Streaming Response
작년부터 AI 관련 프로젝트들을 수행하면서 적용해봤던 것들을 정리해본다.
보통 Flask, FastAPI등과 같은 Python 웹 프레임워크 기반 Backend API를 설계할 일이 대다수였고 이를 활용하여 컨테이너 기반 애플리케이션을 개발했었다.
여기서 다룰 스트리밍이란 단순히 요청이 왔을 때 실시간으로 그에 대한 응답을 하는 의미의 스트리밍과는 조금은 다른 걸 의미한다.
바로 아래 그림과 같이 LLM의 답변 생성을 스트리밍으로 출력하는 걸 의미한다.
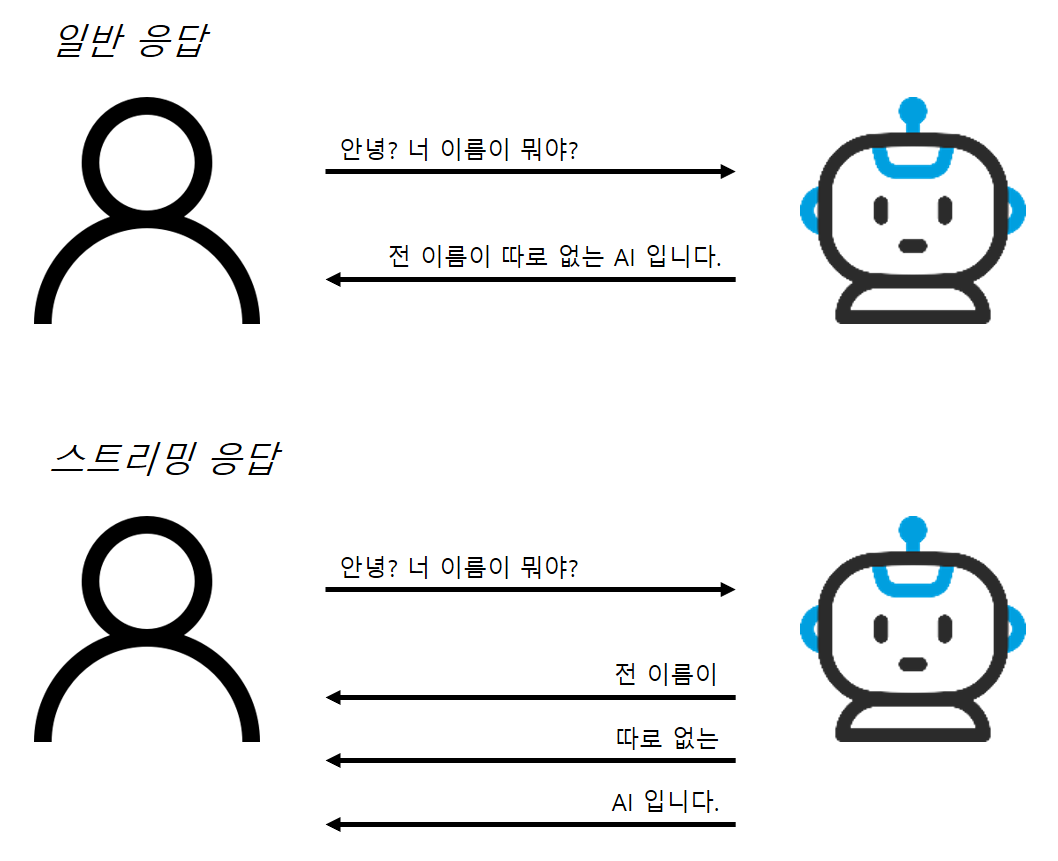
여러 LLM뿐 아니라 GCP의 Vertex AI Agent Builder와 같은 솔루션에서도 답변을 스트리밍으로 생성하는 옵션 설정이 가능한데, 실제 UI상에서 AI 응답을 그렇게 보여주고 싶다는 것이다.
(물론 Cloud Run - supports HTTP/gRPC server streaming 와 Cloud Run - build Websocket Chat Service 링크를 보면 Cloud Run에서 SSE, 웹소켓 구현이 가능하다고 하지만 보기만 해도 복잡시리..; Python 웹 프레임워크에서 훨씬 간단히 구현이 가능하므로.. 일단 Pass.. ^_^ )
LLM 호출
모델은 익숙하니까.. Gemini 사용!
import vertexai
from vertexai.generative_models import GenerativeModel, SafetySetting
def generate(query):
vertexai.init(
project="<프로젝트 ID>",
location="<리전>",
api_endpoint="<리전>-aiplatform.googleapis.com"
)
model = GenerativeModel(
"gemini-1.5-pro-002"
)
responses = model.generate_content(
[f"""{query}"""],
generation_config=generation_config,
safety_settings=safety_settings,
stream=True, #이 옵션으로 답변을 스트리밍으로 생성 가능
)
for response in responses:
yield response.text + "\n"
generation_config = {
"max_output_tokens": 8192,
"temperature": 0,
"top_p": 0.95,
}
safety_settings = [
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
]
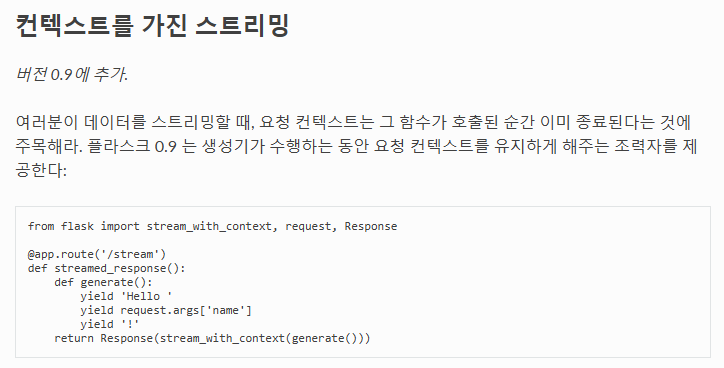
Flask
stream_with_context 라이브러리 사용 > Flask Docs 참고
main.py
'''
LLM 호출 코드
'''
from flask import Flask, request, Response, stream_with_context
app = Flask(__name__)
@app.route("/qa", methods=['POST'])
def main():
body = request.get_json()
query = body.get("query")
if not query:
return {"error": "Query is required"}
return Response(stream_with_context(generate(query)))Dockerfile
# 파이썬 이미지 사용
FROM python:3.12-slim
# 작업 디렉토리 설정
WORKDIR /app
# Python 로그가 버퍼링 없이 바로 터미널로 전송되어 출력
ENV PYTHONUNBUFFERED True
# 의존성 파일 복사 및 설치
COPY . /app/
RUN pip install --no-cache-dir -r requirements.txt
# 연결할 포트
EXPOSE 5000
# 컨테이너 시작시 실행할 명령어
CMD exec gunicorn --bind 5000 --workers 1 --threads 4 --timeout 0 main:app
기본 python 이미지는 풀사이즈 이미지라서 용량이 큼.
Slim 버전을 사용하면 불필요한 패키지가 제거되어 빌드 속도가 빨라지고 컨테이너 크기가 줄어들기 때문에 Slim 사용.
Cloud Run으로 배포 후 호출

스트리밍으로 생성된 답변이 전달되는 것을 확인할 수 있다.
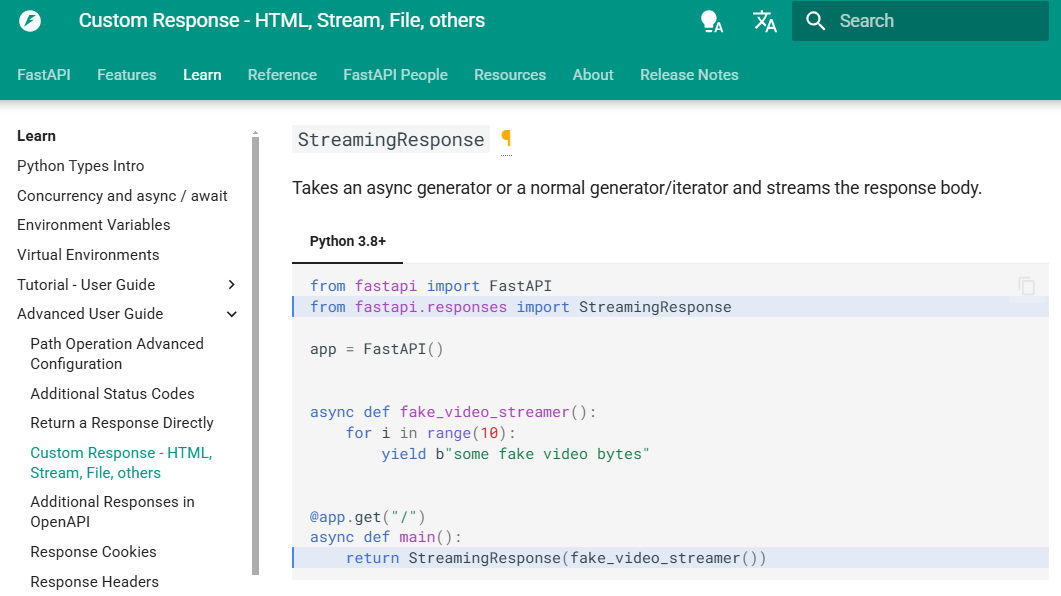
FastAPI
StreamingResponse 라이브러리 사용 > FastAPI Docs 참고
main.py
'''
LLM 호출 코드
'''
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
app = FastAPI()
@app.post("/qa")
async def main(request: Request):
body = await request.json()
query = body.get("query")
if not query:
return {"error": "Query is required"}
return StreamingResponse(generate(query))
Dockerfile
# 윗부분은 Flask의 Dockerfile과 동일하므로 생략
# 연결할 포트
EXPOSE 8080
# 컨테이너 시작시 실행할 명령어
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
Cloud Run으로 배포 후 호출

마찬가지로 스트리밍으로 응답을 받아옴.
[Cloud Run Streaming Response 참고]
[Flask(WSGI), FastAPI(ASGI) 참고]
