embulk

데이터를 전송하는 오픈 소스 Bulk Data Loader.
ETL에서 Transformation 외에 Extraction, Loading 에서 여러 plug-in을 제공.
특징
- Input file format을 자동으로 인식
- 병렬, 분산 수행 가능
- Transaction Control
- Resuming
- RubyGem 기반
MySQL(Cloud SQL) <> BigQuery 간에 embulk를 통해서 데이터를 export/import 해볼 것이다.
사전 작업
- Cloud SQL - MySQL 인스턴스 생성
- BigQuery 데이터 세트 생성
- Service Account 생성 후 JSON 키 다운
미리 콘솔에서 MySQL DB 생성
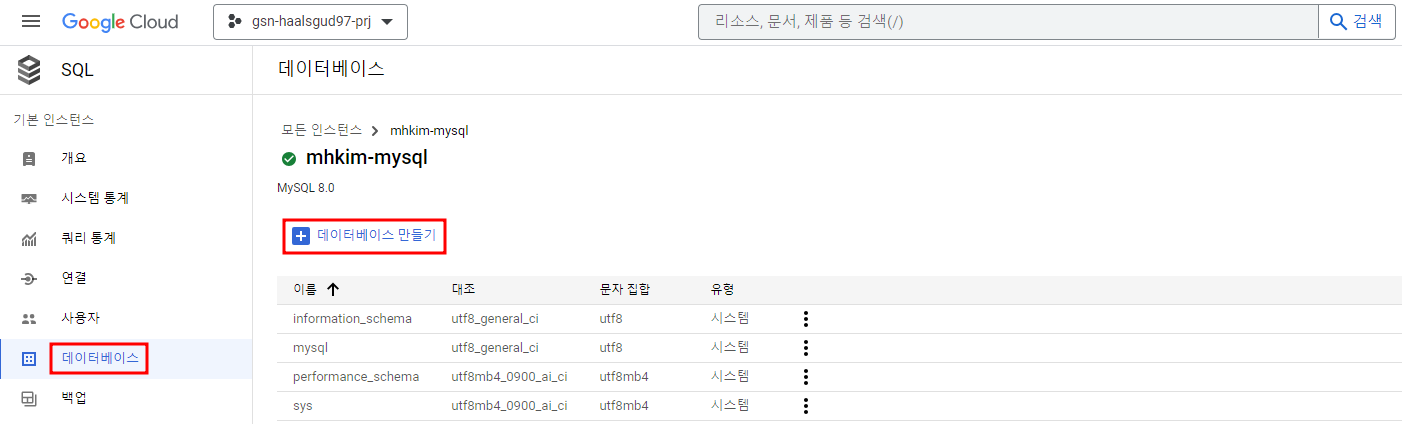

Cloud SQL은 기본적으로 All deny. 연결할 네트워크 대역을 추가해줘야 한다.
VM 서버를 띄워서 작업을 진행한다고 하면 VM의 public ip, 로컬이라면 로컬 PC ip를 네트워크에 추가
embulk 설치
embulk.org를 보면 설치 명령어가 잘 나와있지만 여기선 조금 다르게 설치해줄 것이다.
이유는 아래와 같다.


위 사진들은 공식 홈페이지에 나와있는 것. v0.10은 개발 시리즈라고 나와있었고 실제로 설치해본 결과, embulk는 자바가 설치되어 있어야 하는데 openjdk와의 호환성에서도 문제가 있어 제대로 embulk가 실행되지 않았었다.
embulk 설치 명령어 중 첫째 줄에 아래 명령어를 실행하라고 나와있을 것이다.
curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"명령어를 보면 알겠지만 이는 embulk-latest.jar 즉, 가장 최신버전을 설치하는 명령어이므로 자연스레 v0.10 시리즈로 설치된다.
떄문에 과거 안정 버전이라고 나와있는 0.9.25 버전으로 설치해줄 것이다.
자바 설치
sudo apt update
sudo apt install openjdk-8-jre-headlessembulk 설치
embulk v0.9.25 링크에서 embulk-0.9.25.jar를 사용하여 설치
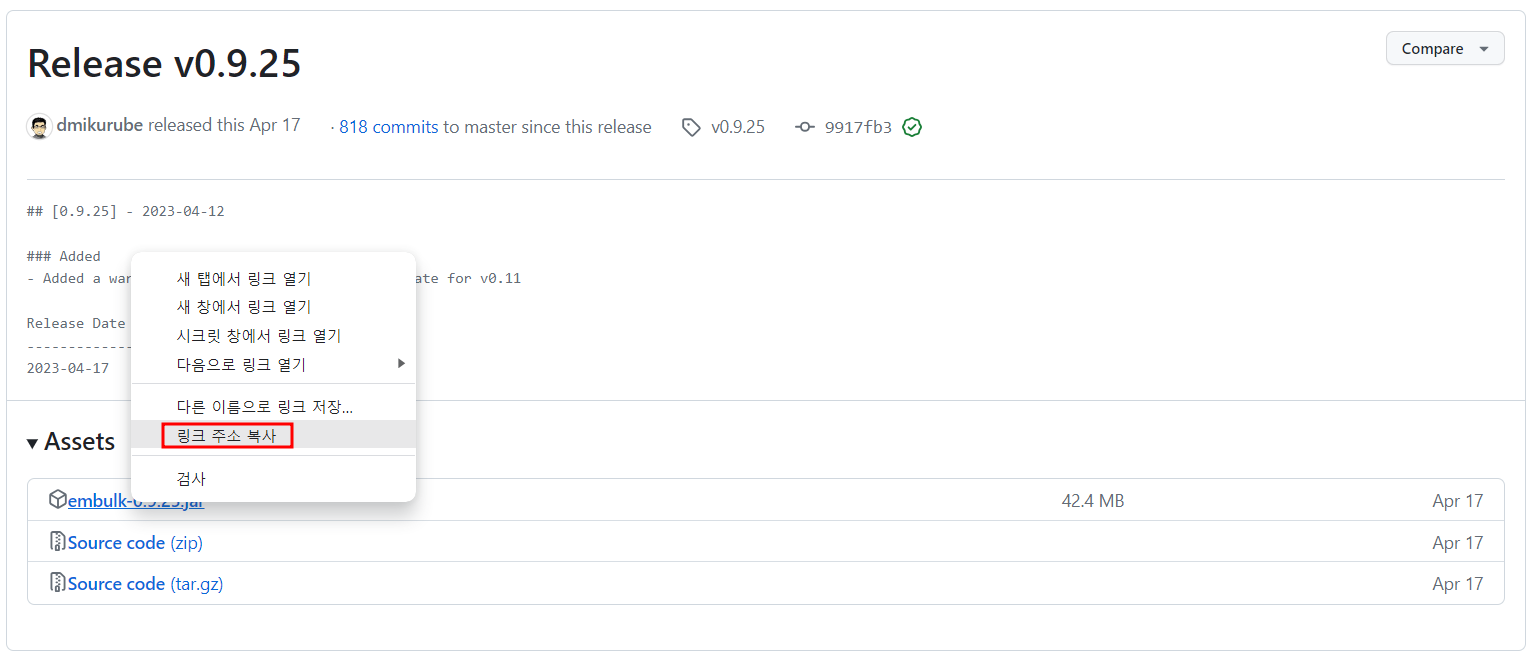
curl --create-dirs -o ~/.embulk/bin/embulk -L "<복사한 링크 주소>"
chmod +x ~/.embulk/bin/embulk
echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
# 버전 확인
embulk -version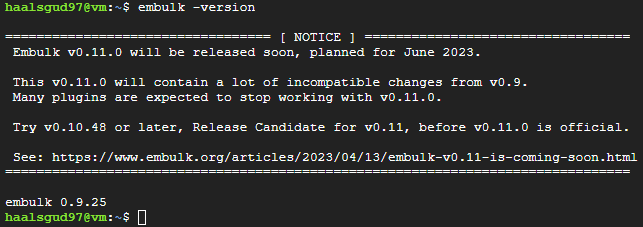
하지만 자신의 Java Version 및 사용할 플러그인에 따라 개인차가 있을 수 있으므로 우선 공식 홈페이지의 명령어를 따라 최신 버전으로 설치해보고 문제가 있을 경우 위의 방법으로 설치해보길 권한다.
플러그인 설치
embulk는 다양한 플러그인을 지원하는데 여기선 여기서 작업할건 1. BigQuery > MySQL, 2. MySQL > BigQuery 이므로 MySQL, BigQuery에 관한 플러그인을 설치해야 한다.
# BigQuery > MySQL을 위한 플러그인
embulk gem install embulk-input-bigquery # BigQuery에서 데이터를 읽기 위한 플러그인
embulk gem install embulk-output-mysql # MySQL에 데이터를 넣기 위한 플러그인
# MySQL > BiQuery를 위한 플러그인
embulk gem install embulk-input-mysql # MySQL에서 데이터를 읽기 위한 플러그인
embulk gem install embulk-output-bigquery # BigQuery에 데이터를 넣기 위한 플러그인하지만 embulk v0.9.25이면 위 명령어를 그냥 실행시 BigQuery 관련 플러그인을 설치할 때 에러가 날 것이다.
이유는 emulk-output-bigquery가 의존하는 jwt의 버전이 22년 6월 6일 부로 올라가면서 요구하는 Ruby 버전이 기존 2.1에서 2.5로 올라간 것이 원인.
하지만 내가 설치한 embulk 0.9.25에 들어 있는 Ruby는 2.3 버전이므로 2.5를 요구하는 jwt의 설치에 실패했다는 것.
아래 명령어 두개를 먼저 수행 후 위의 플러그인 설치
embulk gem install jwt:2.3.0
embulk gem install public_suffix -v 4.0.7BigQuery to MySQL
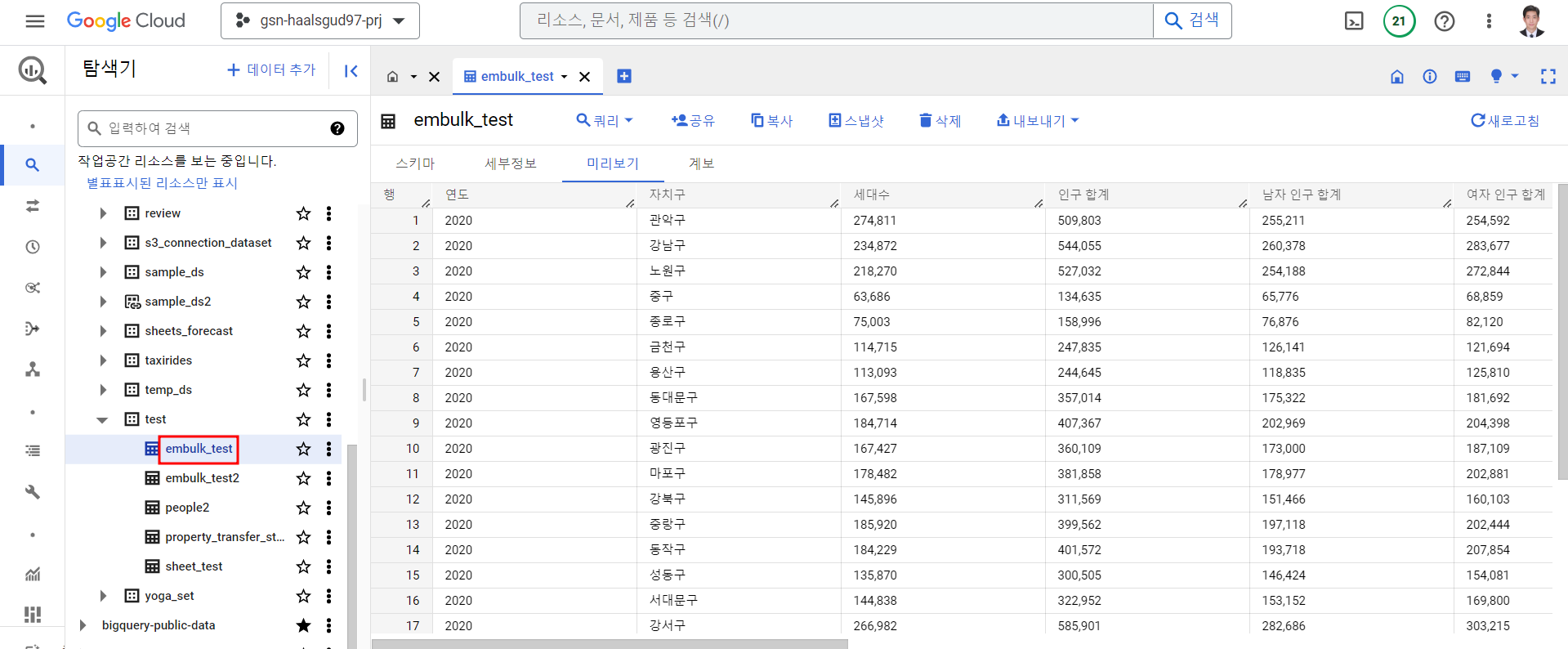
BigQuery to MySQL에선 갖고 있는 '서울시 주민등록 인구' 공공 데이터를 활용할 것이다.
해당 csv 파일을 통해 BigQuery 테이블 생성

확인
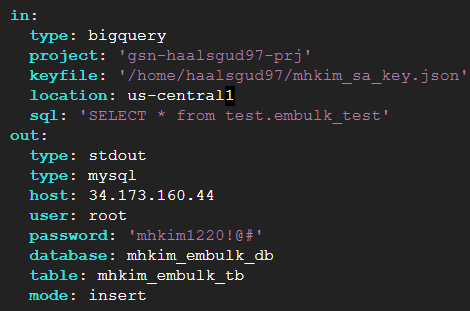
bq-to-mysql.yml
in:
type: bigquery
project: <프로젝트명>
keyfile: <서비스 계정 키파일 경로>
location: <데이터셋 리전>
sql: 'SELECT * from test.embulk_test' # 읽어들일 데이터 쿼리
out:
type: stdout
type: mysql
host: <mysql ip>
user: root
password: <root 유저 비밀번호>
database: <만들어둔 DB명 입력>
table: <생성할 테이블명 입력>
mode: insert예시 코드
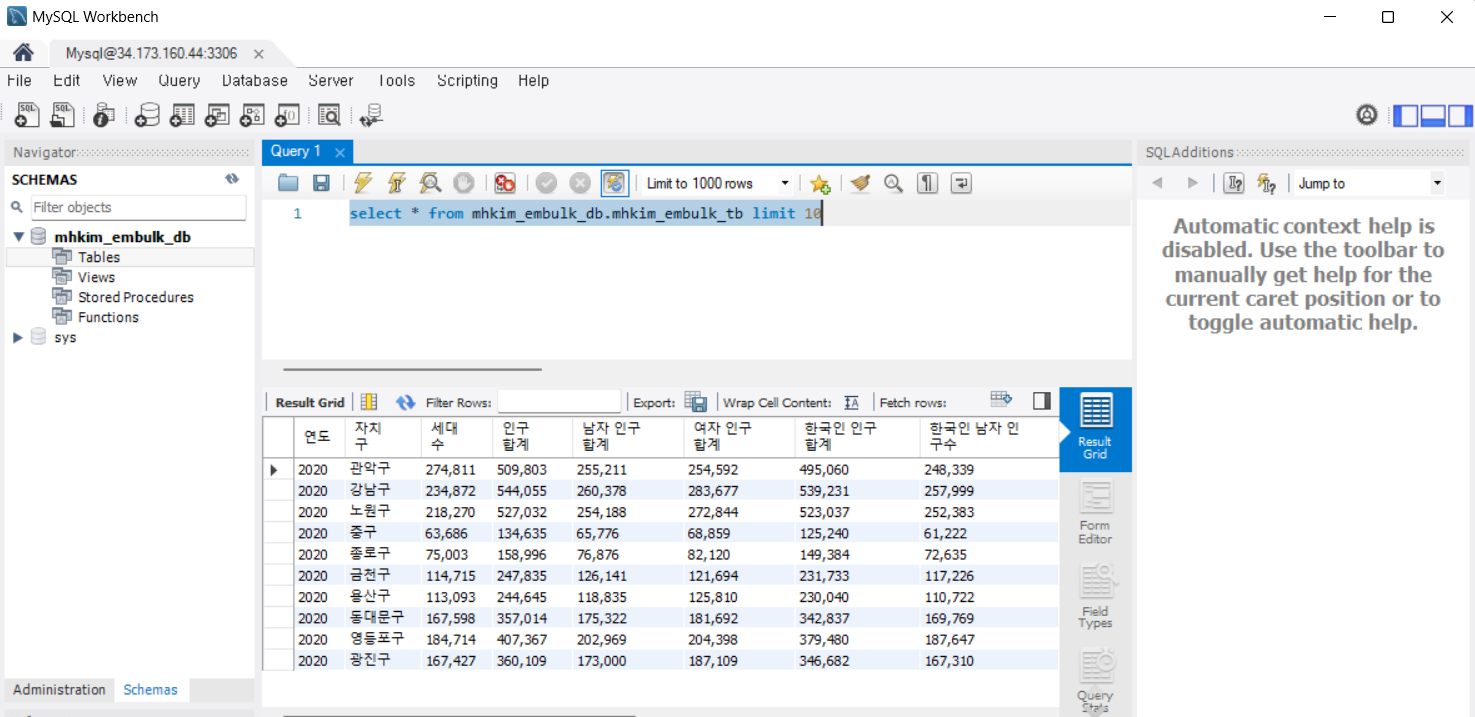
실행
embulk run bq-to-mysql.ymlMySQL Workbench를 사용하여 확인 (직접 DB에 접속해서 확인해도 상관x)
MySQL to BigQuery
기존에 서비스 계정 생성시 부여한 권한을 소유자 권한이었으면 상관이 없지만 편집자 권한 혹은 그 이하 수준의 권한을 부여했으면 이 작업이 실패할 것이다. 이전에 BigQuery > MySQL 작업에서 BigQuery의 데이터를 읽어들인 후 MySQL에 쓰는 것은 필요한 권한이 편집자 권한만으로도 충분했다. 하지만 테이블을 생성하고 BigQuery에 데이터를 로드하기 위해선 BigQuery Admin 권한이 반드시 있어야 한다. 때문에 서비스 계정의 권한을 확인하여 BigQuery Admin 권한이 있는지 확인해야 한다. 이 문제 때문에 작업이 실패하면 아래와 같은 에러가 뜰 것이다.
Error: org.jruby.exceptions.RaiseException: (Error) failed to load
...
response:{:status_code=>404, :message=>"notFound:
...
error_class=>Google::Apis::ClientError}
사용할 데이터는 '유가 정보(2019년 상반기)' 공공 데이터
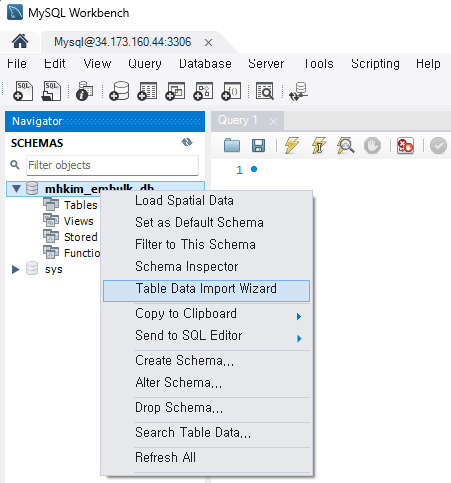
사실 테스트 목적이므로 테이블을 직접 생성하고 데이터도 쿼리문으로 간단하게 넣어줘도 되지만 귀찮아서... 갖고 있는 csv파일을 MySQL Workbench 기능을 활용해서 테이블에 import해줄 것이다.
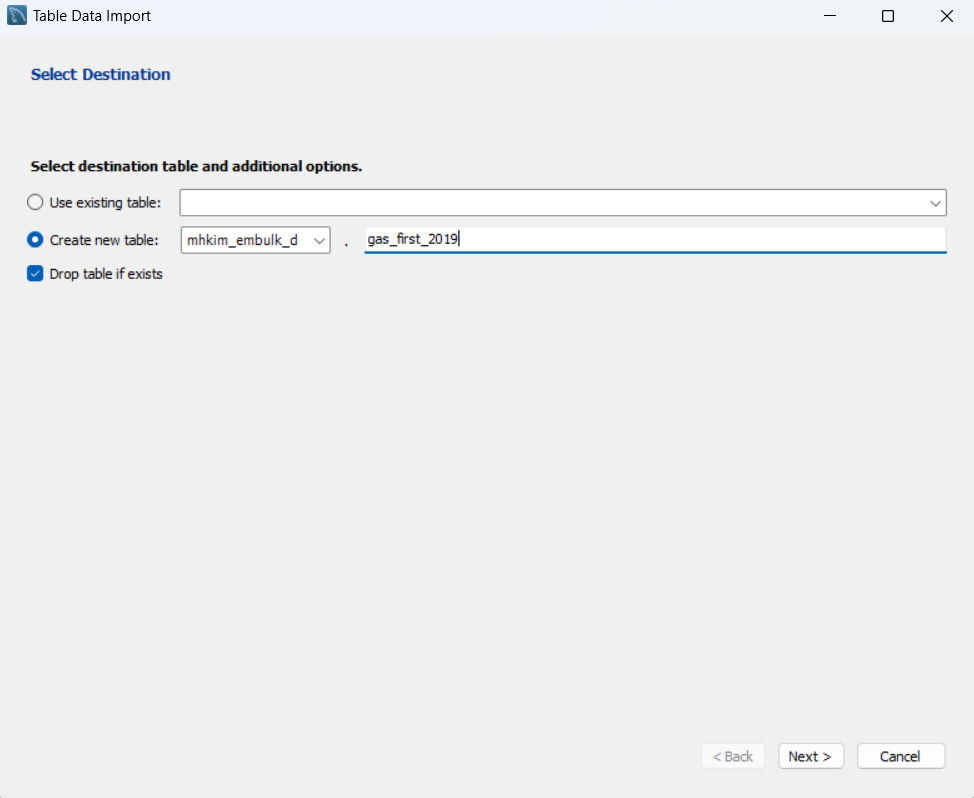
DB에 우클릭하여 Table Data Import Wizad 클릭
생성할 테이블 명 입력
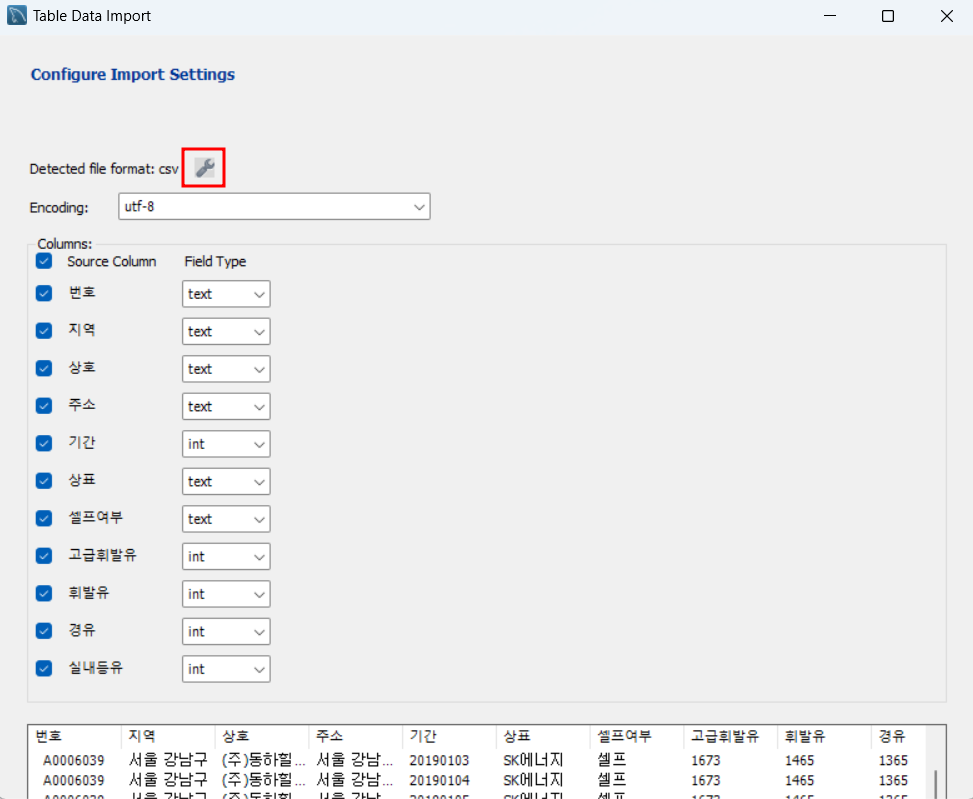
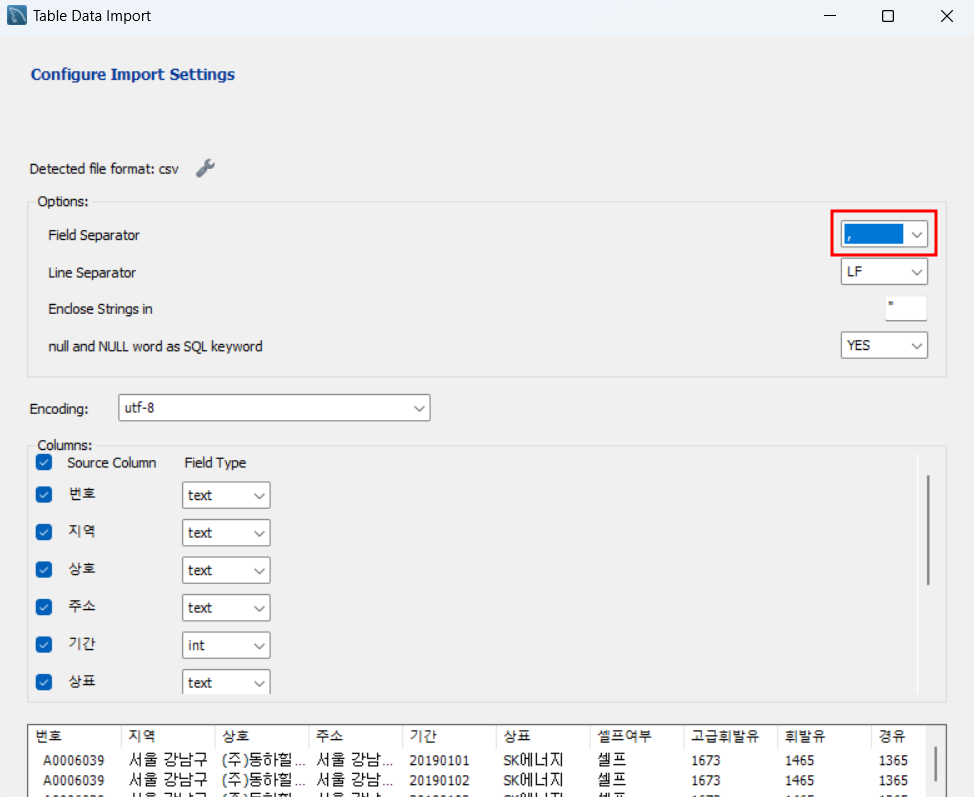
설정에서 csv파일이므로 구분자를 ,로 변경
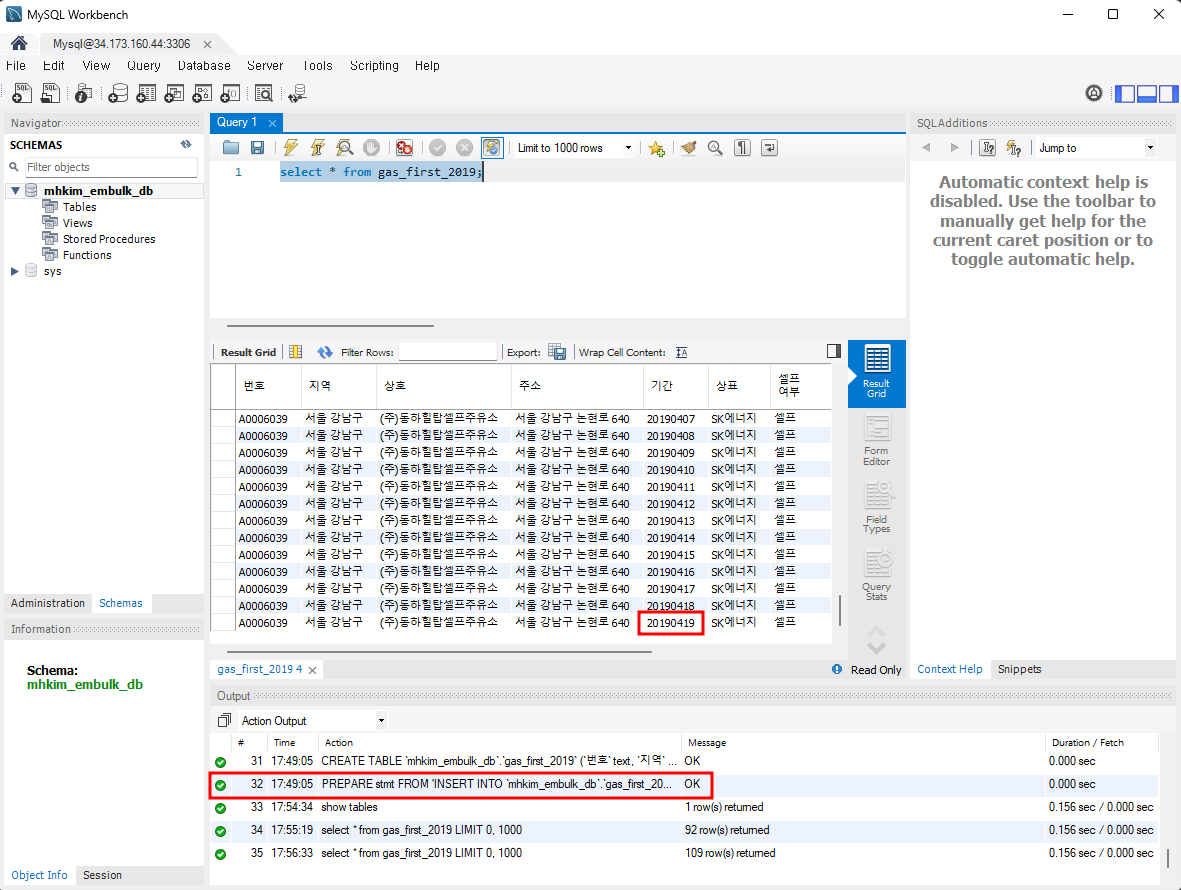
확인
하지만 이대로 BigQuery에 넣으려고 하면 아래와 같은 에러가 날 것이다.
이유는 컬럼명이 한글이라.. 혹은 띄어쓰기가 있는 경우도 아래의 에러가 난다.
Error: org.jruby.exceptions.RaiseException: (Error) failed during waiting a Copy job, get_job
...
[{:reason=>"invalid", :message=>"Table gsn-haalsgud97-prj:test.LOAD_TEMP
...
with flexible column name “<띄어쓰기나 한글이름의 컬럼명>” does not support table copy."}
해당 테이블 우클릭하여 Alter Table 작업 수행
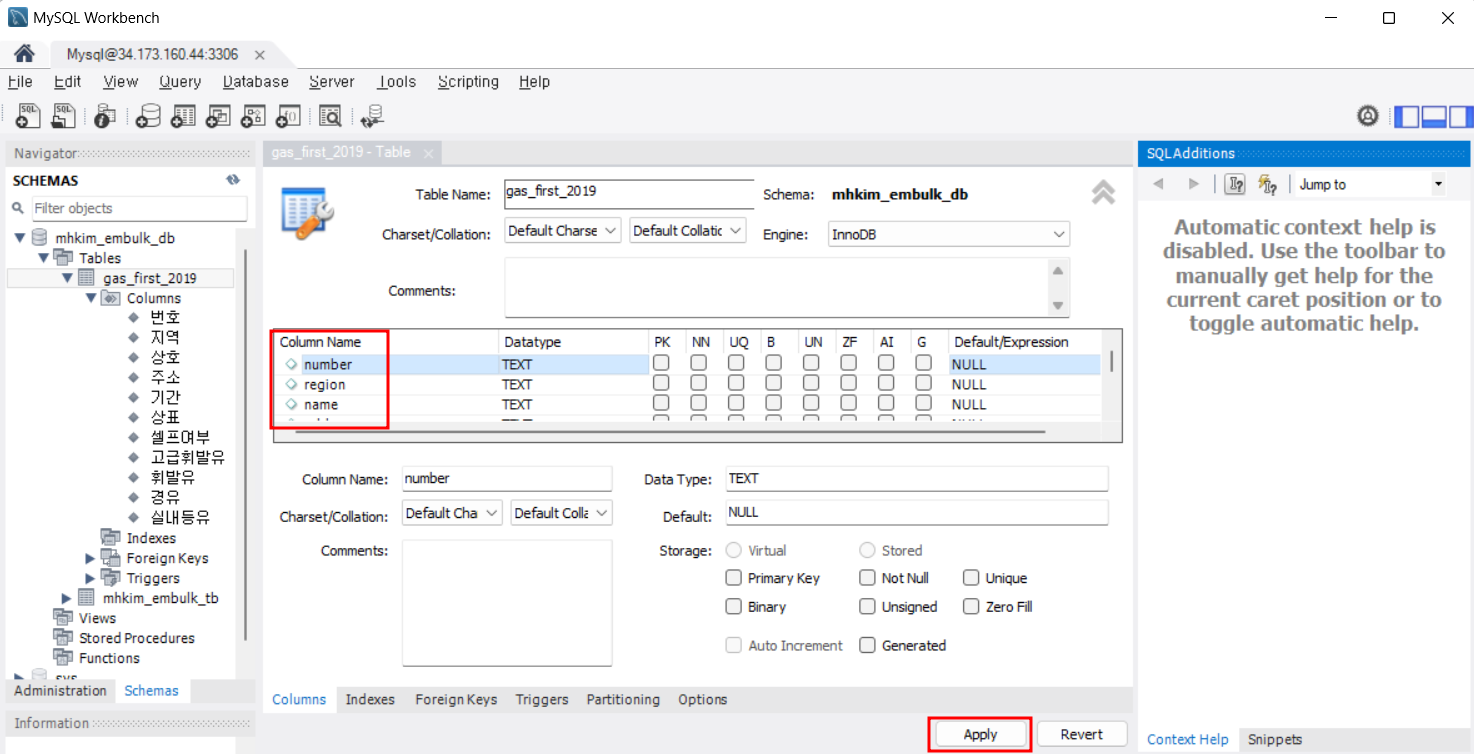
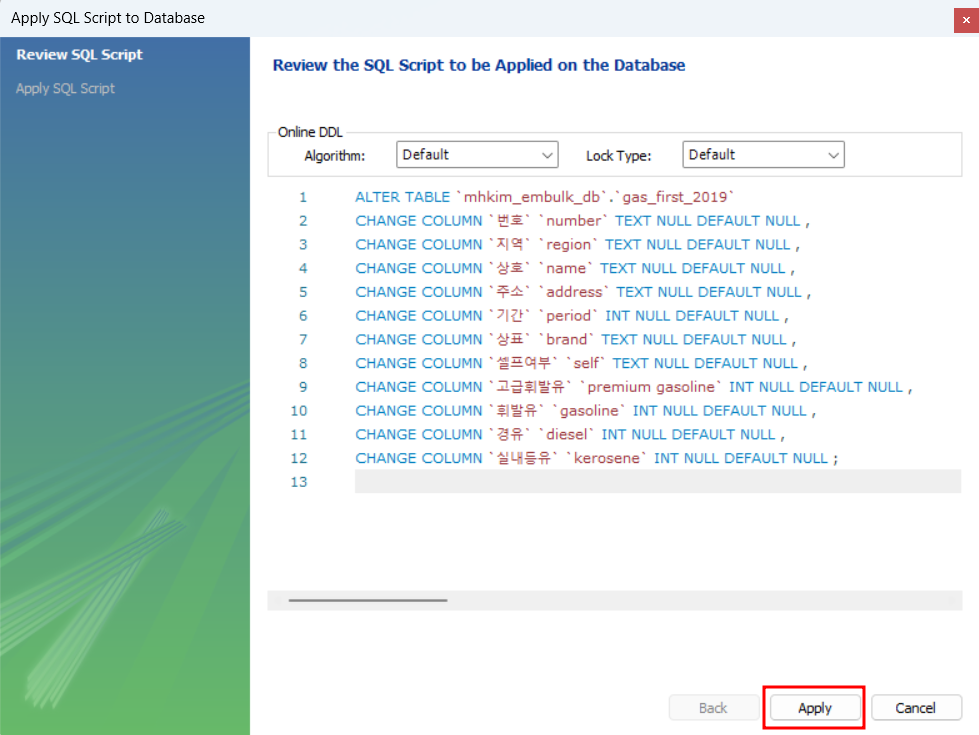
영문으로 모두 변경
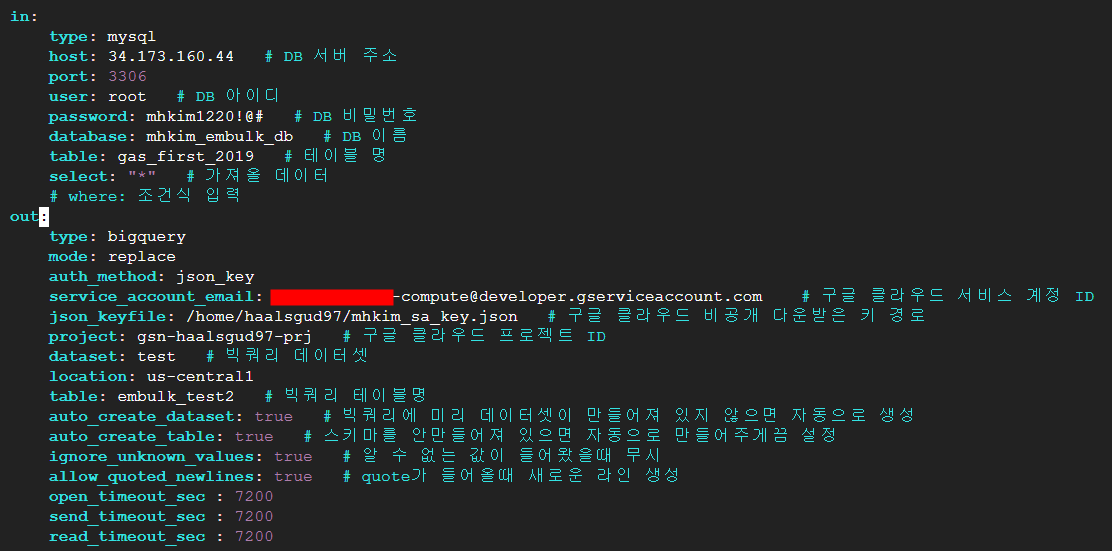
mysql-to-bq.yml
in:
type: mysql
host: <mysql ip>
port: 3306
user: root
password: <root 유저 비밀번호>
database: <DB명>
table: <테이블명>
select: "*" # 읽어들일 데이터 쿼리
# where: <조건식 입력>
out:
type: bigquery
mode: replace
auth_method: json_key
service_account_email: <서비스 계정 이메일>
json_keyfile: <서비스 계정 키파일 경로>
project: <프로젝트명>
dataset: <데이터셋명>
location: <데이터셋 리전>
table: <BigQuery에 생성할 테이블명>
auto_create_dataset: true # 빅쿼리에 미리 데이터셋이 만들어져 있지 않으면 자동으로 생성
auto_create_table: true # 스키마를 안만들어져 있으면 자동으로 만들어주게끔 설정
ignore_unknown_values: true # 알 수 없는 값이 들어왔을때 무시
allow_quoted_newlines: true # quote가 들어올때 새로운 라인 생성
open_timeout_sec : 7200
send_timeout_sec : 7200
read_timeout_sec : 7200예시 코드
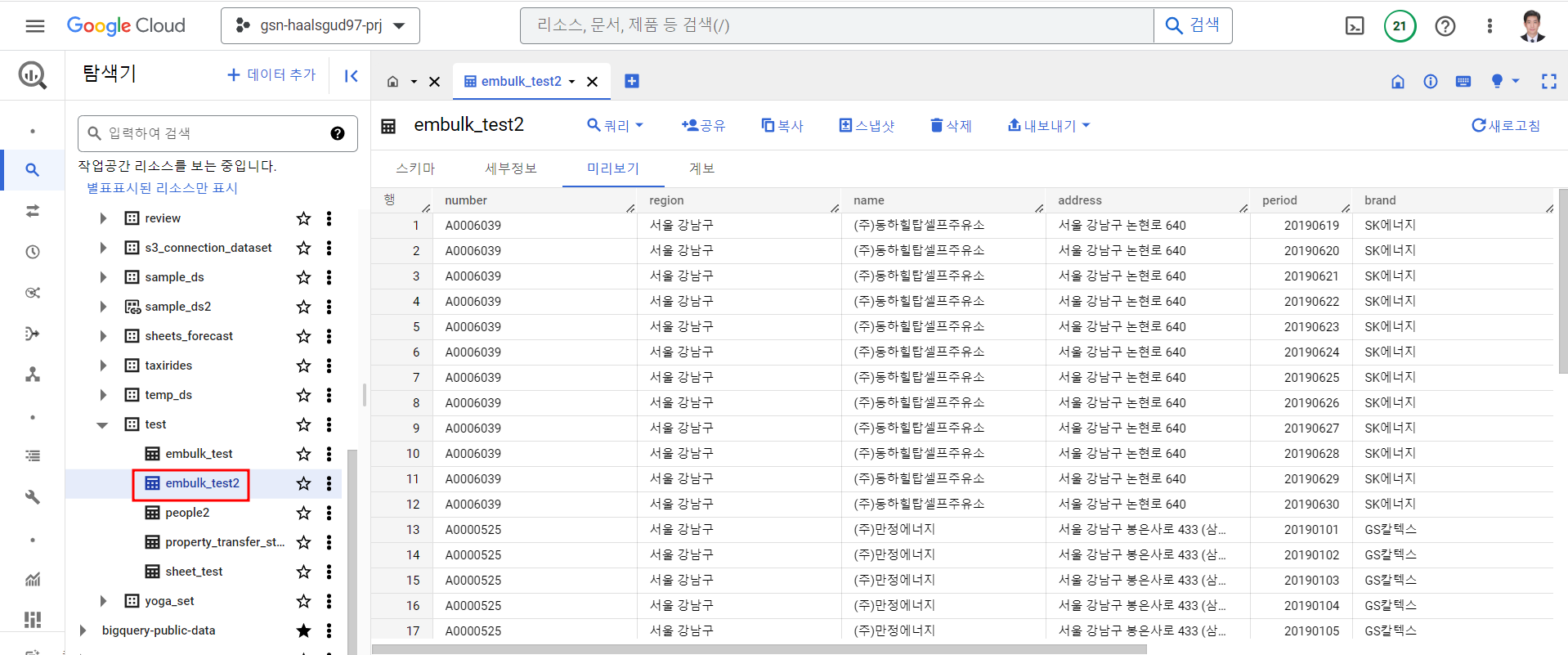
실행
embulk run mysql-to-bq.yml확인
[embulk 사용 참고]
- https://www.kangtaeho.com/61
- https://tora-it-kingdom.tistory.com/5
- https://thewayitwas.tistory.com/434
[embulk output-to-bigquery 플러그인 설치 트러블 슈팅 참고]
