이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Regularization
이 글에서는 Neural Network을 최적화 하기위한 Regularization(정규화) 에 대한 주요 용어의 concept를 알아보도록 하자.
보통 Regularization 은 일반화(generalization) 가 잘되도록 하기 위한 것으로 학습을 방해(제약을 주어서)하여 test 시에도 잘되도록 하는 것을 의미한다.
하지만 학습에 제약을 준다는 concept은 크게 신경 쓰지 않고, 일반화 성능을 높이기 위한 기법이라고 생각하는게 맘이 편해질 것이다.
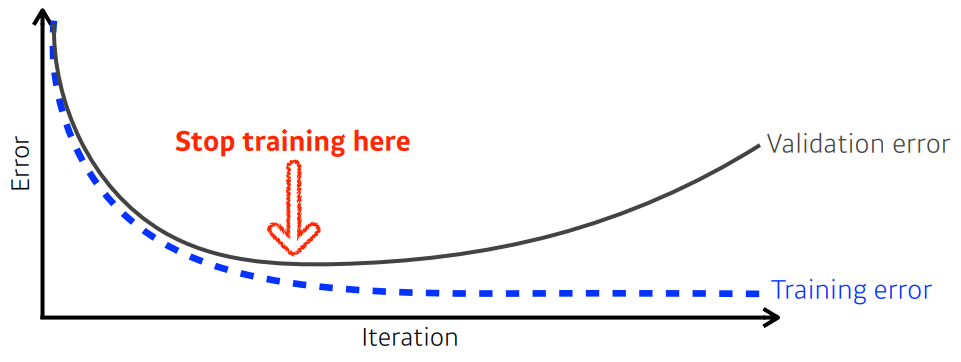
Earlystopping
학습을 너무 많이 시키면
과적합(Overfitting)이 일어나면서 train 성능은 좋아지지만, test 성능은 나빠지는 경우가 발생한다.
이를 방지하기 위해 과적합이 일어나는 것 같으면 모델의 학습은 일찍 멈추는 것을 뜻한다.
Parameter Norm Penalty (Weight Decay)
에 관해서 최대한 부드러운 함수를 만드는 것이 일반화가 잘될 것이다.
즉, 를크기관점에서 작게하는게 좋다.
이를 구현하기 위해Loss Function에 의 크기 항을 추가하여 의 크기도 작게하는 방향으로 학습하게 한다.

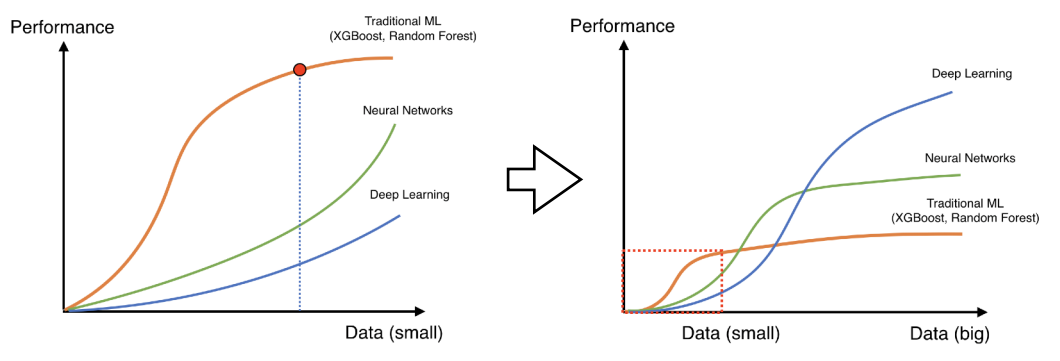
Data Augmentation
데이터가 많이 없으면, 기존의
ML 기반 모델이 더 성능이 좋다.(DL은 안될 가능성이 높다)
반대로 데이터가 많으면, 기존의ML 기반 모델은 표현력이 떨어지게 되고,DL의 성능이 올라간다(DL은 데이터가 많을수록 표현력이 좋다)
따라서 성공적인DL을 위해서는 데이터를 많이 넣는게 좋은데, 현실적으로 어려운 경우가 많기 때문에 데이터를 살짝 변형하여 데이터를증강(Augmentation)시킨다.
대표적인 예로CV에서는 이미지를 그림과 같이 변형해서 데이터를 늘린다.
Noise Robustness
Augmentation의 개념과 비슷하다.
random noise를input 데이터와weights(신경망의 weight) 에 추가한다.
일반적으로 성능이 더 잘나온다는실험적인 결과가 있다. 왜 더 결과가 좋은지는 잘 알려져 있지 않다.

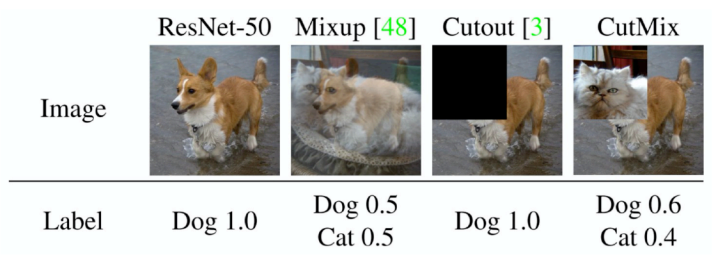
Label Smoothing
분류문제에서 label을 섞는 것을 의미한다.
Mix-up과CutMix등이 있다. 그림으로 이해하면 빠르다.
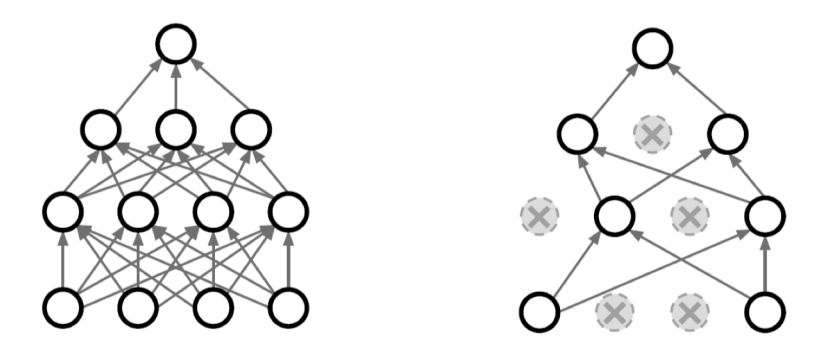
Dropout
랜덤하게
neuron을 선택하여Drop시켜서 학습한다.
(여기서Drop이란 0으로 만들어 버리는 것을 뜻한다)
Batch Normalization
각
Batch를 해당Batch의평균을 빼고 과분산(정확히는표준편차) 로 나눠서정규화를 시키는 것을 뜻한다.
분류문제에서 일반적으로 성능이 올라간다.
해석적으로 생각하는 것은 하지 말도록 하자. . .
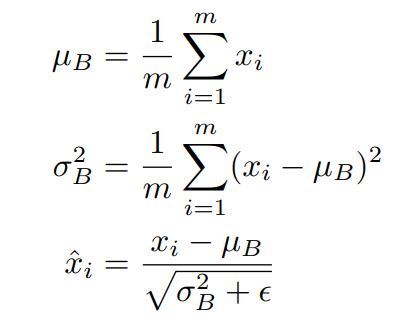
참고적으로 이 개념을 소개한 논문의 제목에서 Internal Covariate 라는 표현이 논란이 있다고 한다.
하지만 성능이 올라간다는 것은 다들 동의하더라. . .
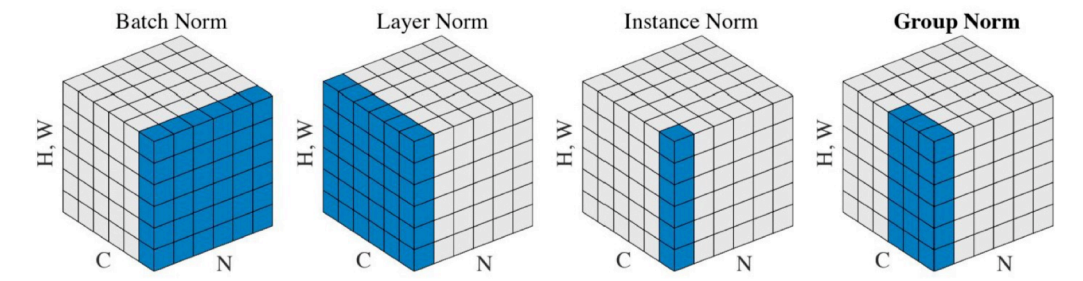
Batch Norm외에도Layer Norm,Instance Norm,Group Norm도 있다.