오차는 작아진다.
- 다음 중 소득 수준과 같이 정규 분포를 따르지 않고 오른쪽 꼬리가 긴(right-skewed)분포를 나타내는 자료의 평균과 중앙값의 관계로 옳은 것은 무엇인가?
① 자료의 크기(scale)에 따라 달라진다.
② 평균이 중앙값보다 작은 경향을 보인다.
③ 평균과 중앙값이 일치하는 경향을 보인다.
④ 평균이 중앙값보다 큰 경향을 보인다.
11. 오른쪽 꼬리가 긴 분포를 나타내면 최빈값 <중앙값 <평균의 순서로 값의 크기를 확인할 수 있다.
- 다음 중 중앙 50%의 데이터들이 흩어진 정도를 의미하는 것은 무엇인가?
① 사분위범위(interquartile range)
② 중앙값(median)
③ 표준편차(standard deviation)
④ 평균(mean)
12. 사분위범위는 아래사분위수(Q1, 25%)와 위사분위수(Q3, 75%)의 차이로 중앙 50%의 데이터의 흩어진 정도로 정의한다.
- 아래는 응답자의 키와 몸무게를 나타낸 표이다. 키와 몸무게의 평균과 분산은 무엇인가?
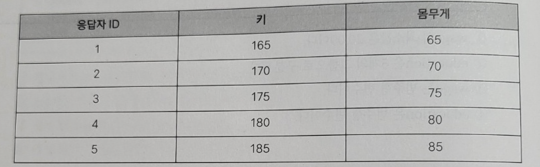
① 키 평균 : 175, 키 분산 : 62.5, 몸무게 평균 : 75, 몸무게 분산 : 62.5
② 키 평균 : 175, 키 분산 : 8, 몸무게 평균 : 75, 몸무게 분산 : 8
③ 키 평균 : 160, 키 분산 : 62.5, 몸무게 평균 : 70, 몸무게 분산 : 8
④ 키 평균 : 160, 키 분산 : 8, 몸무게 평균 : 70, 몸무게 분산 : 62.5
13. 키와 몸무게에 대한 평균은 각각 (165+170+175+180+185)/5=175 (65+70+75+80+85)/5=75이며, 분산은 각각 ((165-175)^2+...(185-175)^2)/4=62.5, ((65-75)^2+..(85-75)^2)/4=62.5이다.
- R 프로그램에서는 연속형 변수에 대해 요약통계량을 구하면 평균 등을 나타내 주고, 범주형 변수에대해 빈도를 나타내준다. 아래는 R의 내장 데이터인 cars에 대한 각 변수별 기술통계량을 도출한 것이다. 아래 설명 중 가장 부적절한 것은?

① cars 자료는 두 개의 수치형 변수로 구성되어 있다.
② speed 변수의 평균의 중앙값보다 크다.
③ cars 자료는 결측값이 포함되지 않은 자료이다.
④ speed 변수의 75% 백분위수는 이자료에서 알 수 없다.
14.speed 변수의 75% 백분위수는 30 Qu로 표현된 3사분위수를 통해 알 수 있다.
- 100명의 키를 cm으로 측정한 데이터의 분산이 225였다. 동일한 100명의 키를 m로 측정한다면 데이터의 분산은 얼마인가?
① 0.0225
② 0.225
③ 2.25
④ 22.5
15. cm로 측정했을 때 분산이 225이라고 할 때, m로 측정하면 1cm=0.01m이다. 분산을 구할 때 (평균 - 관측값)의 제곱값이므로 단위 역시 제곱값을 취하게 되어 기존 분산 225* (0.01)^2=0.0225가 된다.
- 아래 그림에서 (a), (b), (c)에 해당하는 통계량으로 적절한 것은?
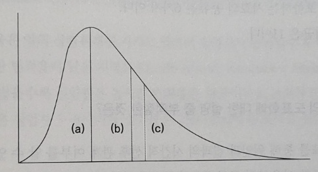
①(a) 평균, (b) 중앙값, (c) 최빈값
②(a) 최빈값, (b) 중앙값, (c) 평균
③(a) 평균, (b) 최빈값, (c) 중앙값
④(a) 최빈값, (b) 평균, (c) 중앙값
16. 오른쪽 꼬리가 긴 분포를 나타내면 최빈값, 중앙값, 평균의 순서로 값이 나타남을 확인할 수 있다.
- 모집단과 표본의 특성을 파악하는 방법으로써 특성값들의 대략적인 크기를 나타내는 측도를 위치 측도(Location Parameter)라 한다. 다음 중 위치 측도에 대한 설명으로 가장 부적절한 것은?
① 표본평균(sample mean)은 데이터의 합계를 데이터의 총 개수로 나눈 값이다.
② 중앙값(Median)은 데이터를 크기 순으로 나열할 때 가장 중앙에 위치하게 되는 데이터 값이다.
③ q-분위수(q-quantile)는 정렬된 데이터를 균등하게 q개로 나누는 값들이다.
④ q-백분위수(q-percentile)는 전체 데이터중 p번째 순위에 해당하는 값을 의미한다.
17. p-백분위수는 전체 n개의 데이터를 크기순으로 배열하고 관측값의 개수(n)에 p(percent)를 곱한 위치에 해당하는 수이다.
- R 프로그램에서는 연속형 변수에 대해 요약통계량을 구하면 평균 등을 나타내 주고, 범주형 변수에대해 빈도를 나타내준다. 아래는 닭 사료의 종류(feed)와 닭의 성장(weight)의 관측치를 포함하고있다. 아래의 기술통계량에 대한 설명이 가장 부적절한 것은?
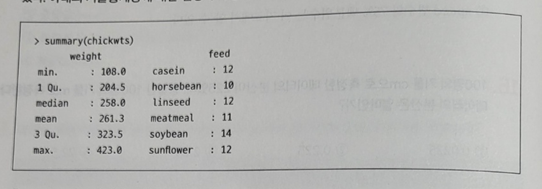
① feed는 범주형 변수이다.
② 약 25%의 닭의 weight가 204.5보다 작다.
③ 데이터가 포함하는 사료의 종류는 6가지 이다.
④ feed의 평균은 11이다.
18. feed는 범주형 변수로 평균값을 구할 수 없다.
- 다음 중 자료의 도표화에 대한 설명 중 부적절한 것은?
① 도수분포표를 통해 원인과 결과의 시간적 선후 관계 여부를 알 수 있다.
② 도수분포표를 이용하여 표본자료의 분포를 나타낸 그래프를 히스토그램이라고 한다.
③ 산점도를 통해 자료의 선형 또는 비선형 관계의 여부를 파악할 수 있다.
④ 도수분포표는 특정 값에 대한 자료의 개수를 하나의 표로 나타낸 것이다.
19. 도수분포표의 정보만으로 원인과 결과의 시간적 선후 관계 여부를 알기 어렵다.
- 다음은 실업자와 범죄율에 따른 인구를 나타내는 산점도이다. 점의 크기가 클수록 인구가 커지는 버블차트이다. 아래의 버블차트에 대한 설명 중 틀린 것은 무엇인가?
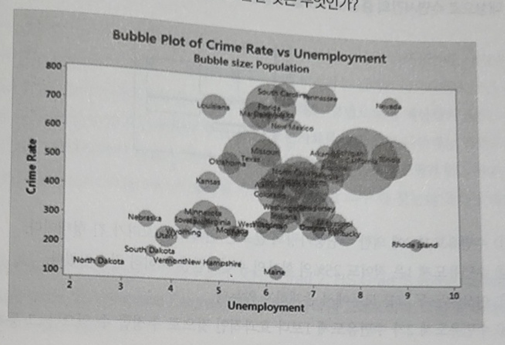
① 실업자와 범죄율은 양의 상관관계를 가지고 있어서 실업자가 늘어날수록 범죄율이 증가한다.
② 실업자가 많지만 범죄율이 낮은 지역은 Rhode Island, Kentucky, Maine 등이 있다.
③ 인구가 많으면 많을수록 실업률은 높지만 범죄율은 평균이하로 분포하고 있다.
④ 대부분의 지역은 실업자 5~8사이에 범죄율은 250~600에 분포하고 있다.
20. 인구가 많으면 많을수록 실업률과 범죄율이 함께 증가하고 있음을 확인할 수 있다.
- 자료의 특징이나 분포를 한 눈에 보기 쉽도록 시각화하는 작업은 매우 중요하다. 다음 중 상자그림(box plot)에 대한 설명으로 가장 부적절한 것은?
① 자료의 크기 순서를 나타내는 5가지 통계량(최소값, 최대값, 1사분위수, 중앙값, 3사분위값)을 이용하여 시각화하는 방법이다.
② 이상치를 판단하기에는 적합하지 않다.
③사분위수를 한 눈에 볼 수 있다.
④ 자료의 범위를 개량적으로 알 수 있다.
21. 상자그림의 범위 밖에 * 등의 표시로 나타나는 관측치는 이상치로 판단할 수 있다.
- 아래의 데이터는 두 가지 종류의 수면유도제(group)에 대해 랜덤으로 선정된 두 그룹의 환자들을 대상으로 수면시간의 증감(extra)을 측정한 자료이다. 다음의 결과에 대한 설명 중 부적절한 것은?
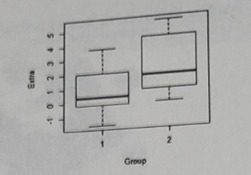
① 수면유도제 2에 의한 수면증가량의 분포는 왼쪽으로 꼬리가 긴 형태이다.
② 수면유도제 1은 적어도 25%의 환자의 수면시간을 오히려 감소시켰다.
③ 이상치는 두 그룹 모두에서 존재하지 않는다.
④ 수면유도제 2가 수면유도제 1보다 효과적인 것으로 추정할 수 있으나 그 통계적 유의성은 판단 할 수 없다.
22. 수면유도제 2에 의한 수면증가량의 분포는 중앙값과 값들이 왼쪽으로 치우쳐져 오른쪽으로 꼬리가 긴 형태가 나타날 것이다.
- 여섯 가지 종류의 닭 사료 첨가물의 효과를 비교하기 위한 데이터와 그래프이다. 그래프에 대한 설명으로 다음 중 적절하지 않은 것은 무엇인가?
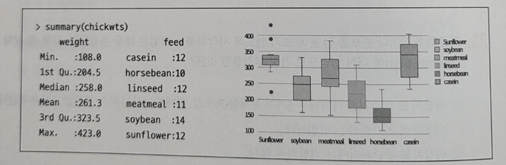
① Weight의 중앙값은 horsebean 그룹이 가장 작다.
② 이상값이 존재하지 않는다.
③ Meatmeal 그룹과 Linseed 그룹의 Weight의 평균이 유의한 차이가 있는지 알 수 없다.
④ Horsebean 그룹에서 Weight가 150보다 작은 개체가 약 50% 가량 된다.
23. sunflower의 상자그림에서 이상치가 점으로 나타나 있는 것을 확인할 수 있다.
- 다음 중 표본을 도표화함으로써 모집단 분포의 개형을 파악하는 방법에 대한 설명으로 가장부적절한 것은?
① 히스토그램은 도수분포표를 이용하여 표본자료의 분포를 나타낸 그래프이다. 수평축 위에계급구간을 표시하고 그 위로 각 계급의 상대도수에 비례하는 넓이의 직사각형을 그린 것이다.
②줄기잎그림은 각 데이터의 점들을 구간단위로 요약하는 방법으로써 계산량이 많다.
③ 산점도는 두 특성의 값이 연속적인 수인 경우, 표본자료를 그래프로 나타내는 방법으로써 각 이차원 자료에 대하여 좌표가 (특성 1의 값, 특성 2의 값)인 점을 좌표평면 위에 찍은 것이다.
④ 파레토그림(pareto diagram)은 명목형 자료에서 "중요한 소수"를 찾는데 유용한 방법이다.
24. 각 데이터의 점들을 구간단위로 요약하는 방법은 히스토그램을 만드는 것이며, 줄기잎그림은 계산량이 많지 않다.
- 아래는 근로자의 임금(wage)과 교육수준(1. <HS Grad 2, HS Grad. 3,some College, 4. College Grad, 5,Advanced Degree))의 관계를 나타낸 그래프이다. 다음 중 아래에 대한설명으로 부적절한 것은?
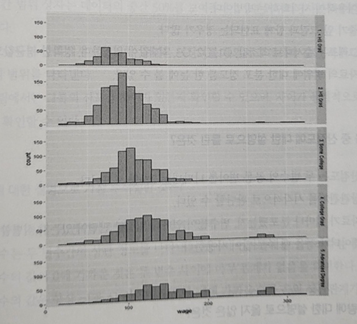
① 각 학력 수준에 따라 임금의 분포를 나타낸다.
② 학력 수준이 높아질수록 임금은 높아지는 경향이 있다.
③ 각 막대의 높이는 임금 수준을 나타낸다.
④ 5. Advanced Degree 그룹의 임금 분포는 낙도형이다.
25. 히스토그램의 각 막대의 높이는 빈도를 나타낸다. 임금 수준은 x축을 통해서 확인할 수 있다.
- 히스토그램은 표로 되어 있는 도수분포표를 그래프로 나타낸 것이다. 다음 중 히스토그램에 대한 설명으로 부적절한 것은?
① 히스토그램에서는 가로축이 계급, 세로축이 도수를 나타낸다. 계급은 보통 변수의 구간이며,서로 겹치지 않는다.
② 히스토그램은 표본의 크기가 작아도 각 막대의 높이가 데이터 분포의 형상을 잘 표현해낸다.
③ 그래프의 모양이 치우쳐있거나 봉우리가 여러 개 있는 그래프는 비정규 데이터일 수 있다.
④ 봉우리가 여러 개 있는 데이터는 일반적으로 2개 이상의 공정이나 조건에서 데이터가 수집되는 경우 발생한다.
26. 히스토그램은 표본의 크기가 작으면 각 계급에 해당하는 빈도가 동일해져 각 막대의 높이가 데이터 분포의 형상을 잘 표현해내지 못한다.
- 다음 중 상자그림 (Box Plot)에 대한 설명으로 부적절한 것은?
① 최대값, 최소값, 사분위수(제1사분위수, 중앙값, 제3사분위수)의 다섯 가지 순서통계량을 이용하여 시각화하는 방법이다.
② 줄기 잎 그림과 함께 표현되는 경우가 많다.
③ 그래프는 순서대로 최소값, Q1, Q2 Q3, 최대값이 위치하며, 정확한 평균값도 확인할 수 있다.
④ 자료의 범위에 대한 분포 정도를 한 눈에 볼 수 있다.
27. 상자그림을 통래서 5가지 통계량(최소값, 최대값, 제1사분위수, 중앙값(제2사분위수), 제3사분위수)에 대한 정보를 확인할 수 있지만, 정확한 평균값은 확인할 수 없다.
- 다음 중 산점도에 대한 설명으로 틀린 것은?
① 산점도는 두 변수의 공통 변이를 나타내는 2차원 도표이다.
② 상관관계를 시각적으로 판단할 수 있다.
③ 자료가 얼마나 분포됐는지, 변수들이 얼마나 밀접한 관련이 있는지 식별할 수 있다.
④ 데이터가 적을 때 주로 많이 사용한다.
28. 산점도는 데이터가 많을 때 유용하며, 적을 경우에는 막대그래프나 일반 표가 더 효과적일 수 있다.
- 통계량에 대한 설명으로 옳지 않은 것은?

정답:4번.
29. n이 짝수인 경우, 중앙값은 번째 값과 +1번째 값의 평균으로 구한다.
- 시각적 데이터 탐색의 그래프에 대한 설명 중 틀린 것은?
① 막대그래프는 막대의 높이가 특정 집계에 비례하여 계급을 비교하는 것이 목적일 때
주로 사용 되는 그래프이다.
② 선 그래프는 선의 기울기가 완만할수록 변화가 크다는 것을 의미한다.
③ 도수다각형은 연결된 직선의 모양 때문에 꺾은선 그래프라고도 한다.
④ 도수분포표의 계급의 수와 간격이 변하면 히스토그램의 모양도 변한다.
30. 선그래프는 x축의 연속형 변수의 변화에 따른 y축의 변화를 선으로 나타내는 그래프로 선의 기울기가 급할수록 변화가 크다는 것을 의미한다.
- 상자그림은 자료로부터 얻은 통계량인 5가지 요약 수치의 그림이다. 5가지 요약 수치는 min,max, Q1, Q2, Q3이다. 다음 중 상자그림에 대한 설명으로 부적절한 것은?
① 중위수는 상자 안에 선으로 표시되며, 관측치의 절반은 이 값보다 크거나 같고 절반은 작거나 같다.
② 사분위간 범위 상자는 데이터의 중간 50%를 보여주며, 1사분위수와 3사분위수간의 거리를 보여준다.
③ 수염은 상자의 양쪽에서 연결되며, 수염은 이상치를 제외하고 데이터 값의 하위 25%, 상위25%의 범위를 나타낸다.
④ 상자그림에서는 그룹의 산포간 차이가 있는지 확인할 수 있으며, 차이가 통계적으로 유의한지 여부도 확인할 수 있다.
31. 상자그림을 통해서 그룹 간 차이가 통계적으로 유의한지 여부를 파악할 수 없다. 그룹 간 평균 및 분산의 차이에 대해서는 통계적 검정을 통해서 여부를 파악할 수 있다.
- 상관분석에 대한 설명으로 가장 부적절한 것은?
① 상관계수를 통해 두 변수의 상관관계를 알 수 있다.
② 상관계수는 두 변수간의 상관 정도를 나타내는 것이지 인과관계를 설명해주는 것은 아니다.
③ 상관계수의 값이 0에 가까운 것은 두 변수 사이에 아무 관계가 없음을 의미한다.
④ 상관계수의 값은 항상 -1과 +1 사이에 있으며 +1에 가까울수록 음의 상관관계가 뚜렷한 것이다.
32. 상관계수 값이 +1에 가까울수록 양의 상관관계를 가지며, -1에 가까울수록 음의 상관관계를 가진다.
- 아래의 산점도 행렬에 대한 설명으로 가장 부적절한 것은?

① Temp와 Wind 간의 관계는 비선형이다.
② Solar.R와 Ozone의 관계는 명확하지 않다.
③ Solar.R과 Wind 간에는 양의 상관관계가 있다.
④ Ozone와 Temp간에는 선형 관계가 있다.
33. Solar.R과 Wind 간의 산점도를 보면 선형성이 띄고 있지 않아, 상관관계를 확인할 수 없다.
- 두 확률변수 X와 Y의 상관계수가 0.5일 때 다음 중 옳은 것은?
① -X와 Y의 상관계수는 0.5이다.
② X+0.1 과 Y의 상관계수는 0.5이다.
③ X와 Y의 상관계수는 1이다.
④ X+0.3과 2Y의 상관계수는 1이다.
34.X+0.1 과 Y의 상관계수는 X값 전체가 동일하게 증가했기 때문에 상관계수에는 변동이 없으므로 0.5이다. ① -X와 Y의 상관계수는 방향이 바뀌어 -0.5가 된다. 820 ③X와 Y의 상관계수는 크기가 커지면 평균도 증가하기 때문에 상관계수가 증가하지 않고 동일한 값인 0.5가 된다. ④ X+0.3과 2Y를 하면 값들이 동일하게 증가하므로 상관계수도 0.5가 된다.
- 다음 중 상관분석의 정의로 틀린 것은?
① 데이터의 두 변수 간의 관계를 알아보기 위한 분석방법이다.
② 두 변수의 상관관계를 알아보기 위해 상관계수를 이용한다.
③ 상관계수가 0일 때는 데이터 간의 상관관계를 정의할 수 없다.
④ 상관계수가 1에 가까울수록 데이터가 강한 양의 상관관계를 갖는다.
35. 상관계수가 0일 때는 선형관계가 존재하지 않아 상관관계가 없다고 할 수 있다.
- 아래는 스위스 내 47개의 프랑스어 사용 지역에서의 출산율과 관련된 변수들을 사용하여 그린 그림이다. 다음 중 시각화 자료에 대한 설명으로 가장 적절한 것은?

① 출산율(Fertility)은 시험(Examination)과 음의 상관관계를 가진다.
② 출산율(Fertility)과 가장 상관관계가 높은 변수는 가톨릭인구 비율(Catholic)이다.
③ 교육수준(Education)이 높을수록 출산율(Fertility)은 높아진다.
④ 출산율(Fertility)과 농업인구 비율(Agriculture)은 선형관계를 보인다.
36. ② 출산율(Fertility)과 가톨릭인구 비율(Catholic)은 산점도로 보아 상관관계가 없음을 확인할 수 있다. ③ 교육수준(Education)이 높을수록 출산율(Fertility)은 음의 상관관계를 보이고 있어 교육수준이 높을수록 출산율은 낮아진다. ④ 출산율(Fertility)과 농업인구 비율(Agriculture)의 산점도는 고르게 분포되어 선형성을 띄고있지 않다.
- 아래는 스위스의 47개의 프랑스어 사용지역의 출산율(Fertility)과 관련된 변수들을 사용하여 상관계수를 얻은 결과이다. 다음 설명 중 부적절한 것은?
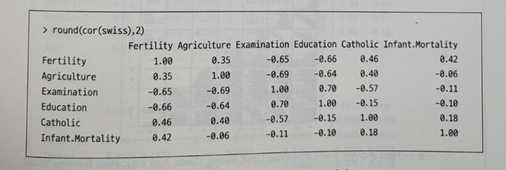
① Fertility와 가장 높은 상관관계를 갖는 변수는 Education이다.
② 서로 다른 두 개의 변수 간의 가장 큰 상관계수 값은 1이다.
③ Agriculture와 Examination은 음의 상관관계를 갖고 있다.
④ 서로 다른 두 개의 변수 간의 양의 상관관계가 가장 강한 변수들은 Education과 Examination이다.
37. 서로 다른 두 개의 변수 간의 가장 큰 상관계수 값은 Education과 Examination 간의 0.7이다. 위의 결과에서 1은 같은 변수 간의 상관계수 값이다.
- 변수 X와 Y의 피어슨 상관계수는 0.27이고 변수 X와 Z의 피어슨 상관계수는 -0.78이다. 다음 중 X, Y, Z 간 피어슨 상관계수에 대한 설명으로 가장 부적절한 것은?
① 두 상관계수의 유의성은 판단할 수 없다.
② X와 Y는 선형관계를 가진다.
③ X와 Y는 거의 상관관계가 없다.
④ X와 Y의 선형관계보다 X와 Z의 선형관계가 강하다.
38.X와 Y는 상관계수가 0.27로 거의 상관관계가 없다고 할 수 있다. 상관계수가 0에 가까울 때 두 변수는 선형이 아닌 다른 관계이거나 서로 독립적이어서 아무런 관계가 없다고 볼 수 있다.
- 다음 중 스피어만 상관계수에 대한 설명으로 부적절한 것은?
① 비선형적인 상관관계는 나타내지 못한다.
② 서열척도로 측정된 변수 간 관계를 측정한다.
③-1과 1사이의 값을 가진다.
④ 0은 상관관계가 없음을 의미한다.
39. 스피어만 상관계수는 서열척도인 두 변수들의 상관관계를 측정할 수 있으며, 순위를 기준으로 상관관계를 측정한다. 피어슨 상관계수와 동일하게 상관계수가 0이면 비선형을 띈다고 할 수 있다.
- Credit 데이터는 400명의 신용카드 고객에 대한 신용카드와 관련된 변수들이 포함되어 있다. 아래 변수간의 산점도와 피어슨 상관계수를 나타내고 있다. 아래 그림을 보고 설명이 부적절한 것은?
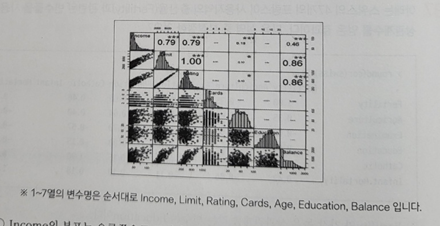
① Income의 분포는 오른쪽으로 꼬리가 긴 분포를 가진다.
② Limit와 Ratting은 거의 완벽한 선형관계를 가진다.
③ Balance와 가장 상관관계가 높은 변수는 Income이다.
④ Age와 Balance는 거의 상관관계가 없다.
40. Balance와 가장 상관관계가 높은 변수는 산점도와 상관계수를 통해 판단해 볼 수 있고, 그 결과 Limit 또는 Rating 라고 할 수 있다.
- 아래는 200개의 특정 제품의 sales(단위 : 1천개)와 TV, Radio, Newspaper 광고예산(단위:1천달러) 간의 pearson 상관계수 행렬이다. 설명이 가장 부적절한 것은?

① 3가지 매체의 광고예산은 Sales와 양의 상관계수를 띄고 있다.
② Sales와 가장 상관관계가 높은 변수는 TV이다.
③ Radio 광고예산이 증가할 때 Newspaper 광고 예산이 증가하는 경향이 있다.
④ TV 광고 예산을 늘릴 경우 Sales가 증가하는 인과관계를 가진다.
41. TV 광고 예산을 늘릴 경우 Sales가 증가하는 상관관계를 가진다. 상관계수를 통해 인과관계는 확인할 수 없다.
- Carseats 데이터프레임은 400개 상점에서 판매 중인 유아용 카시트에 대한 자료이다. 이 데이터의 일부 변수들의 상관분석 결과로 가장 부적절한 것은?
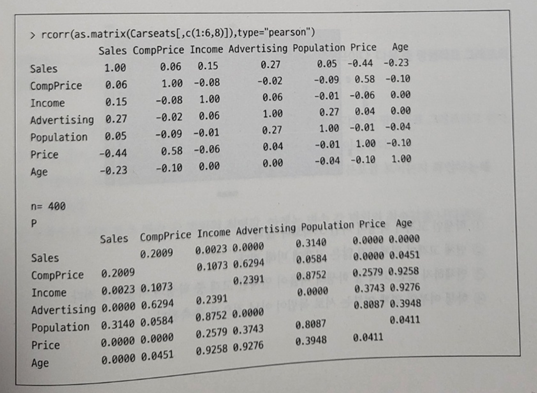
① Sales와 CompPrice 간의 상관계수는 유의하지 않다.
② Sales와 가장 강한 상관관계를 보이는 변수는 Price이다.
③ Price가 올라갈수록 Sales는 낮아지는 경향이 있다.
④ Sales와 Price는 양의 상관관계를 가진다.
42. Sales와 Price는 음의 상관관계를 가진다고 할 수 있다.
- 두 변수 간 선형 관계의 크기를 측정하는 공분산의 크기가 단위에 따라 영향을 받지 않도록 표준화된 공분산 값을 이용한 상관계수가 피어슨 상관계수이다. 두 변수의 상관관계가 존재하지 않을경우 도출되는 피어슨 상관계수의 값은?
① -1
② NA
③ 0
④ 1
43. 두 변수가 상관관계가 존재하지 않을 경우에는 0이 도출된다. 상관계수가 1이면 매우 강한 양의 상관관계를 가지고 -1이면 매우 강한 음의 상관관계를 가진다.
- Default 데이터셋은 10,000명의 신용카드 고객에 대한 카드대금 연체여부(default=Yes/No), 학생여부(student=Yes/No)를 포함한다. 아래는 default와 student 간의 관계를 나타내는 그림이다. 보기의 설명 중 옳지 않은 것은?

① 학생인 고객이 학생이 아닌 고객보다 많다.
② 연체 고객이 연체하지 않은 고객에 비해 적다.
③ 연체하지 않은 고객 중 학생의 비율이 연체한 고객 중 학생의 비율보다 적다.
④ 학생 여부와 연체 여부는 서로 독립이 아닐 것으로 추측된다.
44.사각형의 크기를 보면 student Yes가 student No보다 작게 나타나 학생인 고객이 학생이 아닌 고객보다 작다.
- 다음 중 공간 데이터 탐색 도구와 특징 중 틀린 것은?
① ArcGIS : 사람과 지도, 데이터 및 앱을 지리정보 시스템을 통해 연결해주는 소프트웨어이다.
② X-ray Map:코로플레스맵 등을 만들어 실제 지역의 데이터 관계를 살펴볼 수 있다.
③ Power Map: 엑셀 2013에서 유료로 추가 설치할 수 있는 시각화 도구로 모션차트를 결합해제공하고 있다.
ⓐ GeoChart : 구글에서 제공하며, 위도와 경도의 위치값을 모르고 지명만 알아도 시각화 작업을할 수 있다.
45.Power Map은 엑셀 2013에서 무료로 추가 설치할 수 있는 시각도구로 시간의 흐름에 따라 지도상의 데이터가 어떻게 변화하는지 시각적으로 볼 수 있는 모션 차트까지 결합해 제공하고 있다.
- 다변량 데이터에 관한 그래프에 대한 설명 중 틀린 것은?
① 선버스트 차트는 비계층 구조로된 데이터를 표현할 경우 유용하게 활용할 수 있다.
② 체르노프 얼굴은 다차원 통계데이터를 시각화하는 방법 중 하나이다.
③ 레이더 차트는 여러 측정 목표를 함께 겹쳐 놓아 비교하기에 편리하다.
④ 피벗 테이블은 엑셀에서 사용할 수 있으며 많은 양의 데이터를 요약할 수 있다.
46. 선버스트 차트는 계층 구조로 된 데이터를 표현할 경우 트리맵과 함께 유용한 그래프이다.
- 평행좌표 그래프는 다변량 데이터를 탐색하는데 활용되는 그래프이다. 다음 중 평행좌표 그래프의 설명 중 틀린 것은?
① 데이터 테이블의 각 행을 선으로 연결하는 형태의 다변량 시각화를 평행좌표 그래프라고 한다.
② 측정 값이 1개이며, 여러 개의 그룹인 경우 평행 좌표계를 이용한다.
③ 각 데이터 요소들이 어떠한 방식으로 누적돼 있는지, 어떤 분포를 보이는지 확인하는데유용하다.
④ Y축에서 윗부분은 변수 값 범위의 최댓값, 아래는 변수 값 범위의 최솟값을 나타낸다.
47. 평행좌표 그래프는 측정값이 여러 개이며, 단일 그룹인 경우 평행 좌표계를 사용한다.
- 아래 그래프의 특징으로 부적절한 것은 무엇인가?

① 영역 기반의 시각화로, 각 사각형의 크기가 수치를 나타낸다.
② 한 사각형을 포함하고 있는 바깥의 영역은 세부 분류, 내부의 사각형은 그 사각형이 포함된 대분류를 의미한다.
③ 모든 사각형의 면적은 전체 100%를 나타내며, 각각의 면적은 전체 값의 비율을 의미한다.
④ 단순 분류별 분포 시각화에도 쓸 수 있지만, 위계 구조가 있는 데이터나 트리 구조의 데이터를표시할 때 활용할 수 있다.
48. 한 사각형을 포함하고 있는 바깥의 영역은 그 사각형이 포함된 대분류, 내부의 사각형은 내부적인 세부분류를 의미한다.
- 다음 보기 중 ( )안에 들어갈 단어로 적절한 것은?
"( )은 다수의 변수를 하나의 차트에 표현하지 않고 영역을 구분해 표현하는 방식이며, 라인차트, 막대차트, 산점도 등을 활용해 만들 수 있다."
① 스몰 멀티플즈
② 선버스트 차트
③ 트리맵
④ 레이더 차트
49. 스몰 멀티플즈는 다수의 변수를 하나의 차트에 표현하지 않고 영역을 구분해 표현하는 방식이다. 복잡해 보이는 데이터의 문제를 구분해 시각화 해주며, 라인차트, 막대차트, 산점도 등을 활용해 스몰 멀티플즈를 만들 수 있다.
- 다음 중 웹 크롤링에 대한 설명 중 틀린 것은?
① 웹 크롤러를 이용해 www를 탐색해 정보를 얻어내는 컴퓨터 프로그램이다.
② 웹 페이지 크롤링을 통해 직접 접근해 정보를 수집하거나 자동 이메일 수집 또는 웹 유지관리를 위해 사용된다.
③ Scrapping은 웹 페이지의 내용 전체를 웹코드까지 가져오지만, 크롤링은 Scrapping
이외에도 웹에서 전달하고자 하는 콘텐츠를 데이터화 하는 것까지 포함한다.
④ 크롤러 구현 방법 중 Scrapy 라이브러리를 활용해 html을 파싱하여 크롤러를 구현한다.
50. 크롤러 구현 방법 중 라이브러리 중 Beautiful soup, lxml, curl 등을 통해 html을 파싱하여 기능을 지원한다. 프레임워크인 Scrapy, nutch, crawler4j를 통해 크롤링의 아키텍처 위에 확장 가능한 기반 코드를 제공한다.
