FastMCP란?
MCP 서버와 클라이언트를 빠르고 간단하게 생성할 수 있도록 설계된 파이썬 전용 프레임워크
FastMCP를 사용해서 나만의 MCP 서버를 만들어보고 FastMCP와 ADK 기반 클라이언트에서 해당 서버를 사용해볼 것이다.
아키텍처
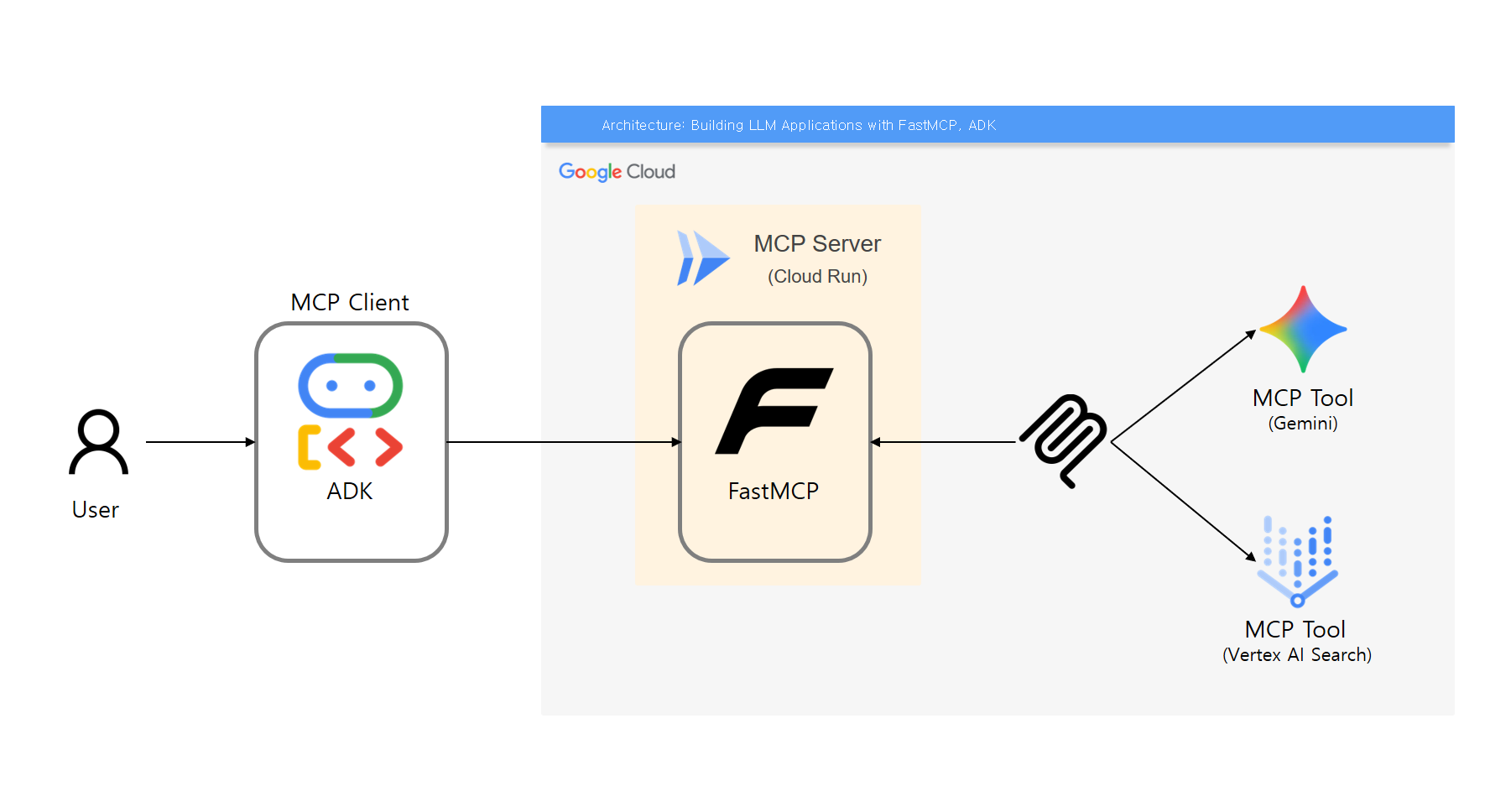
만들어볼 앱은 Vertex AI Search의 웹사이트 기반 인덱싱을 활용하여 기술 질의의 경우 Google 공식 문서 기반의 LLM 응답을 하는 애플리케이션을 만들어볼 것이다.
Vertex AI Search의 웹사이트 기반 검색에 + LLM 응답을 위해선 자신이 소유한 도메인이어야 하고, 그에 대한 인증이 필요하다. 하지만 해당 도메인은 당연히 내 소유가 아니므로 여기선 키워드 기반 문서 검색의 수준 정도 밖에 구현할 수 없었다. 때문에 만약 Google의 기술 관련 질문일 때,
1. 키워드를 추출하는 Tool -> 2. 문서 검색하는 Tool을 Sequential하게 호출하도록.. 응답 시간은 오래 걸리겠지만 우회해서 구현해볼 것이다.
MCP Server
MCP Tool - Google 문서 검색
Vertex AI Search Datastore 생성
GCP의 AI Applications > 데이터 스토어 > 만들기 > 웹사이트 콘텐츠 만들기 클릭
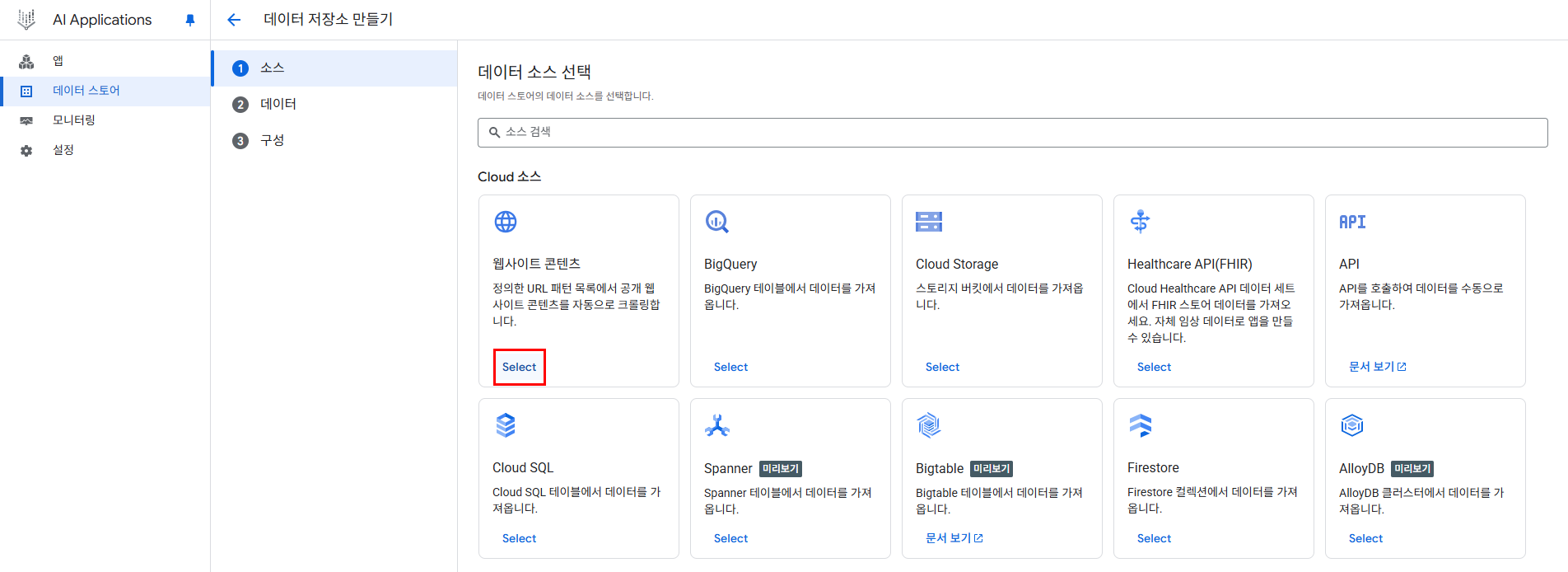
검색에 포함할 도메인, 제외할 도메인이 있다. 포함할 도메인은 아래의 도메인 리스트 들을 추가해주자.
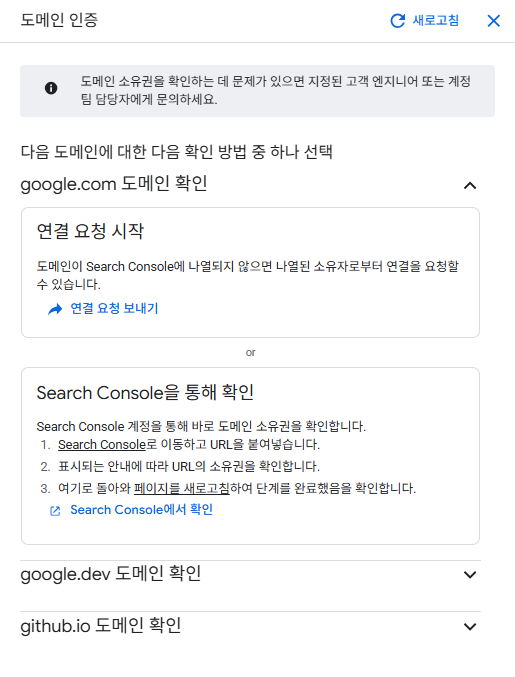
여기서 고급 웹사이트 색인 생성을 체크 해주면 해당 문서들 기반으로 자연어 기반 질의 응답이 가능하나, 도메인 인증을 할 수 없으므로 체크해주지 않을 것이다.
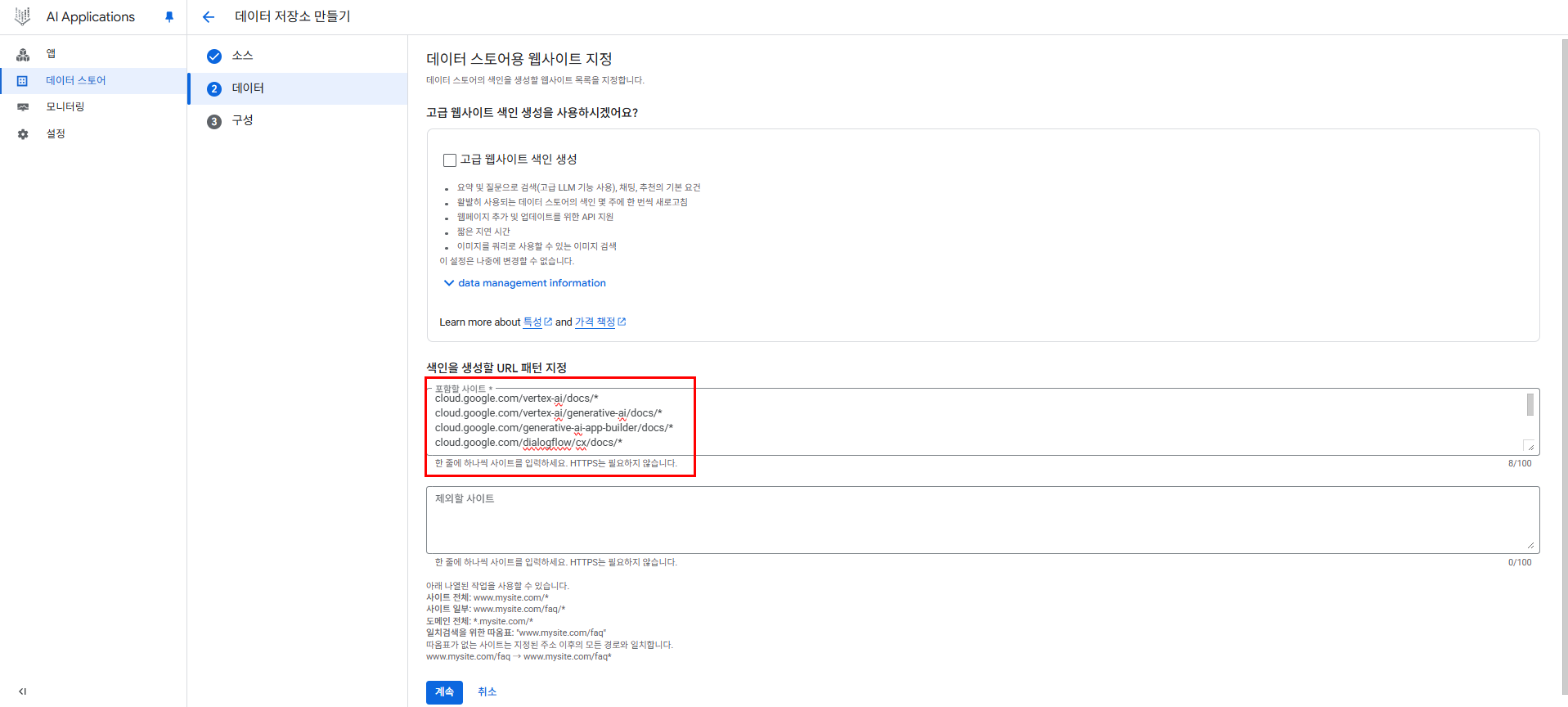
도메인 리스트
도메인은 BigQuery 및 Vertex AI의 생성형 AI 관련 서비스들에 대한 문서, Google의 Gemini Developer 문서, 그리고 ADK 및 A2A 관련 문서이다.
- cloud.google.com/vertex-ai/docs/*
- cloud.google.com/vertex-ai/generative-ai/docs/*
- cloud.google.com/generative-ai-app-builder/docs/*
- cloud.google.com/dialogflow/cx/docs/*
- cloud.google.com/bigquery/docs/*
- ai.google.dev/gemini-api/docs/*
- google.github.io/adk-docs/*
- a2aproject.github.io/A2A/latest/*
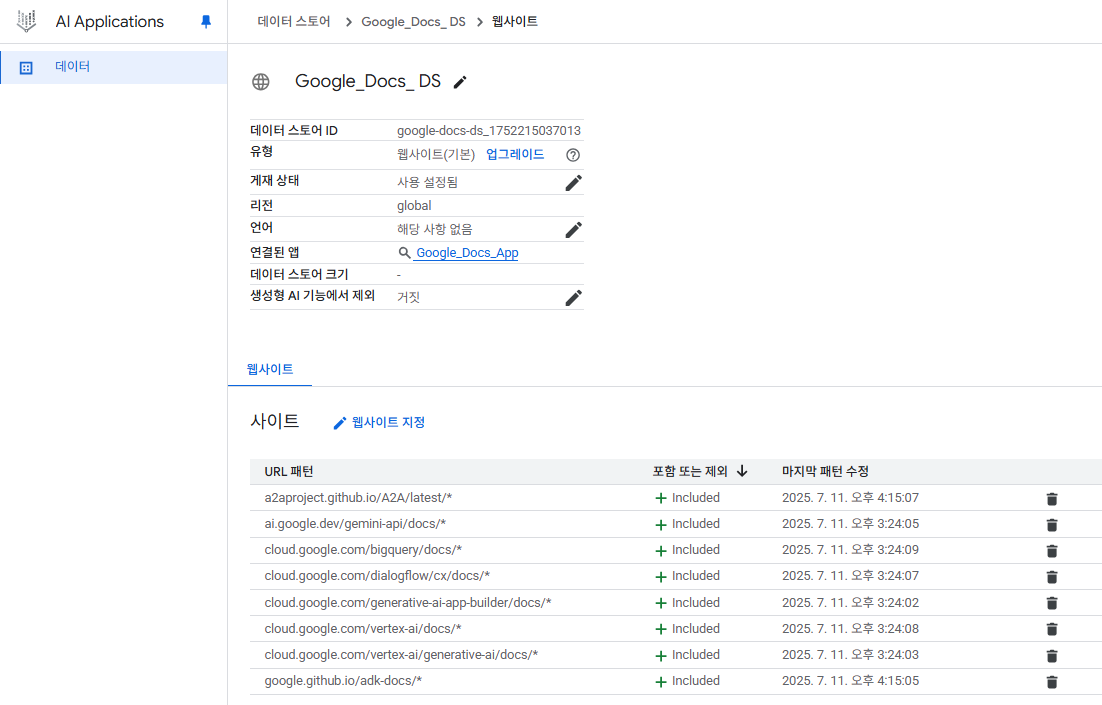
해당 도메인들을 포함해주고 데이터 스토어 이름 지정 후 생성
아래 사진과 같이 included가 보이면 성공
만약 고급 웹사이트 색인 생성을 체크하여 생성했다면 아래와 같은 화면이 뜰 것이다.
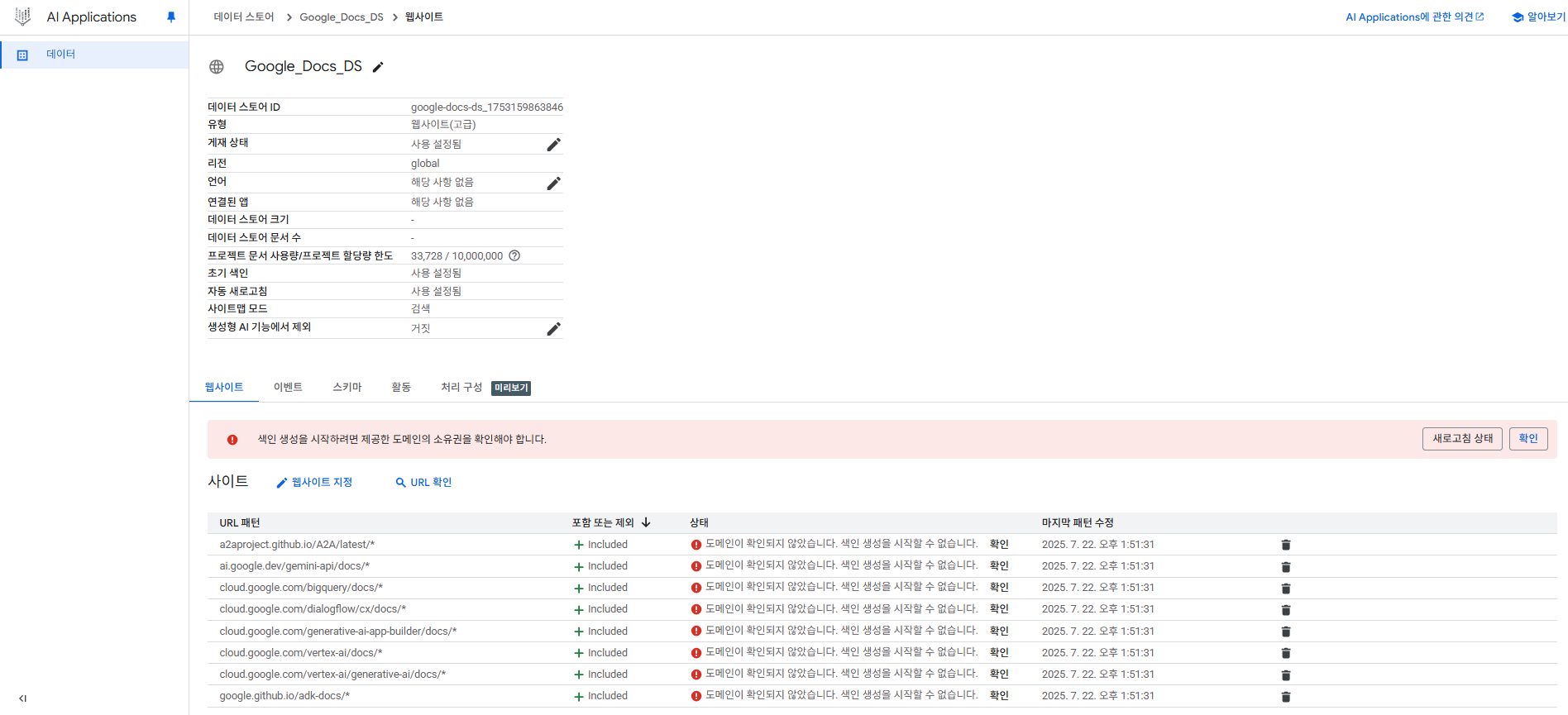
도메인 인증이 필요하다는 내용이다.
Vertex AI Search App 생성
GCP의 AI Applications > 앱 > 앱 만들기 클릭
만든 Datastore를 기반으로 앱을 생성해줄 것이다. 기본 설정들 그대로해서 생성해주자.
검색 테스트
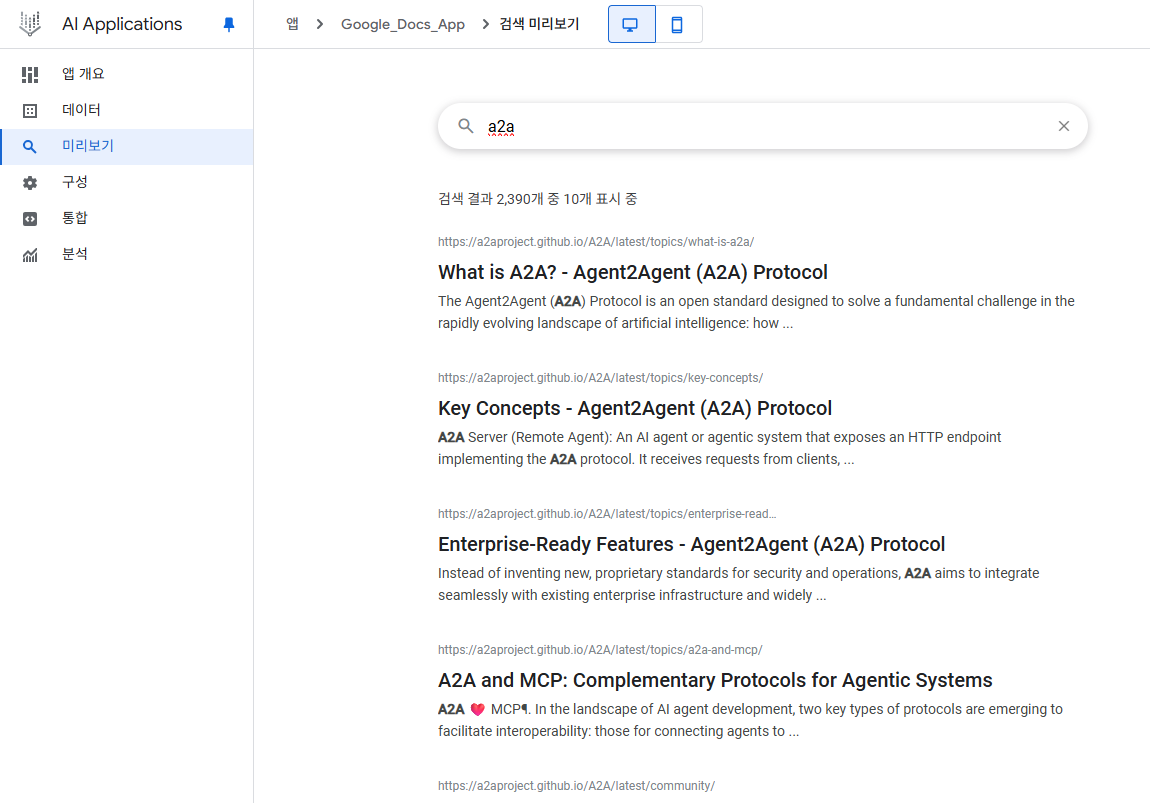
앱을 생성했을 시 자연스레 엔드포인트가 생성되고 API 기반으로 손쉽게 통합할 수 있는 방법이 나와있다.
MCP Tool - 키워드 추출
Gemini를 활용해 Google의 Data/AI 관련 질의일 때, 키워드를 추출해주도록 할 것이다.
MCP Server 코드
server.py
import os
import json
from typing import List
import requests
import google.auth
import google.auth.transport.requests
from fastmcp import FastMCP
from starlette.applications import Starlette
from starlette.routing import Mount
from google import genai
from pydantic import BaseModel
# ------------------------------------------------------------------
# 환경 변수
# ------------------------------------------------------------------
PROJECT_NUMBER = os.getenv("PROJECT_NUMBER")
ENGINE_ID = os.getenv("ENGINE_ID")
LOCATION = os.getenv("LOCATION")
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
# ------------------------------------------------------------------
# FastMCP 서버 정의
# ------------------------------------------------------------------
mcp = FastMCP("My Google Docs Search MCP Server")
# ------------------------------------------------------------------
# Tool1 - LLM을 통한 키워드 추출
# ------------------------------------------------------------------
client = genai.Client()
instructions = """
You are a competent AI-powered keyword extractor.
When you see a user question and realize it's about Data/AI technology on Google Cloud, you need to extract the keywords in the question.
Below are some examples of keyword extraction:
Question: A2A가 뭐야?
Keywords: A2A
Question: BigQuery에서 MCP를 구현할 수 있어??
Keywords: BigQuery, MCP
"""
class schema(BaseModel):
keywords: list[str]
@mcp.tool
async def keyword_extract(query: str) -> List[str]:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=query,
config=genai.types.GenerateContentConfig(
system_instruction=instructions,
temperature=0,
response_mime_type="application/json",
response_schema=list[schema],
),
)
print(f"[SUCCESS] {response.text}")
data = json.loads(response.text)
return data[0]["keywords"] if data else []
# ------------------------------------------------------------------
# Tool2 - Vertex AI Search 호출
# ------------------------------------------------------------------
@mcp.tool
async def search_docs(keywords: List[str]) -> List[str]:
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(google.auth.transport.requests.Request())
url = f"https://discoveryengine.googleapis.com/v1alpha/projects/{PROJECT_NUMBER}/locations/{LOCATION}/collections/default_collection/engines/{ENGINE_ID}/servingConfigs/default_search:search"
def call_api(url: str, payload: dict, access_token: str):
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"[ERROR] {url}: {e}")
if e.response is not None:
print("[ERROR] 내용:", e.response.text)
return None
def search_call(keywords: List[str]):
access_token = creds.token
if not access_token:
return
print("[SUCCESS] 액세스 토큰을 성공적으로 가져왔습니다.")
query_str = ", ".join(keywords)
payload = {
"query": query_str,
"pageSize": 10,
"queryExpansionSpec": {"condition": "AUTO"},
"spellCorrectionSpec": {"mode": "AUTO"},
"languageCode": "ko",
"userInfo": {"timeZone": "Asia/Seoul"},
}
search_response = call_api(url, payload, access_token)
return search_response
# 결과에서 URL 추출
data = search_call(keywords)
results_md: list[str] = []
for res in data.get("results", []):
d = res.get("document", {}).get("derivedStructData", {})
title = d.get("title") or d.get("htmlTitle")
link = d.get("link")
if title and link:
results_md.append(f"[{title}]({link})")
print(f"[SUCCESS] {results_md}")
return results_md
# ------------------------------------------------------------------
# Starlette ASGI 래퍼 (Cloud Run entry-point)
# ------------------------------------------------------------------
http_app = mcp.http_app() # Streamable HTTP transport at '/mcp/'
app = Starlette(routes=[Mount("/", app=http_app)], lifespan=http_app.lifespan)
if __name__ == "__main__":
import uvicorn
uvicorn.run("server:app", host="0.0.0.0", port=8080)Starlette 랩퍼
- mcp.http_app() 하나로 FastMCP가 HTTP 앱을 만들어주고 '/mcp/' 경로에서 세션, 툴 호출을 처리한다.
- Starlette 최상위 라우터에 마운트 즉, 모든 경로 -> http_app 으로 전달
- mcp.http_app() → MCP 프로토콜 HTTP 핸들러
- Starlette Mount → URL 라우팅(지금은 / 전체를 MCP에 연결)
- uvicorn → ASGI 서버(요청 ↔ 앱 바인딩)
이렇게 세가지가 맞물려 Cloud Run 에서 /mcp/ 로 들어오는 스트리밍 요청을 FastMCP 로직에 전달하게 된다.
MCP Client
해당 코드를 Cloud Run에 배포하면 엔드포인트 URL이 나오게 된다.
'URL/mcp/'로 호출하면 내가 정의한 MCP Server의 Tool들을 받아와서 사용할 수 있다.
FastMCP
우선 list_tools() 및 call_tool()로 Tool이 제대로 호출되는지 확인하자.
키워드를 임의로 입력해주고 search_docs Tool만 따로 테스트해볼 것이다.
client.py
import os
import asyncio
from fastmcp import Client
MCP_URL = "<Cloud Run Endpoint URL>/mcp/"
async def main():
async with Client(MCP_URL) as client:
# List available tools
tools = await client.list_tools()
for tool in tools:
print(f"--- 🛠️ Tool found: {tool.name} ---")
print("--- 🪛 Calling search_docs tool ---")
result = await client.call_tool(
"search_docs", {"keywords": ["Gemini","JSON Output", "Function Calling"]}
)
print(f"--- ✅ Success: {result} ---")
if __name__ == "__main__":
asyncio.run(main()) 결과
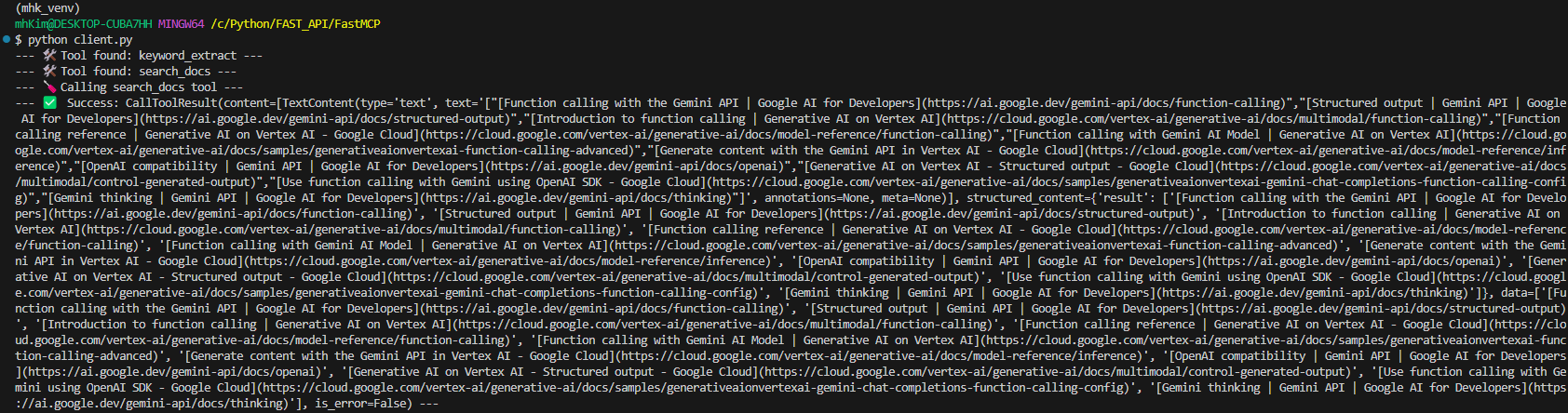
정의해준 두 개의 Tool을 모두 불러온 것을 확인할 수 있고 Gemini, JSON Output, Function Calling 키워드에 관련된 문서를 Vertex AI Search에 검색해서 가져온 것을 확인할 수 있다.
실제 질문을 해서 알맞게 Tool을 호출한 뒤 응답을 하는지 봐보자.
client.py
import os
import asyncio
from fastmcp import Client
from google import genai
MCP_URL = "<Cloud Run Endpoint URL>/mcp/"
query = "Gemini에서 JSON 출력하고 Function Calling 어떻게 사용해?"
async def main():
mcp_client = Client(MCP_URL)
client = genai.Client()
async with mcp_client:
response = await client.aio.models.generate_content(
model="gemini-2.5-pro",
contents=query,
config=genai.types.GenerateContentConfig(
system_instruction=SYSTEM_INSTRUCTION,
temperature=0,
tools=[mcp_client.session]
),
)
print(response.text)
if __name__ == "__main__":
asyncio.run(main())Cloud Run URL 기반으로 MCP Client를 만들어주고
tools에 mcp_clinet.session만 추가해주면 내가 정의한 Tool을 가져와서 사용할 수 있다.. 매우 간단하다!!🙂😊
결과
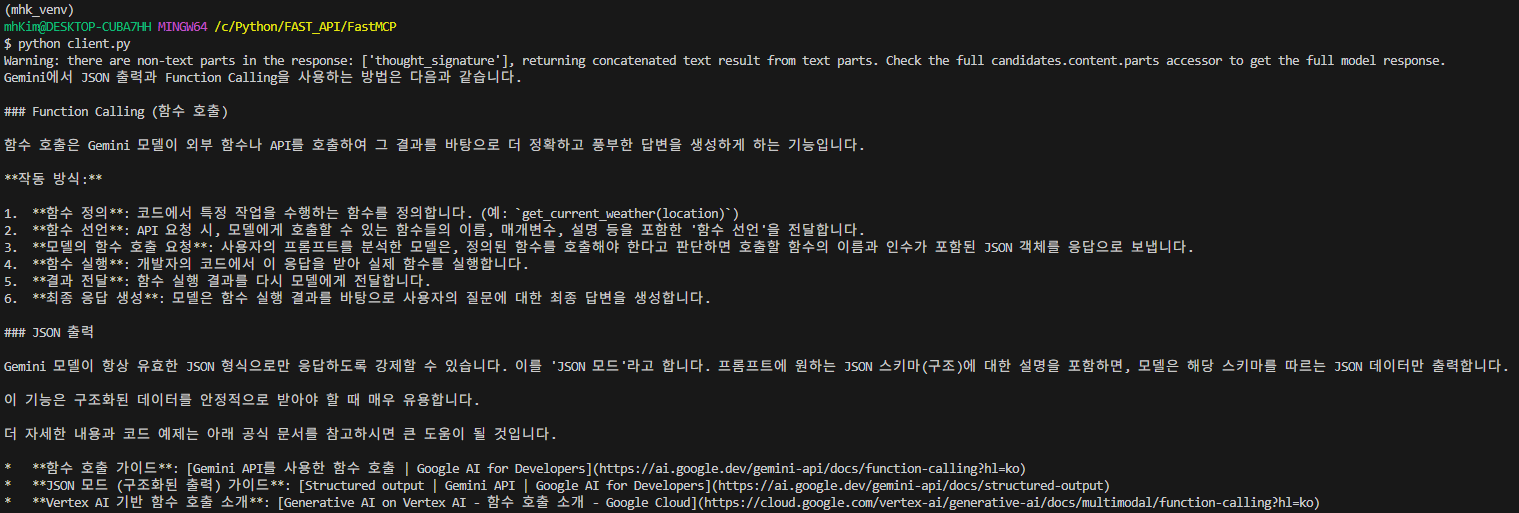
답변을 잘 생성하고 실제로 Vertex AI Search에서 포함시켜준 문서 범위 내에 있는 문서들을 링크로 같이 전달준 것을 확인할 수 있다.
FastMCP 못지않게 ADK 기반으로 Client를 구현해도 아주아주 간단하게 구현할 수 있다.
ADK
ADK WEB을 사용할 것이므로 따로 폴더를 만들고 init.py 파일과 .env도 같이 만들어주어야 한다.
폴더 구조
├── google_docs_search
│ ├── __init__.py
│ ├── .env
│ └── agent.py
│── server.py
│── client.pyagent.py
import os
from google.adk.agents import LlmAgent
from google.adk.tools.mcp_tool import MCPToolset, StreamableHTTPConnectionParams
MCP_URL = "<Cloud Run Endpoint URL>/mcp/"
def create_agent() -> LlmAgent:
"""Constructs the ADK currency conversion agent."""
print("--- 🔧 Loading MCP tools from MCP Server... ---")
print("--- 🤖 Creating ADK Currency Agent... ---")
return LlmAgent(
model="gemini-2.5-pro",
name="google_docs_search_agent",
description="Agents help you answer technical questions with clear, well-founded answers.",
instruction=SYSTEM_INSTRUCTION,
tools=[
MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=MCP_URL
)
)
],
)
root_agent = create_agent()FastMCP에서 tools에 mcp_clinet.session만 추가해주면 됐었는데, ADK에서도 tools에 MCPToolset(connection_params=StreamableHTTPConnectionParams(url=MCP_URL))만 추가해주면 된다.
init.py
from . import agent.env
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<API Key>'adk web' 명령어 실행 후 localhost:8000으로 접속
실행
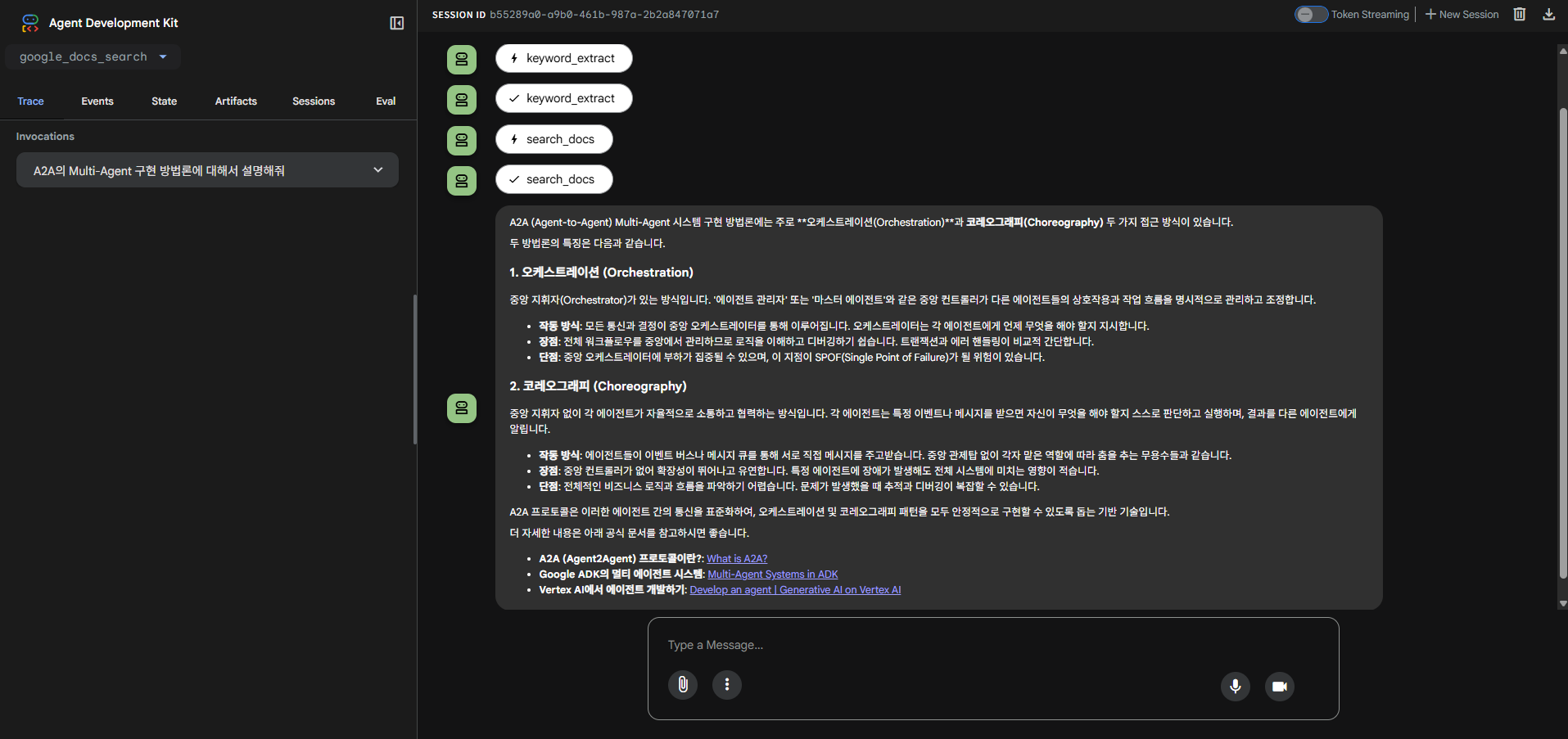
keyword_extract Tool과 search_docs Tool을 차례로 호출한 뒤 해당 정보들을 토대로 답을 생성한 것을 확인할 수 있다.
Events 확인
실제로 어떻게 도구들이 호출됐는지 확인해보자
질문은 'A2A의 Multi-Agent 구현 방법론에 대해서 설명해줘'였다.
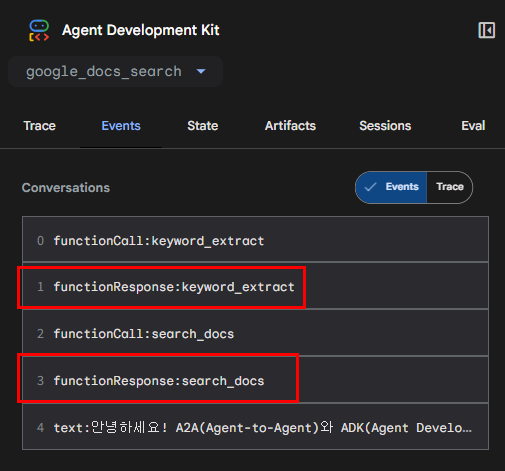
keyword_extract를 확인해보니 Gemini JSON Output 설정에 따라 리스트 형태로 잘 키워드가 추출된 것을 알 수 있다.
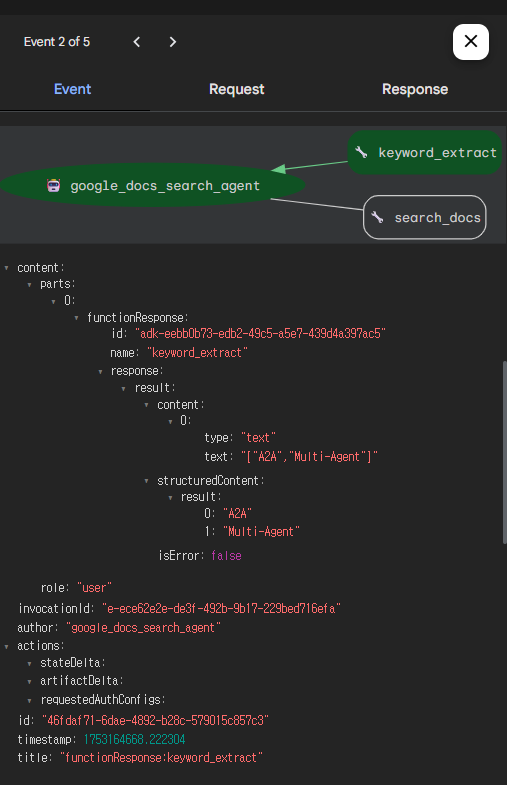
search_docs도 마찬가지로 해당 키워드에 맞는 문서들을 잘 검색해온 것을 알 수 있다.
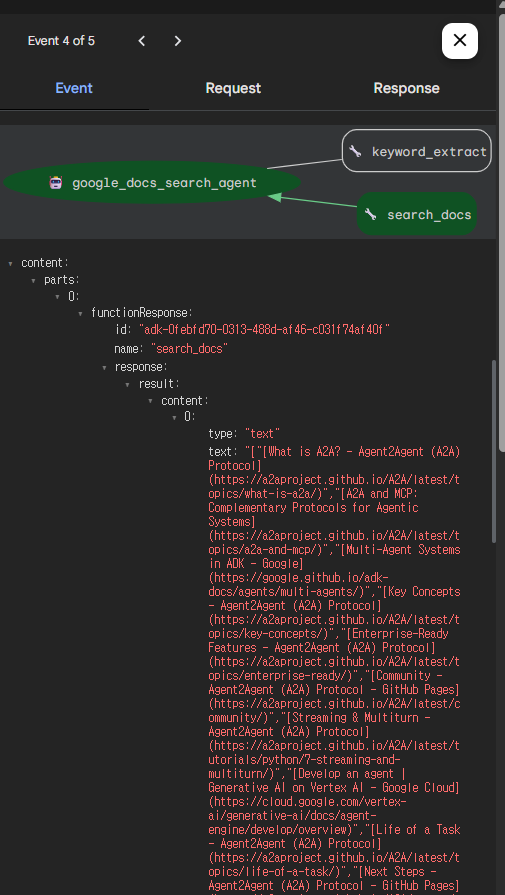
(번외) StdioServerParameters vs StreamableHTTPConnectionParams
이전 포스팅 중 ADK와 MCP를 사용한 Agent 개발에선 StdioServerParameters를 사용하여 개발했었다. 이번엔 StreamableHTTPConnectionParams를 사용했는데 둘이 어떤 차이가 있는지 아래 표를 통해 확인할 수 있다.
| 항목 | StdioServerParameters | StreamableHTTPConnectionParams |
|---|---|---|
| 용도 | 동일 프로세스 또는 로컬에서 실행 중인 MCP 서버와 표준입·출력(STDIN/STDOUT) 파이프로 통신 | 원격 MCP 서버(Cloud Run, GKE, VM 등)에 HTTP 스트리밍(Server‑Sent Events 업그레이드) 프로토콜로 접속 |
| 네트워크 | 없음 | HTTPS TCP 연결 |
| 권장 시나리오 | 단위 테스트, 로컬 개발, CI | 실제 배포 환경, 다중 클라이언트, 인증·프록시 필요 |
| ADK 버전 | v1.0 이후 계속 지원 | v1.2.0+ 부터 도입 |
| MCP 프로토콜 | stdio transport | Streamable HTTP transport -> SSE 대체 차세대 표준 |
[FastMCP, ADK를 사용한 LLM 애플리케이션 개발 참고]
