HDFS란?
하둡 분산 파일 시스템(Hadoop Distributed File System)
기존에도 parallel computing이라는 단어가 있지만 이 단어는 보다 cpu로 병렬처리를 한다는 것에 좀 더 초점을 둔 용어 distributed는 data에 좀 더 초점을 둔 용어
- 데이터를 분산하고 분산된 데이터를 처리하는 건 distributed computing
- 데이터를 cpu 코어 수나 메모리를 여러 개로 나눠서 처리하는 것은 parallel computing
구글 플랫폼의 철학
- 한대의 고가 장비보다 여러 대의 저가 장비가 낫다
- 데이터는 분산 저장한다
- 시스템(H/W)은 언제든 죽을 수 있다 (Smart S/W)
- 시스템 확장이 쉬워야 한다
하둡 특성
수천대 이상의 리눅스 기반 범용 서버들을 하나의 클러스터로 사용
- 마스터-슬레이브 구조
- 파일은 블록(block) 단위로 저장
- 블록 데이터의 복제본 유지로 인한 신뢰성 보장(기본 3개의 복제본)
- 높은 내고장성(Fault-Tolerance)
- 데이터 처리의 지역성 보장
하둡 클러스터 네트워크 및 데몬 구성
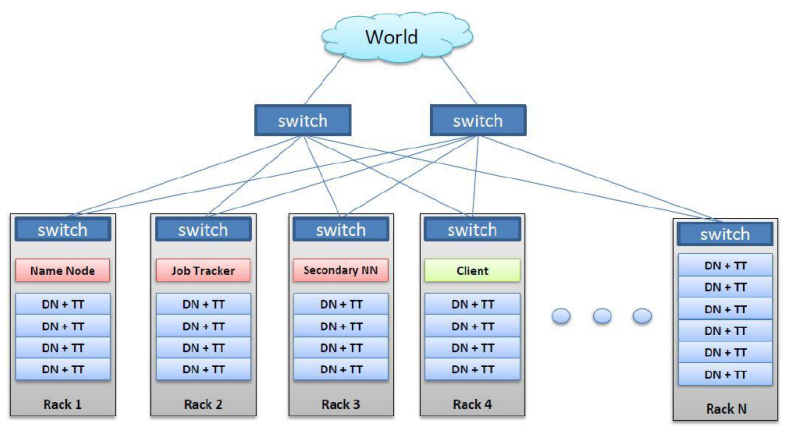
빨간색이 master, 파란색이 slave
DN은 Data Node, TT는 Task Tracker
하둡 블록
default로 128, 용량을 변경할 수 있다.
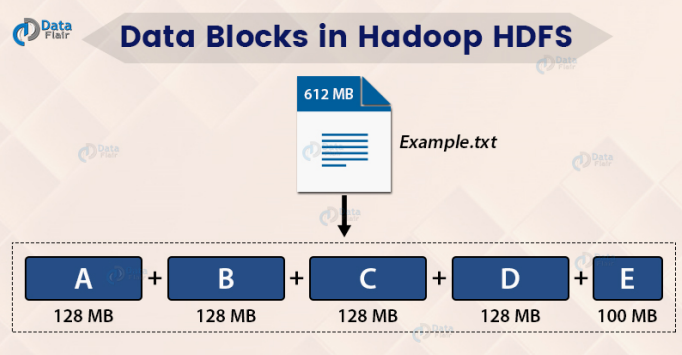
- 하나의 파일을 여러 개의 Block으로 저장
- 설정에 의해 하나의 Block 은 64MB 또는 128MB 등의 큰 크기로
나누어 저장 - 블록 크기가 128MB 보다 적은 경우는 실제 크기 만큼만 용량을 차
지함
HDFS 데이터 저장 구조

그렇다면 hadoop은 데이터 유실을 하지 않나?
3개의 데이터 노드가 거의 동시에 장애가 나면 데이터 유실을 할 수 있다.
이러한 상황이 아닌 이상 거의 유실이 나지 않는다.
데이터 센터 자체가 장애가 나지 않는 이상 보통 하둡 클러스터 자체에 문제가 있어서 블록이나 데이터를 유실하는 경우는 거의 없다...
하둡은 replication으로 인해 원래 갖고 있는 데이터 사이즈보다 3배나 용량을 써야 한다
하지만 그럼에도 불구하고 비용적인 측면을 계산해보면 기존의 상용 스토리지보다 훨씬 싸다.
(디스크도 SATA 디스크를 사용하는 등.. 한대의 고가 장비보다 여러 대의 저가 장비가 낫다는 구글 플랫폼의 철학이 반영된 솔루션이기 때문)
1PB를 저장해야 된다고 하면 기존 스토리지 솔루션으로 견적을 산출하고, Hadoop 클러스터로 비용을 산출한 후 비교해보면 비교가 되지 않는다.
데이터가 크리티컬하지 않고 그렇게 중요한 데이터가 아니라고 하면 replication을 2로 놓고 운영하는 방법도 있다.
스펙, 클러스터 운영
데이터 노드 하나에 메모리를 크게 잡는다. 그 이유는?
요새는 ETL 처리를 스파크로 많이 한다.
스파크는 대부분 메모리 베이스. 때문에 보통 노드 하나에 적게는 128GB 많게는 256GB의 메모리를 가진다.
반면 cpu는 보통 안좋은걸 쓰는 경우가 많다.
(가장 저가이면서 효율적인 cpu모델 선택)
코어 수는 요새 나오는 서버들은 하이퍼스레딩을 지원해서 물리적인 코어는 보통 16개, virtual core까지 하면 32
데이터 노드의 디스크는 많이 구성할 수도 있고 적게 구성할 수도 있는데 데이터 노드를 보통 여러개 구성한다.
너무 큰 디스크 하나를 사용하면 성능 측면에 안좋은 면이 있기 때문.
데이터 디스크는 적게는 6개, 많게는 12개를 쓰고 보통 2테라~3테라 정도 되는 크기로 사용한다.
하지만 하둡 클러스터를 운영하다보면 위의 사이즈보다 더 저장해야되는 경우가 있다. scale-out해야 하지만 도입 당시 적절한 스펙으로 맞췄는데 그거랑 많아 다른 스펙의 클러스터가 신규로 들어올 수도 있다.
때문에 도입 시기에 따라 다른 스펙의 클러스터들을 운영하게 될 수도 있다.
블록의 지역성
하둡에 데이터가 저장되어 있다라는 가정 하에 큰 데이터가 저장되어 있어도 1차적으로 빠른 연산을 할 수 있게 해주는 알고리즘이 플랫폼화되어 내부에 저장되어 있다.
그냥 Job을 던지면 하둡의 마스터 노드 슬레이브 노드들이 알아서 통신하고 자기들끼리 알아서 할당해서 처리한다.
- 네트워크를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리시간 증가
블록 캐싱
마스터성 데이터가 크지 않다라는 전제하에 데이터 노드도 데몬을 띄울 때 메모리 설정을 해줄 수 있다.
내가 갖고 있는 물리적인 하드웨어 스펙에따라 데이터 노드가 들고 올라가는 메모리가 정해져 있는데 거기에 캐시를 둘 수 있을 만큼의 용량
→ 한마디로 상대적이다.
큰 데이터가 아닌 수십MB 언더로는 캐시 등록을 해서 쓸 수 있다.
네임 노드
- 전체 HDFS 에 대한 Name Space 관리
- 데이터 노드로 부터 Block 리포트를 받음
- 데이터에 대한 Replication 유지를 위한 커맨더 역할 수행
- 파일시스템 이미지 파일 관리(fsimage)
- 파일시스템에 대한 Edit Log 관리
보조 네임 노드(SNN)
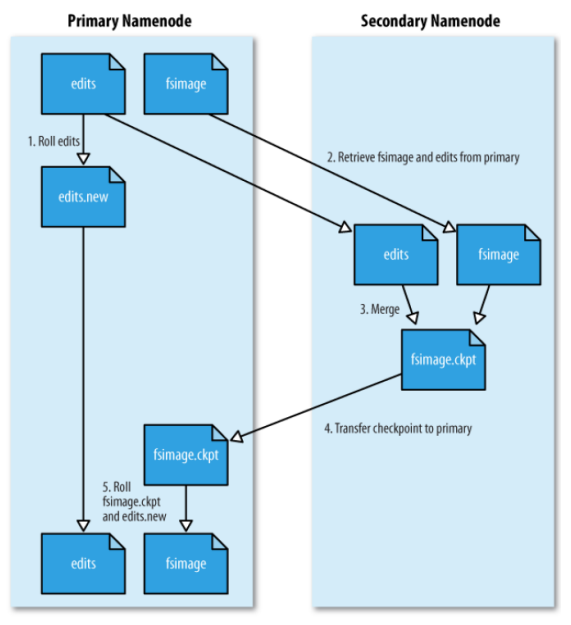
마스터 노드를 보조할 수 있는 노드처럼, 이중화 구성처럼 보이지만 그 역할은 아니다.
하둡은 네임노드 메모리의 fs이미지 파일, edits로그들을 읽어들이는 작업 등을 통해 항상 최신 상태를 유지하게 되어있다.
이를 위해선 클러스터 운영 중 하둡에 어떤 변경이 일어났다고 하면 edits로그에 모든 변경사항이 남는다.
그걸 fs이미지에 병합을 계속해줘야 하는데 그걸 네임노드에서 직접하지 않고 snn에 파일 보내고 머지한 다음 fs이미지를 바꿔치기하는 작업을 주기적으로 해준다.
snn이 장애나면 어떤 이슈가 생기는지?
당장의 어떠한 장애가 따로 나진 않지만 edits로그가 무한히 커진다.
그렇게 되면 나중에 하둡 네임노드를 restart하는 경우에 파일이 너무 크면 읽지를 못하고 out of memory exception이 발생할 수 있다.
데이터 노드
마스터 노드한테 내가 가진 데이터에 대해 데이터 리포트(블록 리포트)를 계속해서 보내는 역할, 실제 데이터가 저장되는 곳(마스터 노드에는 부하를 최소화하기 위해 실제 데이터를 저장하진 않는다.)
세이프 모드
HDFS의 세이프모드(safemode)는 데이터 노드를 수정할 수 없는 상태
- 세이프 모드가 되면 데이터는 읽기 전용 상태가 되고, 데이터 추가와 수정이 불가능 하며 데이터 복제도 일어나지 않음
- 관리자가 서버 운영 정비를 위해 세이프 모드를 설정 할 수 있음
- 네임노드에 문제가 생겨서 정상적인 동작을 할 수 없을 때 자동으로 세이프 모드로 전환
- 주로 missing block 이 발생하는 경우, 혹은 클러스터 재 구동 시 블록 리포트를 다 받기 전까지 Safe mode 로 동작
블록 종류
-
under replicated blocks
default로 3개의 replication인데 2개로 replication이 되어있다고 하면 under replicated라고 한다. -
missing blocks
3이어야 되는 블록인데 그게 하나의 replication도 없다면 missing block이라고 한다. -
corrupt blocks
파일 자체가 깨진 것, 유실이 발생했을 경우 corrupt block이라고 한다.
HDFS 명령어
우선 hadoop 명령어를 쓰기 위해선 ./bashrc에 export HADOOP_HOME과 PATH를 해준다.
bashrc에 아래 설정을 해주면 어느 디렉토리에서든 hadoop 명령어를 쓸 수 있다.
export HADOOP_HOME=<경로>
export PATH=$HADOOP_HOME/bin:$PATHls, mkdir 등등의 리눅스의 기본 명령어와 겹치는 부분도 많아 몇 가지만 적겠다.
hadoop fs -setrep <rep> <path>path에 있는 데이터들은 replication 만큼 복제되도록 하둡 네임노드가 알아서 관리를 해준다.
hadoop fs -text <src>하둡에 저장되어 있는 데이터의 내용을 볼 때 사용하는 명령어
hadoop fs -getmerge <src> <localdest>하돕에 많은 파일들을 merge해서 파일 하나로 로컬로 받고 싶을 때 사용하는 명령어
