GCS to BigQuery 파이프라인 구축에서 이어지는 내용.
앞의 포스팅과 같은 구조에서 'Cloud Storage에 지속적으로 쌓이는 csv파일들이 한 테이블에 계속해서 쌓이게끔 해줄 수는 없는가?'와 같은 요구조건이 있을 수 있다.
ex) 한 달치 데이터가 계속해서 쌓이는데 6개월, 1년치 데이를 한 테이블에서 볼 수 있게끔 등등
이럴땐 폴더 단위로 트리거를 걸 수 있으면 좋은데 보다시피 콘솔에서 Cloud Storage에 트리거를 거는 것은 버킷 단위만 되고 폴더, 파일 단위는 되지 않는다.
하지만 코드를 통해 구현할 수 있다.
Cloud Storage는 Object Storage이므로 저장되는 객체들이 단순히 콘솔에서 보면 hierarchical한 구조로 보이지만 사실은 flat한 구조이다.
객체가 저장되는 것은 사실 버킷에 '폴더1/폴더2/파일이름' 이런 이름으로 저장되는 것.
때문에 data['name']을 통해 파일 이름을 불러오면 특정 폴더에 속해있을 경우 사실 파일 이름은 아래와 같이 불러와진다.

때문에 /를 기준으로 파일 이름을 나누고 폴더명으로 테이블이 생성되게끔 설정해줬다.
main.py
from google.cloud import bigquery
def import_to_bigquery2(data, context):
client = bigquery.Client()
project_id = '<프로젝트 ID>'
dataset_id = '<데이터 세트 명>'
bucket_name = data['bucket']
file_name = data['name']
# /를 기준으로 폴더와 파일 분리
file_name = file_name.split('/')
# 폴더명을 테이블명으로 지정
table_id = file_name[-2]
print(file_name)
file_ext = file_name[-1].split('.')[-1]
if file_ext == 'csv':
uri = 'gs://' + bucket_name + '/' + data['name']
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
#load config
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.schema_update_options = [
bigquery.SchemaUpdateOption.ALLOW_FIELD_ADDITION
]
job_config.create_disposition = [
bigquery.CreateDisposition.CREATE_IF_NEEDED
]
#load data
load_job = client.load_table_from_uri(
uri,
table_ref,
job_config=job_config
)
print('Started job {}'.format(load_job.job_id))
load_job.result()
print('Job finished.')
destination_table = client.get_table(dataset_ref.table(table_id))
print('Loaded {} rows.'.format(destination_table.num_rows))
else:
print('Nothing To Do')폴더를 만들고 csv파일을 하나 업로드
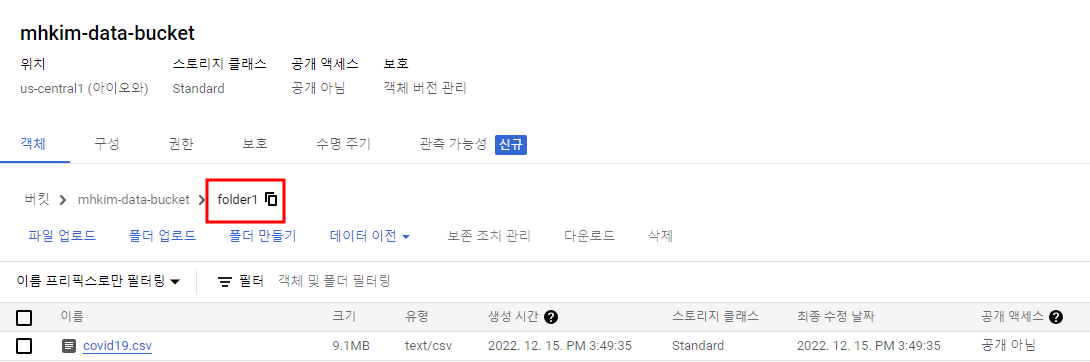
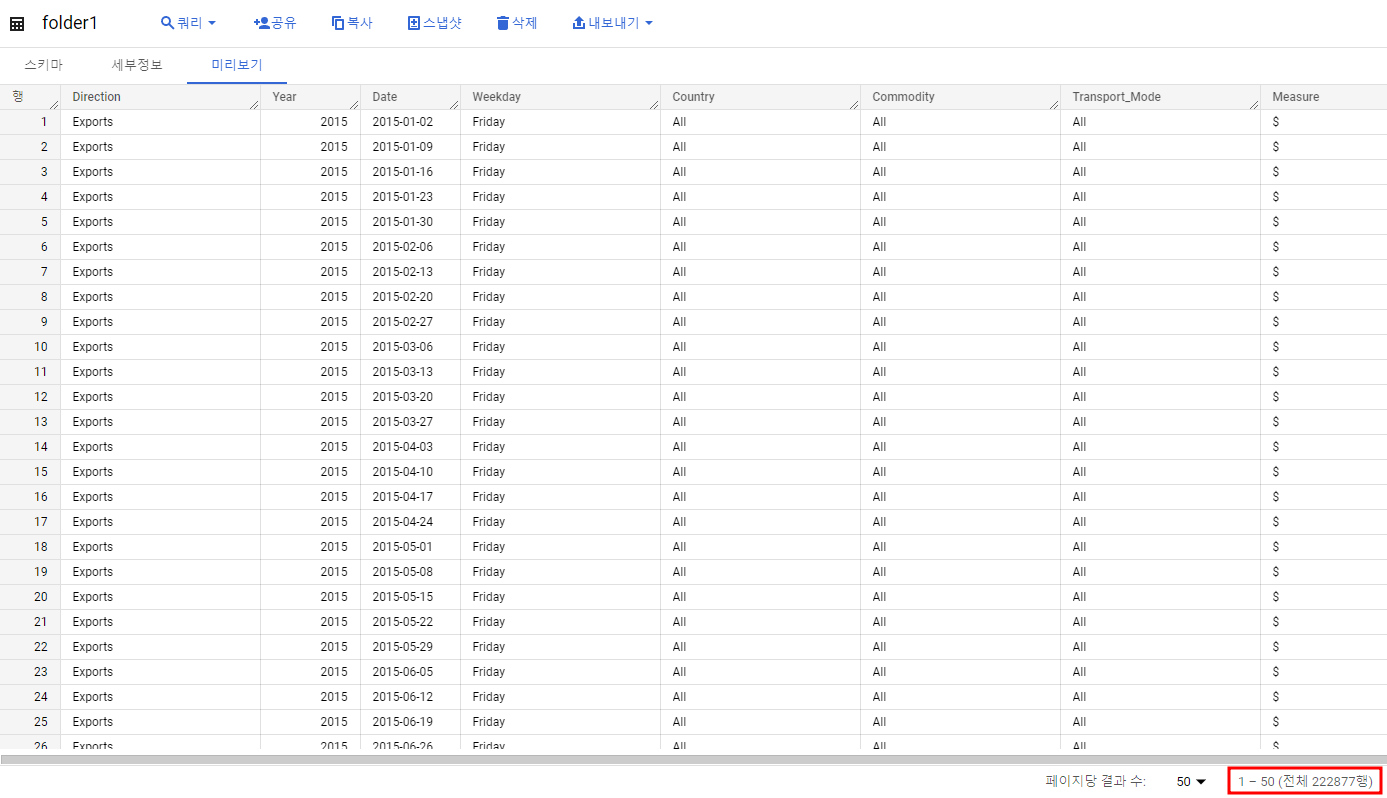
폴더명으로 테이블이 생성된 것 확인(222876행)
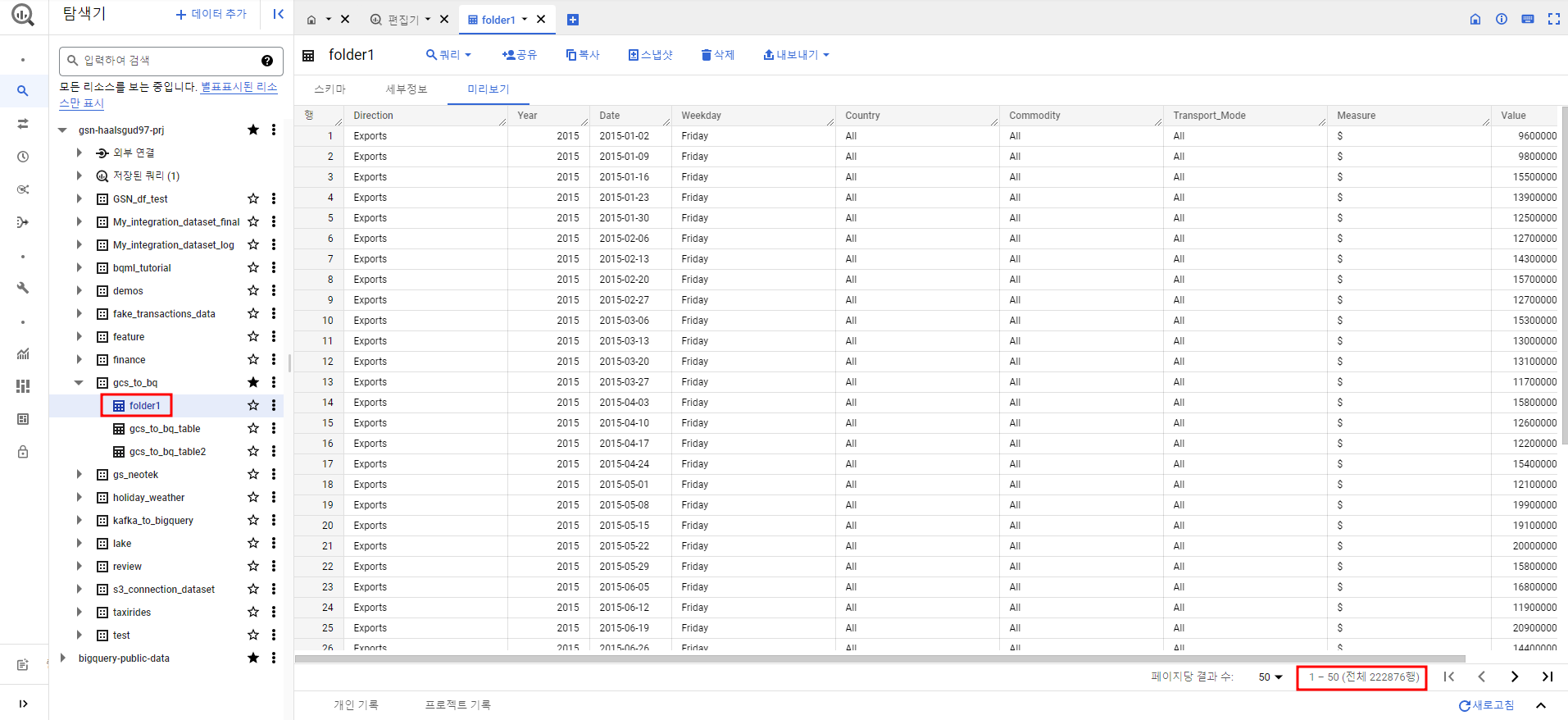
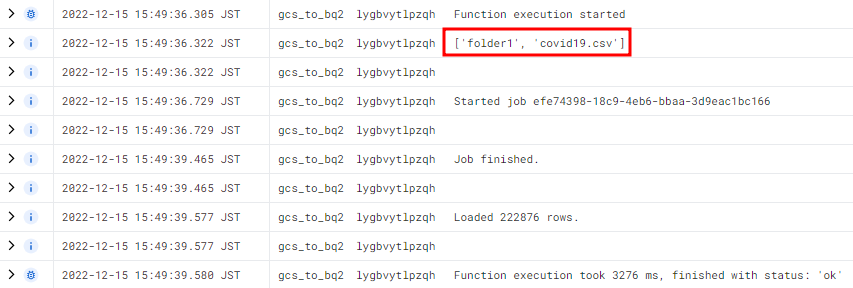
코드에서 중간에 file_name을 print 해줬다.
Cloud Functions 로그를 보면 /를 기준으로 파일 이름이 분리된 형태를 알 수 있고 빅쿼리에 잘 적재된 것도 확인할 수 있다.
이제 같은 폴더에 csv파일을 하나 더 올려주자.

행이 하나 늘어난 것을 확인할 수 있다.
사실 버킷에서 년단위 or 월단위 데이터들을 따로 폴더로 구분해줄 필요가 없다고 한다면 시간 관련 라이브러리를 사용하여 간단하게 구현할 수 있다.
import datetime
today = datetime.date.today()
#연 단위일 경우
y = str(today.year)
table_id = '<테이블 ID>_' + y
#월 단위일 경우
m = str(today.month)
table_id = '<테이블 ID>_' + y + '_' + m
이러면 같은 년도 or 같은 월에 들어오는 데이터들은 자동으로 한 테이블에 쌓이게 된다.
