이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
추천 시스템이 성능평가?
비즈니스 / 서비스 관점
-
추천 시스템 적용으로 인한
매출,PV(page view)증가 -
추천 아이템으로 인한 유저의
CTR(노출 대비 클릭율)상승
품질관점
-
연관성(Relevance): 추천 아이템이 유저에게 관련 있는가?- 40대 남자에게는 화장품이 아닌 골프용품을 추천해 주어야 한다.
-
다양성(Diversity): 추천된 Top-k 아이템이 얼마나 다양한 아이템이 추천되는가- 노트북 한번 봤다고 주구장창 노트북을 노출시켜선 안된다.
-
새로움(Novelty): 얼마나 새로운 아이템이 추천되는가- 새로고침시 A 말고 B가 뜨면 좋다
-
참신함(Serendipity): 유저가 기대하지 못한 뜻밖의 아이템이 추천되는가- 메인 지표는 아니지만 재미요소를 가져올 수 있다.
Offline Test
Offline Test?
새로운 추천 모델을 검증하기 위해 가장 우선적으로 수행되는 단계
유저들로부터 수집한 데이터를 train/valid/test로 나누어 모델의 성능을 객곽적인 지표로 평가 -> ML평가와 동일
보통 offline test에서 좋은 성능을 보여야 online serving에 투입되지만 실제 서비스 상황에서는 다양항 양상을 보임( serving bias 존재)
serving bias
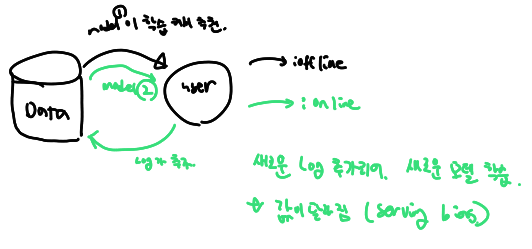
Offline Test 성능 지표
예측 문제의 경우 일반적인 ML 성능지표와 동일하므로 이 글에서는 제외합니다.
랭킹문제
랭킹 문제에 대한 성능지표는 추천에서만 쓰인다.
-
Precision @ K
우리가 추천한 K개 아이템 중 실제 유저가 관심있는 비율 -
Recall @ K
유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
Precision @ KRecall @ K예시
우리가 추천한 아이템 개수 : 5
추천한 아이템 중 유저가 관심있는 아이템 개수 : 2
유저가 원래 관심있는 아이템의 전체개수 : 3 일때
Precision @ K= 2/5
Recall @ K= 2/3
AP @ K(Average Precision)
Precision @ 1~Precision @ K까지의 평균값
Precision @ K와 달리 관심 아이템을 더 높은 순위에 추천할수록 점수가 상승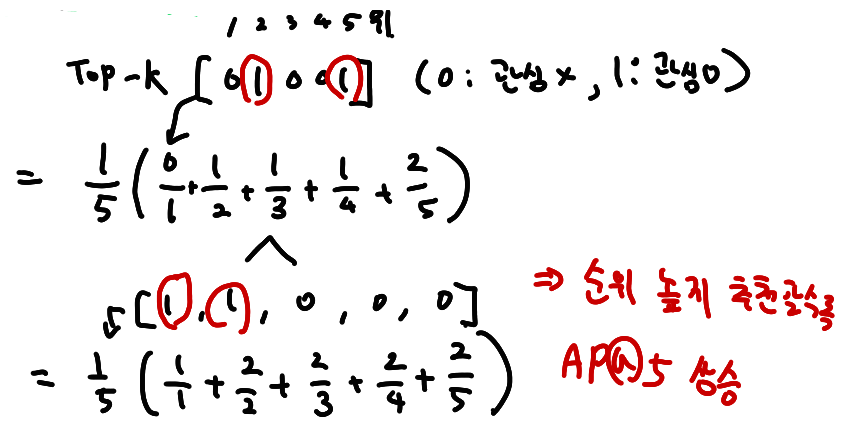
MAP @ K(Mean Average Precision)
AP @ K를 전체 유저로 확장 -> 모든 유저에 대한 AP 평균
nDCG (Normalized Discounted Cumulative Gain)
추천시스템에서 가장 많이 사용되는 지표로 원래는 검색에서 등장한 지표
Precision@K, MAP@K와 마찬가지로 Top K 리스트를 만드고 유저가 선호하는 아이템을 비교하여 값을 구함
MAP@K 와 마찬가지로 추천 순서에 가중치를 더 많이 두어 성능을 평가하면 1에 가까울 수록 좋음(DCG를 IDCG로 나눈 값이기 때문에 1보다 클 수 없다)
MAP 과 달리, 연관성을 binary 값이 아닌 수치로도 사용할 수 있기 때문에 유저에게 얼마나 더 관련있는 아이템을 상위로 노출 시키는 지 알 수 있음.
NDCG를 구하기 위해 차근차근 성능지표를 알아보자.
-
Cumulative Gain
상위 K 아이템에 대하여 관련도를 합한 것
순서에 따라 Discount 하지 않고 동일하게 더한 값 -
Discounted Cumulative Gain
순서에 따라 Cumulative Gain을 Discount함( 로) -
Ideal DCG
이상적인 추천이 일어났을 때의 DCG 값 (이때 이상적인 추천은 알고있다 가정)
가능한 DCG 값중에 제일 크다 -
Normalized DCG
추천결과에 따라 구해진 DCG를 IDCG로 나눈 값
예시)
NDCG@5를 구해보자
Ideal Order : [ C(3), A(3), B(2), D(1) ]
Recommend Order : [ E, A, C, D, B ]Online Test
Offline Test 에서 검증된 가설이나 모델을 이용해 실제 추천 결과를 serving 하는 단계
추천 시스템 변경 전후 성능 비교 X
동시에 대조군(A) 와 실험군(B) 의 성능을 평가
-> A/B test 환경은 최대한 동일해야한다.
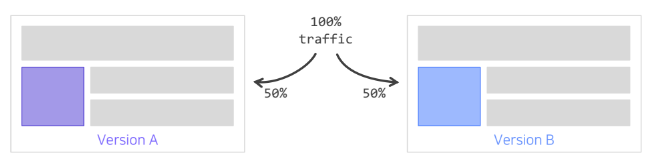
이를 통해 얻어지는 결과를 토대로 최종 의사결정을 하게 된다
대부분의 현업에서 의사결정에서 사용하는 최종 지표는
모델성능이 아닌 매출, CTR 등의 비즈니스/서비스 지표
