오늘 학습 내용
1. Multi-modal learning
2. Multi-modal tasks - Visual data & Text
1.Multi-modal learning
- Multi-modal 은 여러 가지 형태와 의미로 컴퓨터와 대화하는 환경을 뜻한다.
- 따라서, Multi-modal Learning 은 다양한 형태의 데이터를 입력 데이터로 사용한다는 의미이다.

Challenge for Multi-Modal Learning
1. Different representations between modalities

2. Unbalance between heterogeneous feature spaces

3. May a model be biased on a specific modality

1.Multi-modal tasks - Visual data & Text
Text Embedding
1.Sparse Representation
- One-Hot Encoding 을 통해 단어를 표현하는 방법
Ex) 강아지 (index=4) = [ 0 0 0 0 1 0 0 0 0... 0]
- 단어의 개수가 늘어나면 늘어 날수록, 벡터의 차원이 한없이 커진다.
→ 매우 비효율적이다.
2.Dense Representation
- Sparse Representation 과 달리, 벡터의 차원크기를 직접 설정한다.
Ex) 강아지 (n=128) = [0.2 1.8 1.1 -2 ... 0.3] #128 차원으로 표현
- Text 를 이러한 Dense Representation 으로 표현하는 방법을 Text Embedding 이라한다.
Text Embedding 시 의미가 유사한 단어들은 유사한 벡터값을 가지며, 거리가 가깝다.
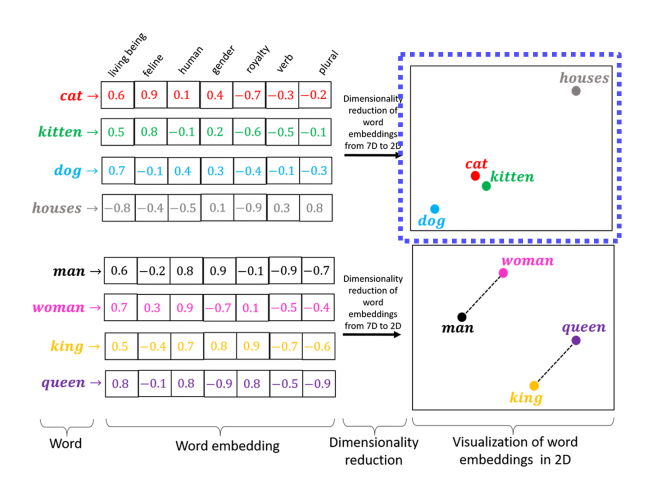
Word2Vec

- Text Embedding 방법론 중 하나이다.
- 분산 표현(Distributed Representation) 방법을 사용한다.
분산 표현 (Distributed Representation)
- "비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다" 라는 분포 가설을 따른다.
- 예로, 강아지란 단어는 귀엽다, 예쁘다 라는 단어와 자주 등장하는데
분산 표현을 사용하여 Embedding 시, 해당 단어들은 유사한 벡터값을 가지며 벡터 공간상에서 거리가 가깝다.
CBOW
- CBOW 는 주변의 단어들의 입력으로 중간에 있는 단어들을 예측하는 방식
- 예문 : "The fat cat sat on the mat"
위의 예문에 있어서 ['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측하는 것이다.
- window 란, 중심 단어를 예측하기 위해 앞, 뒤로 몇 개의 단어를 볼지 결정하는 범위이다.
[ window = 2 일때, 데이터셋 구성 ]
- Input Layer 에 주변단어들을 넣고, Output Layer에서 중심 단어가 나오도록 학습.

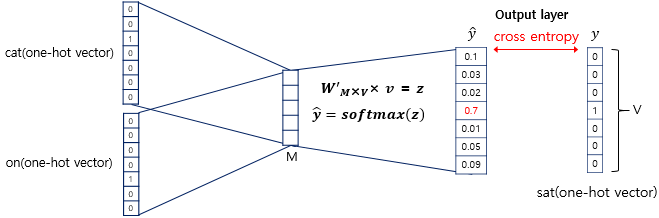
Skip-gram
- Skip-gram 는 중심 단어의 입력으로 주변 단어들을 예측하는 방식
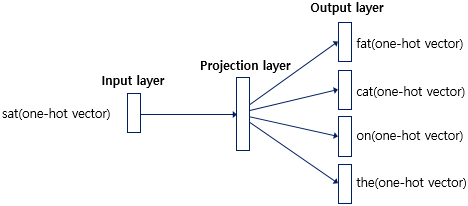
Matching

Image Tagging
- 주어진 이미지로 부터 알맞은 Tag를 만들어내거나, Tag 로 부터 Image 를 Retreive 한다.
Structure
- Text Data 와 Image Data 로 부터 동일한 차원의 Feature Vector 를 추출한다.
- 이때, 각각 Pre-trained 된 Unimodal Model 들을 사용한다.
- 각 Feature Vector 를 올바른 Text, Image Pair 는 서로 가깝게, 잘못된 Pair는 거리가 서로 멀게 Embedding Space 상에 나타낸다. (Joint Embedding)

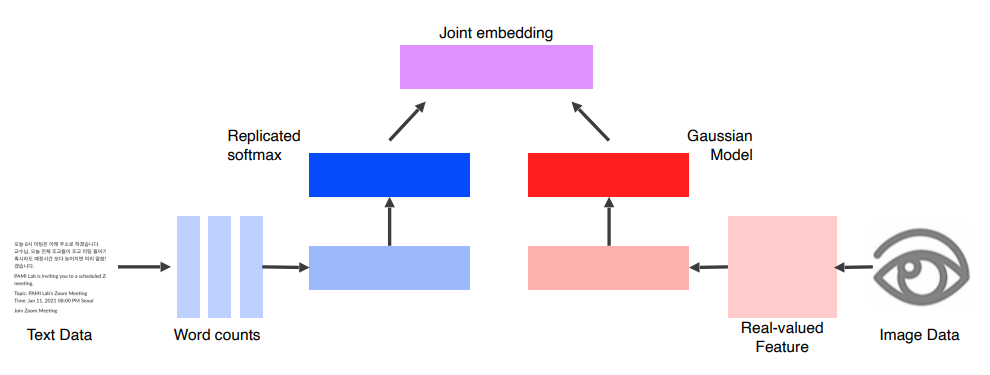
Translating

Image Captioning
- 이미지가 주어지면 해당 이미지에 대한 묘사를 출력한다.

- Image 에 대해서는 CNN 모델을, Sentence 에 대해서는 RNN 모델을 사용한다

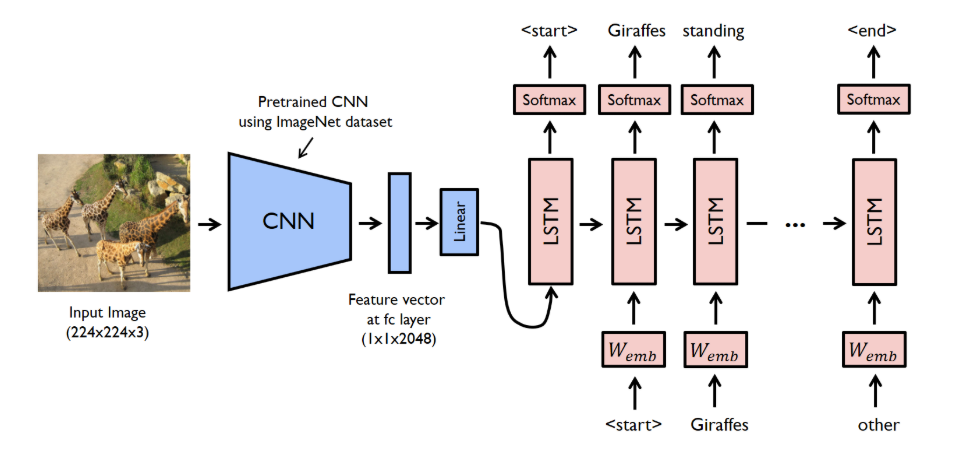
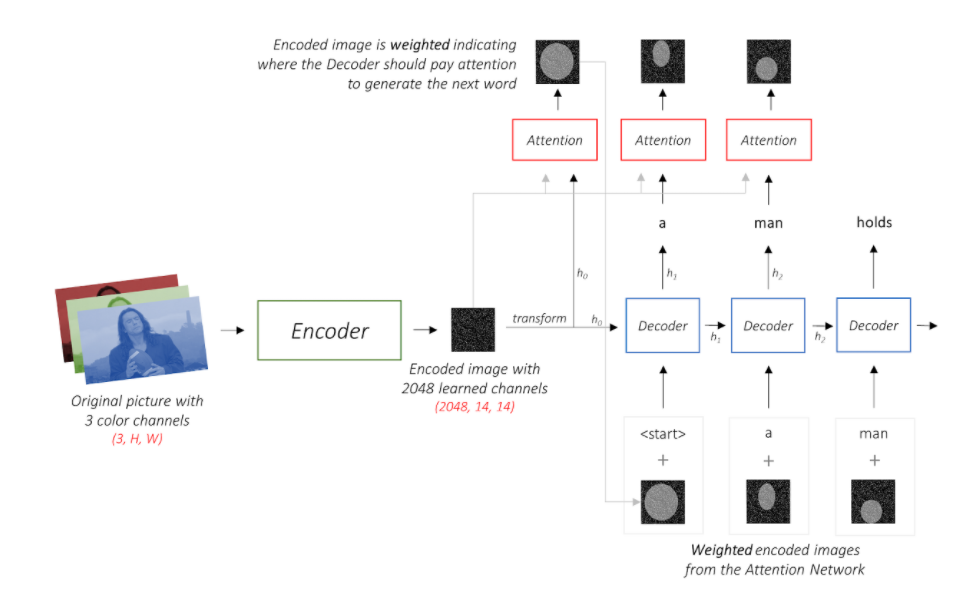
Show and Tell
- CNN Model 로 이루어진 Encoder 단과 LSTM 으로 이루어진 Decoder 단으로 나뉨.
- Image 를 Pre-trained 된 CNN 모델에 넣어 FC 층의 Feature Vector 를 구한다.
- 추출된 Feature Vector 를 LSTM 의 Input 으로 넣어 Sentence 를 Predict 한다.
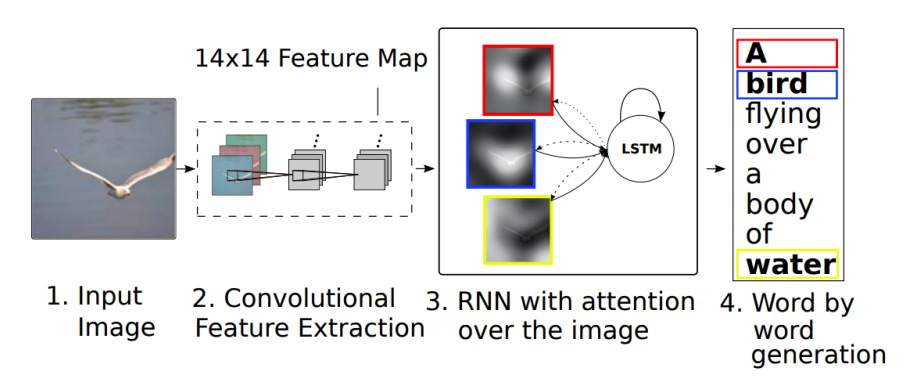
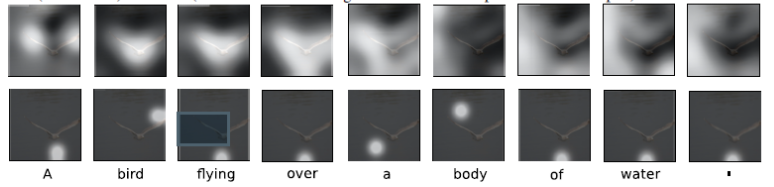
Show, Attend and Tell
Encoder

- CNN 마지막 FC Layer의 Feature Vector 가 아닌, 그 이전의 Convolution Feature Map을 사용한다.
- FC Layer는 3차원 컬러이미지를 Flatten 시키기 떄문에, 공간 정보가 유실되어 제대로 Attention 을 할 수 없다.
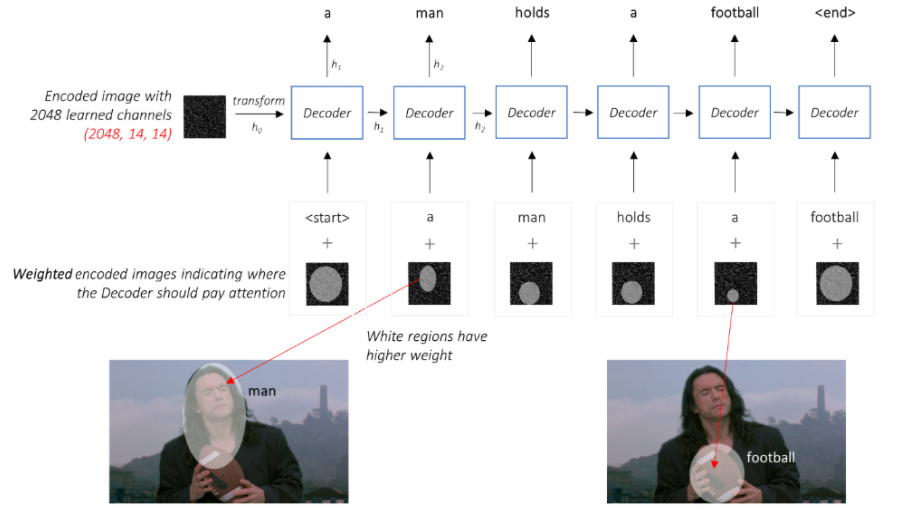
Decoder
- Decoder는 Encoder 의 Feature Map 을 Input 으로 받아 Sentence 를 Predict한다.
- 이때, Show and Tell 과는 다르게 이전 단어 뿐만 아니라, Attention 된 Feature Map을 같이 사용하여 다음 단어를 Predict 한다.
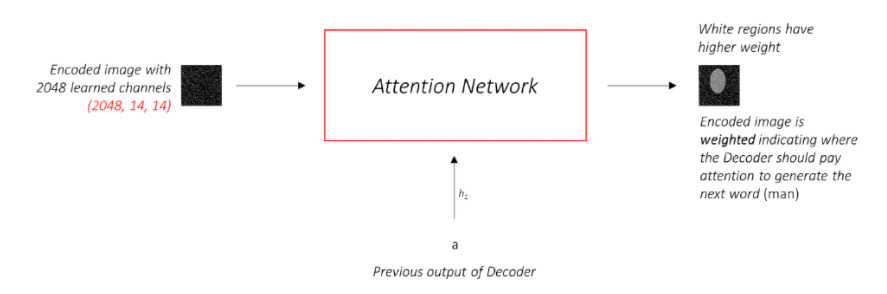
Attention Network
- Input 으로 들어가는 Feature Map 은 Attention Network 를 통해 Weight 가 조정되어 Attentioned 된 Feature Map이 된다.
- Soft Attention 은 위와 같이 Weight 조정을 통해, Feature Map 전체를 바라보면서 작동하는 것이다.
- Hard Attention 은 0,1 의 Sampling 을 통해 Feature Map 의 일부 영역만을 바라 보면서 작동하는 것이다.
Structure
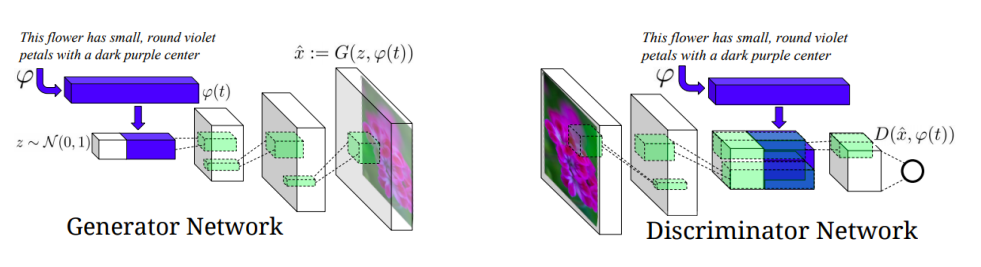
Text to image by generative model
- Text 를 Embedding 한 후, Random 한 Gaussian 값과 함께 Generator 에 넘긴다.
→Random 한 Guassian 값을 넣음으로써, 항상 동일한 이미지가 생성되는 것을 방지
- Discriminator 의 중간 Layer에 Embedding 된 Text 값을 같이 넣어줌으로써, 현재 이미지가 해당 Text 와 매칭되는 이미지가 맞는지 식별하도록 학습한다.
Referencing

Visual Question Answering
- 이미지와 질문이 주어지면, 해당 이미지를 참고하여 정답을 도출한다.
Structure

- CNN 과 LSTM 을 거쳐 나온 같은 차원의 Vector 들을 Joint Embedding 시킨다.
- 이후 Softmax 를 통하여, 가장 높은 확률의 답을 출력한다.
