[논문리뷰] Diffusion-Based Scene Graph to Image Generation with Masked Constrastive Pre-Training
Abstract
Scene graph와 같이 graph-structured를 input으로 받은 이미지 생성은 이미지의 옵젝트와 옵젝트들의 관계로 그래프에 노드와 연결을 배치한다는 독특한 챌린지가 있다.
가장 많이 사용하는 방법은 scene layouts을 이용하는 것인데, scene image의 coarse 구조를 포착해서 나타내는 image-liked representation 이다.
(이미지의 low한 구조를 이미지와 비슷한 형태로 나타내는 방법)
Scene layout은 수작업으로 만들어지기 때문에, scene 정렬이 최적화되지 않아 원본 scene과 생성된 scene graph의 사이의 차선의 적합성을 제공한다.
이 문제를 다루기 위해, Scene graph embedding을 이미지의 배열과 직접 최적화하여 학습하는 방법을 제시한다.
특히, 우리는 masked autoencoding loss와 constrastive loss 라는 두가지 손실함수에 의존하여 해당하는 이미지를 예측하는 scene graph에서 global 및 local 정보를 모두 추출하도록 encoder를 pretrained 한다.
전자는 무작위로 masking된 이미지 영역들을 재구성하면서 embedding을 훈련시키고, 반면 후자는 scene graph에 따라 compliant(준수) 이미지와 non-compliant image를 구별하기 위해 embedding을 훈련시킨다.
이러한 embedding을 고려하여 scene graph에서 이미지를 생성하는 latent diffusion model을 만든다.
SGDiff인 결과 방법론은, scene graph의 node와 connection 을 수정하며 생성된 이미지의 semantic 조작(의미론적 조작)을 허용한다.
Visual Genome 및 COCO-Stuff 데이터셋에서 SGdiff가 Inception Score 및 FID metrics 로 측정된 SOTA를 능가하는 것을 보여준다.
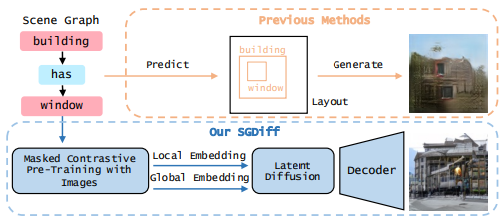
Figure 1. SGDiff vs Previous methods.
Scene layout과 같은 수동으로 지정된 scene graph representation 에 의존하는 대신, mask된 auto encoding loss와 canstract training으로 scene graph embedding을 pretrained 하여 graph-image align에 대한 prediction power을 극대화한다. 이러한 embedding 조건으로 우리의 latent diffusion model인 SGDiff는 scene graph에서 image generation에 대한 이전 연구작업들을 능가한다.
즉, 이전 scene graph는 scene graph 그리고, 직접 layout 만들고 이미지 생성했다면, SGDiff는 scene graph에서 Masked 와 Constrastive라는 pre-training 과정을 거쳐서 Local embedding과 Global embedding을 뽑아낸 뒤, Latent Diffusion 모델에 넣어서 이미지를 생성한다.
Introduction
Image generation 은 주로 diffusion 과 score-based generative model들의 성공 덕분에 지난 몇년간 엄청난 발전을 이루었다. 이러한 방법을 사용하면 lable, caption, segmentation masks, sketches, stock paintings등 다양한 형식을 통해 사용자가 지정할 수 있는 사실적이고 다양한 이미지 샘플들을 만들 수 있다.
그러나 이러한 유형의 specification들은 이미지의 여러 개체간의 복잡한 관계에 있어서는 종종 부족하다.
**대신 scene graph는 다음을 제공한다.
사물과 그것들의 상호 관계를 간결하고 정확하게 묘사하는 방법을 제공한다. 따라서 복잡한 장면을 합성하는 수단으로 scene graph를 기반으로 image generation을 연구하는 것은 중요하다. **
이전 Scene graph and layout problems
Scene graph에서 이미지를 생성할 때 중요한 과제는 결과 이미지가 input scene graph와 밀접하게 일치하는지 확인하는 것이다. 이를 위해 generative model은 image 와 graph 라는 크게 다른 두 데이터 도메인 간의 대응관계를 이해할 수 있어야한다.
기존의 방법은 주로 scene graph 의 image-liked representation을 사용하여 이 부분을 해결한다. 주로 scene layout 형태를 사용해서,Image generative process를 coarse sketches 만들어서 guide한다. 이러한 sketch는 generative model에 의해 refine되어 scene graph에 의해 주어진 명세사항(specification)을 따르는 현실적인 이미지를 생성한다.
Scene layout과 같은 intermediate representation은 유용할 수 있지만, 수동으로 제작되고 image와 graph간 alignment를 용이하게 하도록 특별하게 설계되진 않았다. 예를 들어 scene layout의 경우 scene graph의 노드는 일반적으로 bounding box에 mapping 되고 connection 은 spatial layout에 mapping된다. (image랑 graph를 직접 대응 x)
그러나 scene graph내의 모든 connection 이 "eating" 이나 "looking at" 과 같은 spatial layout 으로 정확하게 변환되지 않는다.
또한 "behind", "inside", "in front of" 와 같은 몇몇 relation 들은 모두 scene layout에서 유사한 spatial relations에 대응하므로, ambiguity가 있다. 이러한 intermediate scene layout representation 은 downstream generative model의 훈련을 복잡하게 만드는 외부 정보(extraneous information) 을 포함할 수도 있다.
이를 위해 제안한 모델
이러한 한계를 극복하기 위해 scene graph와 image간의 alignment를 명시적으로 최대화하는 intermediate representation training을 제안한다. 우리는 figure1에서 우리 접근방법을 보여줬다.
Pre-trained
특히, 우리는 graph-image pair 데이터셋에서 scene graph encoder를 pre-trained 하여 scene graph에서 local 및 global 정보를 모두 추출하는 embedding을 생성하는 동시에 image와의 alignment를 최대화한다.
local 정보 추출
local 정보를 추출하기 위해 image의 object를 무작위로 masking하고, encoder에서 획득한 masking되지 않은 영역과 embedding을 사용하여 누락된 부분을 재구성하는 masking된 auto encoding loss를 도입한다.
global 정보 추출
Grobal 정보를 얻기 위해, 우리는 constrastive learning을 활용하여 encoder가 scene-graph를 준수하거나 준수하지 않은 image를 구별하도록 training 한다.
두 embedding 합침
두 가지 접근 방식에서 얻은 embedding을 결합하여, graph와 image간의 alignment를 용이하게 하는 scene graph의 간결화된 intermediate represenation 을 얻는다.
Pretrained된 embedding의 도움을 받아 scene-graph에서 image를 생성하는 latent diffusion model을 구축하여 scene-graph embedding 효과를 보여준다.
Ablation studies(절제 연구) 를 통해 local 및 global embedding의 중요성을 평가하고, 전통적인 intermediate layout의 representation 에 비해 우리의 접근 방식이 갖는 분명한 이점을 보여준다.
SGDiff라고 하는 우리의 모델은 scene-graph의 정확한 local 및 global 구조를 캡처하는 image를 성공적으로 생성한다. 또한 우리 모델은 scene graph 조작을 통해 image의 semantic manipulation 을 가능하게 한다.
우리는 Visual Genome과 COCO-Stuff와 같은 표준 데이터셋에서 SGDiff를 평가하고, 질적과 양적인 비교 모든 측면에서 현재의 SOTO보다 성능이 우수하단걸 밝혀냈다.
Related Works (한계 부분만)
Diffusion Models for Conditional Image Synthesis.
(~~~ diffusion 모델 발전 장난 아니다 대충 이런 내용)
Diffusion based conditional image synthesis는 발전했지만, 그래프 구조 데이터에서 이미지를 생성하는 것은 충분히 연구되지 않았다. 우리는 self-supervised learning으로 구성된 새로운 scene-graph embedding을 사용하여 scene graph에서 image generation 을 위한 첫 번째 diffusion 모델을 설계함으로써 이 격차를 메운다.
Image Generation from Scene Graphs.
(~~대부분 scene layout 기반 내용)
수동으로 제작된 scene layout 대신 우리느 graph image alignment를 간결하고 예측하는 training scene graph embedding을 제안한다. 그런 다음 이러한 embedding을 사용하여 scene graph에서 이미지 생성에 대한 latent diffusion model을 구축하여 scene graph layout의 한계를 피한다.
Method
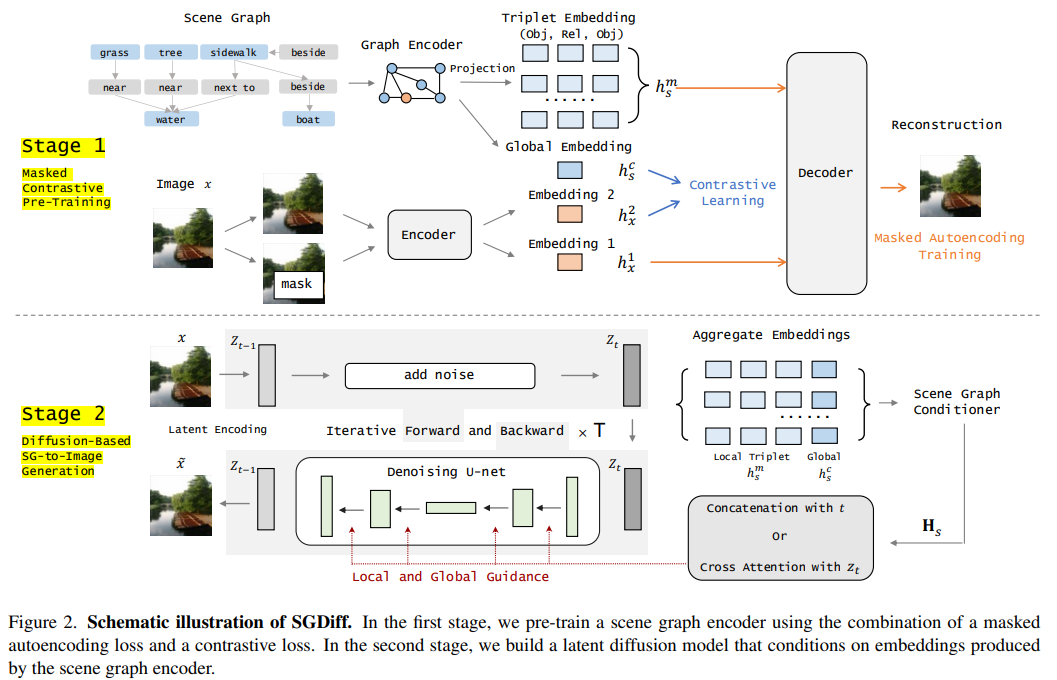
Figure2. SGDiff Schematic illustration
첫 번째 단계에서는 masking 된 auto encodding loss와 constrative loss의 조합을 사용하여 scene graph encoder를 사전학습한다. 두 번째 단계에서는 scene-graph encoder에 의해 생성된 embedding을 조건화하는 latent diffusion 모델을 구축한다.
Experimental Result(필요해 보이는것만)
Qualitative Evalutions
Semantic Image Manipulation
생성된 이미지와 scene-graph간의 semantic consistency 를 입증하기 위해 SGDiff를 적용하여 scene-graph input의 object와 relation 을 수정하여 이미지 샘플을 조작한다.

figure 4 에 나타난 바와 같이, SGDiff는 object 와 relation 에 대해 준수한 조작 결과를 생성하고, 동일한 scene-graph에서 조건화되었을 때 perceptual 하게 다양한 이미지를 합성할 수 있었다. (<- multi-concept에서 적용 가능할 듯??)
결과는 우리 모델이 masking된 constractive pretrained training을 통해 학습한 scene-graph embedding을 효과적으로 활용할 수 있음을 보여준다.
Ablation Studied
Retrieval Tasks
먼저 graph대 image 및 image 대 graph 검색 실험을 통해 mask된 auto encoding loss와 constractive loss이 cross-modal semantic alignment에 미치는 영향을 평가한다.
graph 대 image 검색에서, 우리는 scene-graph embedding과 image embedding을 사용하여 주어진 scene graph에 대해 가장 semantic하게 유사한 image 를 검색한 다음, 주어진 데이터셋에서 정확하게 쌍을 이룬 이미지를 찾는 정확도를 보고한다. image-graph 검색은 동일하게 정의된다.
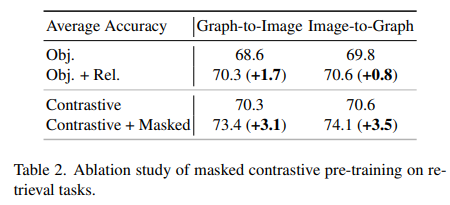
위 표에 결과가 나와있고,
여기서 "obj"는 object embedding만 훈련시키는 실험을 의미
"obj" + "Rel" 는 object와 relation embedding을 모두 훈련시키는 것을 의미한다.
우리는 두 embedding을 모두 사용하면 모든 검색 작업의 성능이 향상된 다는 것을 관찰했다. Constrative loss만으로 graph대 image와 image대 graph 검색에서 이미 70% 이상의 정확도를 얻을 수 있었다. Masking된 auto encoding loss 를 추가하면 더 정확도가 향상되어 더 나은 graph image 정렬을 보여준다.
Generation from Scene Graphs <- Scene graph 적용이 어떤 효과 냈는지

Ont-hot embedding 및 scene layout 에 비교하여, 우리 masked 된 pretrained 및 constrative embedding을 통한 SGDiff가 더 현실적이로 장면 그래프를 더 잘 준수하는 이미지를 생성할 수 있음을 확인할 수 있다.
Constrative와 달리 Masked는 embedding이 더 세분화된 객체 세부 사항으로 로컬 구조를 더 잘 캡쳐하는 것을, 대조 방법은 global 구조를 더 잘 캡처하는 것을 알 수 있다.
Conclusion
이 논문은 scene-graph 에서 이미지를 생성하기 위한 새로운 프레임워크인 SGDiff를 제안한다.
SGDiff는 마스크된 constrative pretrained training approach를 사용하여 scene-graph와 image간의 alignment를 개선하는 동시에 scalability(확장성) 및 생성 품질 향상을 위해 latent diffusion 을 활용하는 scene-graph embedding을 얻는다.
결과적으로 SGDiff는 이전의 수동 방법보다 더 사실적이고 호환되는 이미지를 생성한다.
또한 SGDiff는 이미지 생성을 semantic 하게 제어할 수 있도록 하여 scene-graph 편집을 통해 이미지를 더 쉽게 조작할 수 있게 한다.
