이번에는 딥러닝과 인공 신경망 알고리즘을 이해하고 텐서플로를 사용해 인공 신경망 모델을 만들어 보겠다.
먼저 텐서플로를 사용해 데이터를 불러와보자.
from tensorflow import keras
(train_input, train_target), (test_input, test_target)=\
keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)(60000, 28, 28) (60000,)
훈련 데이터는 60,000개의 이미지로 이루어져 있고 각 이미지의 크기는 28x28크기인 것을 알 수 있다.
#테스트 세트의 크기 확인하기
print(test_input.shape,test_target.shape)(10000, 28, 28) (10000,)
테스트 세트는 10,000개의 이미지로 이루어진 것을 볼 수 있다. 그럼 이 이미지를 그림으로 출력해볼 수는 있을까?
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,10,figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
사진이 흐릿하게 보이는 이유는 크기를 28x28 크기로 제한했기 때문이다.
#처음 10개 샘플의 타깃값을 리스트로 만든 후 출력하기
print([train_target[i] for i in range(10)])[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
각 숫자들이 무슨 데이터를 나타내는지는 아직 모른다. 하지만 위의 과정을 통해 패션 MNIST 데이터셋을 저장했고, 어떤 종류의 이미지로 이루어졌는지를 알 수 있었다. 그럼 다음은 이 이미지들을 분류해보자.
로지스틱 회귀로 패션 아이템 분류하기
우리가 다루고자 하는 데이터들은 60,000개나 되기에 전체 데이터를 한번에 사용해 모델을 훈련하기보다는 샘플을 하나씩 꺼내서 모델을 훈련하는 방법이 더 효율적일것이다. 이 때 사용하는 방법이 '확률적 경사 하강법' 이다.
확률적 경사 하강법은 이전에 다룬 적이 있는데, 'SGDClassifier'를 사용했다.
그럼 본격적으로 분류를 시작해보자.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)reshape() 메서드의 두 번째 매개변수 28x28 이미지 크기에 맞도록 지정하면, 첫 번째 차원(샘플개수) 은 변하지 않고 원본 데이터의 두 번째, 세 번째 차원이 1차원으로 합쳐진다.
#변환된 train_scaled의 크기 확인하기
print(train_scaled.shape)(60000, 784)
784개의 픽셀로 이루어진 60,000개의 샘플이 만들어졌다. 그럼 이제 SGDClassifier 클래스와 cross_validate 함수를 사용해 이 데이터에서 교차검증으로 성능을 확인해보자.
import numpy as np
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
#SGDClassifier의 반복 횟수를 5번으로 지정해주기
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc,train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))0.8196000000000001
기대만큼 성능이 좋지 않은 것을 볼 수 있다. 그럼 반복 횟수를 늘려주면 성능이 좋아질까? 아쉽게도 반복 횟수를 늘려준다고 해서 성능이 눈에 띄게 좋아지지는 않는다.
인공 신경망(artificial neural network, ANN)
인공 신경망은 이미지 분류에 가장 잘 맞는다. 앞서 훈련한 모델의 성능은 만족스럽지 못했지만, 인공 신경망을 이용해서 성능을 높일 수 있다.
먼저 인공 신경망이란, 기계학습과 인지과학에서 생물학의 신경망(동물의 중추신경계중 특히 뇌)에서 영감을 얻은 알고리즘이다.
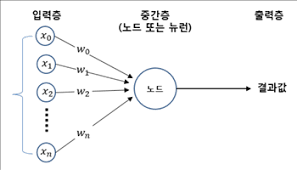
그럼 이제 인공 신경망으로 모델을 만들어 보자. 앞서 로지스틱 회귀에서 만든 훈련 데이터 train_scaled와 train_target을 사용할 것이다. 로지스틱 회귀에서는 교차 검증을 사용해 모델을 평가했지만, 인공 신경망은 교차 검증을 잘 사용하지 않고, 검증 세트를 별도로 덜어내서 사용한다.
인공 신경망에서 교차 검증을 잘 사용하지 않는 이유?
- 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이기 때문이다.
- 교차 검증을 수행하기에는 훈련 시간이 너무 오래걸리기 때문이다.
from sklearn.model_selection import train_test_split
#훈련 세트에서 20%를 검증 세트로 덜어오기
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
#훈련 세트의 크기
print(train_scaled.shape, train_target.shape)
#검증 세트의 크기
print(val_scaled.shape, val_target.shape)훈련 세트의 크기
(38400, 784) (38400,)
테스트 세트의 크기
(9600, 784) (9600,)
60,000개의 데이터 중 12,000개가 검증 세트로 분류되었다. 그럼 이제 훈련 세트로 모델을 만들고, 검증 세트를 통해 훈련한 모델을 평가해 보겠다.
먼저, 케라스의 레이어 패키지 안에는 다양한 층이 준비되어 있다. 가장 기본이 되는 층을 밀집층이라 한다. 이런 층을 양쪽의 뉴런이 모두 연결하고 있기에 완전 연결층 이라고도 부른다.
#신경망 층 만들기
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))여기서 10은 뉴런 개수가 10개라는 뜻이고, activation = 'softmax' 는 뉴런의 출력에 적용할 함수가 앞서 다루었던 '소프트맥스' 함수 라는 뜻이다. 소프트맥스 함수는 뉴런에서 출력되는 값을 확률로 바꾸기 위해서 사용한다.
그럼 이제 신경망 모델을 만들어 볼 단계이다. 사이킷런에 비해 케라스에서 모델을 만드는 방식은 조금 다르다. 케라스 모델은 훈련하기 전 설정 단계가 있다. 이런 설정을 model 객체의 compile() 메서드에서 수행한다. 여기서 가장 중요한 것은 손실함수의 종류를 지정해주어야 한다는 것이다. 그 다음에 훈련 과정에서 계산하고 싶은 측정값을 지정해 준다.
#신경망 모델 만들기
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')#신경망 모델 평가해보기
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1200/1200 [==============================] - 3s 2ms/step - loss: 0.6388 - accuracy: 0.7829
Epoch 2/5
1200/1200 [==============================] - 2s 2ms/step - loss: 0.4878 - accuracy: 0.8330
Epoch 3/5
1200/1200 [==============================] - 2s 2ms/step - loss: 0.4606 - accuracy: 0.8454
Epoch 4/5
1200/1200 [==============================] - 3s 2ms/step - loss: 0.4458 - accuracy: 0.8477
Epoch 5/5
1200/1200 [==============================] - 2s 2ms/step - loss: 0.4366 - accuracy: 0.8530
<keras.callbacks.History at 0x7d12edd24310>케라스는 에포크마다 걸린 시간과 손실, 정확도를 출력해주는 것을 볼 수 있다. 5번의 반복에 정확도가 85%를 넘은 것을 알 수 있다. 전에 보았던 모델보다 더 나은 결과인 것 같다. 그럼 이제 따로 분류해놓은 검증 세트에서 모델의 성능을 알아보자.
#evaluate 메서드로 모델 성능 평가하기
model.evaluate(val_scaled, val_target)300/300 [==============================] - 1s 2ms/step - loss: 0.4281 - accuracy: 0.8581
[0.428091824054718, 0.8581249713897705]evaluate 메서드도 fit 메서드와 비슷한 출력값을 보여준다. 여기까지 인공 신경망 알고리즘을 사용해 패션 아이템을 분류하는 모델을 훈련해봤다.
심층 신경망
심층 신경망이란?
심층 신경망은 입력층(input layer)과 출력층(output layer) 사이에 다중의 은닉층(hidden layer)을 포함하는 인공신경망(ANN)을 말한다. 이미지 트레이닝, 문자인식과 같은 분야에서 유용하게 사용된다.
그럼 은닉층은 무엇일까?
은닉층이란, 입력층과 출력층 사이에 있는 모든 층을 말한다.
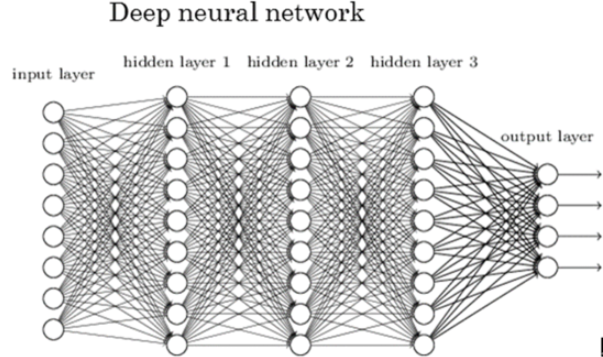
(출처: https://m.blog.naver.com/tjdudwo93/221072421443)
위 그림은 심층 신경망의 구조를 나타낸 그림이다. 앞서 보았던 인공 신경망과는 다르게 은닉층과 각 계층의 다수 뉴런이 연결되어있는 것을 볼 수 있다. 은닉 계층들은 입력 계층과 연결되어 있으며, 입력 변수의 값을 조합하고, 가중치를 부여해 새로운 실수를 만들어내야하며, 이 값은 다시 출력 계층으로 전달된다. 쉽게 말해, 은닉 계층에서 계산된 가장 추상화된 특징을 이용해서 출력 계층은 분류나 예측을 하게 되는 것이다.
#케라스 API를 사용해 데이터셋 불러오기
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
#이미지의 픽셀값 변환, 크기와 배열 바꾸기
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)#층 추가해주기
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')여기서 dense1 이 은닉층이고, 100개의 뉴런을 가진 밀집층이다. 활성화 함수를 '시그모이드' 로 지정했고, 매개변수에서 입력의 크기를 (784,) 로 지정했다. 여기서 한가지 제약 사항은, 적어도 출력층의 뉴런보다는 은닉층의 뉴런 개수를 많게 만들어야 한다는 것이다.
그 다음 dense2 는 출력층이다. 10개의 클래스를 분류하기에 10개의 뉴런을 두었고, 활성화 함수는 '소프트맥스' 함수를 지정했다.
심층 신경망 만들기
model = keras.Sequential([dense1,dense2])Sequential 클래스의 객체를 만들 때, 여러 개의 층을 추가하려면 dense1, dense2와 같이 리스트를 만들어서 전달해야한다. 여기서 중요한 것은, 출력층은 리스트의 가장 마지막에 두어야 한다는 것이다. 즉 순서가 은닉충 -> 출력층 이다.
층을 추가하는 다른 방법
층을 추가하는 다른 방법은 Sequential 클래스의 생성자 안에서 바로 Dense 클래스의 객체를 만드는 방법이다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name="output")
], name='패션 MNIST모델')
model.summary()Model: "패션 MNIST모델"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________Summary 메서드는 층에 대한 유용한 정보를 얻을 수 있는 메서드이다.
위와 같은 방법으로 작업하면 층을 한눈에 알아보기 쉽다는 장범이 있지만, 너무 많은 층을 추가하려면 코드가 매우 길어지기에 add() 메서드도 사용한다.
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 100) 78500
dense_4 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________이제 compile() 메서드 설정을 통한 모델 훈련을 해보자.
#5번의 에포크 동안 훈련하기
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.5692 - accuracy: 0.8060
Epoch 2/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4098 - accuracy: 0.8536
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3745 - accuracy: 0.8648
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3520 - accuracy: 0.8723
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3355 - accuracy: 0.8776
<keras.callbacks.History at 0x7d12edaba800>훈련 세트에 대한 성능을 보면 추가된 층이 성능을 향상시킨 것을 알 수 있다.
렐루 활성화 함수
초창기 인공 신경망의 은닉충에 많이 사용된 활성화 함수는 시그모이드 함수였다.
다만 이 함수는 오른쪽과 왼쪽 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는데 신속하게 대응하지 못한다는 단점이 있다. 이는 층이 많은 신경망일수록 효과가 누적되어 학습을 어렵게 한다.
이를 개선하기 위해 렐루 함수가 사용된다.
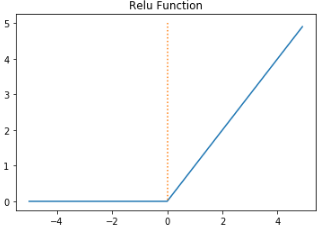
렐루 함수는 max(0, z) 로 쓸 수 있다. 이는 특히 이미지 처리에 좋은 성능을 낸다.
패션 MNIST 데이터는 28x28 크기이기 때문에 인공 신경망에 주입하기 위해선느 넘파이 배열의 reshape() 메서드를 사용해 1차원으로 펼쳤다. 직접 1차원으로 펼치는 것도 좋지만, 케러스에서는 이를 위한 Flatten 층을 제공한다.
#렐루 함수를 이용한 밀집층 추가하기
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense_5 (Dense) (None, 100) 78500
dense_6 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________Flatten 층을 신경망 모델에 추가하면 입력값의 차원을 짐작할 수 있다.
다음은 훈련 데이터로 모델을 훈련시켜 보겠다.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.5346 - accuracy: 0.8119
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3964 - accuracy: 0.8592
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3573 - accuracy: 0.8704
Epoch 4/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3343 - accuracy: 0.8786
Epoch 5/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3205 - accuracy: 0.8852
<keras.callbacks.History at 0x7d12f3e58610>
시그모이드 함수를 사용했을 때와 비교하면 성능이 조금 나아졌다. 미약하지만 렐루 함수의 효과를 본 것 같다. 그럼 검증 세트에서의 성능도 한번 확인해보자.
model.evaluate(val_scaled, val_target)375/375 [==============================] - 1s 3ms/step - loss: 0.3635 - accuracy: 0.8742
[0.3635408878326416, 0.8741666674613953]은닉층을 추가하지 않은 경우보다 몇 퍼센트 성능이 향상된 것을 볼 수 있다.
신경망 모델 훈련
지금까지 인공 신경망과 심층신경망을 구성하고 다양한 옵티마이저를 통해 성능을 향상시킬 수 있는 방법에 대해 알아보았다.
이번에는 과대적합을 막기 위해 신경망에서 사용하는 규제방법인 드롭아웃, 최상의 훈련된 모델을 자동으로 저장하고 유지하는 콜백과 조기종료를 알아본다.
#데이터 준비하기
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)이를 토대로 모델을 만들어 보자.
def model_fn(a_layer=None) :
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
#은닉층 뒤에 또하나의 층 추가
if a_layer :
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model여기서 if 구문의 역할은 model_fn() 함수에 케러스 층을 추가하면 은닉층 뒤에 또 하나의 층을 추가해 주는 것이다.
model = model_fn()
model.summary()Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_7 (Dense) (None, 100) 78500
dense_8 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________그럼 함수로 신경망 모델을 만들고 손실도와 정확도를 확인해보자.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
print(history.history.keys())dict_keys(['loss', 'accuracy'])
손실과 정확도가 포함되어 있다. history 객체에는 훈련 측정값이 담겨 있는 history 딕셔너리가 들어 있다.
딕셔너리 안에는 손실과 정확도가 담겨 있다. 이는 에포크마다 계산한 값이 순서대로 들어있다.
에포크에 따른 손실과 정확도를 그림으로 표현할 수 있을까? 맷플롯립을 통해 쉽게 해볼 수 있다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()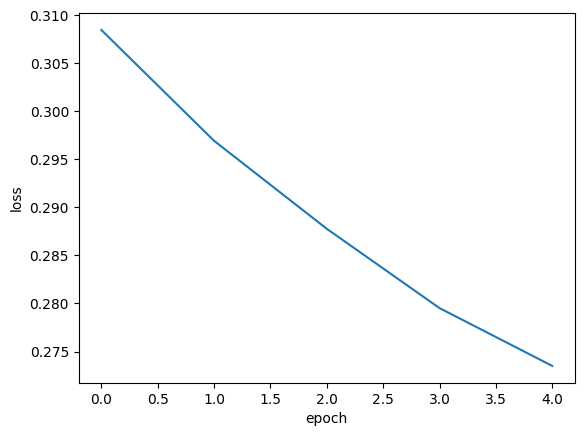
위의 그림은 손실도에 대한 그래프이고, 정확도를 그림으로 출력해보자.
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
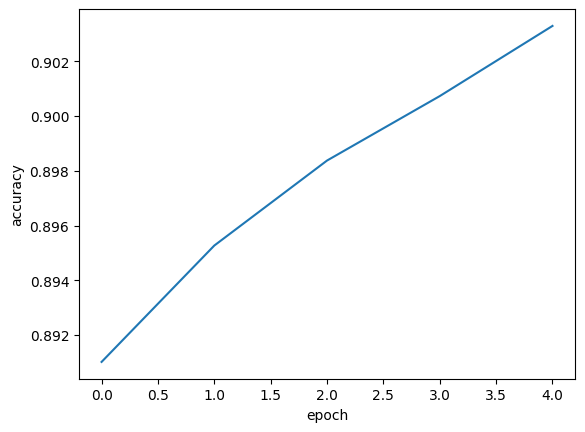
그림을 보면 에포크마다 손실이 감소하고, 정확도가 올라가는 경향을 볼 수 있다. 에포크 횟수를 늘리면 손실도 감소하고, 정확도도 조금 올라간다. 하지만 여기서 빠뜨린 것이 한 가지 있다. 에포크에 따른 과대적합과 과소적합을 파악하려면 훈련 세트에 대한 점수뿐 아니라, 검증 세트에 대한 점수도 필요하다. 위와 같이 훈련 세트의 손실만 그리는 것이 검증 세트에 대한 손실도 그려보아야 하는 것이다.
에포크마다 검증 손실을 계산하기 위해 케라스 모델의 fit() 메서드에 검증 데이터를 전달할 수 있다.
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))반환된 history.history 딕셔너리에 어떤 값이 있는지 확인해보자.
print(history.history.keys())dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
검증 세트에 대한 손실은 'val_loss' 에 들어 있고 정확도는 'val_accuracy' 에 들어 있을것이라 예상된다. 과대, 과소적합의 문제가 있는지 알아보기 위해 훈련 손실과 검증 손실을 한 그래프에 비교해서 그려보겠다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend('train', 'val')
plt.show()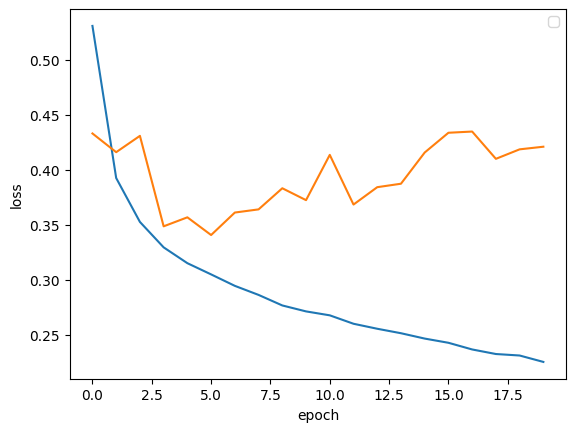
그림을 보면 초기에는 검증 손실이 감소하다가 다섯 번째 에포크 만에 다시 상승하기 시작한다. 또한, 훈련 손실은 꾸준히 감소하기에 전형적인 과대적합 모델이라고 볼 수 있다. 검증 손실이 상승하는 시점을 뒤로 미루면 검증 세트에 대한 손실이 줄어들 뿐 아니라, 검증 세트에 대한 정확도도 증가할 것이다.
드롭아웃
과대 적합을 막기 위한 신경망에 특화된 규제 방법은 '드롭아웃' 이다.
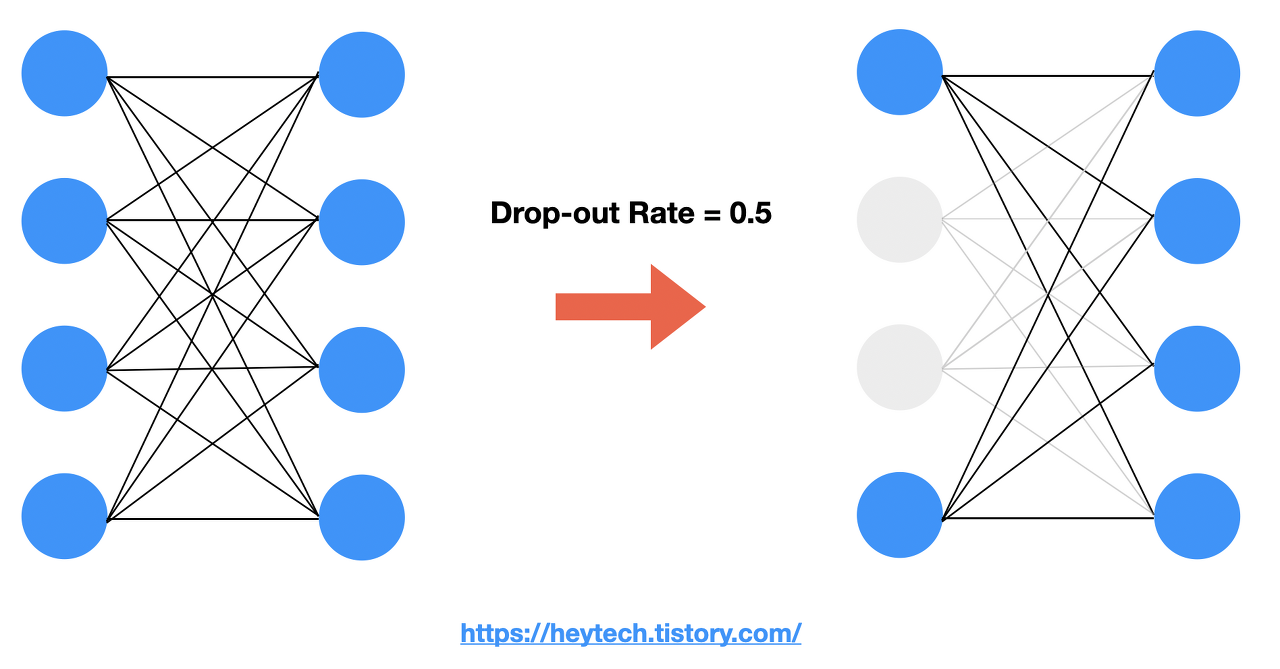
드롭아웃이란?
- Drop-out은 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거(drop)하는 기법이다. Drop-out Rate는 하이퍼파라미터이며 일반적으로 0.5로 설정한다.
드롭아웃의 목적?
- Drop-out은 어떤 특정한 설명변수 Feature만을 과도하게 집중하여 학습함으로써 발생할 수 있는 과대적합(Overfitting)을 방지하기 위해 사용된다.
과대적합을 막는 방법
- 드롭아웃은 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서(뉴런의 출력을 0으로 만들어) 과대적합을 막는다.
케라스에서는 드롭아웃을 keras.layers 패키지 아래 Dropout 클래스를 제공한다. 어떤 층의 뒤에 드롭아웃을 두어 이 층의 출력을 랜덤하게 0으로 만드는 것이다. 드롭아웃이 층처럼 사용되지만 훈련되는 모델 파라미터는 없다.
그럼 이제 model_fn() 함수에 드롭아웃 객체를 전달해 층을 추가해 보겠다.
model = model_fn(keras.layers.Dropout(0.3))
model.summary()Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_3 (Flatten) (None, 784) 0
dense_11 (Dense) (None, 100) 78500
dropout (Dropout) (None, 100) 0
dense_12 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________출력 결과에서 볼 수 있듯이 은닉층 뒤에 추가된 Dropout 층은 훈련되는 모델 파라미터가 없다. 또한 입력과 출력의 크기가 같은 것을 볼 수 있다. 일부 뉴런의 출력은 0으로 만들지만 전체 출력 배열의 크기를 바꾸지는 않는다. 여기서 주의할 점은 훈련이 끝난 뒤에 평가나 예측을 수행할 때는 드롭아웃을 사용하지 말아야 한다는 것이다. 이유는, 훈련된 모든 뉴런을 사용해야 올바른 예측을 할 수 있기 때문이다.
그럼 다시 훈련 손실과 검증 손실의 그래프를 그려보자.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()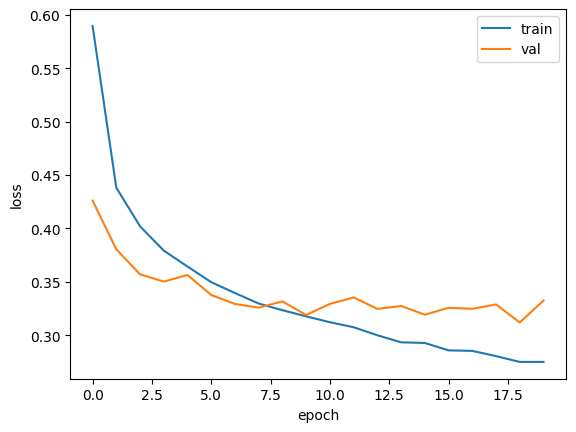
이전에 봤던 것보다 과대적합 문제가 줄어든 것을 볼 수 있다. 하지만 이 모델은 20번의 에포크 동안 훈련했기 때문에 약간의 과대적합 문제가 있는 것을 볼 수 있다. 이 문제를 해결하기 위해서는 에포크 횟수를 10회로 줄여서 해결할 수 있다.
#에포크 횟수를 10으로 지정하고 다시 훈련하기
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics = 'accuracy')
history = model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))
#훈련된 모델의 파라미터 지정하기
model.save_weights('model-weights.h5')
#모델 구조와 모델 파라미터를 함께 저장하기
model.save('model-whole.h5')콜백
콜백이란?
- 콜백은 모델을 fit한 뒤, iteration 할 때마다 특정한 이벤트에 따라 callback이 수행되는 것을 말한다. 주로 learning_rate를 수정할 때 사용된다.
콜백의 종류?
-
ModelCheckpoint
-> 기본적으로 에포크마다 모델을 저장한다.
-> Save_best_only=True 매개변수를 지정해서 가장 낮은 검증 점수를 만드는 모델을 저장할 수 있다. -
ReduceLROnPlateau
->learning_rate를 동적으로 감소시킨다. -
EarlyStopping(조기종료)
-> 특정 epochs 동안 성능 개선이 되지 않으면(과대적합이 시작되기 전), 조기 중단하는 것을 말한다.
-> 딥러닝 분야에서 널리 사용된다.
EarlyStopping 콜백을 ModelCheckpoint 콜백과 함께 사용하면 가장 낮은 검증 손실의 모델을 파일에 저장하고 검증 손실이 다시 상승할 때, 훈련을 중지할 수 있다. 또한 훈련을 중지한 다음 현재 모델의 파라미터를 최상의 파라미터로 되돌릴 수도 있다.
그럼 이 두 콜백을 함께 사용해 보겠다.
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks = [checkpoint_cb, early_stopping_cb])
#훈련이 중지된 에포크 횟수 알아보기
print(early_stopping_cb.stopped_epoch)10
이 결과값은 11번째 에포크에서 훈련이 중지되었다는 것을 뜻한다. patience를 2로 설정했기에 8번째 에포크가 최상의 모델일 것으로 예측된다.
훈련 손실과 검증 손실을 출력해서 확인해보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show() 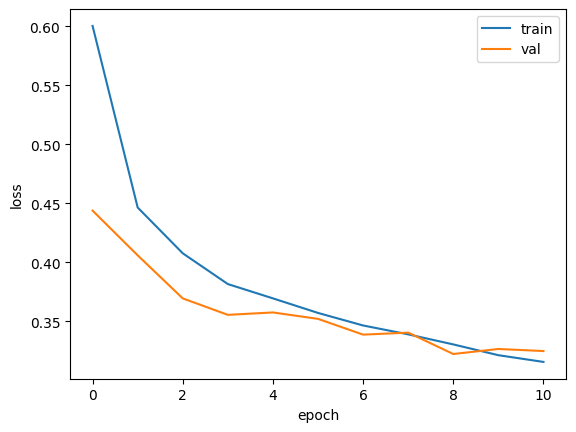
예측한 것과 같이 8번째 에포크에서 가장 낮은 손실을 기록했고, 11번째 에포크에서 훈련이 종료된 것을 볼 수 있다. 이렇듯 조기종료 기법을 사용하면, 안심하고 에포크 횟수를 늘려도 된다. 자동적으로 알아서 훈련을 종료해주기 때문이다. 오늘은 여기까지 하겠다.

좋은 글 감사합니다. 자주 올게요 :)