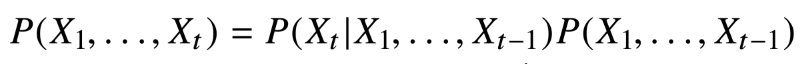
이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
RNN은 구조자체는 어렵지 않지만 왜 그렇게 해야하는지 수식을 통해 이해가 필요하다
시퀸스 데이터
시퀸스 데이터란
- 소리, 문자열, 주가 등 시간에 따라 변화하는 데이터를 시퀸스(sequence) 데이터라고 한다
- 시퀸스 데이터는 i.i.d(독립동등분포)가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
시퀸스 데이터는 이전의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 기본적으로 조건부 확률을 이용한다.
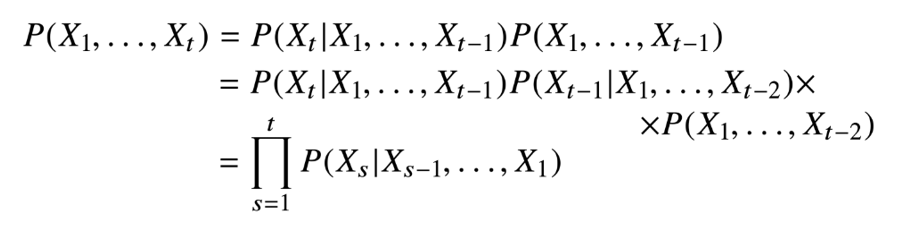
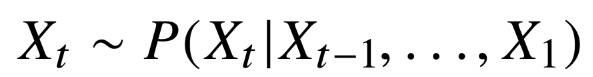
이처럼 조건부 확률을 이용하게 된다면 과거의 모든 정보를 사용하게 된다.
하지만 실제로 시퀸스 데이터를 분석할 때 과거의 모든 정보들을 사용 할 수 없다.
RNN(Recurrent Neural Network)
RNN의 등장
시퀸스 데이터를 다루기 위해서는 길이가 가변적인 데이터를 고정된 길이의 데이터로 다룰 수 있는 모델이 필요
AR(Autoregressive) 모델
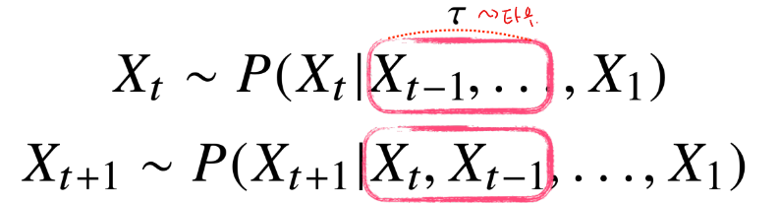
고정된 길이 만큼의 시퀸스를 사용하는경우 라는 자기회귀 모델이 된다.
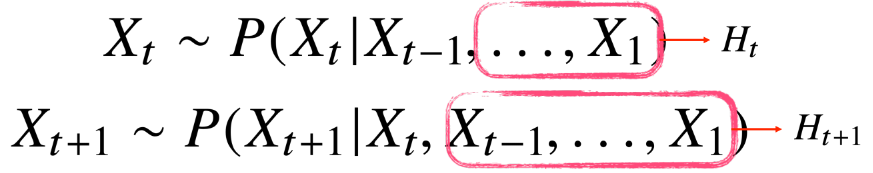
바로 이전 정보를 제외한 나머지 정보들을 라는 잠재변수로 인코딩해서 활용하는
잠재AR모델이 활용될 수 있는데, 이때 를 인코딩 할 때 RNN이 등장하게 된다.
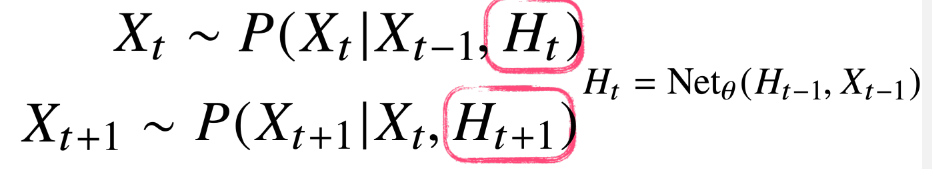
이처럼 잠재변수 를 신경망을 통해 반복해서 사용하여
시퀸스 데이터의 패턴을 학습하는 모델이 RNN이다.
RNN 이해
가변적인 길이의 데이터를 다루기 위해 잠재변수를 활용해 자기회귀적인 모형을 만들어서 모델링을 하게된다.
MLP
가장 기본적인 RNN 모형은 MLP와 유사하다.(2-Layer)

MLP의 경우 입력 를 과 선형결합 후 활성화함수를 씌운 잠재벡터에 다시 를 곱해 출력되게 된다.
이때 과 는 시점에 상관 없이 모든 시점에서 동일한 값을 가지는 값이다.
그렇기 때문에 이 모델은 과거의 정보를 다룰 수 없다.
RNN
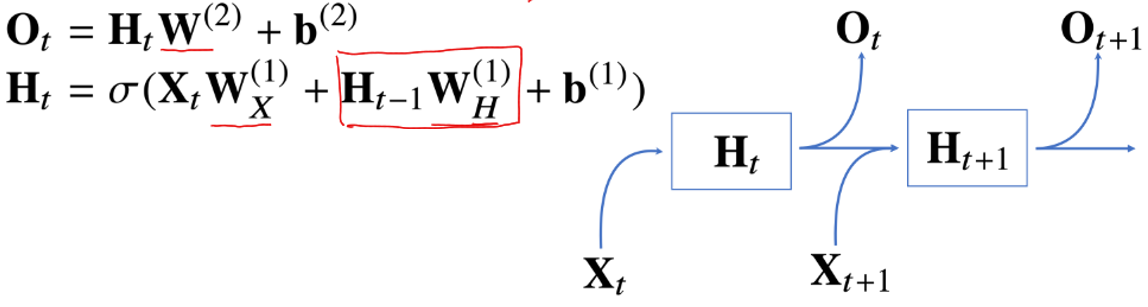
MLP와 다른점을 보면 term을 표현할 때 RNN은 새로운 벡터(가 등장한다.
- : 입력의 가중치
- : 이전까지의 잠재변수
- : 이전 잠재변수의 가중치
잠재변수인 는 복제해서 다음순서의 잠재변수를 인코딩하는데 사용한다.
이때도 마찬가지로 가중치는 시점에 따라 변하지 않는 값이다.
- 시점에 따라 변하는 것은 오직 입력벡터와 잠재변수뿐이다.
BPTT(Backpropagation Through Time)
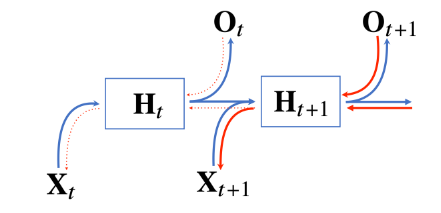
그림으로
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산한다.
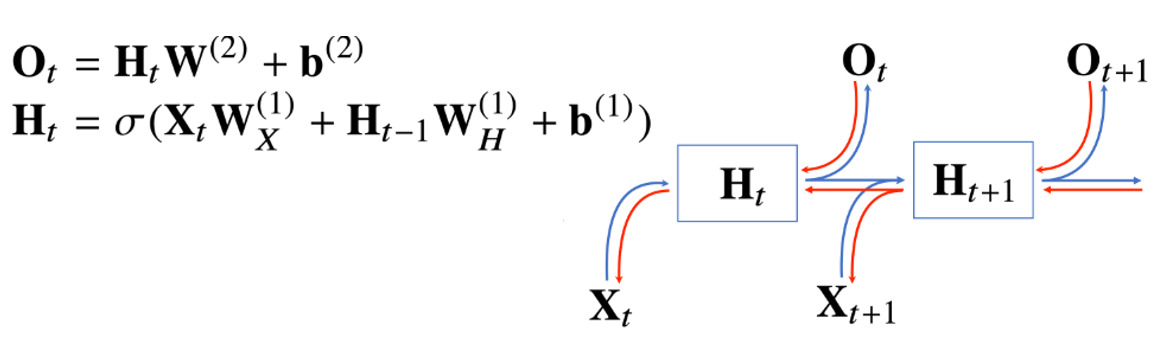
잠재변수들의 연결그래프에 따라서 순차적으로 계산되게 된다.
모든 시점의 그레디언트가 예측이 된 후에 마지막 시점에서부터 타고 올라와서 과거까지 그레디언트가 흐르는 방법이다.
그림에서는 빨색색이 역전파의 흐름이다.
그래서 잠재변수에 들어오는 그레디언트벡터는 2개로
- 지금 시점에서의 출력벡터의 그레디언트 벡터
- 다음 시점에서의 잠재변수의 그레디언트 벡터
이렇게 들어온 그레디언트 벡터를 입력와 이전시점에 잠재변수에 전달을 하게되면서 RNN의 학습이 이루어진다.
수식으로
모든 t시점의 손실함수를 계산하고 그레디언트를 계산하는 형태인데,
다음과 같은 식이 나오게 된다.

빨간박스의 항은 모든 시점에 대한 잠재변수의 미분이 곱해진 형태인 것을 볼 수 있는데,
이때 시퀸스의 길이가 길어질수록 미분값이 곱해진 빨간박스의 항은 0 또는 무한대로 수렴할 확률이 높아지게된다.
-> 기울기 소실 / 과거 시점의 데이터가 소실
이렇게 시퀸스의 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊는 것이 필요한데 이를 truncated BPTT라고 부른다.
하지만 truncated BPTT는 기울기 소실 문제를 완전히 해결할 수 없기때문에
오늘날에는 기울기 소실 문제를 해결하기 위해 LSTM이나 GRU같은 네트워크를 사용한다.
