
A Raft Protocol for the Metadata Quorum
(메타데이터 쿼럼을 위한 Raft 프로토콜)
정리
주키퍼의 메타데이터 쿼럼을 브로커로 전환하려는 제안.
Vote(투표), BeginQuorumEpoch(쿼럼 시작 알림), EndQuorumEpoch(쿼럼 종료 알림), Fetch(가져오기) 4가지 핵심 RPC로 구성되어있습니다.
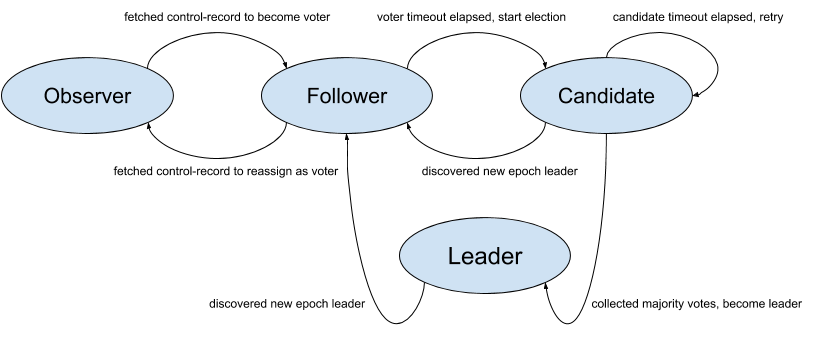
선출 과정
- 새로운 리더를 선출해야하는 이벤트 발생
- 에포크의 종료(EndQuorumEpoch)를 요청받은 경우
- fetch에 대해 응답을 못받는 경우
- 투표가 과반수가 되지 않고 종료된 경우
- 투표(Vote)를 통해 선출한 리더를 선출
- 새로운 에포크의 시작을(BeginQuorumEpoch) 알립니다.
- 이후 fetch를 통해 변경 사항을 복제합니다.
특징
- 에포크를 통한 관리
- 좀비 리더를 방지
- 재시도 백오프는 quorum.retry.backoff.ms로 시작해 quorum.retry.backoff.max.ms 까지 도달
- 오프셋이 가장 큰 복제본이 항상 선택된다는 것을 보장하지 않습니다.
아래 KIP-595 내용입니다.
- 부모 KIP
- Motivation
- Key Concepts
- State Machine
- Configurations
- Persistent State
- Log Structure
- Quorum State
- Leader Election and Data Replication
- Metrics
- Client Interactions
- Log Compaction and Scanpshots
- Quorum performance
- Test Plan
- Rejected Alternatives
- References
부모 KIP
Motivation
해당 KIP 에서는 아래의 사항에 집중합니다.
- 복제 프로토콜 및 의미 체계의 사양
- 쿼럼 상태를 유지하는 데 사용할 로그 구조 및 메시지 스키마 지정
- 쿼럼 상태를 보기 위한 도구/지표
후속 KIP에 대해서는 아래와 같습니다.
- 로그 압축: KIP-630 참조
- 쿼럼 및 메시지 사양의 컨트롤러 사용: KIP-631 참조
- 쿼럼 재할당: KIP-642 참조
프로토타입 구현에서는 단일 파티션 및 __cluster_metadata 로 지정.(공식은 아닙니다.)
Key Concepts
- Leader Epoch: Leader 선택 중에 중가하는 시퀀스 Raft에서 term으로 불리는 leader epoch는 모든 리더 선택 중에 중가하는 시퀀스입니다. 이것은 좀비를 차단하고 분기된 로그를 조정하는 데 모두 사용됩니다. 로그 레코드는 로그의 오프셋과 이를 추가한 리더의 에포크로 고유하게 식별됩니다.
- High watermark: 복제 완료된 메시지 지점 쿼럼 기반의 복제 프로토콜에 대한 ISR 개념은 없지만 high watermark는 존재합니다. 대부분의 voter에게 복제되는 주요한 오프셋입니다. 커밋된 레코드가 손실되지 않도록 보장 설계되었습니다.
- Voter: 선거중에 투표할 자격이 있고 Leader가 될 수 있는 복제본 Voter또한 레코드를 리더에서 복제합니다.
- Candidate: 새로운 Leader를 선출할 때, 선거에 참가하는 Voter Voter가 새로운 리더를 선출하기로 결정할 때, 애포크를 증가시키고 스스로 투표함으로 리더 선출을 시작합니다. 이들을 candidate로 언급합니다.
- Leader: Voter가 과반수 표를 얻은 후 현재 epoch에 Leader가 됩니다. 각 epoch는 새 래코드에 대한 클라이언트 요청을 받는 단 하나의 리더가 있습니다. leader와 Voter로 quorum은 구성됩니다.
- Follower: 현재 candidate에게 투표했거나, 현재 Leader로부터 가져오는 Voter를 Follower라 합니다. 팔로워는 현재 리더의 소식을 듣지 못했거나 리더 선출이 종료되지 않은 경우 구성 제한 시간 후에 Candidate가 될 수 있습니다.
- Observer: Leader를 검색하고 로그를 복제하는 일만 담당하는 replica 투표할 자격이 없고 리더가 될 수 없는 복제본입니다. 다른 Voter와 마찬가지로 리더에서 레코드를 복제할 수는 있습니다.
State Machine
Configurations
- quorum.voters: Voter의 ID와 endpoint를 연결하는 맵입니다.
{broker-id}@{broker-host):{broker-port}
ex) quorum.voters=1@kafka-1:9092, 2@kafka-2:9092, 3@kafka-3:9092 - quorum.fetch.timeout.ms: 새로운 Leader 선출 전, 현재 Leader로 부터 가져오는 타임아웃
- quorum.election.timeout.ms: 새로운 Leader 선출 재시도 전, Candidate 과반수 득표가 없는 최대 시간
- quorum.election.backoff.max.ms: 선택 시간 초과 후 새로운 선거가 트리거되기 전의 Backoff 시간 최댓값 (재시도하는 회수 기준)입니다.
- quorum.request.timeout.ms: 보류 중인 요청이 실패한 것으로 간주되어 연결이 끊어지기까지의 최대 시간입니다.
- quorum.retry.backoff.ms: 요청 재시도 사이의 초기 지연.
이 구성과 아래 구성은 재시도 가능한 요청 오류 또는 연결 끊김에 사용되며 위의election.backoff구성과 다릅니다. - quorum.retry.backoff.max.ms: 요청 간 최대 지연.
Backoff는quorum.retry.backoff.ms부터 기하급수적으로 증가합니다
- 참조 KIP-580[KIP-580: Exponential Backoff for Kafka Clients](https://cwiki.apache.org/confluence/display/KAFKA/KIP-580%3A+Exponential+Backoff+for+Kafka+Clients) - broker.id: Raft 쿼럼에서는 기존의 broker id를 Voter id로 사용합니다.
Persistent State
이 제안은 현재 쿼럼 상태를 유지하기 위해 영구 로그와 별도의 파일이 필요합니다. 후자는 Voter의 동적 재할당과 투표 상태의 지속성을 모두 지원하는 데 필요합니다.
Log Structure
Record => Offset LeaderEpoch ControlType Key Value Timestamp
레코드는 로그의 오프셋과 레코드를 추가한 Leader의 Epoch로 고유하게 정의됩니다. 키 및 값 스키마 는 별도의 KIP에서 컨트롤러에 의해 정의됩니다. 여기서는 그것들을 임의의 바이트 배열로 취급합니다. 그러나 Raft 쿼럼 내에서만 사용하도록 예약된 로그에 "제어 레코드"를 추가하는 기능이 필요합니다.
Quorum State
쿼럼의 현재 상태를 저장하기 위해 별도의 파일을 사용합니다. 이는 편의성과 정확성을 위한 것입니다. 재시작 후 쿼럼 상태를 초기화하는 데 도움이 되지만 주어진 선거에서 어떤 브로커에 투표했는지 알기 위해서도 필요합니다. Raft 프로토콜은 Voter가 자신의 투표를 변경할 수 없도록 하므로 다시 시작하는 동안 이 상태를 유지해야 합니다.
{
"type": "data",
"name": "QuorumStateMessage",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{"name": "LeaderId", "type": "int32", "versions": "0+"},
{"name": "LeaderEpoch", "type": "int32", "versions": "0+"},
{"name": "VotedId", "type": "int32", "versions": "0+"},
{"name": "AppliedOffset", "type": "int64", "versions": "0+"},
{"name": "CurrentVoters", "type": "[]Voter", "versions": "0+", "fields": [
{"name": "VoterId", "type": "int32", "versions": "0+"}
]}
]
}LeaderId: 마지막으로 알려진 leader입니다. -1 값은 Leader가 없음을 나타냅니다.
LeaderEpoch: 이것은 마지막으로 알려진 leader epoch 입니다. 쿼럼이 부트스트랩될 때 0으로 초기화되며 절대 음수일 수 없습니다.
VotedId: 현재 epoch에서 이 복제본이 투표한 브로커의 ID를 나타냅니다. 값 -1은 복제본에 투표권이 없거나 투표할 수 없음을 나타냅니다.
AppliedOffset: 이 쿼럼 상태에 적용된 최대 오프셋(high-watermark)을 반영합니다. 이것은 로그 복구에 사용됩니다. 브로커는 초기화 시 이 시점부터 스캔하여 이 파일에 대한 업데이트를 감지해야 합니다.
CurrentVoters: 이 쿼럼에 대해 가장 최근에 참여한 Voter
주요 차이점은 Raft 알고리즘 정확성을 보장 하기 위해 로컬 로그에 추가할 때 항상 fsync를 적용 해야 한다는 것입니다 . 즉, 이 주제에 대한 그룹 플러시를 삭제합니다. 실제로는 다음과 같은 방법으로 fsync 대기 시간을 최적화할 수 있습니다. 1) Leader에 대한 클라이언트 요청에는 여러 항목이 있을 것으로 예상되고, 2) Leader의 가져오기 응답에는 여러 항목이 포함될 수 있으며, 3) Leader는 실제로 "majority - 1"이 특정 항목 오프셋에 도달했음을 알 때까지 fsync를 연기합니다. 이 잠재적인 최적화는 이 KIP 디자인의 범위를 벗어나는 미래 작업으로 남겨둘 것입니다.
로그 시작 오프셋, 복구 지점, HWM 등과 같은 기타 로그 관련 메타데이터는 다른 Kafka 토픽 파티션과 마찬가지로 기존 체크포인트 파일에 계속 저장됩니다.
Leader Election and Data Replication
모든 합의 프로토콜의 주요 기능은 Leader 선택 및 데이터 복제입니다. 이 두 가지 기능에 대한 프로토콜은 4개의 핵심 RPC로 구성됩니다.
- Vote: 선거를 시작하기 위해 Voter가 보냅니다.
- BeginQuorumEpoch: Voter에게 상태를 알리기 위해 새 Leader가 사용합니다.
- EndQuorumEpoch: Leader가 단계적으로 물러나고 새 Leader를 허용하기 위해 사용합니다.
- Fetch: 로그를 복제하기 위해 Voter와 Observer가 Leader에게 보냅니다.
쿼럼 복제의 상태를 보기 위해 하나의 새로운 API를 추가
- DescribeQuorum : Voter의 복제 상태(예: 지연)를 나열하는 관리 API입니다. 자세한 내용은 KIP-642: Dynamic quorum reassignment#DescribeQuorum 에서도 확인할 수 있습니다 .
공통 속성
- 모든 투표 저장 요청에는 Leader Epoch 대한 필드가 있습니다. Voter와 Leader는 항상 요청 epoch가 자신의 epoch와 일치하는지 확인하고 그렇지 않은 경우 오류를 반환해야 합니다.
- 우리는 모든 응답에 대한 현재 Leader 및 Epoch 정보를 편승합니다. 이렇게 하면 Leader 변경 사항을 발견하기 위한 대기 시간이 줄어듭니다.
- 이 KIP는 처음에는 single-raft 쿼럼 구현만 예상하지만 장기적으로는 multi-raft 아키텍처에 대한 문을 열어 두는 것이 유익하다고 생각합니다. 이렇게 하면 공유된 컨트롤러 또는 일반 쿼럼 기반 토픽 복제와 같은 사용 사례를 위한 문이 열려 있습니다.
위에서 언급했듯이 이 프로토콜은 Leader 선택 및 로그 복제에만 관련됩니다. Leader의 로그에 추가되는 로그 항목이나 Leader가 이를 수신하는 방법을 지정하지 않습니다. 일반적으로 이는 특정 관리 API를 통해 이루어집니다. 예를 들어 KIP-497 은 AlterISR API를 추가합니다. 메타데이터 쿼럼의 Leader(즉, 컨트롤러)가 AlterISR 요청을 받으면 해당 로그에 항목을 추가합니다. 또한 로그 압축은 메타데이터 로그의 의미 체계와 연결되어 있기 때문에 범위에서 벗어났습니다. 압축에 대한 자세한 내용 은 KIP-630 을 참조 하십시오.
공통 오류 코드 : API는 여기에 정의된 공통 오류 코드 세트에 의존합니다.
- INVALID_CLUSTER_ID: 요청이 meta.properties에 캐시된 값과 일치하지 않는 clusterId를 나타냅니다.
- FENCED_LEADER_EPOCH: 요청의 Leader Epoch가 요청 수신자에게 알려진 최신 Epoch보다 작습니다.
- UNKNOWN_LEADER_EPOCH: 요청의 Leader Epoch가 예상보다 큽니다. 이는 예상치 못한 오류입니다. 일반적인 Kafka 로그 복제와 달리 Follower가 Leader보다 먼저 최신 Epoch를 받는 일은 발생할 수 없습니다.
- OFFSET_OUT_OF_RANGE: 팔로어가 잘못된 오프셋에서 가져왔고 응답에 표시된 오프셋/Epoch로 잘라야 함을 나타내기 위해 Fetch API에서 사용됩니다.
- NOT_LEADER_FOR_PARTITION: 요청 수신자가 현재 Leader가 아님을 나타내기 위해 DescribeQuorum 및 AlterPartitionReassignments에서 사용됩니다.
- INVALID_QUORUM_STATE: 이 오류 코드는 요청이 알려진 로컬 상태와 충돌하는 경우를 위해 예약되어 있습니다. 예를 들어, 두 개의 개별 노드가 동일한 Epoch에서 Leader가 되려고 하면 잘못된 상태 변경을 나타냅니다.
- INCONSISTENT_VOTER_SET: 요청에 일치하지 않는 멤버십이 포함된 경우 사용됩니다.
아래에서는 이러한 각 API의 스키마와 동작을 설명합니다.
Vote
Voter가 Leader를 다운으로 인식하면 새로운 선거를 치르고 자신을 Candidate로 선언합니다.
새로운 선거를 시작하는 세가지 조건
- quorum.fetch.timeout.ms 만료 전에 현재 Leader로부터 FetchResponse를 받지 못한 경우
- 현재 Leader로부터 EndQuorumEpoch 요청을 받는 경우
- 자신을 Candidate로 선언한 후 quorum.election.timeout.ms 만료 전에 과반수 득표를 얻지 못한 경우.
Voter는 자신에게 먼저 투표하고 쿼럼 상태 파일을 업데이트하여 선거를 트리거합니다. 이 상태가 지속되면 Voter는 Candidate가 되고 다른 모든 Voter에게 VoteRequest를 보냅니다. Candidate를 포함한 Voter는 주어진 Epoch에서 한 번 투표한 투표를 변경할 수 없습니다.
새 선거는 항상 quorum.election.backoff.max.ms로 제한되는 임의의 시간으로 지연됩니다. 이것은 Raft 프로토콜의 일부이며 정체된 선거를 방지하기 위한 것입니다. 예를 들어 정족수 크기가 3인 경우 두 명의 Voter만 온라인 상태인 경우 각 Voter가 자신을 Candidate로 선언하고 다른 Voter에게 투표를 거부하는 반복 선거를 방지해야 합니다.
Leader Progress Timeout
기존 푸시 기반 모델에서는 Leader가 네트워크 분할로 인해 쿼럼에서 연결이 끊어지면 활성 쿼럼을 학습하기 위해 새로운 선거를 시작하거나 즉시 새 쿼럼을 구성합니다. 그러나 끌어오기 기반 모델에서 새 Leader가 새 Epoch로 선출되었고 이전 Leader를 제외한 모든 사람이 그것에 대해 알게 되었다고 가정합니다(예: 해당 Leader는 더 이상 Voter에 없으므로 BeginQuorumEpoch도 수신하지 않음). 그런 다음 이전 Leader는 새 Leader/Epoch에 대한 알림을 받지 않고 Leader에서 Follower로 정기적인 하트비트가 전달되지 않기 때문에 순수한 "좀비 Leader"가 됩니다. 이로 인해 클러스터 내부의 Observer와 클라이언트에 오래된 정보가 제공될 수 있습니다.
이 문제를 해결하기 위해 "quorum.fetch.timeout.ms" 구성을 piggy-back하여 Leader가 해당 시간 동안 대부분의 쿼럼에서 Fetch 요청을 받지 못한 경우 새 최신 쿼럼을 이해하기 위해 VoteRequest를 클러스터의 Voter 노드로 보내기 시작합니다. 알려진 Voter와 연결할 수 없으면 이전 Leader가 계속해서 새로운 선거를 시작하고 Epoch를 증가시킬 것입니다. 그리고 반환된 응답에 새로운 Epoch Leader 포함된 경우 이 좀비 Leader는 물러나고 Follower가 됩니다. 노드는 다른 Voter에 의해 대체되거나 결국 선거에서 승리할 때까지 Candidate로 남아 있습니다.
Raft 문헌에서 알 수 있듯이 이 접근 방식은 Leader에서 네트워크 파티션이 발생할 때 파괴적인 Voter를 생성할 수 있습니다. 분할된 Leader는 Epoch를 계속 증가시킬 것이며 결국 쿼럼에 다시 연결되면 매우 큰 Epoch 번호로 선거에서 승리할 수 있으므로 추가 복원 시간으로 인해 쿼럼 가용성이 줄어들 수 있습니다. 이 시나리오가 드물다는 점을 고려하여 후속 KIP에서 해결하고자 합니다.
Vote 요청 스키마
```jsx
{
"apiKey": N,
"type": "request",
"name": "VoteRequest",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+", "nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "CandidateEpoch", "type": "int32", "versions": "0+",
"about": "The bumped epoch of the candidate sending the request"},
{ "name": "CandidateId", "type": "int32", "versions": "0+",
"about": "The ID of the voter sending the request"},
{ "name": "LastOffsetEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the last record written to the metadata log"},
{ "name": "LastOffset", "type": "int64", "versions": "0+",
"about": "The offset of the last record written to the metadata log"}
]
}
]
}
]
}
```Vote 요청 처리
우리는 리더십에 **대한 추가 조건을 존중해야 합니다. Candidate의 로그는 최소한 그것에 투표한 대다수의 다른 로그만큼 최신입니다. Raft는 로그에 있는 마지막 항목의 오프셋과 Epoch를 비교하여 두 로그 중 어느 것이 더 "최신"인지 결정합니다. 로그의 마지막 항목에 다른 Epoch가 있는 경우 이후 Epoch의 로그가 더 최신입니다. 로그가 동일한 Epoch로 끝나는 경우 더 긴 로그가 최신 로그입니다. 투표 요청에는 Candidate의 로그에 대한 정보가 포함되며 Voter는 자신의 로그가 Candidate**의 로그보다 최신인 경우 투표를 거부합니다.
Voter가 Candidate가 되기로 결정하고 다른 사람에게 투표하도록 요청하면 현재 Leader Epoch를 CandidateEpoch로 증가시킵니다.
Voter가 투표 요청을 처리할 때:
- 요청의 clusterId가 캐시된 로컬 값(있는 경우)과 일치하는지 확인하십시오. 그렇지 않은 경우 투표를 거부하고 INVALID_CLUSTER_ID를 반환합니다.
- 먼저 요청의 Candidate epoch보다 큰 epoch가 알려져 있는지 확인합니다. 그렇다면 투표가 거부됩니다.
- 다음으로 해당 Candidate epoch에 이미 투표했는지 확인합니다. 그렇다면 Candidate ID가 이미 투표된 ID와 일치하는 경우에만 투표를 부여합니다. 그렇지 않으면 투표가 거부됩니다.
- Candidate Epoch가 현재 알려진 epoch보다 큰 경우:
- CandidateId가 예상 Voter 중 하나인지 확인합니다. 그렇지 않다면 투표를 거부하십시오. 이 경우 Candidate는 불완전한 Voter 재할당의 일부였을 수 있으므로 Voter는 Epoch 증가를 수락하고 스스로 새로운 선거를 시작해야 합니다.
- Candidate의 기록이 최소한 최신인지 확인하십시오(비교 규칙은 위 참조). 예인 경우 먼저 쿼럼 상태 파일을 업데이트한 다음, voteGranted가 yes인 응답을 반환하여 해당 투표를 승인합니다. 그렇지 않으면 응답과 함께 해당 요청을 거부합니다.
또한 Candidate는 항상 현재 Candidate Epoch에서 자신에게 투표합니다. 즉, 투표 요청을 보내기 전에 쿼럼 상태 파일을 "나 자신을 위한 투표"로 업데이트해야 합니다. 반면에 더 큰 Candidate Epoch가 포함된 투표 요청을 받으면 새 Epoch에 새 Leader가 선출되었을 수 있기 때문에 Voter 상태로 다시 전환하는 동시에 해당 투표를 승인할 수 있습니다.
Vote 응답 스키마
```jsx
{
"apiKey": N,
"type": "response",
"name": "VoteResponse",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ "name": "VoteGranted", "type": "bool", "versions": "0+",
"about": "True if the vote was granted and false otherwise"}
]
}
]
}
]
}
```Vote 응답 처리
- 먼저 Voter가 더 큰 epoch의 선거를 이미 관찰했을 수 있기 때문에 Voter가 여전히 Candidate인지 확인해야 합니다. 더 이상 "Candidate" 상태가 아니면 응답을 무시하십시오.
- 그렇지 않으면 이 epoch에 대해 다수의 투표가 누적되었는지 확인합니다. 장애 조치 시 투표 요청을 다시 보낼 수 있고 Voter는 새로운 epoch Candidate가 없는 한 해당 요청을 다시 승인하기 때문에 이 정보를 유지할 필요가 없습니다. – 그렇다면 새 Epoch의 Leader로 자신을 나타내는 쿼럼 상태 파일을 업데이트하여 Leader 상태로 전환할 수 있습니다. 그렇지 않으면 이 투표를 메모리에 기록하십시오.
- Candidate가 과반수 득표를 얻은 경우에는 LastEpoch 및 LastEpochOffset이 업데이트되도록 로그에 현재 할당 상태를 기록한 다음 BeginQuorumEpoch 요청 전송을 시작할 수 있습니다.
새 Epoch로 더미 항목을 작성하는 것은 정확성을 위해 필요한 것이 아니라 클라이언트 요청 대기 시간을 줄이기 위한 최적화로 필요합니다. 기본적으로 Leader 선출 후 하이 워터마크의 더 빠른 발전을 허용합니다(이에 대한 필요성은 Fetch API 처리에서 아래에서 자세히 설명합니다). 더미 레코드는 Type=3인 제어 레코드가 됩니다. 아래에서 스키마를 정의합니다.
{
"type": "data",
"name": "LeaderChangeMessage",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{"name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the newly elected leader"},
{"name": "VotedIds", "type": "[]int32", "versions": "0+",
"about": "The IDs of the voters who voted for the current leader"},
]
}또한 로그 추가가 비동기식으로 유지되는 다른 Kafka 주제 파티션 데이터와 달리 이 특수 쿼럼 주제의 경우 모든 로그 추가는 반환하기 전에 FS에 동기화되어야 합니다.
정체된 선거에 대한 참고 사항: 선거가 실패할 수 있습니다. 예를 들어 각 Voter가 동시에 Candidate가 되어 스스로 투표하는 경우. 일반적으로 Voter가 quorum.election.timeout.ms 이전에 과반수 득표에 실패하면 투표가 실패한 것으로 간주되어 재시도하기 전에 quorum.election.backoff.max.ms에 따라 물러나 백오프됩니다. . 일부 상황에서 Candidate는 투표가 실패했을 때 즉시 감지할 수 있습니다. 예를 들어 Voter가 두 명뿐이고 Candidate가 다른 Voter로부터 투표를 얻지 못한 경우(즉, VoteGranted가 VoteResponse에서 false로 반환됨) 선거 시간 초과를 기다릴 필요가 없습니다. 이 경우 Candidate는 즉시 사퇴하고 물러날 수 있습니다.
BeginQuorumEpoch
전통적인 Raft에서 Leader는 기간을 주장하기 위해 빈 Append 요청을 쿼럼의 다른 노드에 보냅니다. 풀 기반 프로토콜로서 선거 결과를 신속하게 검색하려면 동일한 작업을 수행하는 별도의 BeginQuorumEpoch API가 필요합니다. 이 프로토콜에서 Leader가 충분한 표를 받으면 쿼럼의 모든 Voter에게 BeginQuorumEpoch 요청을 보냅니다.
Voter만 BeginQuorumEpoch 요청을 받습니다. Observer는 Fetch API를 통해 새 Leader를 발견합니다. Leader가 아닌 사람이 가져오기 요청을 받으면 더 이상 Leader가 아님을 나타내는 오류 코드를 응답에 반환하고 현재 알려진 Leader ID/epoch도 인코딩합니다. 그런 다음 Observer는 새 Leader에서 가져오기를 시작할 수 있습니다. 초기화 시 Observer는 새 Leader를 찾을 때까지 임의의 Voter에게 가져오기 요청을 무작위로 보냅니다.
BeginQuorumEpoch 요청 스키마
```jsx
{
"apiKey": N,
"type": "request",
"name": "BeginQuorumEpochRequest",
"validVersions": "0",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+", "nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the newly elected leader"},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the newly elected leader"}
]}
]}
]
}
```BeginQuorumEpoch 요청 처리
Voter는 Leader Epoch가 이전 정보와 충돌하지 않는 한 현재 알려진 Epoch보다 크거나 같으면 BeginQuorumEpoch를 수락합니다. 예를 들어, Epoch 5의 leaderId가 A인 것으로 알려진 경우 Voter는 동일한 Epoch의 별도 Voter B의 BeginQuorumEpoch 요청을 거부합니다. epoch가 알려진 epoch보다 작으면 요청이 거부됩니다.
클러스터 부트스트래핑 섹션에 설명된 대로 브로커는 캐시된 값과 일치하지 않는 clusterId가 있는 BeginQuorumEpoch를 수신하는 경우 실패합니다.
브로커가 BeginQuorumEpoch 요청을 수락하는 즉시 Follower 상태로 전환되고 Fetch 요청을 새 Leader에게 보내기 시작합니다.
BeginQuorumEpoch 응답 스키마
```jsx
{
"apiKey": N,
"type": "response",
"name": "BeginQuorumEpochResponse",
"validVersions": "0",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"}
]}
]}
]
}
```BeginQuorumEpoch 응답 처리
응답에 오류가 없으면 Leader는 Follower가 선거를 지지한 것으로 메모리에 기록합니다. Leader는 지지를 받을 때까지 각각의 알려진 Voter에게 BeginQuorumEpoch를 계속 보냅니다. 이렇게 하면 네트워크에서 분할된 Voter가 분할이 복원된 후 신속하게 Leader를 검색할 수 있습니다. 기존 Voter의 지지는 BeginQuorumEpoch 요청이 수신되지 않은 경우에도 새로운 Leader의 Epoch로 수신된 Fetch 요청을 통해 유추될 수 있습니다.
오류 코드가 Voter의 알려진 Leader Epoch가 더 크다는 것을 나타내면(즉, 오류가 FENCED_LEADER_EPOCH인 경우) Voter는 쿼럼 상태를 업데이트하고 해당 Leader의 Follower가 되어 가져오기 요청을 보내기 시작합니다.
EndQuorumEpoch
EndQuorumEpoch API는 Leader가 선택 제한 시간을 기다리지 않고 즉시 선택을 수행할 수 있도록 정상적으로 물러나는 데 사용됩니다. 이에 대한 기본 사용 사례는 정상적인 종료를 활성화하는 것입니다. 폐쇄 Voter가 현재 활동 중인 Leader이거나 진행 중인 선거가 있는 경우 Candidate인 경우 이 요청이 전송됩니다. 또한 AlterPartitionReassignments 요청에 따라 쿼럼에서 Leader를 제거해야 하는 경우에도 사용됩니다.
EndQuorumEpochRequest는 쿼럼의 모든 Voter에게 전송됩니다. 각 요청 내에서 Leader는 내림차순으로 각 Voter의 현재 복제 오프셋별로 정렬된 선호하는 계승자 목록을 정의합니다. 선호하는 후임자의 우선 순위에 따라 각 Voter는 가장 최신 Voter가 선출될 가능성이 더 높도록 해당 지연 선거 시간을 선택합니다. 노드의 우선 순위가 가장 높으면 즉시 Candidate가 되며 선출 제한 시간을 기다리지 않습니다. 우선 순위가 N > 0인 후속 작업의 경우 다음 선택 시간 제한은 다음과 같이 계산됩니다.
💡 MIN(retryBackOffMaxMs, retryBackoffMs * 2^(N - 1))EndQuorumEpoch 요청 스키마
```jsx
{
"apiKey": N,
"type": "request",
"name": "EndQuorumEpochRequest",
"validVersions": "0",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+", "nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ReplicaId", "type": "int32", "versions": "0+",
"about": "The ID of the replica sending this request"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The current leader ID or -1 if there is a vote in progress"},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The current epoch"},
{ "name": "PreferredSuccessors", "type": "[]int32", "versions": "0+",
"about": "A sorted list of preferred successors to start the election"}
]}
]}
]
}
```EndQuorumEpoch 요청 처리
EndQuorumEpoch를 수신하면 Voter는 요청의 Epoch가 마지막으로 알려진 Epoch보다 크거나 같은지 확인합니다. epoch가 마지막으로 알려진 epoch보다 작거나 이 epoch에 대한 Leader ID를 알 수 없는 경우 요청이 거부됩니다. 그런 다음 Voter는 주어진 PreferredSuccessors안에 있는지 여부를 확인합니다. 그렇지 않은 경우 INCONSISTENT_VOTER_SET을 반환합니다. 두 유효성 검사가 모두 통과되면 Voter는 목록에서 첫 번째인 경우 즉시 Candidate 상태로 전환할 수 있습니다. 그렇지 않으면 이전 섹션에서 설명한 대로 선택을 시작하기 위해 계산된 백오프 타임아웃을 기다립니다. Voter 수집을 시작하기 전에 Voter는 정족수 상태 파일을 업데이트해야 합니다.
EndQuorumEpoch 응답 스키마
```jsx
{
"apiKey": N,
"type": "response",
"name": "EndQuorumEpochResponse",
"validVersions": "0",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"}
]}
]}
]
}
```EndQuorumEpoch 응답 처리
오류 코드가 없으면 아무것도 하지 마십시오. 그렇지 않으면 오류 코드가 이미 더 높은 Epoch Leader가 있음을 나타내는 경우("이봐 당신은 이제 구식 뉴스이므로 물러나든 뭐든 상관없습니다"), Follower 상태로 전환하는 동안 쿼럼 상태 파일을 업데이트합니다 . Leader는 이를 최선의 정상 종료로 간주합니다. Voter가 EndQuorumEpoch를 보낼 수 없는 경우 Leader는 재시도 없이 종료됩니다. 최악의 경우 EndQuorumEpoch 요청이 수신되지 않으면 선택 시간 초과로 인해 결국 새 선택이 트리거됩니다.
동일한 FENCED_LEADER_EPCOH 오류 코드를 재사용하여 더 큰 Leader Epoch가 있음을 나타냅니다. 발신자의 종료 여부에 따라 응답 오류를 무시하거나 응답에 표시된 Leader의 Follower가 됩니다.
Fetch
가져오기 요청은 로그 변경 사항을 복제하기 위해 Voter와 Observer 모두 현재 Leader에게 보냅니다. Voter의 경우 이는 Leader의 활성 상태를 확인하는 역할도 합니다.
로그 조정: Raft 프로토콜은 오프셋이 가장 큰 복제본이 항상 선택된다는 것을 보장하지 않습니다. 즉, Leader 선출 후 Follower는 로그에서 커밋되지 않은 일부 항목을 잘라야 할 수 있습니다. Kafka 로그 복제 프로토콜은 Leader 선택 후 유사한 문제가 있으며 Leader가 변경될 때마다 입력되는 별도의 절단 상태로 해결됩니다. 자르기 상태에서 Follower는 OffsetsForLeaderEpoch API를 사용하여 로그와 Leader 사이의 분기 오프셋을 찾습니다. 발견되면 로그가 잘리고 복제가 계속됩니다.
Kafka 접근 방식을 따르는 대신 이 프로토콜은 Raft 복제와 더 유사한 Fetch API에서 로그 조정을 피기백합니다. Voter 또는 Leader가 가져오기 요청을 보낼 때 가져올 오프셋을 포함하는 것 외에도 로컬 로그에 있는 마지막 오프셋의 Epoch를 나타냅니다(이를 “Fetch Epoch"라고 함). Leader는 항상 fetch offset 및 fetch Epoch가 자체 로그와 일치하는지 확인합니다. 일치하지 않는 경우 가져오기 응답은 가장 큰 Epoch와 요청된 Epoch 이전의 끝 오프셋을 나타냅니다. Leader 변경 사항을 감지하고 Fetch 응답을 사용하여 로그를 자르는 것은 Follower의 책임입니다.
이 접근 방식의 장점은 Follower 상태 머신을 단순화한다는 것입니다. 기본적으로 페치 오프셋을 사용하여 현재 예상되는 Leader에게 페치를 보내면 됩니다. 응답은 가져올 새 Leader 또는 새 fetch offset 을 나타낼 수 있습니다. 또한 Leader가 Epoch 변경을 감지하기 위해 팔로어에 의존하는 대신 모든 요청에서 fetch offset 의 유효성을 검사할 수 있기 때문에 더 안전합니다.
기존 Fetch API를 사용하고 있기 때문에 일반 복제 프로토콜을 비슷한 방식으로 변경하는 것이 합리적이라고 생각합니다. 후속 KIP 기회로 남겨두겠습니다.
커밋에 대한 추가 조건: Raft 프로토콜은 동일한 Leader가 현재 Epoch의 항목을 이미 성공적으로 복제한 경우에만 Leader가 이전 Epoch의 항목을 커밋하도록 요구합니다. Kafka의 ISR 복제 프로토콜은 유사한 문제를 겪고 있으며 Leader가 자체 Epoch로 메시지를 작성할 수 있을 때까지 하이 워터마크를 진행하지 않음으로써 문제를 처리합니다. Raft 논문에서 가져온 아래 다이어그램은 시나리오를 보여줍니다.
](https://s3-us-west-2.amazonaws.com/secure.notion-static.com/bdd2e2eb-a5ad-4aab-b4fc-9708c7d873fd/Untitled.png)
문제는 헌신과 Leader 선출을 위한 조건에 관한 것이다. 이 다이어그램에서 S1은 초기 Leader이고 "2"를 쓰지만 모든 복제본에 커밋하지 못합니다. 경영진은 "3"이라고 적힌 S5로 이동하지만 역시 커밋하지 않습니다. 그런 다음 리더십은 "2" 커밋을 시도하는 S1으로 돌아갑니다. "2"가 대부분의 노드에 성공적으로 기록되더라도 S5가 여전히 Leader가 될 수 있는 위험이 있으며, 이로 인해 대부분의 노드에 존재하더라도 "2"가 잘릴 수 있습니다.
여기에서 제안하는 프로토콜에서 우리는 선거 후 새 Leader가 해당 Epoch와 함께 항목을 작성할 때까지 High watermark를 진행하지 않음으로써 이 문제를 해결합니다. 따라서 대다수의 노드가 "2"를 썼음에도 불구하고 "3"을 쓴 S5에 대한 선거를 허용할 것입니다. 이것은 "2"가 커밋된 것으로 간주되지 않았기 때문에 허용됩니다. 따라서 High watermark가 이를 초과할 때까지 추가된 항목에 대한 클라이언트의 요청에 응답하지 않는 한 이 추가 조건이 충족됩니다.
일반 파티션 복제 프로토콜에도 비슷한 문제가 있습니다. Leader가 선출되면 ISR의 복제본이 새 Epoch 시작 시 오프셋까지 가져올 때까지 이전 최고 워터마크를 알 수 없습니다. 이 경우 Follower가 더 이상 활성 상태가 아닌 경우 Leader는 항상 ISR을 축소하여 하이 워터마크가 고착되지 않도록 할 수 있습니다. Raft 프로토콜에는 Leader를 선택하는 ISR이 없습니다. 우리는 Leader를 선출하기 위해 로그에서 가장 높은 Epoch/offset에 의존합니다. Leader가 된 후 하이 워터마크를 진행하려면 커밋한 모든 데이터를 복제하지 않는 한 Leader가 될 수 있는 다른 복제본이 없다는 것을 알아야 합니다. 이것은 Leader가 자신이 작성한 항목을 커밋할 수 있는 즉시 보장됩니다. 이전 항목보다 더 큰 Epoch가 보장되기 때문입니다. 그러나 클라이언트가 레코드를 즉시 보내지 않을 수 있고 하이 워터마크가 로그 끝 오프셋보다 낮은 오프셋에 남아 있을 수 있는 위험이 있습니다. 이것이 투표 처리 섹션에서 언급한 "더미" Leader 변경 메시지의 목적입니다. Leader가 된 후 즉시 이 제어 레코드를 추가합니다. 즉, 하이 워터마크가 안정적으로 끝 오프셋을 따라잡을 수 있습니다.
현재 리더 검색: 이 제안은 현재 Leader를 나타내기 위해 요청 수신자를 위한 별도의 필드를 포함하도록 Fetch 응답을 확장합니다. 그렇지 않으면 복제본에 추가 왕복이 필요하므로 현재 Leader를 찾기 위한 대기 시간을 개선하기 위한 것입니다. 브로커가 다시 시작되면 Fetch 프로토콜을 사용하여 현재 Leader를 찾습니다.
소비자가 NOT_LEADER_FOR_PARTITION 오류를 받은 후 현재 Leader를 찾기 위해 메타데이터 API를 사용해야 하므로 동일한 메커니즘을 사용하는 것이 일반 파티션에도 도움이 될 것이라고 생각합니다. 그러나 이것은 이 제안의 범위를 벗어납니다.
Fetch 요청 스키마
```jsx
{
"apiKey": 1,
"type": "request",
"name": "FetchRequest",
"validVersions": "0-12",
"flexibleVersions": "12+",
"fields": [
// ---------- Start new field ----------
{ "name": "ClusterId", "type": "string", "versions" "12+", "nullableVersions": "12+", "default": "null", "taggedVersions": "12+", "tag": 0,
"about": "The clusterId if known. This is used to validate metadata fetches prior to broker registration." },
// ---------- End new field ----------
{ "name": "ReplicaId", "type": "int32", "versions": "0+",
"about": "The broker ID of the follower, of -1 if this request is from a consumer." },
{ "name": "MaxWaitTimeMs", "type": "int32", "versions": "0+",
"about": "The maximum time in milliseconds to wait for the response." },
{ "name": "MinBytes", "type": "int32", "versions": "0+",
"about": "The minimum bytes to accumulate in the response." },
{ "name": "MaxBytes", "type": "int32", "versions": "3+", "default": "0x7fffffff", "ignorable": true,
"about": "The maximum bytes to fetch. See KIP-74 for cases where this limit may not be honored." },
{ "name": "IsolationLevel", "type": "int8", "versions": "4+", "default": "0", "ignorable": false,
"about": "This setting controls the visibility of transactional records. Using READ_UNCOMMITTED (isolation_level = 0) makes all records visible. With READ_COMMITTED (isolation_level = 1), non-transactional and COMMITTED transactional records are visible. To be more concrete, READ_COMMITTED returns all data from offsets smaller than the current LSO (last stable offset), and enables the inclusion of the list of aborted transactions in the result, which allows consumers to discard ABORTED transactional records" },
{ "name": "SessionId", "type": "int32", "versions": "7+", "default": "0", "ignorable": false,
"about": "The fetch session ID." },
{ "name": "SessionEpoch", "type": "int32", "versions": "7+", "default": "-1", "ignorable": false,
"about": "The fetch session epoch, which is used for ordering requests in a session" },
{ "name": "Topics", "type": "[]FetchableTopic", "versions": "0+",
"about": "The topics to fetch.", "fields": [
{ "name": "Name", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The name of the topic to fetch." },
{ "name": "FetchPartitions", "type": "[]FetchPartition", "versions": "0+",
"about": "The partitions to fetch.", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "CurrentLeaderEpoch", "type": "int32", "versions": "9+", "default": "-1", "ignorable": true,
"about": "The current leader epoch of the partition." },
{ "name": "FetchOffset", "type": "int64", "versions": "0+",
"about": "The message offset." },
// ---------- Start new field ----------
{ "name": "LastFetchedEpoch", "type": "int32", "versions": "12+", "default": "-1", "taggedVersions": "12+", "tag": 0,
"about": "The epoch of the last replicated record"},
// ---------- End new field ----------
{ "name": "LogStartOffset", "type": "int64", "versions": "5+", "default": "-1", "ignorable": false,
"about": "The earliest available offset of the follower replica. The field is only used when the request is sent by the follower."},
{ "name": "MaxBytes", "type": "int32", "versions": "0+",
"about": "The maximum bytes to fetch from this partition. See KIP-74 for cases where this limit may not be honored." }
]}
]},
{ "name": "Forgotten", "type": "[]ForgottenTopic", "versions": "7+", "ignorable": false,
"about": "In an incremental fetch request, the partitions to remove.", "fields": [
{ "name": "Name", "type": "string", "versions": "7+", "entityType": "topicName",
"about": "The partition name." },
{ "name": "ForgottenPartitionIndexes", "type": "[]int32", "versions": "7+",
"about": "The partitions indexes to forget." }
]},
{ "name": "RackId", "type": "string", "versions": "11+", "default": "", "ignorable": true,
"about": "Rack ID of the consumer making this request"}
]
}
```Fetch 요청 처리
Leader가 FetchRequest를 수신하면 다음을 확인해야 합니다.
- null이 아닌 경우 clusterId가 meta.properties의 캐시된 값과 일치하는지 확인합니다.
- 먼저 요청의 Leader Epoch가 로컬로 캐시된 값과 동일한지 확인합니다. 그렇지 않은 경우 FENCED_LEADER_EPOCH 또는 UNKNOWN_LEADER_EPOCH 오류와 함께 이 요청을 거부합니다.
- Leader Epoch가 더 작으면 결국 이 리더의 BeginQuorumEpoch가 Voter에게 도달하고 해당 Voter가 Epoch를 업데이트합니다.
- Leader Epoch가 더 크면 결국 수신기는 어쨌든 새 Epoch에 대해 알게 됩니다. 실제로 이 경우는 일반적인 파티션 복제 프로토콜과 달리 리더가 항상 자신이 선출되었음을 가장 먼저 발견하기 때문에 발생하지 않아야 합니다.
- LastFetchedEpoch가 Leader의 로그와 일치하는지 확인하십시오. Leader는 LastFetchedEpoch가 FetchOffset 이전의 오프셋 Epoch라고 가정합니다. FetchOffset은 Epoch가 LastFetchedEpoch인 오프셋 범위에 있거나 로그에서 다음 Epoch의 시작 오프셋일 것으로 예상됩니다. 그렇지 않은 경우 빈 응답(응답에 포함된 레코드 없음)을 반환하고 DivergingEpoch를 페처의 LastFetchedEpoch보다 작은 가장 큰 epoch로 설정합니다. Fetch 왕복 횟수를 줄이면서 시작 발산 지점에 도달하기 위해 팔로어가 가능한 한 많이 자를 수 있도록 자르기에 대한 최적화입니다. 예를 들어, 페처의 마지막 Epoch가 페칭 오프셋 이전 오프셋의 Epoch와 일치하지 않는 X인 경우 Follower에서 Epoch X가 있는 모든 레코드가 분기되어 잘릴 수 있음을 의미합니다.
- 요청이 옵저버가 아닌 Voter의 것인 경우 Leader는 최고 수위를 높일 수 있습니다. 위에서 설명한 것처럼 현재 Leader가 현재 epoch까지 쿼럼의 대다수에 대한 항목을 하나 이상 복제한 경우에만 하이 워터마크를 진행합니다. 그렇지 않으면 High watermark는 다수의 Voter에게 복제된 최대 오프셋으로 설정됩니다.
2단계의 확인은 현재 Follower가 OffsetsForLeaderEpoch API를 통해 Kafka에서 사용하는 논리와 유사합니다. 이 검사를 효율적으로 수행하기 위해 Kafka는 디스크에 leader-epoch-checkpoint 파일을 유지하며 그 내용은 메모리에 캐시됩니다. 모든 Epoch 변경이 관찰된 후 Epoch와 해당 시작 오프셋을 이 파일에 쓰고 캐시를 업데이트합니다. 이를 통해 Leader의 Log가 Follower에서 분기되었는지 여부와 분기점이 어디인지 효율적으로 확인할 수 있습니다. 최악의 경우 발산하는 첫 번째 오프셋을 찾기 위해 여러 라운드의 Fetch가 필요할 수 있습니다.
Fetch 응답 스키마
```jsx
{
"apiKey": 1,
"type": "response",
"name": "FetchResponse",
"validVersions": "0-12",
"flexibleVersions": "12+",
"fields": [
{ "name": "ThrottleTimeMs", "type": "int32", "versions": "1+", "ignorable": true,
"about": "The duration in milliseconds for which the request was throttled due to a quota violation, or zero if the request did not violate any quota." },
{ "name": "ErrorCode", "type": "int16", "versions": "7+", "ignorable": false,
"about": "The top level response error code." },
{ "name": "SessionId", "type": "int32", "versions": "7+", "default": "0", "ignorable": false,
"about": "The fetch session ID, or 0 if this is not part of a fetch session." },
{ "name": "Topics", "type": "[]FetchableTopicResponse", "versions": "0+",
"about": "The response topics.", "fields": [
{ "name": "Name", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]FetchablePartitionResponse", "versions": "0+",
"about": "The topic partitions.", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The error code, or 0 if there was no fetch error." },
{ "name": "HighWatermark", "type": "int64", "versions": "0+",
"about": "The current high water mark." },
{ "name": "LastStableOffset", "type": "int64", "versions": "4+", "default": "-1", "ignorable": true,
"about": "The last stable offset (or LSO) of the partition. This is the last offset such that the state of all transactional records prior to this offset have been decided (ABORTED or COMMITTED)" },
{ "name": "LogStartOffset", "type": "int64", "versions": "5+", "default": "-1", "ignorable": true,
"about": "The current log start offset." },
// ---------- Start new field ----------
{ "name": "DivergingEpoch", "type": "EpochEndOffset", "versions": "12+", "taggedVersions": "12+", "tag": 0,
"about": "In case divergence is detected based on the `LastFetchedEpoch` and `FetchOffset` in the request, this field indicates the largest epoch and its end offset such that subsequent records are known to diverge",
"fields": [
{ "name": "Epoch", "type": "int32", "versions": "12+", "default": "-1" },
{ "name": "EndOffset", "type": "int64", "versions": "12+", "default": "-1" }
]},
{ "name": "CurrentLeader", "type": "LeaderIdAndEpoch",
"versions": "12+", "taggedVersions": "12+", "tag": 1, fields": [
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"}
]},
// ---------- End new field ----------
{ "name": "Aborted", "type": "[]AbortedTransaction", "versions": "4+", "nullableVersions": "4+", "ignorable": false,
"about": "The aborted transactions.", "fields": [
{ "name": "ProducerId", "type": "int64", "versions": "4+", "entityType": "producerId",
"about": "The producer id associated with the aborted transaction." },
{ "name": "FirstOffset", "type": "int64", "versions": "4+",
"about": "The first offset in the aborted transaction." }
]},
{ "name": "PreferredReadReplica", "type": "int32", "versions": "11+", "ignorable": true,
"about": "The preferred read replica for the consumer to use on its next fetch request"},
{ "name": "Records", "type": "bytes", "versions": "0+", "nullableVersions": "0+",
"about": "The record data." }
]}
]}
]
}
```Fetch 응답 처리
응답을 처리할 때 Follower/Observer는 다음을 수행합니다.
- 응답에 FENCED_LEADER_EPOCH 오류 코드가 포함되어 있으면 응답에서 leaderId를 확인하십시오. 정의된 경우 쿼럼 상태 파일을 업데이트하고 해당 Leader의 "Follower"(의결권이 있거나 없을 수 있음)가 됩니다. 그렇지 않으면 나머지 Voter 중 한 명에 대해 무작위로 Fetch 요청을 다시 시도하십시오. 그 동안 새로운 Epoch/Leader도 업데이트하는 BeginQuorumEpoch 요청을 수신할 수 있습니다.
- 응답에 DivergingEpoch 필드가 설정된 경우 로그에서 DivergingEpoch.EndOffset보다 크거나 같은 모든 오프셋을 자르고 DivergingEpoch.EndOffset보다 큰 Epoch가 있는 모든 오프셋을 자릅니다.
Follower는 제어 레코드가 있는지 수신된 모든 레코드를 확인해야 합니다. 특히 Follower/Observer는 자신의 역할을 변경할 수 있는 Voter 할당 메시지를 확인해야 합니다.
Discussion: Pull v.s Push Model
원래 Raft 논문에서 푸시 모델은 Leader가 적극적으로 Follower에게 요청을 보내고 반환된 승인에서 쿼럼을 계산하여 항목이 커밋되었는지 결정하는 복제 상태에 사용됩니다.
우리 구현에서는 이 목적을 위해 풀 모델을 사용했습니다. 더 구체적으로:
- 일관성 검사: 푸시 모델에서는 복제본 측에서 수행되는 반면 풀 모델에서는 Leader에서 수행되어야 합니다. Voter/Observer는 현재 로그 끝 오프셋과 관련된 가져오기 요청을 보냅니다. Leader는 오프셋에 대한 항목을 확인하고 Leader가 항목 배치로 응답하는 Epoch와 일치하는 경우(아래 참조); 일치하지 않는 경우 브로커는 팔로어가 Leader의 이전 Epoch 끝 인덱스의 다음 항목으로 현재 Epoch를 모두 자르도록 응답합니다(예: 팔로어의 용어가 X인 경우 Y에서 용어 Y의 끝 오프셋의 다음 오프셋을 반환합니다. < X인 Leader에서 가장 큰 항입니다. 그리고 이 응답을 받으면 Voter/Observer는 해당 오프셋에 대한 로컬 로그를 잘라야 합니다.
- 커밋에 대한 추가 조건: 푸시 모델에서 Leader는 현재 Epoch가 아닌 항목을 커밋하지 않도록 해야 합니다. 풀 모델에서 Leader는 가져오기에서 보내는 배치를 확인하여 여전히 이를 준수해야 합니다 응답에는 현재 Epoch와 관련된 항목이 하나 이상 포함되어 있습니다.
원본 논문의 재귀적 추론을 기반으로 Leader/레플리카 로그는 로그 끝 인덱스/용어가 여전히 일치하는 동안 로그 중간에서 절대 분기되지 않는다는 결론을 내릴 수 있습니다.
이 구현을 원래 푸시 기반 접근 방식과 비교:
- 프로 측에서: 풀 모델을 사용하면 Leader가 nextIndex를 감소시키면서 요청 전송을 재시도하도록 할 필요가 없기 때문에 새로 추가된 구성원을 빈 로그로 부트스트랩하는 것이 더 자연스럽습니다. . 또한 Leader는 새 구성에서 더 이상 그룹의 일부가 아닌 이전 구성 구성원의 가져오기 요청을 거부할 수 있으며, 거부를 수신하면 복제본은 지금 종료해야 함을 압니다. 즉, "중단 서버" 문제를 자동으로 해결합니다.
- Con-side에서: 푸시 모델과 마찬가지로 좀비 Leader의 퇴장은 좀 더 번거롭습니다. Leader는 Follower 제한 시간 내에 하트비트 요청을 성공적으로 보낼 수 없을 때 물러날 수 있지만 풀 모델에서는 좀비 리더가 필요하지 않습니다. 그 통신 패턴과 한 가지 대안 접근 방식은 일정 시간 동안 항목을 커밋할 수 없는 경우 단계를 내려야 한다는 것입니다. 또한 풀 모델은 항목이 커밋되었는지 확인하기 위해 추가 대기 시간(최악의 경우 단일 가져오기 간격)을 도입할 수 있습니다. 이는 특히 주어진 시간에 여러 메타데이터 항목을 업데이트하려는 경우 문제가 됩니다. 이는 매우 일반적입니다. Kafka의 사용 사례에서 — 따라서 구현에서 배치 쓰기를 효율적으로 지원하는 것을 고려해야 합니다.
성능: 이 두 모델 사이에는 성능 관점에서 장단점이 있습니다. 레코드를 커밋하려면 대부분의 노드에 복제해야 합니다. 여기에는 Leader에서 Follower로 레코드 데이터를 전파하는 것과 Follower에서 다시 Leader로 해당 레코드의 성공적인 쓰기를 전파하는 것이 모두 포함됩니다. 푸시 모델은 파이프라인을 허용하기 때문에 대기 시간이 잠재적으로 유리합니다. Leader는 이전 레코드의 커밋을 기다리는 동안 Follower에게 새 레코드를 계속 보낼 수 있습니다. 여기 제안서에서는 Leader가 Fetch 요청에서 다음 오프셋을 가져오는 데 의존하기 때문에 파이프라인을 사용하지 않습니다. 그러나 이것은 근본적인 제한이 아닙니다. Leader가 마지막으로 전송된 오프셋을 추적하는 경우 대신 Fetch 요청이 파이프라인되어 마지막으로 확인된 오프셋을 나타내고 Leader가 보낼 다음 오프셋을 선택할 수 있도록 할 수 있습니다. 기본적으로 새 데이터가 도착할 때 Leader가 Follower에게 추가 요청을 계속 보내도록 하는 대신 Follower는 ack된 오프셋이 변경되는 한 가져오기 요청을 계속 보냅니다. Kafka 복제에 대한 우리의 경험에 따르면 이것이 필요하지 않을 것이므로 Kafka의 기존 로그 계층을 더 많이 재사용할 수 있는 현재 접근 방식의 단순성을 선호합니다. 그러나 성능 특성을 평가하고 필요에 따라 개선할 것입니다. 이 KIP에서 프로토콜의 초기 버전을 지정하고 있지만 프로덕션에 도달하기 전에 추가 개정이 있을 것이 거의 확실합니다.
DescribeQuorum
DescribeQuorum API는 관리 클라이언트에서 쿼럼 상태를 표시하는 데 사용됩니다. 이 API는 모든 Voter에 대한 지연 정보가 있는 유일한 노드인 Leader에게 전송되어야 합니다.
- Fetch 요청 스키마
{ "apiKey": N, "type": "request", "name": "DescribeQuorumRequest", "validVersions": "0", "flexibleVersions": "0+", "fields": [ { "name": "Topics", "type": "[]TopicData", "versions": "0+", "fields": [ { "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName", "about": "The topic name." }, { "name": "Partitions", "type": "[]PartitionData", "versions": "0+", "fields": [ { "name": "PartitionIndex", "type": "int32", "versions": "0+", "about": "The partition index." } ] }] } ] }
DescribeQuorum 요청 처리
이 요청은 항상 Leader 노드로 전송됩니다. 우리는 AdminClient가 현재 Leader를 찾기 위해 메타데이터 API를 사용할 것으로 기대합니다. 요청을 받으면 노드는 다음을 수행합니다.
- 먼저 노드가 Leader인지 확인하십시오. 그렇지 않은 경우 클라이언트가 메타데이터로 재시도할 수 있도록 오류를 반환합니다. 현재 Leader가 수신 노드에 알려진 경우 응답에 LeaderId 및 LeaderEpoch를 포함합니다.
- 복제 진행률에 대한 현재 할당 정보 및 캐시된 상태를 사용하여 응답을 작성합니다.
DescribeQuorum 응답 스키마
```jsx
{
"apiKey": N,
"type": "response",
"name": "DescribeQuorumResponse",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ "name": "HighWatermark", "type": "int64", "versions": "0+"},
{ "name": "CurrentVoters", "type": "[]ReplicaState", "versions": "0+" },
{ "name": "Observers", "type": "[]ReplicaState", "versions": "0+" }
]}
]}],
"commonStructs": [
{ "name": "ReplicaState", "versions": "0+", "fields": [
{ "name": "ReplicaId", "type": "int32", "versions": "0+"},
{ "name": "LogEndOffset", "type": "int64", "versions": "0+",
"about": "The last known log end offset of the follower or -1 if it is unknown"}
]}
]
}
```DescribeQuorum 응답 처리
응답을 처리할 때 관리 클라이언트는 다음을 수행합니다.
- 의도한 노드가 현재 Leader가 아니라는 응답이 표시되면 응답을 확인하여 LeaderId가 설정되었는지 확인합니다. 그렇다면 새 Leader로 요청을 다시 시도하십시오.
- 현재 Leader가 응답에 정의되지 않은 경우(선거가 진행 중인 경우일 수 있음) 백오프하고 메타데이터로 다시 시도하십시오.
- 그렇지 않으면 응답이 애플리케이션으로 반환되거나 요청이 결국 시간 초과될 수 있습니다.
Cluster Bootstrapping
클러스터가 처음으로 초기화되면 Voter는 정적 quorum.voters 구성을 통해 서로를 찾습니다. 고유한 clusterId 역할을 할 UUID를 생성하는 것은 첫 번째로 선출된 Leader(즉, 첫 번째 컨트롤러)의 작업입니다. 우리는 이것이 KIP-631에 의해 정의된 컨트롤러 상태 시스템 내에서 발생할 것으로 예상합니다. 이 ID는 메타데이터 로그에 메시지로 저장되며 이 제안에서 정의한 복제 프로토콜을 통해 클러스터의 모든 브로커에 전파됩니다. (구현 관점에서 Raft 라이브러리는 clusterId 초기화를 위한 후크를 제공합니다.)
메타데이터 로그를 통해 복제된 clusterId는 meta.properties에 저장됩니다. 오늘날 브로커가 다시 시작되면 meta.properties에서 캐시된 clusterId를 Zookeeper에서 동적으로 발견된 모든 ID와 비교합니다. ID가 일치하지 않으면 브로커가 종료됩니다. 이것의 목적은 브로커가 잘못된 클러스터에 연결되도록 하는 잘못된 구성의 영향을 제한하는 것입니다.
Zookeeper가 사라진 후에도 동일한 보호를 받고 싶지만 메타데이터 로그 자체의 복제가 파괴적일 수 있기 때문에 더 어렵습니다. 예를 들어 잘못된 클러스터에 연결된 브로커는 복제 과정에서 메타데이터 로그를 잘못 자를 수 있습니다. 불량 브로커는 유효하지 않은 Leader가 선출되도록 하여 커밋된 데이터가 손실될 위험이 있습니다.
이 문제를 해결하기 위해 여기서 취하는 접근 방식은 핵심 Raft 요청에 clusterId에 대한 필드를 포함하도록 하는 것입니다. 수신 시 유효성이 검사되며 값이 일치하지 않으면 INVALID_CLUSTER_ID 오류 코드가 반환됩니다. clusterId를 알 수 없는 경우(아마도 브로커가 처음으로 초기화되기 때문일 수 있음) "null"의 clusterId 값을 지정하고 대상 브로커는 유효성 검사를 건너뜁니다. 신규 브로커에 대해 이 면제를 허용해야 하기 때문에 이것은 100% 방탄 솔루션이 아닙니다. 예를 들어 비어 있는 상태의 브로커가 기존 Voter의 ID로 시작되어 정확성 위반이 발생할 수 있는 경우 여전히 가능합니다. 그러나 일반적인 잘못된 구성 사례의 큰 부류를 다루며 오늘날 Kafka가 보호할 수 있는 것보다 나쁘지 않습니다.
이 제안에는 한 가지 미묘함이 있습니다. 활성 Leader가 없는 경우 clusterId의 신뢰할 수 있는 소스로 신뢰할 수 있는 노드는 무엇입니까? INVALID_CLUSTER_ID 오류가 발생한 후 브로커를 맹목적으로 종료하면 단일 브로커가 클러스터에서 유효한 Voter 대다수를 죽일 수 있습니다. 이 문제를 해결하기 위해 브로커의 값이 선출된 Leader의 값과 충돌하는 경우에만 클러스터 ID 불일치 오류를 치명적 오류로 취급합니다. 따라서 Vote 요청의 INVALID_CLUSTER_ID 오류는 단순히 투표 거부로 처리되지만 Fetch의 동일한 오류는 치명적인 것으로 간주됩니다.
Voter가 시작될 때 Voter에 대한 정확한 초기화 프로세스는 다음과 같습니다.
quorum-state의 마지막 알려진 Epoch와 meta.properties의 clusterId(있는 경우)를 포함하여 현재 Voter에게 Fetch 요청을 보냅니다.
응답에 INVALID_CLUSTER_ID가 표시되면 브로커가 종료됩니다.
clusterId가 수신되지 않고 브로커에 null이 아닌 캐시된 clusterId가 있는 경우 선택 제한 시간이 만료될 때까지 무작위 Voter에 대해 가져오기 요청을 계속 재시도합니다.
선거 제한 시간이 만료되면 Candidate가 되어 현재 캐시된 clusterId(또는 없는 경우 null)를 포함하여 투표 요청을 보냅니다.
응답에 INVALID_CLUSTER_ID가 표시되면 일관성 없는 브로커가 소수일 수 있으므로 브로커가 실패하지 않습니다. 대신 선택이 완료될 때까지 계속 재시도합니다.
언제든지 브로커가 클러스터 ID가 일치하지 않는 선출된 Leader로부터 BeginQuorumEpoch 요청을 수신하면 브로커가 종료됩니다.
브로커가 Voter 중 한 명으로부터 투표 요청을 받고 clusterId가 null이 아니며 값이 캐시된 값과 일치하지 않으면 투표를 거부하고 INVALID_CLUSTER_ID를 반환합니다.
Observer에게는 훨씬 더 간단합니다. 1단계에서 동일한 유효성 검사를 수행하지만 Leader를 찾을 수 없는 경우 무기한 재시도를 계속합니다. Observer에게 clusterId가 없으면 null clusterId와 함께 Fetch 요청을 보냅니다. Leader가 선출되고 clusterId 메시지가 커밋되면 Observer는 meta.properties를 업데이트하고 향후 모든 가져오기 요청에 clusterId를 포함하기 시작합니다.
Tooling Support
쿼럼 상태를 설명하고 변경하기 위해 kafka-metadata-quorum.sh라는 새 유틸리티를 추가합니다. 평소와 같이 이 도구를 사용하려면 --bootstrap-server를 제공해야 합니다. 다음 옵션을 지원합니다.
Describing Current Status
- --describe와 함께 사용할 수 있는 두 가지 옵션이 있습니다.
- —describe status: 쿼럼 상태에 대한 간략한 요약이며 다른 하나는 복제 상태에 대한 자세한 정보를 제공합니다.
--describe replication: 복제 상태에 대한 자세한 정보를 제공합니다.
다음은 몇 가지 예입니다.
> bin/kafka-metadata-quorum.sh --describe
ClusterId: SomeClusterId
LeaderId: 0
LeaderEpoch: 15
HighWatermark: 234130
MaxFollowerLag: 34
MaxFollowerLagTimeMs: 15
CurrentVoters: [0, 1, 2]
> bin/kafka-metadata-quorum.sh --describe replication
ReplicaId LogEndOffset Lag LagTimeMs Status
0 234134 0 0 Leader
1 234130 4 10 Follower
2 234100 34 15 Follower
3 234124 10 12 Observer
4 234130 4 15 ObserverMetrics
다음은 이 새로운 프로토콜에 대해 제안된 메트릭 목록입니다.
| NAME | TAGS | TYPE | NOTE |
|---|---|---|---|
| current-leader | type=raft-manager | dynamic gauge | -1 means UNKNOWN |
| current-epoch | type=raft-manager | dynamic gauge | 0 means UNKNOWN |
| current-vote | type=raft-manager | dynamic gauge | -1 means not voted for anyone |
| log-end-offset | type=raft-manager | dynamic gauge | |
| log-end-epoch | type=raft-manager | dynamic gauge | |
| high-watermark | type=raft-manager | dynamic gauge | |
| current-state | type=raft-manager | dynamic enum | possible values: "leader", "follower", "candidate", "observer" |
| number-unknown-voter-connections | type=raft-manager | dynamic gauge | 연결 정보가 캐시되지 않은 미지의 voter는 쿼럼 크기보다 클 수 없습니다. |
| election-latency-max/avg | type=raft-manager | dynamic gauge | 각 voter에 대해 기간 합계/평균으로 측정, candidate가 될 때 시작하여 배우거나 새로운 leader가 될 때 종료 |
| commit-latency-max/avg | type=raft-manager | dynamic gauge | leader에서 창 합계/평균으로 측정, 레코드를 추가할 때 시작하고 high watermark에서 끝납니다. |
| fetch-records-rate | type=raft-manager | windowed rate | follower와observer에게만 적용됩니다. |
| append-records-rate | type=raft-manager | windowed rate | leader에게만 적용됩니다. |
| poll-idle-ratio-avg | type=raft-manager | windowed average |
Client Interactions
이 특정 쿼럼 구현은 Kafka 내부적으로만 사용되기 때문에 클라이언트를 위한 새로운 공용 프로토콜을 추가할 필요가 없습니다. 보다 구체적으로, 쿼럼의 Leader는 클러스터의 컨트롤러 역할을 하며 메타데이터(이전에 ZK에 저장됨)를 업데이트해야 하는 모든 클라이언트 요청은 쿼럼의 내부 로그에 새 레코드를 추가하는 것으로 해석됩니다.
Leader 마이그레이션과 같은 여러 메타데이터 항목을 업데이트해야 하는 일부 작업의 경우(예: 이전에는 여러 ZK 쓰기가 둘 이상의 ZK 경로를 업데이트함) 일괄 레코드 추가로 해석됩니다.
레코드 추가(단일 또는 일괄 처리)는 Leader가 High watermark가 추가된 레코드의 오프셋을 지나서 커밋되었음을 인정할 때까지 반환되지 않습니다. 일괄 추가의 경우 모든 레코드가 커밋된 경우에만 반환됩니다.
Leader가 레코드를 성공적으로 커밋하기 전에 요청이 시간 초과될 수 있으며 클라이언트 또는 브로커 자체가 재시도하여 쿼럼에 대한 중복 업데이트가 발생할 수 있습니다. Kafka의 사용법에서 모든 업데이트는 idempotent인 덮어쓰기입니다(구성 특성이 키-값 매핑이므로). 따라서 "정확히 한 번"을 달성하기 위해 일련 번호를 구현하거나 캐싱을 요청할 필요가 없습니다.
ZK 업데이트와 관련된 몇 가지 컨트롤러 작업이 있으며 이 KIP 범위에 속하지 않습니다.
브로커는 ISR 축소/확장을 위해 ZK를 직접 업데이트할 수 있습니다. 이는 Leader에서 컨트롤러로 전송된 AlterISR 요청으로 대체됩니다(KIP-497: Add inter-broker API to alter ISR). 그런 다음 컨트롤러는 각 주제 파티션이 하나의 항목을 나타내는 메타데이터 로그에 항목 배치를 추가하여 메타데이터를 업데이트합니다.
복제본 재할당에 대한 관리자 요청은 컨트롤러에 대한 AlterPartitionAssignments 요청으로 대체됩니다(KIP-455: 복제본 재할당을 위한 관리 API 생성). 컨트롤러는 각 주제 파티션이 하나의 항목을 나타내는 메타데이터 로그에 항목 배치를 추가하여 메타데이터를 업데이트합니다.
구성 변경 등에 대한 기존 관리자 요청은 메타데이터 로그에 대한 일괄 업데이트로 변환됩니다.
Log Compaction and Scanpshots
이 KIP에 설명된 메타데이터 로그는 무제한으로 커질 수 있습니다. 서론에서 논의한 것처럼 복제된 로그의 크기를 관리하는 접근 방식은 별도의 제안인 KIP-630: Kafka Raft Snapshot에 설명되어 있습니다. KIP-500의 각 브로커는 메타데이터 로그의 Observer가 되며 항목을 일종의 캐시로 구체화합니다. 새롭고 느린 브로커는 1) 스냅샷 가져오기 및 2) 스냅샷 후 복제된 로그 가져오기를 통해 Leader를 따라잡습니다. 이것은 현재 가능한 것보다 메타데이터의 일관성에 대한 더 강력한 보증을 제공할 것입니다.
Quorum performance
Raft 쿼럼의 목표는 Zookeeper 종속성을 대체하고 메타데이터 작업의 성능을 높이는 것입니다. 첫 번째 버전에서는 관리자 요청(AlterPartitionReassignments) 및 클라이언트 요청이 커밋되도록 허용되는 종단 간 대기 시간을 모니터링하는 데 필요한 메트릭을 구축할 것입니다. 로컬에서 소요되는 시간, 주로 새 레코드를 fsync하는 데 걸리는 시간과 변경 사항을 상태 시스템에 적용하는 데 걸리는 시간을 모니터링해야 합니다. 이는 실제로 사소한 작업이 아닐 수 있습니다. 게다가 원격에서 변경 사항을 전파하는 데 사용되는 시간인 I.E도 모니터링합니다. 하이 워터마크를 진행하기 위한 대기 시간. 또한 메타데이터 변경 부하가 높은 조건에서 Zookeeper와 Raft를 사용하여 3노드 브로커 클러스터의 효율성을 비교하기 위한 벤치마크도 구축됩니다. 우리는 동시에 기존 분산 합의 시스템 로드 프레임워크를 탐색할 것이지만 이는 KIP-595의 범위를 벗어날 수 있습니다.
Test Plan
Raft는 잘 연구된 합의 프로토콜이지만 이 제안에는 기존 프로토콜과 몇 가지 눈에 띄는 차이점이 있습니다. KIP-320의 Kafka 복제 프로토콜에 대해 수행한 것처럼 모델 검사를 사용하여 이 프로토콜의 복제 의미 체계를 검증합니다. (컨트롤러 상태 시스템의 유효성 검사는 KIP-631의 일부로 처리됩니다.)
구현을 테스트하는 기본 방법은 DES(Discrete Event Simulation)를 사용하는 것입니다. 프로토타입 구현에는 이미 기본 프레임워크가 포함되어 있습니다. DES를 사용하면 다양한 종류의 결함(예: 네트워크 파티션)을 포함하는 결정론적으로 생성된 많은 수의 무작위 시나리오를 테스트할 수 있습니다. 이를 통해 시뮬레이션의 각 단계 후에 확인되는 시스템 불변량을 프로그래밍 방식으로 정의할 수 있습니다. 이것은 이미 프로토타입 개발 전반에 걸쳐 버그를 식별하는 데 매우 유용했습니다.
그 외에는 일반적인 단위/통합/시스템 테스트 모음을 사용합니다.
Rejected Alternatives
- 기존 Raft 라이브러리 사용 로그 복제는 Kafka의 핵심이며 프로젝트에서 이를 소유해야 합니다. 타사 시스템 또는 라이브러리에 대한 의존도는 KIP-500의 핵심 동기 중 하나를 무효화합니다. Kafka의 특정 요구 사항에 따라 타사 구성 요소를 쉽게 발전시킬 수 있는 방법은 없습니다. 예를 들어 파티션 수준 복제에 이 프로토콜을 사용할 수 있지만 로그 계층을 계속 제어할 수 없으면 호환성이 훨씬 더 어려워집니다. 따라서 로그 계층과 RPC 프로토콜을 모두 제어해야 하는 경우 타사 라이브러리의 이점은 미미하고 비용은 향후 발전에 불필요한 제약이 됩니다. 또한 Raft 라이브러리는 일반적으로 자체 RPC 메커니즘, 직렬화 형식, 자체 모니터링, 로깅 등을 가져옵니다. 이 모든 것에는 사용자가 이해해야 하는 추가 구성이 필요합니다.
- Raft를 사용하여 파티션 복제 시작 이 문서의 여러 곳에서 언급했듯이 Raft를 개별 파티션에 사용 가능한 복제 메커니즘으로 만드는 것을 선호합니다. 그러면 메타데이터 쿼럼을 위한 별도의 프로토콜을 만들지 않고 바로 시작해야 하는지에 대한 질문이 생깁니다. 우리는 실제로 그렇게 하고 싶었지만 KIP-500 로드맵에 상당한 양의 직교 오버헤드가 추가되기 때문에 궁극적으로 하지 않기로 결정했습니다. 예를 들어 컨트롤러가 더 이상 선거에 대한 책임이 없기 때문에 메타데이터가 클라이언트에 전파되는 방식을 재고해야 합니다. 오늘날처럼 컨트롤러를 통해 모든 것을 계속 라우팅할 수 있지만 Raft 기반 파티션 복제의 주요 동기 중 하나가 약화됩니다. 또한 효율적으로 일괄 선택을 할 수 있는 Raft 프로토콜이 필요합니다. 이러한 문제는 다루기 쉽지만 이를 해결하는 것은 KIP-500의 범위를 벗어납니다. 즉, 우리는 최종 전환을 더 쉽게 하기 위해 어떤 측면에서 현재 복제 프로토콜을 미러링하도록 이 프로토콜을 만들고 싶었습니다. 이것이 아래에 언급된 풀 기반 프로토콜을 선택한 이유 중 하나입니다. 기존 로그 압축 시맨틱을 재사용하기로 결정한 이유이기도 합니다.
- Push vs Pull Raft는 푸시 프로토콜로 지정됩니다. 리더는 차이점을 조정하기 위해 모든 복제본의 상태를 추적해야 하며 변경 사항을 복제본에 적용할 책임이 있습니다. 반면 Kafka의 복제 프로토콜은 풀 기반입니다. 복제본은 필요한 오프셋을 알고 리더에서 가져옵니다. 조정은 복제본에 의해 이루어집니다. 이는 리더가 쿼럼의 복제본 상태만 추적하면 되므로 많은 수의 관찰자 복제본에 적합합니다. 이러한 이유로 그리고 로그 계층을 더 쉽게 재사용할 수 있기 때문에 이 프로토콜에서 풀 기반 모델을 고수하기로 했습니다. 이것은 또한 토픽 파티션에 대한 래프트 복제로의 전환을 단순화합니다.
- 원자 임의 쿼럼 변경 지원 Raft 문헌에서 제안된 또 다른 쿼럼 변경 접근 방식은 기존 쿼럼에 대한 임의 수의 노드 변경을 한 번에 지원하는 것이었습니다. 클러스터 내부에 두 세트의 노드 쿼럼을 유지해야 하므로 더 큰 범위의 코드 논리 변경이 필요합니다. 아이디어는 이전 쿼럼에서 새 쿼럼으로 마이그레이션하는 동안 이 기간 동안 추가된 각 메시지는 이전 구성과 새 구성 모두에 있는 모든 기존 노드와 두 쿼럼의 과반수 투표로 라우팅되어야 한다는 것입니다. 이 접근 방식의 이점은 쿼럼 변경이 그룹 전체에서 원자적이 된다는 것입니다. 그러나 프로덕션에서 대부분의 작업에는 둘 이상의 서버 마이그레이션이 필요하지 않기 때문에 일반 작업이 복잡해지고 실질적인 가치는 거의 제공되지 않습니다. 문헌은 명시적으로 이 접근 방식을 권장하지 않으며 예제 구현은 실제로 정확성에 대해 추론하기 어렵습니다.
- 옵저버 기반 프로모션 옵저버 기반 셀프 프로모션도 이미 풀 기반 모델을 하고 있기 때문에 장점이 있습니다. 리더에서 지연을 모니터링할 수 있으며 간격이 지속적으로 몇 라운드의 가져오기에 대한 특정 임계값 미만이면 이 관찰자가 그룹에 합류할 준비가 되었다고 부를 수 있습니다. 이 특별한 논리는 리더에서 보낸 BeginQuorumEpoch 요청을 처리할 때 관찰자 내부에 내장될 수 있습니다. 요청을 지연된 대기열에 넣고 관찰자가 자신을 동기화된 것으로 가정한 경우에만 성공에 대해 리더에게 회신합니다. 그러나 현재 우리는 쿼럼에 대한 정보를 흩어져 상호 작용 복잡성을 증가시키는 대신 중앙 집중화하려고 합니다. 그런 의미에서 이 방법은 바람직하지 않을 수 있습니다.
References
- Ongaro, Diego, and John Ousterhout. "In search of an understandable consensus algorithm." 2014 {USENIX} Annual Technical Conference ({USENIX}{ATC} 14). 2014.
- Ongaro, Diego. Consensus: Bridging theory and practice. Diss. Stanford University, 2014.
- Howard, Heidi, et al. "Raft refloated: Do we have consensus?." ACM SIGOPS Operating Systems Review 49.1 (2015): 12-21.
- R. Van Renesse. Paxos made moderately complex. http://www.cs.cornell.edu/courses/cs7412/2011sp/paxos.pdf, 2011.
