
특정문자열을 추출 해야 할 때가 있는데 이전에는 아스키코드를 이용했었다면 현재는 정규표현식이 자주 사용되어진다. ( *단 아래 예시의 정규표현식으로 모든 추출에 적용할 수 있지는 않으므로 스스로 실제 검증을 해봐야한다)
1. 아스키코드를 이용한 한글,영어,숫자,특수문자 추출
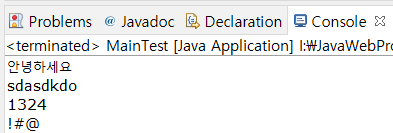
String str4 = "안녕하세요sdasd13kdo24!#@";
String hangule = "";
String english = "";
String num = "";
String specialStr = "";
char [] charArray = str4.toCharArray(); // .toCharArray() --> 문자 배열로 변환
for(int i=0; i<charArray.length; i++) {
char cl = charArray[i];
if('가'<=cl && '힣'>=cl) { // 한글추출
hangule += Character.toString(cl);
}else if('a'<=cl && 'z'>=cl) { // 영어추출
english += Character.toString(cl);
}else if(Character.isDigit(cl)) { // 숫자추출
num += Character.toString(cl);
}else{ // 특수문자 추출
specialStr += Character.toString(cl);
}
}
System.out.println(hangule);
System.out.println(english);
System.out.println(num);
System.out.println(specialStr);결과는 다음과 같다.
- 정규표현식을 이용한 한글,영어,숫자 추출
String regexNum = "^[0-9]*$"; // 숫자 정규표현식
String regexHan = "^[가-힣]*$"; // 한글 정규표현식
String regexEng = "^[a-zA-Z]*$"; // 영문자 정규표현식
String code1 = "1234";
String code2 = "안녕 하세요";
String code3 = "asdgas";
String replaceCode2 = code2.replaceAll("\\p{Z}", "");
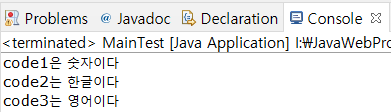
if(code1.matches(regexNum)) {
System.out.println("code1은 숫자이다");
}else {
System.out.println("code1은 숫자가 아니다");
}
if(replaceCode2.matches(regexHan)) {
System.out.println("code2는 한글이다");
}else {
System.out.println("code2는 한글이 아니다");
}
if(code3.matches(regexEng)) {
System.out.println("code3는 영어이다");
}else {
System.out.println("code3는 영어가 아니다");
}이때 code2="안녕 하세요" 에서 공백이 한칸 존재하는데 전부 한글임에도 불구하고 '한글이 아니다' 라는 결과가 나오게 된다. 이는 공백이 존재한다면 제대로 구분을 지을수없다는것인데 이를 방지하기위해 .replaceAll 메서드를 사용하여 한칸의 공백을 공백이 없는것으로 대체한다.
결과값은 다음과 같다.

꾸준하게