이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Sequential Model의 문제점
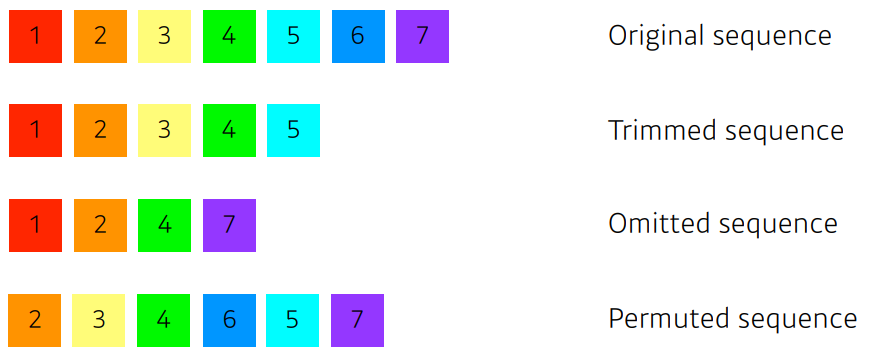
신경망에 넣을때 sequential 하게 입력이 들어가게 되는데 sequential data가 끊기거나(Trimmed), 중간에 빠져있거나(Omitted), 밀리거나(Permuted) 한다면 모델학습을 할 수 없게된다.
Transformer
이 글에서는 Transformer의 구조를 중점적으로 다루도록 하겠다.
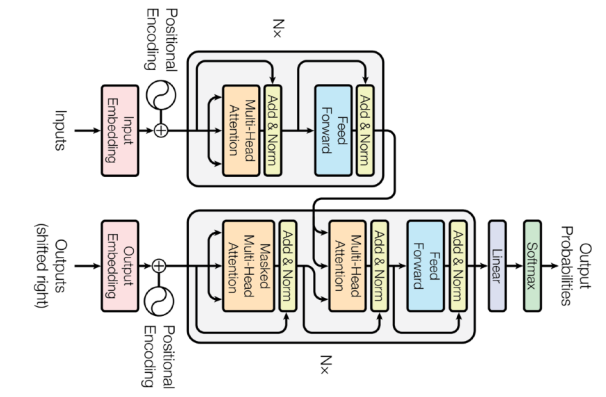
기존의 RNN과 다르게 재귀적 구조가 아닌 Attention 이라는것을 사용해서 sequence를 다루는게 특징이다.
특히, 신경망 기계 번역(Neural machine translation, NMT) 에서 어떻게 처리하는가를 중점적으로 보겠다. ( sequential data를 처리하고 encoding 하는 것이기 때문에 단순히 NMT 뿐만 아니라 이미지 분류 , detection 등에도 사용된다)
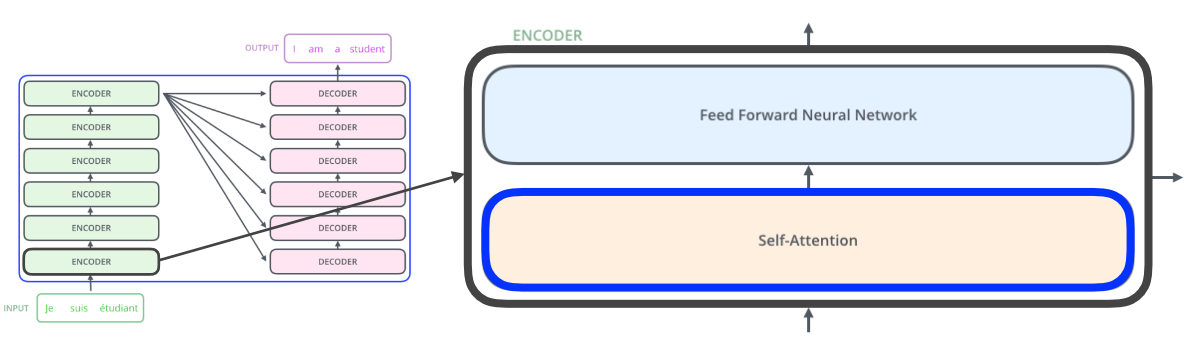
Transformer 는 seq to seq 모델이라고도 하는데 이는 sequence 가 주어졌을 때 다른 sequence로 바꾸는 것을 뜻한다.
예를 들어 그림처럼 불어의 sequence가 주어졌을 때 영어 sequence로 바꿔주는 것이다.
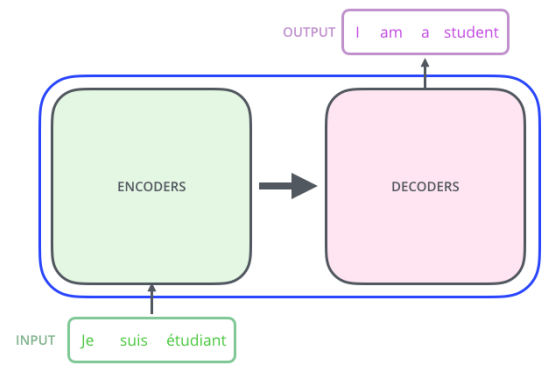
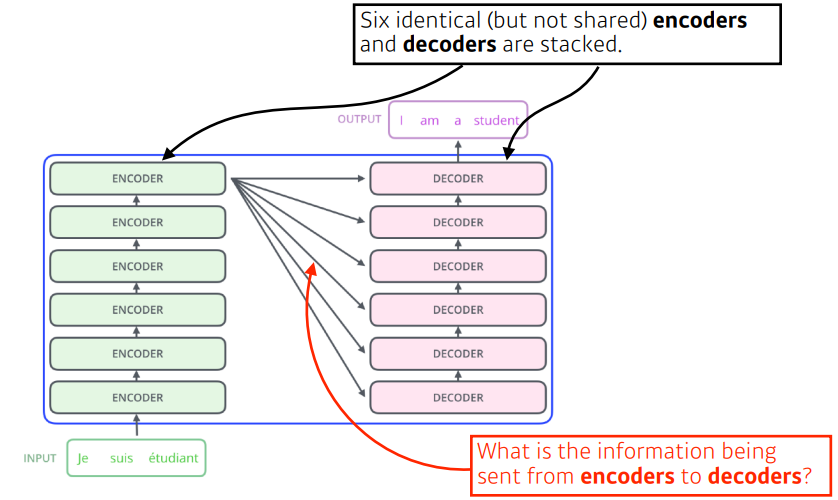
그림에서 알 수 있는 것
-
입력과 출력의 개수가 다를 수 있다. (
input: 3개 ,output: 4개) -
입력과 출력 도메인이 다를 수 있다. (
input: 불어,output: 영어) -
모델은 1개 이다.
RNN은 3개 단어가 들어가면 3번 모델이 돌아가겠지만 ,
Transformer는encoder부분에서 n개의 단어를 한번에 처리할 수 있다!- 단,
decoder에서generation(생성)할 때는 자기회귀적으로 한다)
알아야 할 것
-
encoder에서 어떻게 한번에 처리 하는가? -
decoder와encoder사이에 어떤 흐름이 있는가? -
decoder가 어떻게generation하는가?
Self - Attention
Tranformer의 Encoder 부분의 구조는
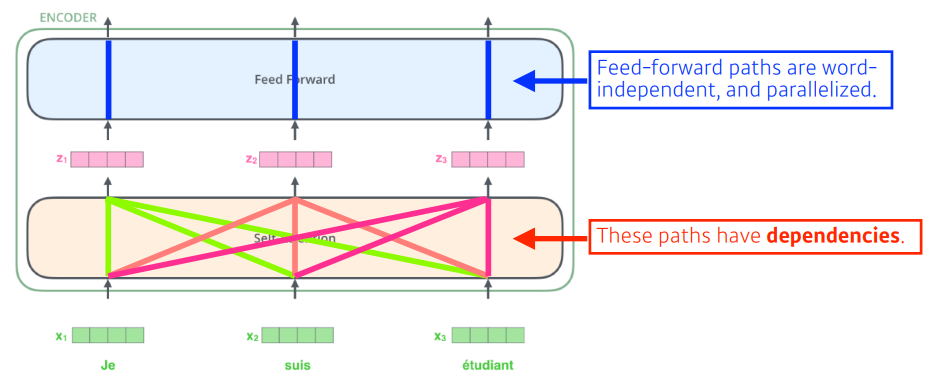
input 이 한번에 들어오면 self-Attention -> feed forward 를 거치는 encoder 를 쌓은것이다.
NMT 문제 라고 가정한 예제를 보자
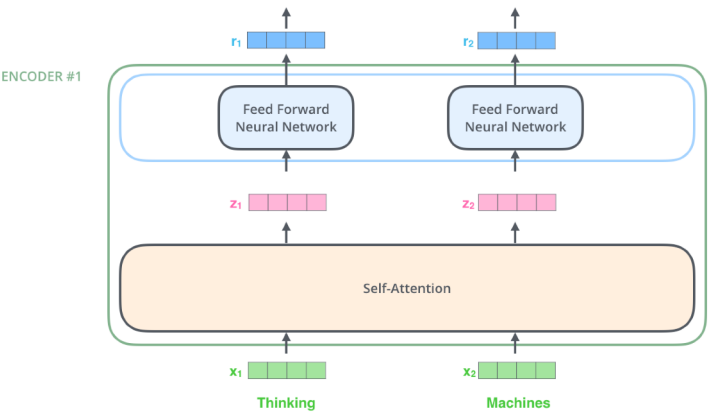
self-Attention은 3개의 단어 벡터를 또다른 벡터 3개로 변환해준다.
이때 중요한 것은 각 단어 벡터는 또다른 벡터로 변화될 때 서로에게 영향을 끼친다는 점이다.
feed forward에서는 서로 영향을 끼치지 않는 것을 볼 수 있다.
Self - Attention 이 어떻게 되는지 high-level에서 한번 보자.

이 그림에서 self-Attention 은 it 을 encoding 할 때 다른 단어들과의 관계성을 본다.
학습된 결과를 보면 it이 aniamal과 관계가 높다고 알아서 학습이 된다.
문제를 더 단순화 해서 2개 단어가 주어졌다고 가정해보자
self-Attention은 기본적으로 Query , Key , Value 3개의 벡터를 만든다.
이 3개의 벡터를 통해서 x1 이라는 Embedding 벡터 로 바꿔 주는 것이 목적이다.
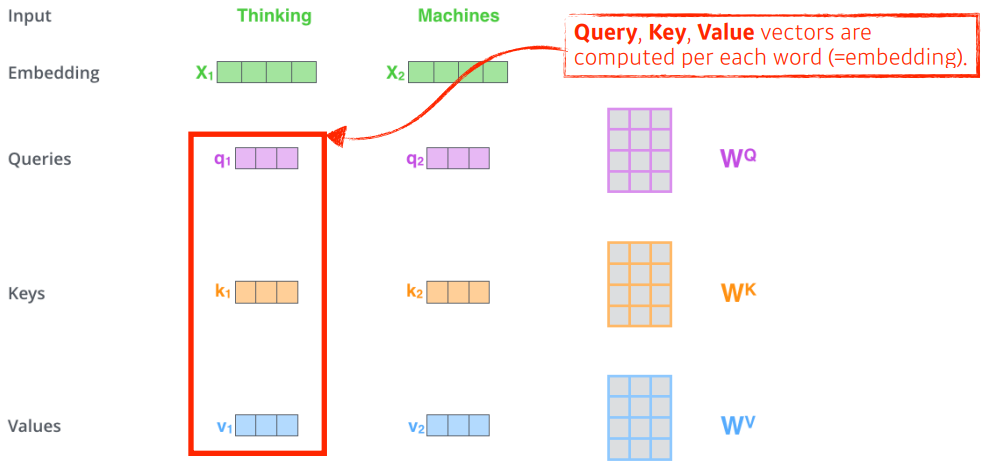
그럼 tinking 이라는 단어를 embedding 시켜보자.
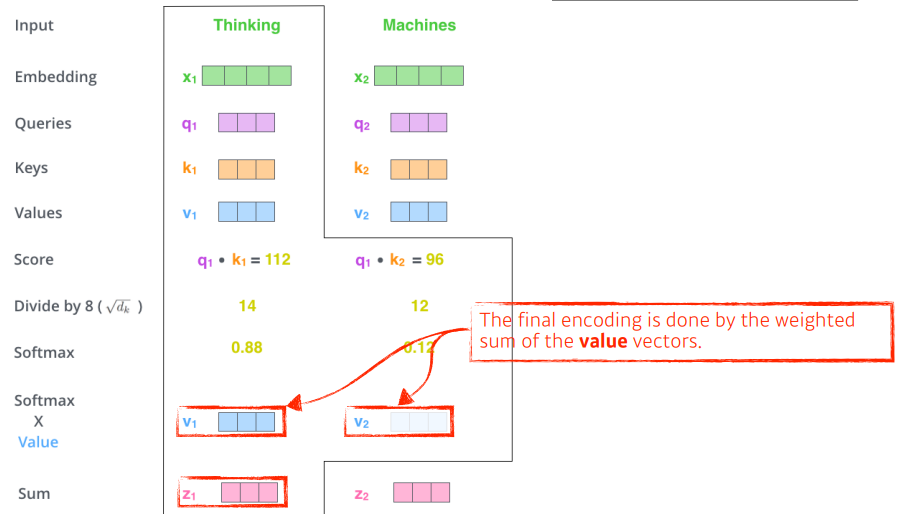
`score 벡터` 를 생성한다.score 벡터 : i 번째 단어 의 query벡터 와 나머지 모든 n개의 key벡터 에 대한 내적 값들.
( i 에 대한 쿼리를 다른 단어들의 key 벡터에 날린다고 생각하면 쉽다 )
-> i번째 단어가 다른 단어와 얼마나 interaction 해야 하는지를 알아서 학습하게 하는 것으로
$nsbr Attention의 의미를 가진다. (해당 step을 볼 때 다른 step 중 어떤 걸 주의깊게 봐야하는지)
score 벡터가 너무 커지지 않게 normalizekey 벡터의 차원 의 루트값으로 나눠주고, softmax를 해주어 0~1 범위 안에 있을 수 있도록 한다.
이때 key 벡터의 차원 은 hyper parameter 이다.
softmax 한 값(attention weight)과 value 벡터들의 weight sum 직접적으로 사용할 값으로 thinking 이란 단어의 embedding 벡터 이다.
value 벡터의 차원 과 차원이 같아진다.
이때 주의할 점을 Q 와 K의 차원은 내적을 해야하기 때문에 같아야 하지만,
V의 차원은 weight sum을 하기 때문에 달라도 괜찮다.
같은 문제를 행렬로 표현하면 훨씬 간단하다. 단어가 2개, 4차원 embedding
Q, K, V 를 찾아내는 MLP가 있다고 생각하자. 이 MLP는 인코딩된 단어끼리 공유된다.
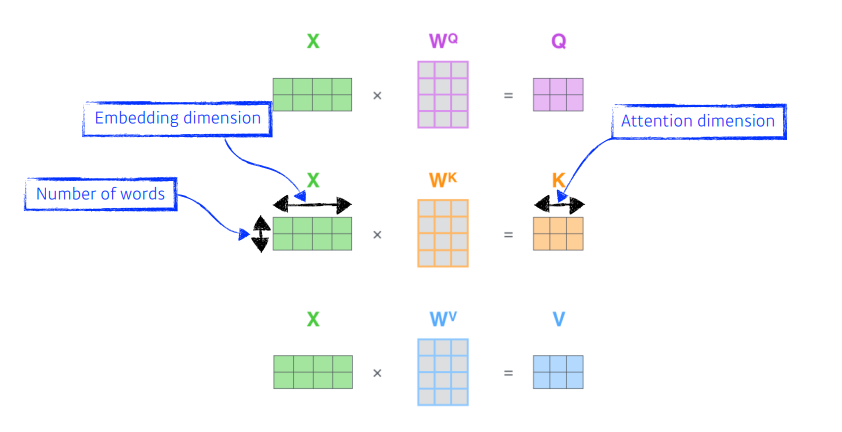
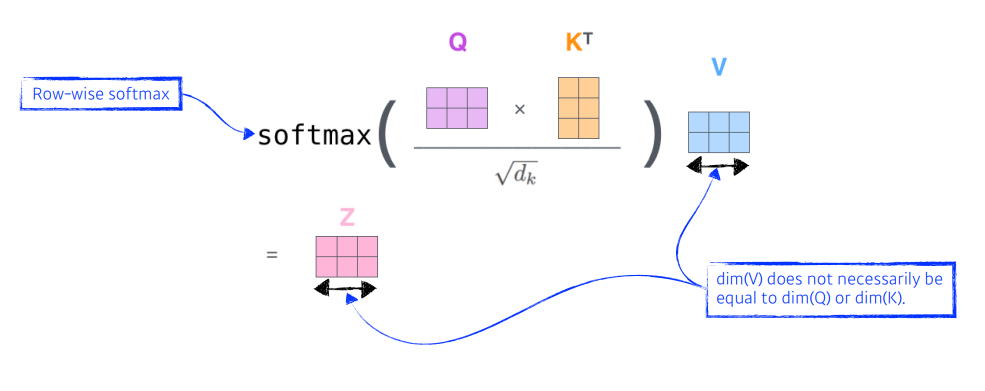
위에서 했던 과정을 행렬로 표현하면
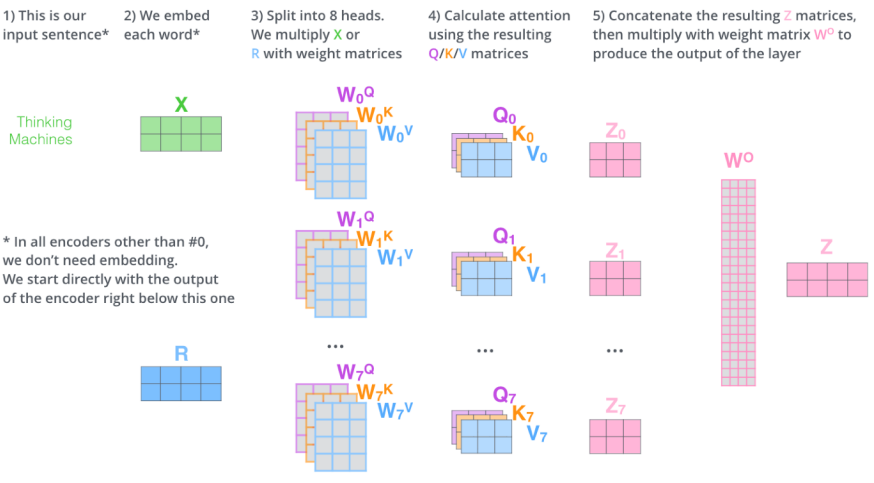
Multi-headed Attention
Multi-headed Attention :
Attention을 여러번 하는 것으로 하나의 입력or인코딩된 벡터에 대해 Q, K, V 를 여러개 만드는 것이다.
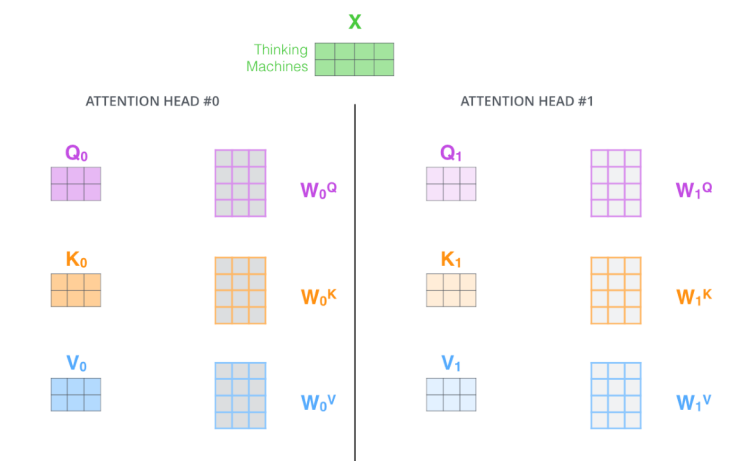
실제 Transformer 에서는 8개의 head가 사용 되고, 8개의 encoding 된 벡터이 나오게 된다.
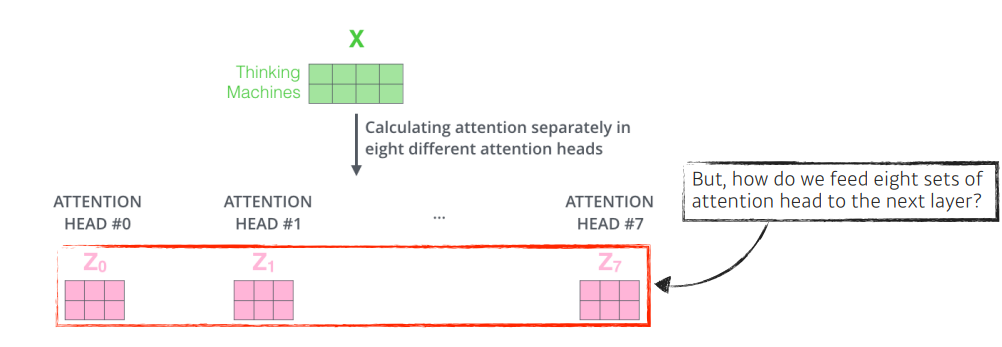
이때 입력과 출력 차원을 맞추기 위해 를 곱한다.
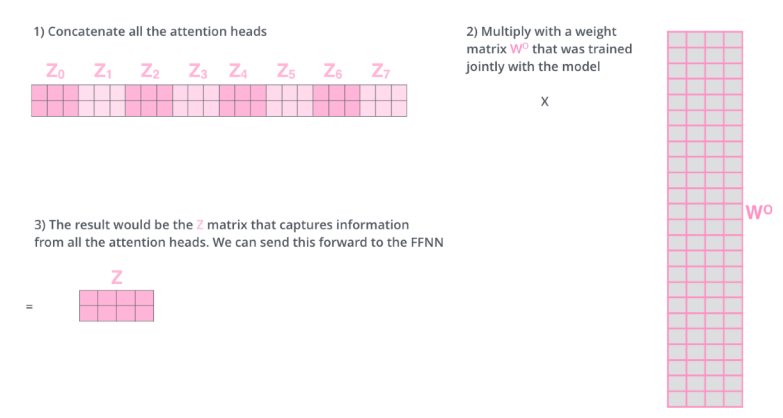
정리하면 다음 그림과 같다.
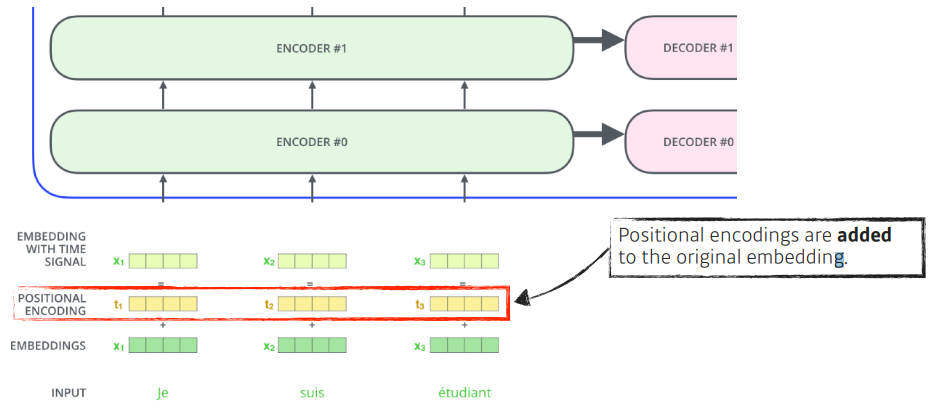
그리고 나서 Positional encoding을 더해주는데 일종의 bias로 보면 된다.
seqential 하게 input 한 것 같지만 sequence 정보가 포함되어 있지 않기 때문에 sequence 정보를 추가해 주는 것이다.
(예를들어 [a,b,c], [c,b,a]의 각각의 단어가 encoding된 값은 달라지지 않는다)
Reference
