해당 포스트는 쉬운코드님의 유튜브 영상을 정리한 내용입니다.
RDB의 단점
- 경직된 스키마
- 새로운 컬럼을 추가하고 싶다면, 반드시 스키마 변경이 필요
- 테이블에 엄청나게 많은 데이터가 쌓였을 때 새로운 컬럼을 추가하는 것은 상당히 위험하다.
- RDB는 유연한 확장성이 부족하다.
- 과도한 조인과 성능 하락
- RDB는 중복 제거를 위해 정규화를 진행한다.
- 정규화를 하면 테이블의 데이터 중복도는 낮아지지만 그만큼 테이블의 개수가 늘어난다.
- 이렇게 되면 원래의 전체 데이터를 읽고싶을 때 많은 조인이 발생한다.
- DB 서버의 cpu 사용량 증가, read 성능의 하락, 응답시간 하락
- Scale-out이 불편함
- RDB는 기본적으로 한 대의 컴퓨터에 저장
- 부하가 늘어날 때 기존의 RDB는 일반적으로 scale up을 통해 DB의 성능을 향상시켰다.
- scale up = 더 좋은 컴퓨터로 교체
- scale up 뿐만 아니라 replication 등의 방법을 통해 read 부하를 분산시킬 수도 있다.
- 하지만 write 부하가 많을 경우는 처리하기 어렵다.
- 일반적으로 RDB는 scale out에 유연한 DB가 아니다.
- replication을 한다 해도 새로운 DB에 모든 데이터를 복사하는 작업 필요
- write가 많아 sharding을 한다 해도 데이터를 옮겨야 하는데, 쉬운 작업이 아니다.
- ACID가 성능에 영향
- ACID는 RDB의 장점
- 하지만 ACID를 보장하려다 보니 DB서버의 성능에 어느 정도 안좋은 영향을 미침
- 엄밀성과 처리량의 trade off
NoSQL 등장의 배경
SNS 등의 미디어가 등장하며
- high-throuput 요구됨
- low-latency 요구됨
- 비정형 데이터의 증가
NoSQL 특징
-
유연한 스키마
ex)mongoDB db.createCollection("student") db.student.insertOne({ name: "easycode" }) db.student.insertOne({ name: "hope", address: { country: "korea", state: "seoul", city: "Gangnam-gu", street: "~~" }, certificate : ["AWS SA"] }) db.student.find({name: "easycode"})- 스키마가 정해져있지 않기 때문에 원하는대로 객체 생성해서 넣어주면 된다.
- mongoDB는 json 포맷으로 데이터를 넣는다.
- but RDB의 경우 RDB단에서 스키마 관리를 해줬지만, NoSQL의 경우 Application 레벨에서 스키마 관리를 해줘야 한다.
- 스키마가 정해져있지 않기 때문에 원하는대로 객체 생성해서 넣어주면 된다.
-
중복 허용 (join 회피)
- RDB는 정규화를 통해 중복을 제거했지만, NoSQL은 중복을 허용한다.
- 이렇게 할 경우 join을 할 필요가 없어진다.
- application 레벨에서 중복된 데이터들이 모두 최신 상태를 유지할 수 있도록 관리해야 한다.
- join을 안해서 얻는 장점과 (저장 공간 + 데이터 상태 관리)의 trade off
- RDB는 정규화를 통해 중복을 제거했지만, NoSQL은 중복을 허용한다.
-
더 편한 scale-out
- 서버 여러 대로 하나의 클러스터를 구성하여 사용한다.
- 각각의 서버들에 데이터를 나눠서 저장한다.
- 중복을 허용하므로 join할 필요 없이 한 서버에서 데이터를 모두 받아온다.
- 서버 여러 대로 하나의 클러스터를 구성하여 사용한다.
-
ACID의 일부를 포기하고 high-throughput, low-latency 추구
- 금융, 결제 시스템처럼 consistency가 중요한 환경에서는 사용하기 어려움
Redis 소개
- in-memory key-value database, cahe or …
- 메모리는 비싸기 때문에 주로 DB가 아닌 캐시로 사용
- 메모리 캐시이기 때문에 DB에 비해 매우 빠르다.
redis> SET name easycode
"OK"
redis> GET name
"easycode"- 여러가지 데이터 타입을 지원
- strings, lists, sets, hashes, sorted sets, …
- 해시 기반 샤딩된 클러스터 구성 가능
- 고가용성 (replication, automatic failover)
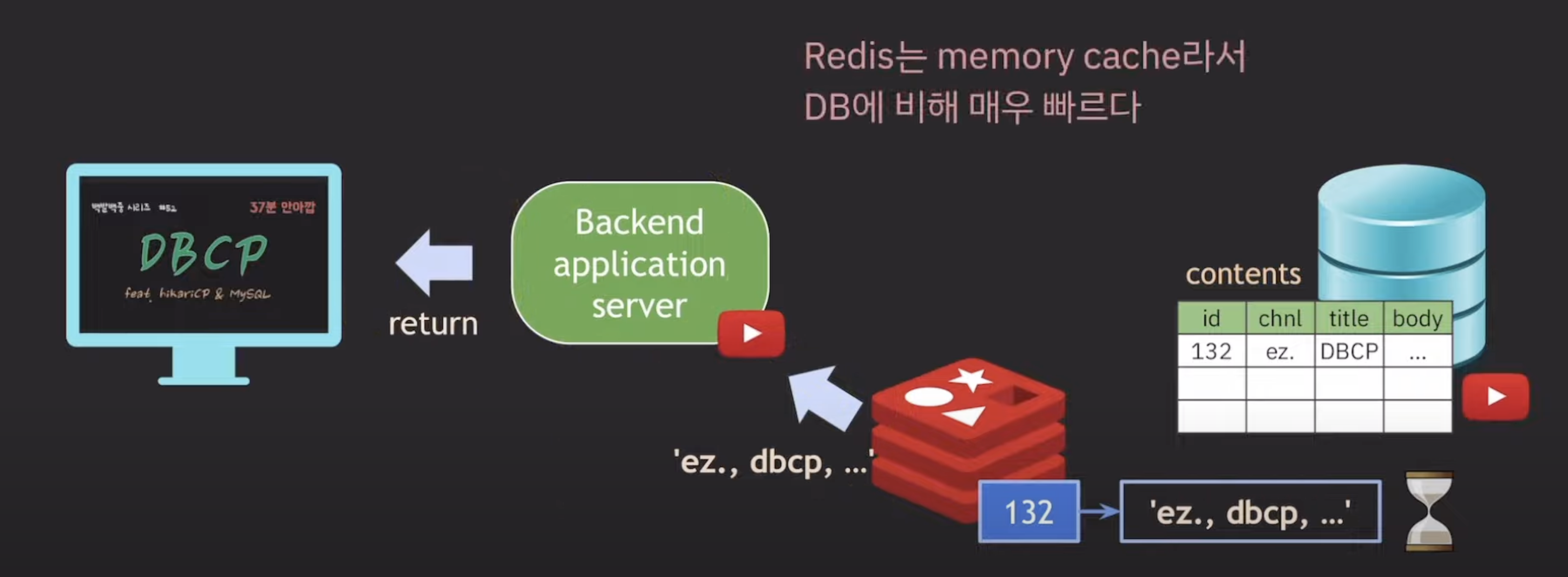
서버와 RDB 사이에 캐시로 둬서 RDB가 받는 부하를 줄여주는 식으로 사용할 수 있다.
