
하 벌려놓은 일들은 많고 하기는 싫지만 데이터 분석부터 해보자
사용자 데이터 분석을 통해 사용자들을 분류하기 위해 clustering을 진행하고자 한다.
고객 데이터는 고객 정보, 거래이력, 자산내역, 거래내역, 접속내역에 관련된 데이터가 있고 나는 이걸 k-means algorithm을 통해 clustering하고자 한다.
k-means 알고리즘이란?
k-means 알고리즘은 이름 그대로 평균(mean)을 활용하여 데이터를 k개의 군집으로 묶는 알고리즘이다.
k-means clustering은 데이터에 라벨이 없고 데이터의 유사도를 바탕으로 군집에 할당하여 라벨을 만드는 비지도 학습이다.
사전에 군집의 개수를 지정해줘야하고 각 개수에 맞게 초기값을 정해야한다.
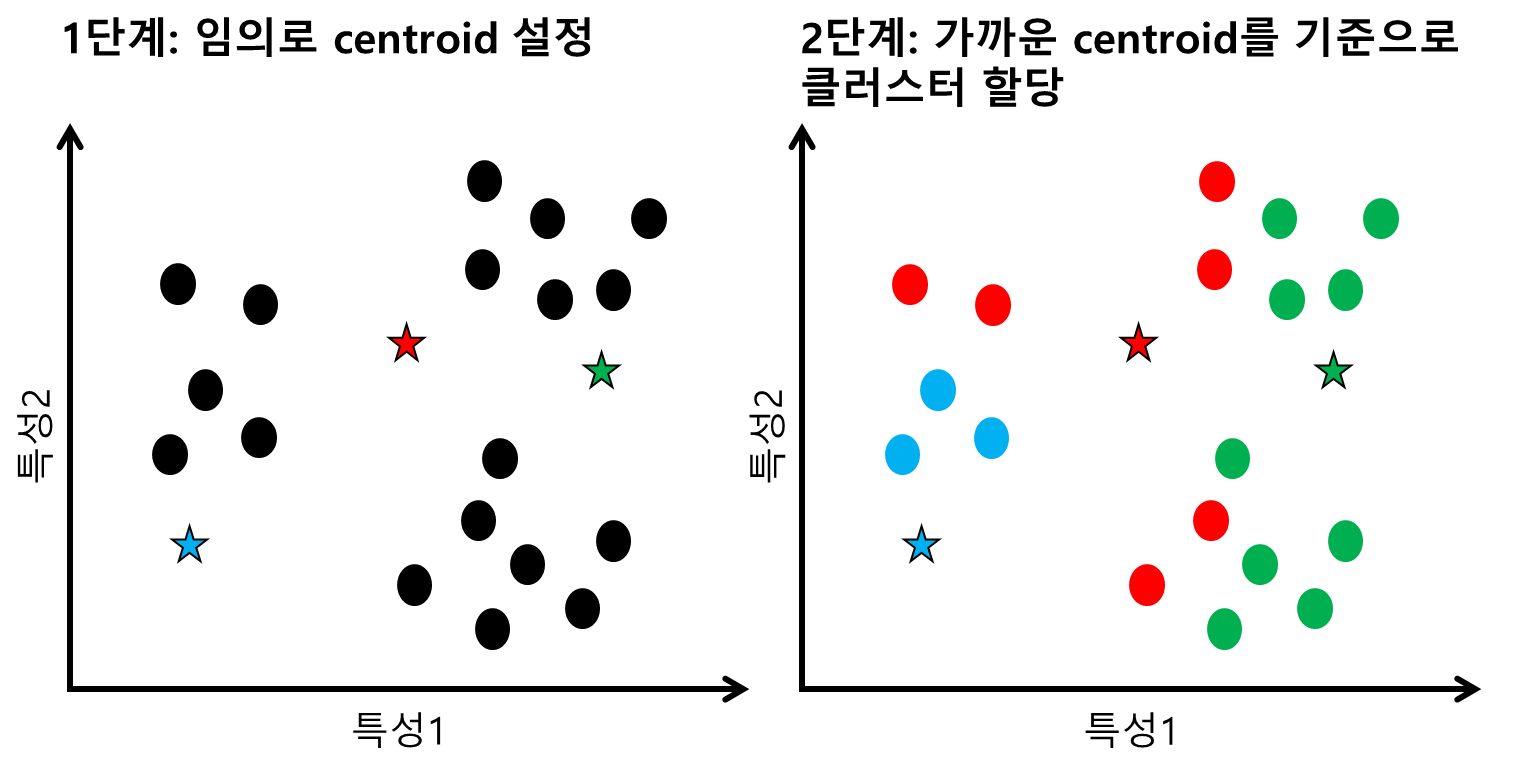
1. 임의의 초기 중심점을 배치
-> 초기 중심점을 지정하는 방법들
- randomly select (랜덤으로 설정)
- manually assign (임의의 값 지정)
- K-means ++
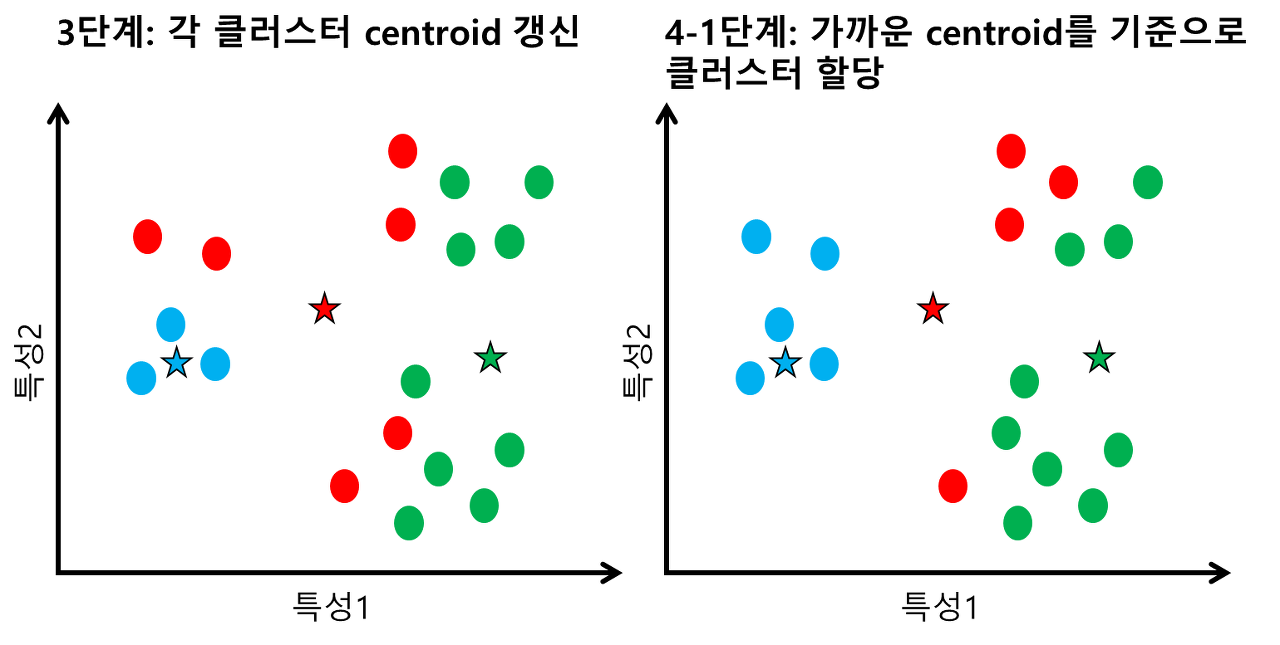
2. 각 데이터들은 자신과 가까운 중심점으로 할당
거리측정은 일반적으로 유클리드 거리로 측정한다. 거리가 가장 작은 군집으로 할당
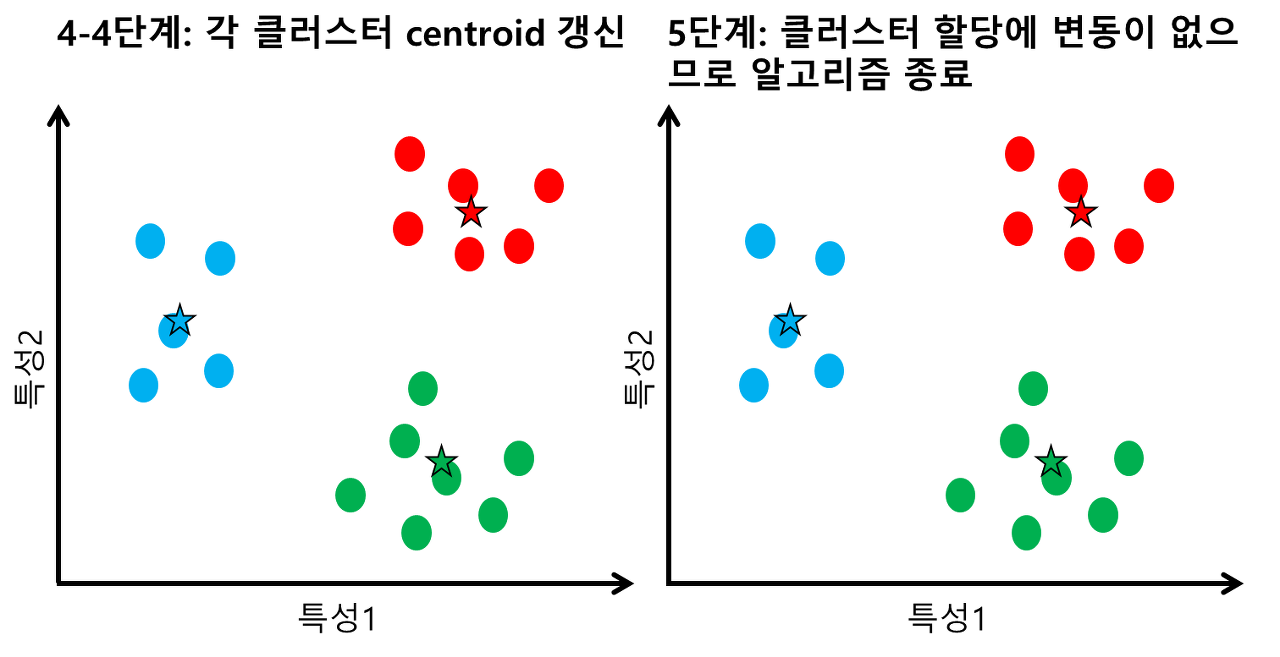
3. 군집으로 지정된 데이터들을 기반으로 군집 중심점 업데이트
중심점은 각각 군집에 속하는 데이터들의 평균에 위치하는 지점으로 업데이트 한다.
4. 더 이상 중심점이 업데이트 되지 않을 때까지 2번 3번을 반복
실제 가지고 있는 데이터로 클러스터링을 해보자구!

혼자 이것저것 해보는걸 즐깁니다..!
뛰어난 글이네요, 감사합니다.