이 포스팅은 숙명여자대학교 김윤진 교수님의 컴퓨터 구조론 특강을 바탕으로 작성되었습니다.
이 포스팅에서 다루는 내용
- 캐시는 무엇이고 왜 필요한가?
- 캐시에는 어떤 데이터가 저장되는가?
- 캐시는 어떤 연산을 하는가?
내용 요약
캐시는 CPU와 메모리의 속도 차이를 완화하기 위한 중간 버퍼이다. 캐시에는 자주 접근하는 데이터를 메모리에서 복사해서 가져온다. CPU는 캐시에 먼저 접근해 해당 데이터가 있으면 빠른 캐시에서 가져올 수 있고, 느린 메모리에 접근하는 경우를 줄일 수 있기 때문에 속도 측면에서 CPU의 낭비를 줄인다. 캐시는 CPU 사이에 read, write 연산을 한다. 멀티 코어에서는 CPU가 메모리에 직접 접근하는 경우도 있다.
이거 왜 배워야됨?
캐시의 사용자는 캐시의 구성을 이해하고 있어야 한다. 최근 10nm 미만 Fab의 등장으로 캐시의 구성에 큰 변화가 있는데, 이를 이해하기 위해 앞에서 배운 VLSI, 캐시 크기, 구성, 배치를 알고 있어야 한다. 또한 캐시의 구성이 CPU의 전력 소모량을 결정하기 때문에, 성능 밸런스의 이해하려면 캐시를 공부해야 한다.
캐시는 무엇이고 왜 필요한가?
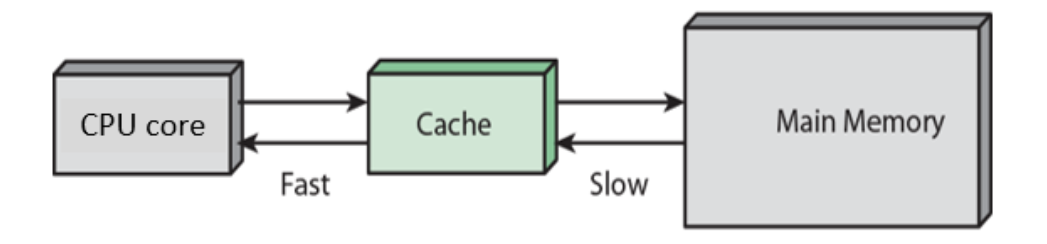
캐시란?
- 캐시는 CPU Core와 Main Memory 사이의 중간 버퍼이다.
- 캐시는 CPU Core와 같은 칩에 들어있을 수도 있고, 아닐 수도 있는데 요즘에는 대부분 같은 칩에 있다.
- Main Memory에는 DRAM이 사용되고, Cache에는 SRAM이 사용된다.
왜 CPU는 캐시가 필요한가?
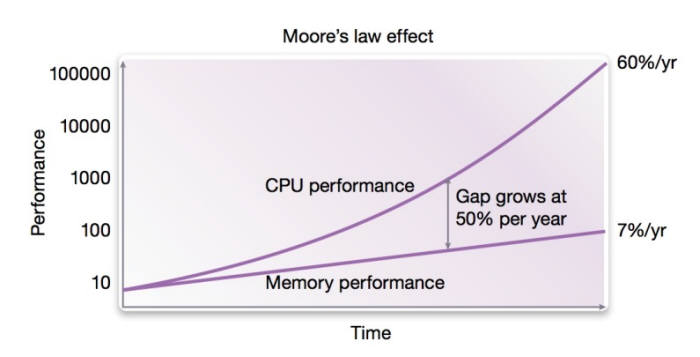
- CPU Core에 들어가는 Clock은 점점 빨라지는데 Memory의 발전은 더뎌서, CPU가 메모리에 접근할 때 Memory의 속도가 느려서 코어의 빠른 Clock이 낭비된다.
- 이 delay를 메꾸기 위해 중간 버퍼인 캐시를 사용한다.
- 캐시를 사용하여 CPU가 Main Memory에 접근할 때 대기하는 시간을 줄인다.
참고1 : 캐시에 어떤 메모리를 사용하는가?
- SRAM을 사용한다.
- 캐시에 사용되는 메모리는 Main Memory로 사용되는 DRAM보다 빨라야 한다.
- Speed : SRAM(1-10 Cycle) < DRAM(100-200 Cycle)
- Capa : SRAM(24KB-12MB) < DRAM(512MB-64GB)
참고2 : 왜 캐시를 사용하면 CPU의 대기 시간이 줄어드는가?
- 캐시 메모리에는 자주 사용되는 데이터의 복사본들이 저장된다. 그래서 CPU에서 자주 사용하는 데이터는 빠른 SRAM에서 가져온다.
- 느린 Main Memory에 접근해야 하는 경우는 덜 자주 사용되는 데이터를 가져올 때이다.
캐시에는 어떤 데이터가 저장되는가?
- 앞에서 가장 자주 사용되는 데이터를 메모리에서 복사해 캐시에 저장한다고 했다. 그렇다면 가장 자주 사용되는 데이터가 무엇인지 어떻게 알 수 있을까?
- 실제로 어떤 데이터가 자주 사용될지는 실행 전에는 알 수 없다. 그래서 우리는 인접성 원칙(The principle of locality)을 사용하여 캐시에 저장될 데이터를 정한다.
The principle of locality
Temporal Locality
- 프로그램이 어떤 메모리 주소에 접근하면, 나중에 똑같은 메모리 주소에 접근할 가능성이 높다.
- 프로그램은 순차적으로 실행되기 때문이다.
- 예를 들어, loop에서 일련의 명령어와 데이터 변수에 다시 접근할 확률은 매우 높다.
Spatial Locality
- 프로그램이 어떤 메모리 주소에 접근하면, 그 메모리와 인접한 다른 메모리에 접근할 확률이 높다.
- 예를 들어, 배열이나 객체(구조체) 등이 있다.
캐시에 데이터를 저장하는게 무슨 의미가 있나요?
- Spatial Locality와 Temporal Locality를 기반으로 캐시에 데이터를 저장한다. 처음 데이터를 읽어올 때는 메모리와 캐시에 둘다 데이터를 가져와야 하기 때문에 오버헤드가 발생한다. 하지만 나중에 접근하는 데이터가 캐시에 이미 있다면 느린 메모리까지 접근하지 않아도 되기 때문에 이후에 속도가 매우 빨라진다.
- Gambling : 캐시에 읽어온 데이터는 나중에 사용되지 않을 수도 있다. 다만 우리는 캐시에서 데이터를 읽어올 때의 속도 이점을 생각하여 데이터를 캐시에 옮겨놓는 것이다. 다행히도 인접성 원칙을 따르기 때문에 나중에 데이터가 다시 읽힐 확률은 아주 높다.
- 실제로 캐시 성능을 평가할 때 따지는 hit rate는 대부분 95%를 넘는다. 즉 대부분의 메모리 접근은 캐시에 의해 이루어지는 것을 알 수 있다.
캐시는 어떤 연산을 하는가?
- basic : hit, miss
- read : read hit, read miss
- write : write hit(write back, write through), write miss(write allocate, no write allocate)
- cache memory space allocation
Cache Hit
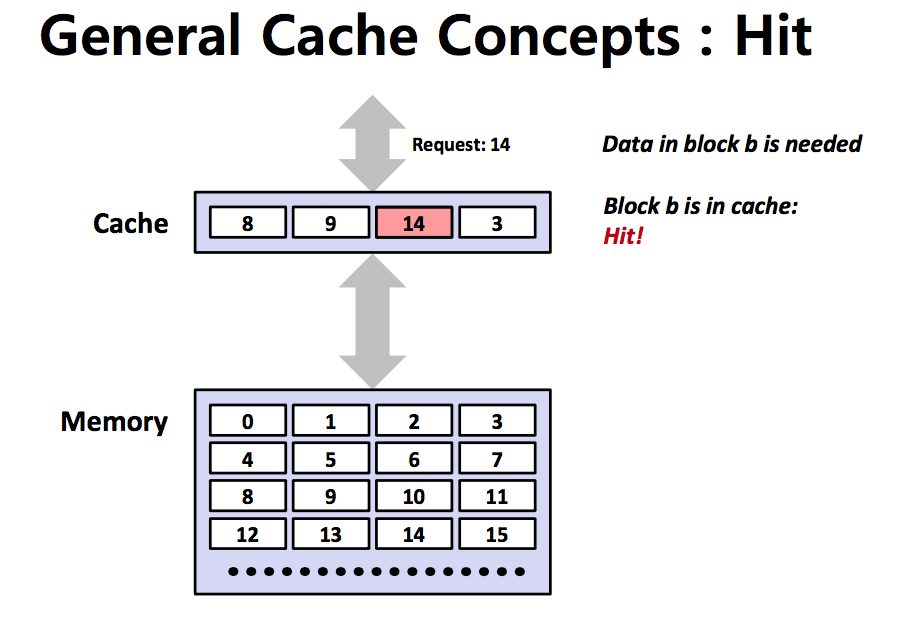
- CPU가 요청하는 데이터가 캐시 블록에서 발견되는 경우
- 데이터는 이미 Locality 원칙을 기반으로 캐시에 옮겨진 상태이다
Cache Miss
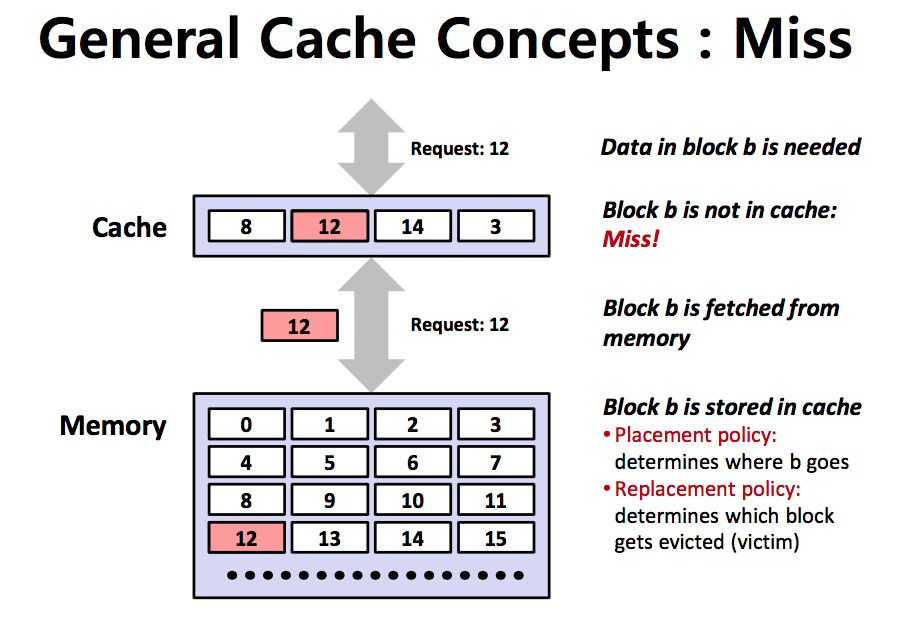
- CPU가 캐시에 데이터를 요청했는데 캐시가 그 데이터를 가지고 있지 않은 경우
- 이럴 때는 메모리에 접근해서 데이터를 복사해 캐시에 넣는 작업이 필요하다.
우리가 해야하는 작업
- CPU Core를 멈춘다
- 메인 메모리에 데이터를 요청한다
- 데이터를 복사해서 캐시에 넣는다
- 다시 캐시에 데이터를 요청한다(cache hit)
Cache의 성능 평가 척도
- Hit Rate (높을수록 좋아)
- 캐시 메모리에 의해 관리되는 메모리 접근 비율
- 대개 95%가 넘는다. 대부분의 데이터 접근은 캐시에 의해 이루어지기 때문에 데이터 접근할 때 속도가 매우 빨라진다.
- Miss Rate (낮을수록 좋아)
- 메인 메모리에 접근하는 메모리 접근 비율
- 1-Hit Rate
- Cache Miss가 발생한 경우
- 멀티 코어 상황에서 Data Consistency를 위해 메모리에 직접 접근하는 경우
이제 캐시의 읽기, 쓰기 연산에서의 Hit과 Miss도 알아보자.
Read Hit
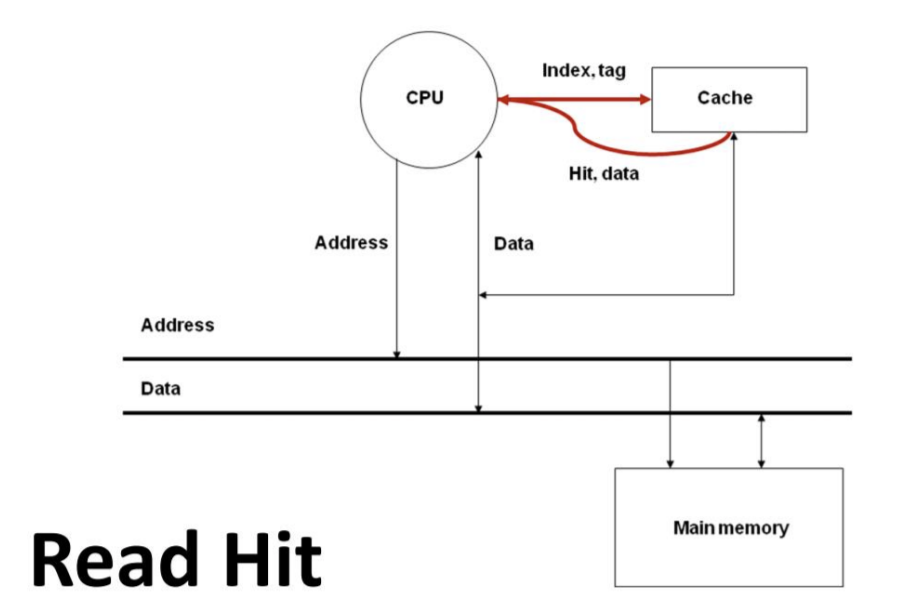
- CPU Core에서 Cache에 데이터 요청을 했고 그 데이터가 캐시에 존재한다. 그 데이터를 읽어 CPU Core에 전달한다.
- 이때 CPU Core와 캐시는 보통 같은 칩 안에 들어있다. 칩 밖보다 빠른 Clock이 들어가며 CPU Core와 캐시는 클락의 속도가 다를 수도 있다.
Read Miss
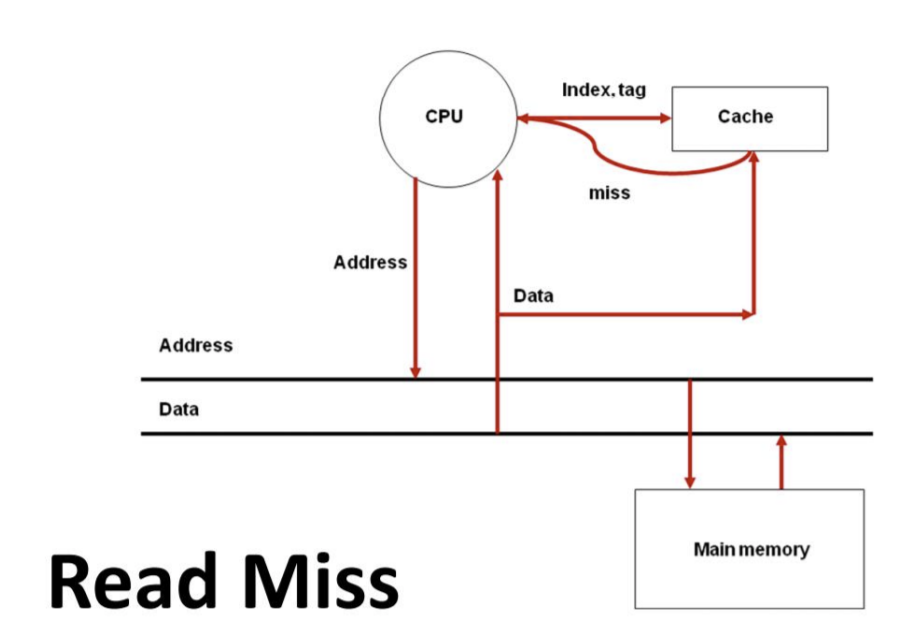
- CPU Core에서 Cache에 데이터 요청을 했고 그 데이터가 캐시에 존재하지 않는다.
- CPU Core를 중지한다.
- Core에서 Memory에 접근하여 데이터를 요청한다.
- Memory에서 데이터를 읽어 캐시에 데이터를 전달하고 저장한다.
- 캐시에서 Core에 데이터를 전달한다.
Write Hit - write back
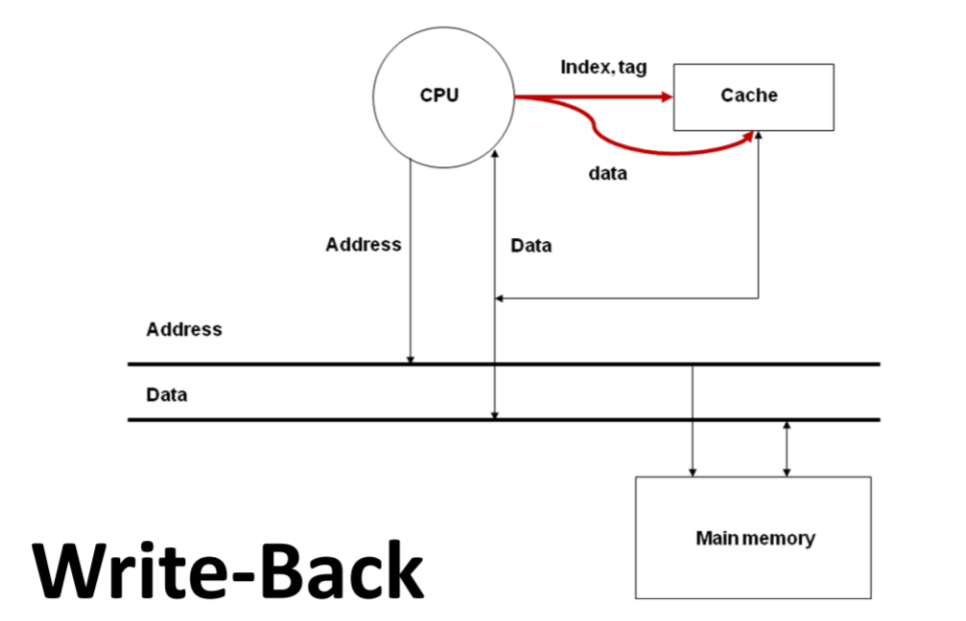
- CPU Core가 캐시의 데이터를 수정한다.
- 캐시 데이터는 메인 메모리 데이터의 복사본이기 때문에 수정된 데이터가 메인 메모리에도 반영되어야 한다.
- 이때 메모리에 반영하는 타이밍은 miss가 발생하여 캐시의 수정된 데이터가 새로운 데이터로 교체될 때이다. 느린 메모리에 접근하는 횟수를 한번으로 줄여 속도의 이점을 가져갈 수 있다.
- 다만 이 방식은 멀티 코어에서 Data Consistency 문제를 일으킨다. 코어 하나당 캐시가 하나씩 있으며, 메모리를 공유하는 상황에서, 어떤 캐시에서 데이터가 수정되어도 메모리에는 바로 반영이 되지 않는다. 이때 다른 코어의 캐시가 수정이 반영되지 않은 데이터로 연산을 하면 데이터 무결성이 깨진다. 그래서 캐시와 메모리 둘다 업데이트하는 Write Through 연산이 있다.
Write Hit - write through
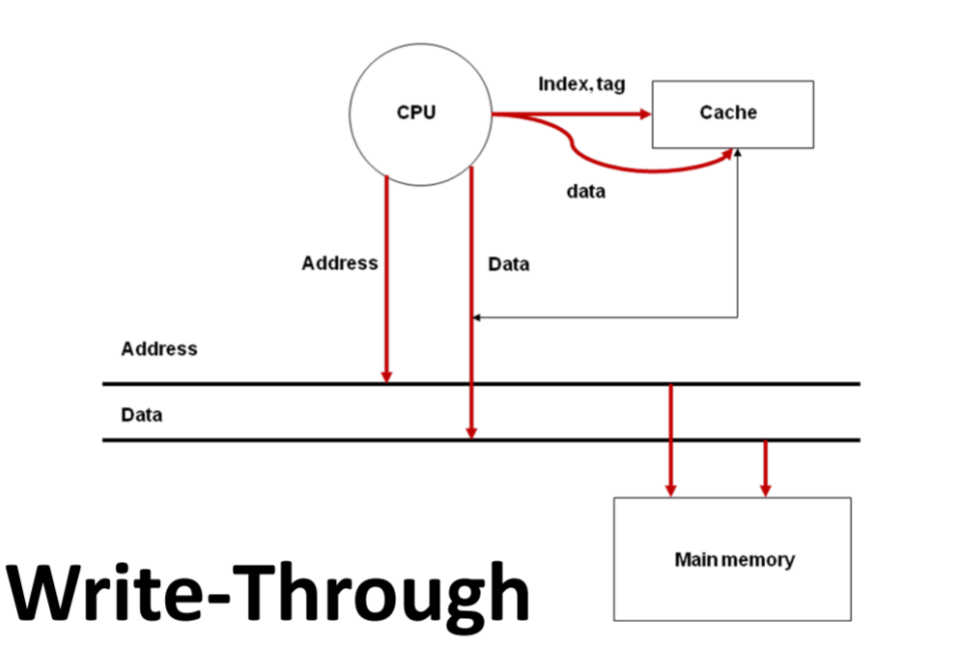
- 캐시와 메모리 둘다 수정된 데이터를 반영한다.
- 멀티 코어 환경에서 데이터 무결성 문제가 발생하지 않음!
- 물론 CPU가 캐시와 메모리에 둘다 요청하기 때문에 오버헤드는 발생한다.
Write Miss - Write allocate
- CPU Core가 Cache에 데이터를 쓰려고 요청했는데, 그 요청한 주소에 해당하는 데이터 공간이 캐시에 할당되지 않은 상태.
- 캐시에 새로운 공간을 할당하기 때문에, 다른 데이터가 out되는 것을 감수해야 한다. 만약 새로 읽어오는 데이터가 다시 사용될 것 같지 않다면 캐시에 쓰지 않고 메모리에만 write하는 방법도 있다.
- CPU Core를 멈춘다
- Cache가 메모리에서 데이터를 read
- 읽어온 데이터를 Cache에 write
Write Miss - No Write allocate
- CPU Core가 Cache에 데이터를 쓰려고 요청했는데, 그 요청한 주소에 해당하는 데이터 공간이 캐시에 할당되지 않은 상태
- 새로운 데이터가 다시 사용될 것 같지 않다면 캐시에 공간을 할당하지 않고 바로 메모리에 데이터를 쓴다.
- 캐시에 공간을 할당하면 다른 데이터가 나가야 하는데, 새로운 데이터를 저장할 가치가 없어보이면 메모리에만 바로 쓰는 것이 낫다.
Cache memory space allocation
Miss가 발생하는 경우, 메모리에서 데이터를 읽어와 캐시에 공간을 할당하는 경우를 말한다.
메모리에 접근해야 하므로 응답 시간은 길어진다.
- Write Allocate Miss
- Read Miss

딩가딩가 백엔드 개발자