kaggle에서의 입문 프로젝트로 제일 첫번째로 많이 접하는 프로젝트.
- competition은 간단: 머신러닝을 이용하여 모델을 생성하고 그 모델로 타이타닉 어떤 승객들이 살았는지 예측하기. → 타이타닉 승객 데이터(name, age, price of ticket, etc)으로 누가 살아남고 누가 죽는지를 예측하기.
competing할 준비가 되었다면 "Join Competition" 버튼을 누르고 competition data를 받을 수 있다. Alexis Cook's Titanic Tutorial 이라고 있는데 차근차근 읽어보면서 따라가면 좋을 것 같다.
The challenge
The sinking of the Titanic is one of the most infamous(악명 높은) shipwrecks(난파선) in history.
On April 15, 1912, during her maiden voyage, the widely considered "unsinkable" RMS Titanic sank after colliding(충돌하다) with an iceberg(빙산). Unfortunately, there weren't enough lifeboats for everyone onboard, resulting in the deadth of 1502 out of 2224 passengers and crew.
While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
In thie challenge, we ask you to build a preditive model that answers the question: "what sorts of people were more likely to survive?" using passenger data (ie name, age, gender, socio-economic class, etc).
Titanic Tutorial
위의 튜토리얼을 읽으면서 진행할 것.
1. Join the competition
2. New notebook
노트북을 시작하면 제일 처음에 있는 코드를 실행시킨다. 그러면 /kaggle/input/titanic/에 파일 3개가 저장된다.
- train.csv
- test.csv
- gender_submission.csv
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current sessionLoad data
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
trin_data.head()
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()모델 생성
튜토리얼에서는 random forest model을 사용하여서 예측 모델을 만들 것으로 보인다.
- 모델은 여러개의 "트리들"로 구성된다. "트리"는 각 승객들의 데이터로 살았는지 아닌지를 투표한다. 그 투표로 random forest model은 민주적인 결정을 한다. 많은 투표를 받은 결과가 win!
from sklearn.ensemble import RandomForestClassifier
y = train_data['Survived']
features = ['Pclass', 'Sex', 'SibSp', 'Parch']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
# n_estimators: 트리의 갯수, max_depth: 트리의 최대 깊이, random_state: 랜덤,,,?
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
moedel.fit(X,y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId' : test_data.PassengerId, 'Survived' : predictions})
output.to_csv('submission.csv', index=False)
print('Your submission was successfully saved!')코드 저장하기
우측 상단에 있는 save version으로 완전히 저장한 후, Open in Viewer로 가서 Data-submission.csv파일을 submit하면 제출 완료!
*여기서 주의할 점이 있음. output.to_csv('파일명.csv', index=False)로 하지 않으면 오류가 발생하여 제출 error 발생!! 주의할 것!!
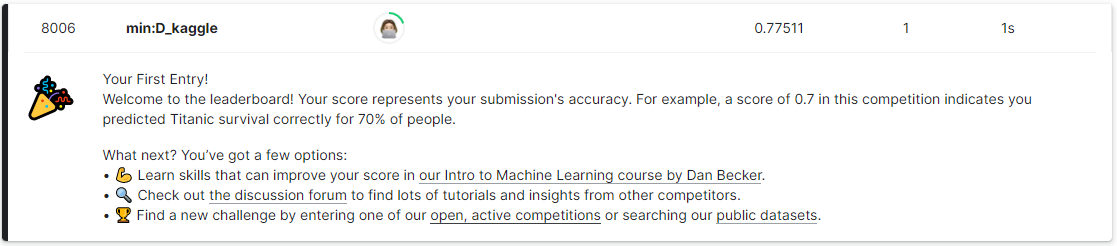
왕@@!# 캐글 리더보드 첫 안착 성공😁