정리
아직 챗봇 i Open Builder 신청 승인이 나지않아 챗봇에는 접근도 못해본 상황이다. 그래서 그냥 서버를 미리 만들어놓기로 했다. 어차피 RSS 코드 긁어와서 정제하고 출력하고 데이터베이스 짜고 하면은 시간 걸리는데 일찍 만드는 편이 편할 것이다.
챗봇 출력은 안되니 우선 index.html로 렌더링을 돌리면서 확인해보기로 했다.
우선 현재 할 수 있는 것은 마무리했고 남은 것은 신청 승인을 받은 후 챗봇을 조작하는 일이다. 최소 이번주 내로 대부분을 완료할 생각.
렌더링
### Home
@app.route('/')
def home():
return render_template('index.html')RSS 파싱
1시간 동안 beautifulsoup4로 RSS 긁어오려 씨름하다 포기하고 RSS 라이브러리를 사용했다. 사용한 라이브러리는 feedparser. RSS 한정 엄청 간편하다..
게시판 RSS를 파싱해서 글 목록(item)을 추출하는데 성공했다. 가져온 글 목록은 게시판에서 최근 시간순으로 상위 10개의 글이므로, 현재 날짜의 글만 가져오도록 수정했다.
app.py
import feedparser as fp
def crawlingRSS(url):
content = fp.parse(url)
data = []
for entry in content.entries:
pubDate = entry.published.split()[0]
todayDate = date.today().strftime("%Y-%m-%d")
todayDate = "2023-03-02"
if pubDate == todayDate:
print(pubDate, todayDate)
data += [[entry.title, entry.link, entry.published]]
#print(data)
return datadata 콘솔 출력
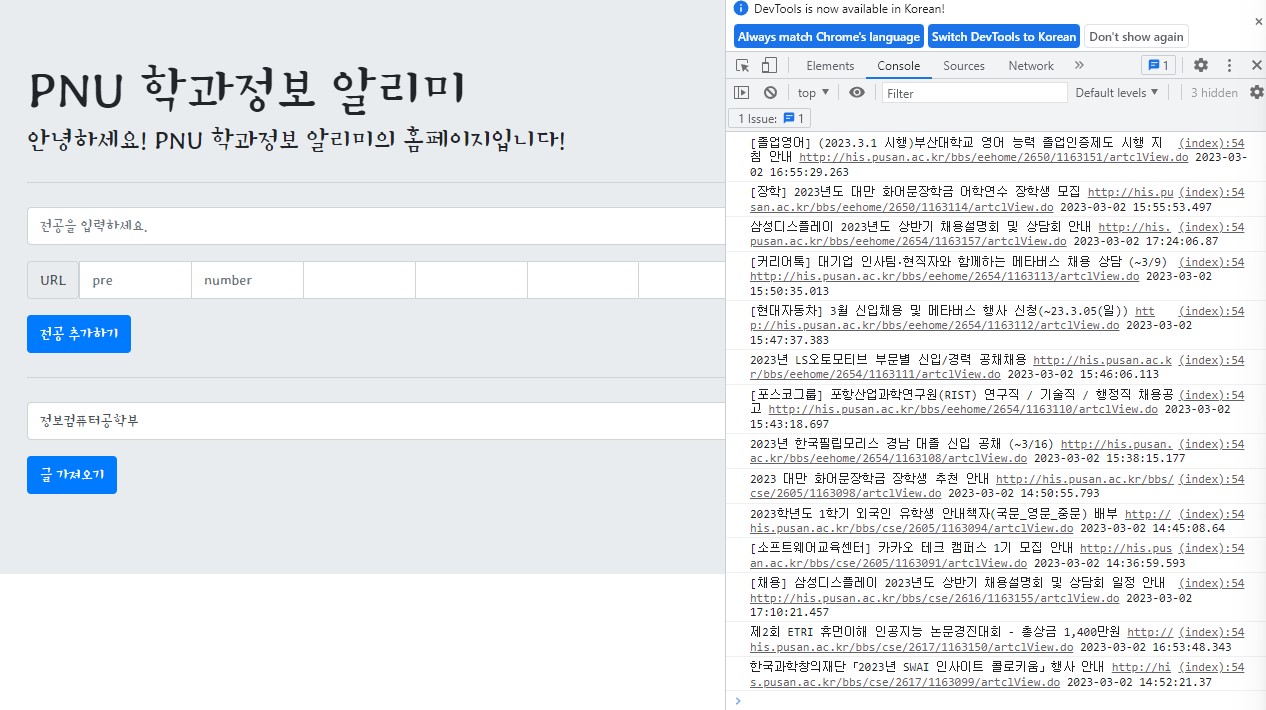
새 전공과 URL 추가하기
오직 관리자만이 전공명과 학과 홈페이지를 등록할 수 있다. 이상한 주소가 등록되거나 주소에 오탈자가 생기면 안되니까 그러하다. 그래서 index.html은 관리자만이 사용하는 것을 가정하고 설계했다. 어차피 AWS 개인서버에 돌릴 것이라 사용자들이 접근가능한 것은 챗봇 뿐이다.
빈 데이터가 데이터베이스에 저장되면 안되기에 if url == '': 문자열 데이터가 존재하는지 확인하고 데이터가 존재하면 데이터베이스에 insert_one으로 저장한다.
부산대학교 RSS 주소를 보니 아래와 같은 패턴을 띈다.
패턴을 잘 쪼개면 효율성이 높아질 것 같은데, 정말로 모든 학과의 RSS 주소가 위와 같은 패턴인지 확인할 수 없어서 일단 현체제를 유지할 생각이다.
index