이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Introduce
이 글에서는 Basic CNN 보다는 나은 CNN 모델들의 기본 개념과 어떻게 발전해왔는지에 다뤄보고자 한다.
앞선 글 에서 CNN이 어떤 식으로 발전해 왔는지 언급하였는데
Depth는 깊어짐Parameter 개수는 적어짐
이라고 하였는데 , 이 두가지 관점위주로 살펴보도록 하자.
ILSVRC 라는 대회의 12~15년도 우승작을 다룬다.
AlexNetVGGNetGoogLeNetResNetDenseNet
AlexNet(2012)
AlexNet은 이미지 분류 문제에서 DL의 시대를 연 모델이다.
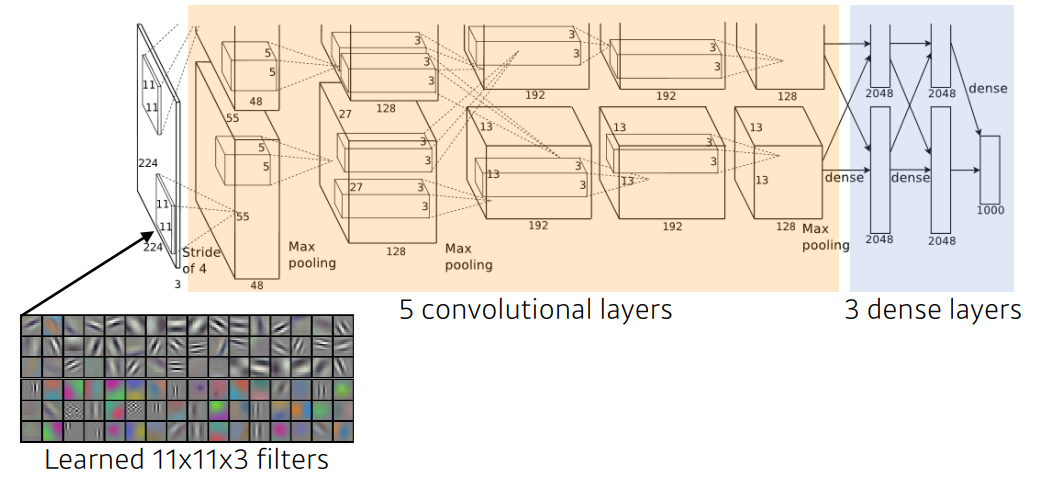
구조는 다음과 같다.
2개로 나눠지는 특징이 있는데 그 당시(2012)에는 GPU의 성능이 부족하여 2개로 나눈 것이라고 한다.
또한 11x11 kernal을 사용한 것을 볼 수 있는데 이는 사실 좋은 선택은 아니다.
kernal의 size 가 크기 때문에 Receptive Field(커널이 볼 수 있는 영역)은 커지지만 parameter 수 가 증가하기 때문이다.
Key Idea
- ReLU 사용
- Local response normalization, Overlapping Pooling
- Data augmentation
- Dropout
여기서 가장 중요한 Key Idea 는 활성화 함수에 기존의 sigmoid 나 tanh 가 아닌 ReLU를 사용한 것이다.
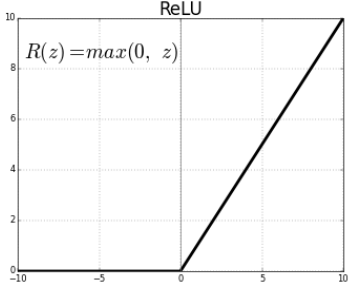
ReLU 장점
- Linear model 의 장점을 포함하고 있다.
- gradient descent로 최적화하기 쉽다.
- 일반화 성능이 좋다 (결과론적 얘기이긴 하지만)
- ★
ReLU기울기 소실 문제를 해결할 수 있었다. ★
VGGNet(2014)
VGGNet 모델
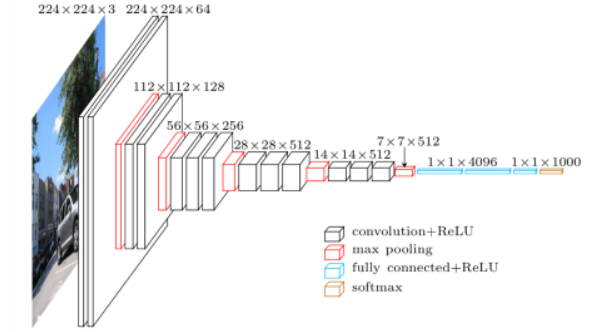
key Idea
- ★
3x3 Kernal만 사용★ - F.C 에
1x1 Convolution을 사용 - Dropout(p=0.5)
3x3 Kernal
3x3 kernal x2 한 것과 5x5 kernal x1 한 것을 비교해 보면 다음과 같다.
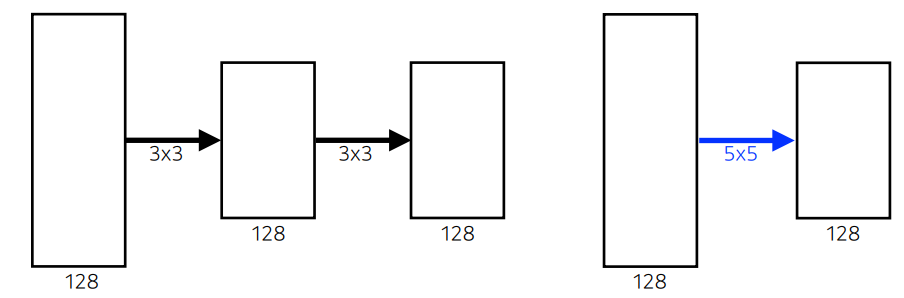
Receptive field 관점에서는 3x3 kernal x2 한 것과 5x5 kernal x1 은 같은 결과를 갖게 된다.
하지만 parameter 개수 관점으로 보rp 된다면
-
3x3 kernalx2 : (3x3x128x128) + (3x3x128x128) = 294,912 -
5x5 kernalx1 : 5x5x128x128 = 409,600
3x3 kernal x2 한 것이 더 적은 parameter 개수 를 가지게 된다.
작은 커널로 깊게 쌓는 것이parameter개수를 줄일 수 있다는 것을 의미한다.
GoogLeNet(2014)
우선 GoogLeNet 모델을 보면 다음과 같다.
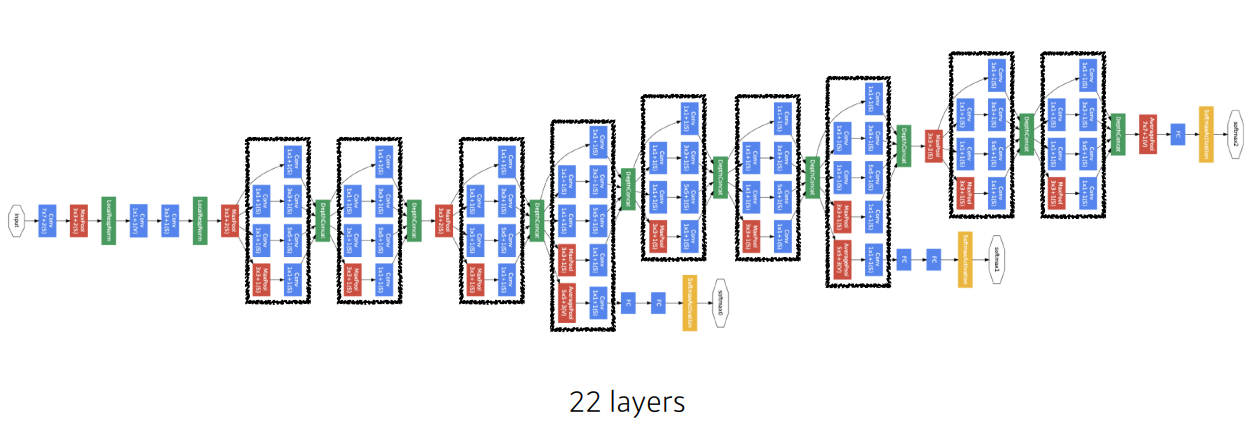
비슷한 네트워크 뭉탱이가 반복되는 것을 볼 수 있는데 이를 NiN(Network in Network) 라고 하고 GoogLeNet은 이를 Inception Block 과 결합한 형태이다.
Inception Block
Inception Block 은 노드간의 연결은 Sparse하게 하면서 Matrix연산은 Dense연산을 하도록 처리하는 Module이다.
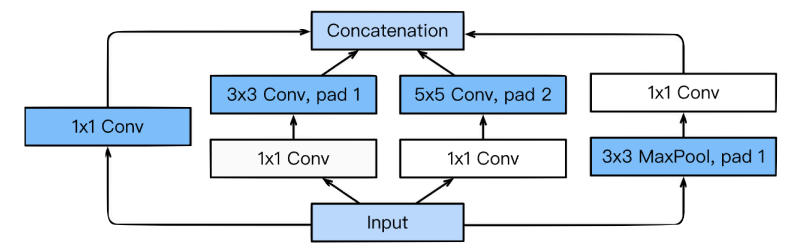
결론부터 말하자면 Inception Block 은 parameter 개수를 줄여준다.
어떻게 줄이는가에 대한 핵심은 1x1 convolution 이다.
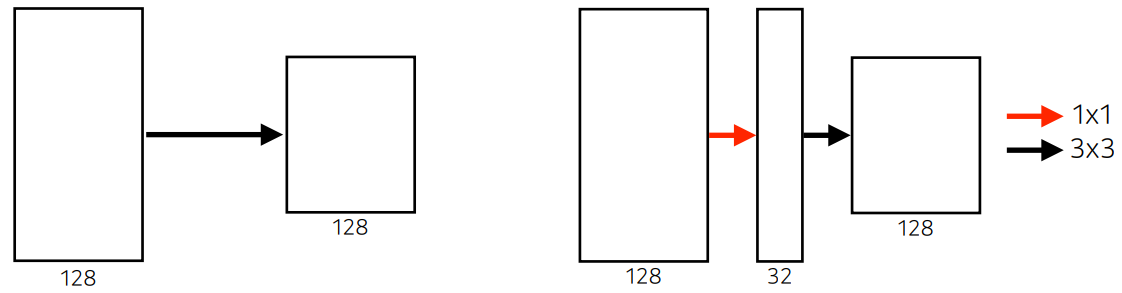
3x3 Convolution parameter 개수
3 x 3 x 128 x 128 = 147,456
3x3 Convolution 1x1 Convolution parameter 개수
1 x 1 x 128 x 32 = 4,096
3 x 3 x 32 x 128 = 36,864
4,096 + 36, 864 = 40,960
단순히 3x3 Convolution 한 것과 1x1 Convolution 을 추가한 것을 비교해 본다면
Receptive field , 입력과 출력의 채널 관점에서는 똑같지만, parameter 개수 는 줄은 것을 볼 수 있다.
ResNet(2015)
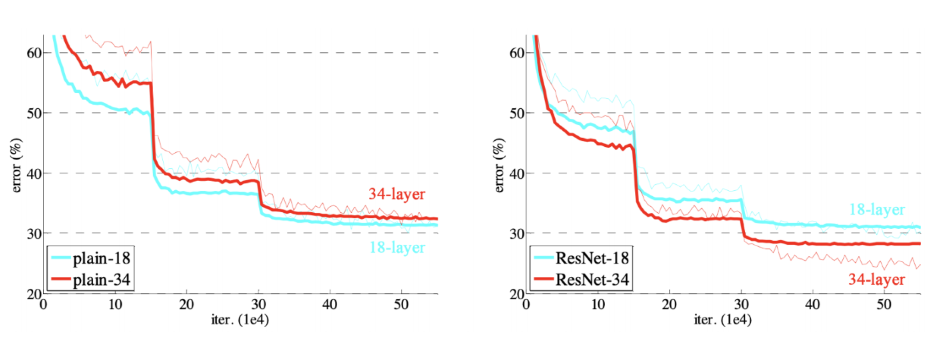
DL 에서 parameter 개수가 거대하면 과적합이 되는 문제가 있었다. VGG와 같은 architecture를 설계할 때 깊이가 너무 정도 깊어진다면 오히려 성능이 하락하는 결과가 나타난다.
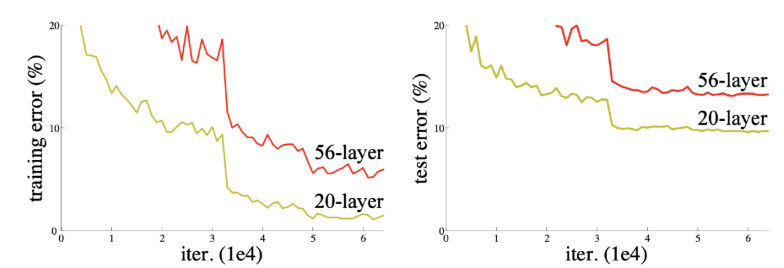
그래프에서 보는 것 처럼 더 깊게 쌓은 56-layer 이 학습과 테스트 모두 20-layer 보다 않좋은 성능을 보이고 있다.
Skip connection (identity map)
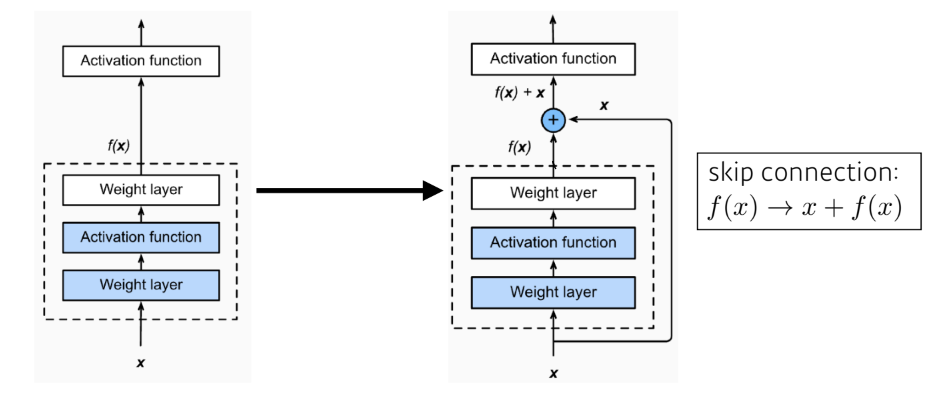
skip connections 몇 개의 layer를 건너 뛰어 연결해 non-linearities를 추가하는 방법으로
update를 안정화하고 기울기 소실 문제를 해결할 수 있다.
이에 따라 아래 그래프처럼 층을 안정적으로 깊게 쌓을 수 있다.
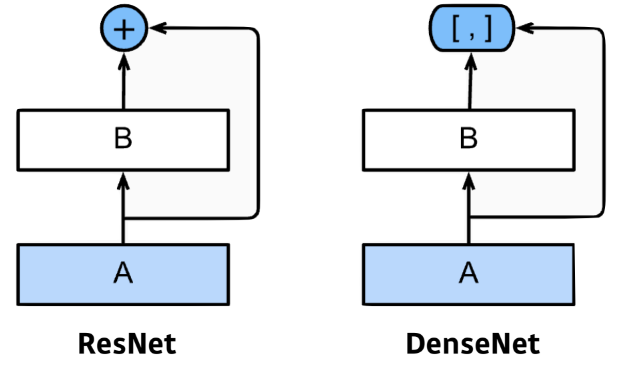
DenseNet
DenseNet 은 +(ResNet) 대신 concat을 하여 학습하는 모델이다.
이렇게 하면 아래 그림처럼 채널이 Layer를 거칠수록 기하급수적으로 늘어나게 되고, 커널의 채널이 늘어나면서 결과적으로 parameter 개수 도 기하급수적으로 늘어나게 된다.
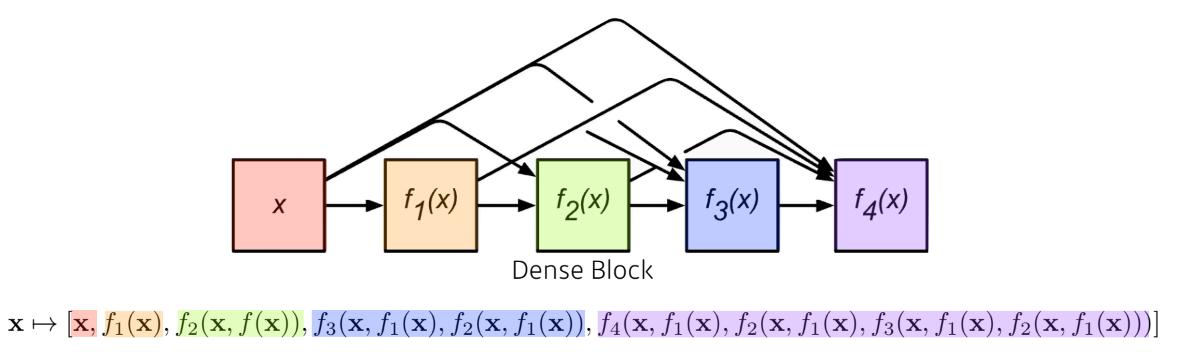
이에대한 해결방법으로 Dense Block 으로 concat 된 것을 Transition Block으로 다시 채널을 줄여서 학습하게 된다.
Transition Block: [Batch norm->1x1Conv->2x2AvgPooling]

한줄정리
-
VGG:receptive field를 더 많이 보고 싶으면3x3Conv를 반복해라. -
GoogLeNet:1x1 Conv를 통해채널수를 줄여parameter 개수를 줄이자. -
ResNet:skip-connection을 통해 깊게 쌓아도 학습이 잘되도록 하자. -
DenseNet:concat을 통해 쌓으면서 깊게 할 수 있게 하자.
