데이터 입력, 조회, 삭제
curl -XGET http://localhost:9200/<index 이름>
- 데이터를 조회할 경우 -XGET
- 데이터를 생성 및 추가할 경우 -XPOST, -XPUT
- 데이터를 삭제할 경우 -XDELETE
ex) curl -XGET http://localhost:9200/classes
위의 명령어는 classes라는 index가 있는지 확인하는 것이고 없으므로 404가 뜬 것을 확인할 수 있다.

인덱스 생성
curl -XPUT http://localhost:9200/classes결과값을 좀 더 이쁘게 보는 법
curl -XGET http://localhost:9200/classes?pretty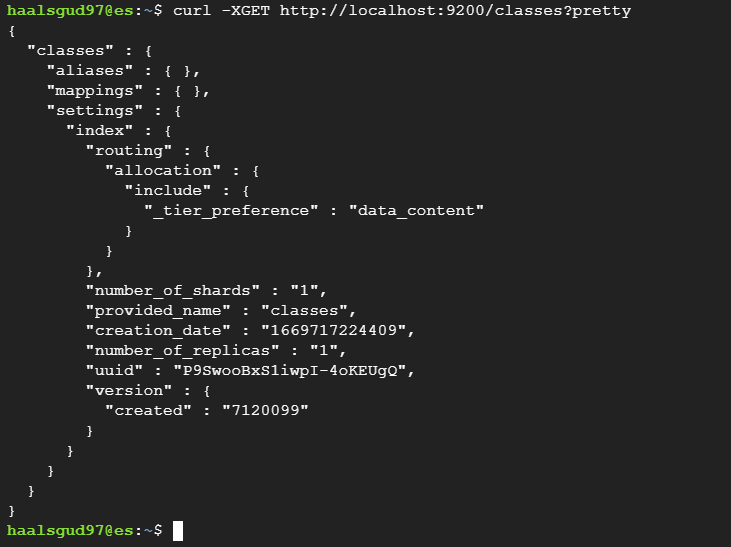
Document 생성
(만들어져 있는 인덱스가 없는 경우에도 index와 document를 한 번에 생성할 수 있다.)
# ES 7.0.0 버전 이하 DOCUMENT 생성
curl -XPOST http://localhost:9200/classes/class/1/ -d ‘{”title” : “Algorithm”, “professor” : “John”}’
# ES 7.0.0 버전 이상 DOCUMENT 생성
curl -XPOST -H "Content-Type: application/json" localhost:9200/classes/class/1/ -d '{"title":"Algorithm", "professor":"John"}’JSON 파일을 사용하여 생성할 수도 있다.
oneclass.json
{
"title" : "Elastic Search",
"Professor" : "Minhyoung Kim",
"major" : "ISE",
"semester" : ["spring", "fall"],
"student_count" : 100,
"unit" : 3,
"rating" : 5
}curl -XPOST -H "Content-Type: application/json" localhost:9200/classes/class/1/ -d @oneclass.jsonXGET으로 확인
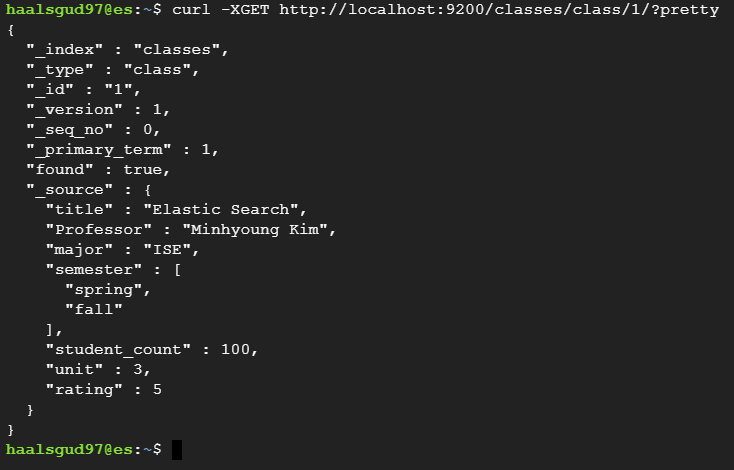
DOCUMENT 업데이트
다시 아래와 같이 DOCUMENT를 생성해준다.
curl -XPOST -H "Content-Type: application/json" localhost:9200/classes/class/1/ -d '{"title":"Algorithm", "professor":"John"}'필드 추가(UPDATE)
curl -XPOST -H "Content-Type: application/json" localhost:9200/classes/class/1/_update -d '{"doc" : {"unit" : 1}}’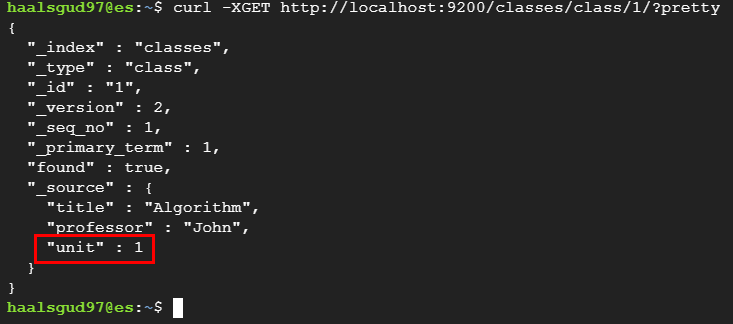
스크립트 사용
# unit이라는 필드에 5를 더하는 스크립트
curl -XPOST -H "Content-Type: application/json" localhost:9200/classes/class/1/_update?pretty -d '{"script" : "ctx._source.unit +=5"}’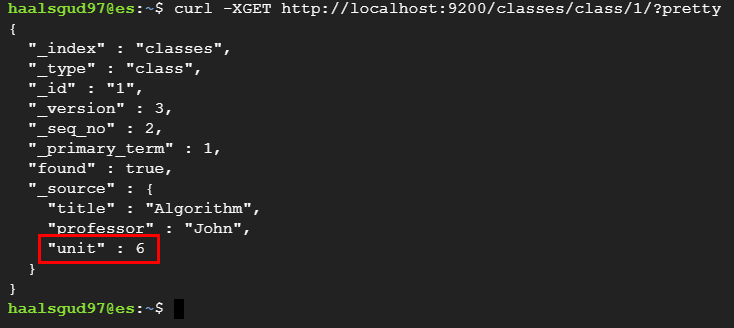
매핑
RDB로 생각하면 스키마 정의와 같다고 보면 된다.
매핑은 인덱스를 먼저 만들어주어야 생성할 수 있다.
mapping.json
ES 6.x.x 버전 이상부터는 string이 지원 안된다 string 대신 text, keyword 사용
{
"class" : {
"properties" : {
"title" : {
"type" : "text"
},
"professor" : {
"type" : "text"
},
"major" : {
"type" : "text"
},
"semester" : {
"type" : "text"
},
"student_count" : {
"type" : "integer"
},
"unit" : {
"type" : "integer"
},
"rating" : {
"type" : "integer"
},
"submit_date" : {
"type" : "date",
"format" : "yyyy-MM-dd"
},
"school_location" : {
"type" : "geo_point"
}
}
}
}curl -XPUT localhost:9200/classes/class/_mapping?include_type_name=true -d @mapping.json -H 'Content-Type: application/json'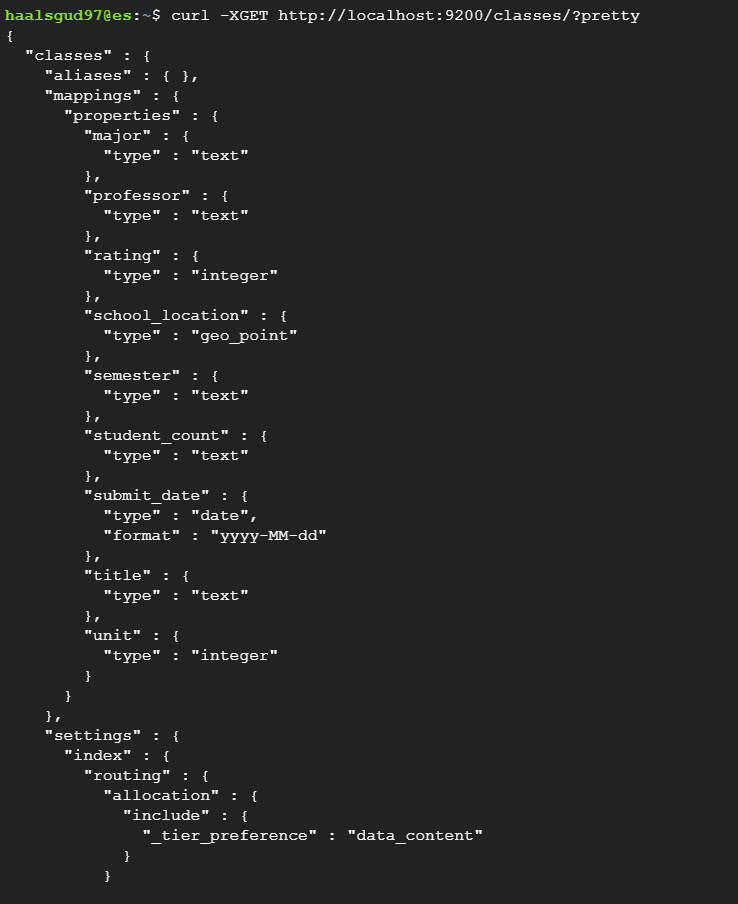
BULK POST
BULK FILE
위의 링크와 같이 많은 DOCUMENT들이 정의된 JSON파일을 갖고 인덱스를 한 번에 생성해줄 수 있다. 매핑으로 만들어놓은 스키마에 BULK FILE을 사용해 데이터를 넣어주자
curl -XPOST -H "Content-Type: application/json" localhost:9200/_bulk?pretty --data-binary @classes.json
SEARCH
두 개의 DOCUMENT가 있는 BULK FILE생성
simple_basketball.json
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "1" } }
{"team" : "Chicago Bulls","name" : "Michael Jordan", "points" : 30,"rebounds" : 3,"assists" : 4, "submit_date" : "1996-10-11"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "2" } }
{"team" : "Chicago Bulls","name" : "Michael Jordan","points" : 20,"rebounds" : 5,"assists" : 8, "submit_date" : "1996-10-11"}curl -XPOST -H "Content-Type: application/json" localhost:9200/_bulk?pretty --data-binary @simple_basketball.json모든 DOCUMENT 조회
curl -XGET localhost:9200/basketball/record/_search?prettypoints가 30인 값만 나오게 하는 쿼리를 넣어주는 명령어
curl -XGET 'localhost:9200/basketball/record/_search?q=points:30&pretty'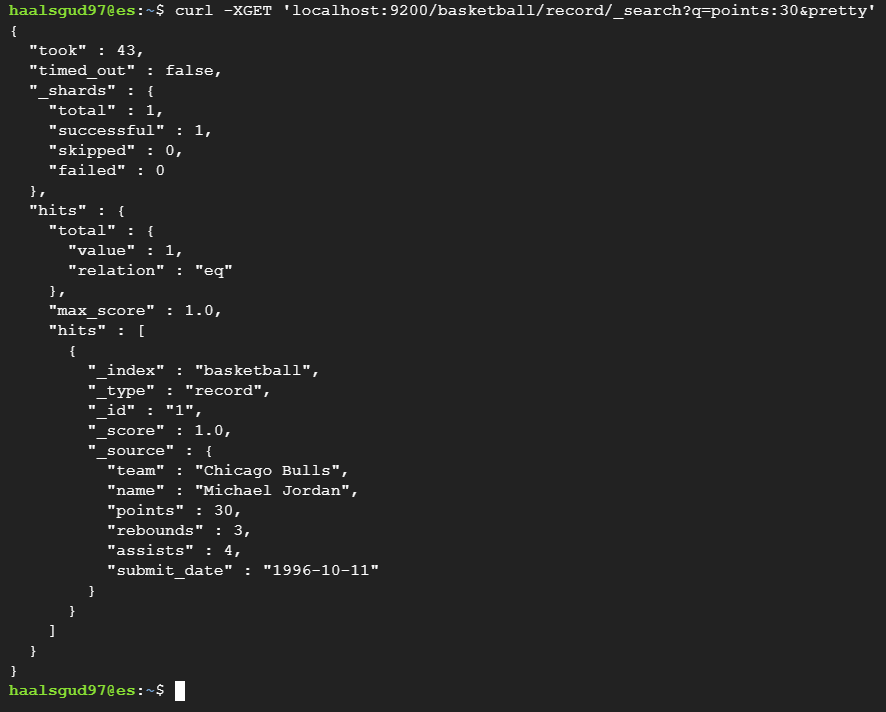
AGGREGATIONS
ES안에 있는 DOCUMENT 안에서 조합을 통해서 어떤 값을 도출할 때 쓰는 방법
그 중 메트릭 어그리게이션은 산수에 쓰인다.(평균, 최솟값, 최댓값 등등)
위에 넣어줬던 basketball 데이터가 있는 상태
실행 명령어
curl -XGET localhost:9200/_search?pretty --data-binary @<파일 이름>- AVG
points의 평균값을 구하겠다는 뜻
(aggs말고 aggregations라고 써도 된다.)
{
"size" : 0,
"aggs" : {
"avg_score" : {
"avg" : {
"field" : "points"
}
}
}
}- MAX
points의 최댓값을 구하겠다는 뜻
{
"size" : 0,
"aggs" : {
"max_score" : {
"max" : {
"field" : "points"
}
}
}
}- MIN
points의 최솟값을 구하겠다는 뜻
{
"size" : 0,
"aggs" : {
"min_score" : {
"min" : {
"field" : "points"
}
}
}
}- SUM
points의 합계를 구하겠다는 뜻
{
"size" : 0,
"aggs" : {
"sum_score" : {
"sum" : {
"field" : "points"
}
}
}
}- STATS
위에 4개의 모든 값을 한 번에 도출
{
"size" : 0,
"aggs" : {
"stats_score" : {
"stats" : {
"field" : "points"
}
}
}
}BUCKET AGGREGATIONS
SQL에서 GROUP BY라고 생각하면 된다.
실행 명령어
curl -XGET localhost:9200/_search?pretty —data-binary @<파일 이름>아래의 파일로 basketball 인덱스를 다시 생성
twoteam_basketball.json
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "1" } }
{"team" : "Chicago","name" : "Michael Jordan", "points" : 30,"rebounds" : 3,"assists" : 4, "blocks" : 3, "submit_date" : "1996-10-11"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "2" } }
{"team" : "Chicago","name" : "Michael Jordan","points" : 20,"rebounds" : 5,"assists" : 8, "blocks" : 4, "submit_date" : "1996-10-13"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "3" } }
{"team" : "LA","name" : "Kobe Bryant","points" : 30,"rebounds" : 2,"assists" : 8, "blocks" : 5, "submit_date" : "2014-10-13"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "4" } }
{"team" : "LA","name" : "Kobe Bryant","points" : 40,"rebounds" : 4,"assists" : 8, "blocks" : 6, "submit_date" : "2014-11-13"}curl -XPOST -H "Content-Type: application/json" localhost:9200/_bulk --data-binary @twoteam_basketball.json- team으로 각각 GROUP BY해서 출력
{
"size" : 0,
"aggs" : {
"players" : {
"terms" : {
"field" : "team"
}
}
}
}- 팀별로 묶은 다음 points의 스탯을 표시
(roup by로 묶은 다음 그 결과값에서 다시 aggs를 넣어줄 수 있다.)
{
"size" : 0,
"aggs" : {
"team_stats" : {
"terms" : {
"field" : "team"
},
"aggs" : {
"stats_score" : {
"stats" : {
"field" : "points"
}
}
}
}
}
}