
집계 함수
대상 데이터를 특정 그룹으로 묶은 다음에 총합, 평균, 최댓값, 최솟값등을 구하는 함수.
WORKER 테이블을 다음과 같이 가정한다.
| WORKER_ID | NAME | JOB | SALARY |
|---|---|---|---|
| 7369 | SMITH | ANALYST | 800 |
| 7499 | ALLEN | SALEMAN | 1600 |
| 7521 | JOHNES | MANAGER | 2450 |
| 7566 | BLAKE | MANAGER | 5000 |
| 7654 | JAMES | ANALYST | 3000 |
집계 함수의 종류
- COUNT (expr)
전체 row수를 반환하는 집계 함수.
--예시
select count(*) from worker; // 결과 COUNT(*) : 5
select count(job) from worker; // 결과 COUNT(*) : 5
- DISTINCT
중복 컬럼값을 제거하는 것.
--예시
select distinct job from worker; // 결과 JOB : SALEMAN, MANAGER, ANALYST
select count(distinct job) from worker; // 결과 COUNT(DISTINCTJOB) : 3
- SUM(expr)
expr의 전체 합계를 반환하는 함수
--예시
select sum(salary) from worker; // 결과 SUM(SALARY) : 12850
- AVG(expr)
expr의 평균값을 반환하는 함수
--예시
select avg(salary) from worker; // 결과 AVG(SALARY) : 2570
- MAX(expr), MIN(expr)
MAX는 최댓값, MIN은 최솟값을 반환
--예시
select MIN(salary), MAX(salary) from worker; // 결과 MIN(SALARY) : 800
// MAX(SALARY) : 5000
- GROUP BY 절, HAVING 절
GROUP BY 절은 전체가 아닌 특정 그룹으로 묶어 데이터를 집계하는 용도로 사용.
HAVING 절은 GROUP BY 다음에 위치하여 다시 한번 필터를 거는 용도로 사용.
--GROUP BY 예시
select job, sum(salary), avg(salary) from worker group by job;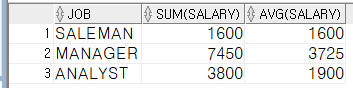
--HAVING 예시
select job, sum(salary), avg(salary) from worker group by job having sum(salary)>=1900;
출처
- 오라클 SQL과 PL/SQL을 다루는 기술 (책)

꾸준하게