맨 처음 필기자료 작성
✔ Function
함수형 프로그래밍 관련 함수
map
- 데이터를 변환하기 위한 함수
- 이 함수에 하나의 매개변수를 갖고 하나의 데이터를 리턴하는 함수를 대입하면 리턴하는 데이터들을 모아서 리턴합니다.
- 반복문을 이용해서 직접 변환하는 것 보다 속도가 훨씬 빠릅니다.
# 숫자 list를 가지고 제곱한 list를 생성 li=[i for i in range(10000)] #0부터 9999까지의 숫자를 가지고 list를 생성 temp=[] for x in li: temp.append(x*x) print(temp)
def f(x): return x*x #한줄이면 lambda로 바꿀 수 있다. temp=list(map(f,li)) #함수를 먼저주고 데이터를 뒤에다 줘야한다. print(temp)
temp =list(map(lambda x: x*x, li)) #함수의 내용이 한줄이기에 람다로 처리 가능 print(temp)
ar=["Hello", "mino", "5894"] def f(x): if len(x)>3: return x[0:3]+"..." return x temp=list(map(f,ar)) print(temp)
filter
- 데이터의 모임에서 조건에 맞는 데이터만 골라서 데이터의 모임으로 리턴하는 함수
- 매개변수로 하나의 데이터를 받아서 bool을 리턴하는 함수를 대입해야 합니다.
ar1=["a","b","c",None] #결측치 여부 확인 print(None in ar1) #in : 앞에 애가 뒤에 애 안에 있니?(탐색) #결측치 제거 def f1(x): return x!=None ar1=list(filter(f1,ar1)) print(ar1) #이름이 3자 이상인 데이터만 추출 def f2(x): return len(x)>=3 #None type은 len사용 불가야 #결국 결측값을 지워야 하겠구나! result=list(filter(f2,ar1)) print(result) #문자열 비교 가능? def f3(x): return x[0]>="아" and x[0]<"자" result3=list(filter(f3,ar1)) print(result3) #ar1=list(filter(lambda x: x!None, ar1)) #result=list(filter(lambda x: len(x)>=3, ar1)) #result3=list(filter(lambda x: x[0]>="아" and x[0]<"자", ar1))
# 데이터가 collection에 포험되어 있는지 확인 : in(반대는 not in) ar=["1","2","3"] kwlist=["2"] #ar에서 kwlist에 있는거 뺴고 list생성 ar_new=list(filter(lambda x: x not in kwlist, ar)) print(ar_new) #글자의 개수를 세서 하거나, 공백을 제거하였을 때 kwlist에 있는지
reduce
- 데이터의 모임을 가지고 연산을 수행해서 하나의 결과를 만들어내는 작업
- 합계, 평균, 최대값 등..
- python에서 예전에는 기본함수였는데, 지금은 functools 패키지의 함수로 변경되었다.
- 매개변수가 2개이고 하나의 결과를 만들어내는 함수를 대입해야 합니다.
from functools import reduce result=reduce(lambda x, y : x*y, [1,2,3,4]) print(result)
zip
- 여러 개의 데이터 모임을 받아서 하나의 데이터로 묶어주는 함수
- 데이터는 튜플로 묶어 줍니다.
- 데이터의 모임에 데이터 개수가 일치해야 합니다.
- pandas 썼으면 알 것입니다.
key=["초등학교","중학교","고등학교"] value=["a초등학교","b중학교","c고등학교"] print(list(zip(key,value))) print(dict(zip(key,value)))진짜 단순히 묶어주는 역할입니다.
High Order Function - 고위함수
- 함수를 매개변수로 받거나 함수를 리턴하는 함수
- 위에 나온게 다 고위함수
중첩함수
- 파이썬에서는 함수 내부에 함수를 만들 수 있습니다.
- 내부에 만든 함수는 자신을 포함한 함수의 데이터에 접근하는 것이 가능합니다.
- 함수를 만들어서 호출을 하면 먼저 함수 내부를 확인해서 함수 내부에 대입문이 있으면 대입문에 사용된 이름들을 로컬 변수로 간주를 하고, 함수를 호출할 때 변수의 이름만을 사용하면 로컬에 있는 변수를 호출하는 문장으로 해석하고, 로컬변수가 아닌 변수 이름을 사용하면 함수 외부에서 만든 것으로 간주합니다.
def outer(): outer_data="함수 외부에서 만든 데이터" def inner(): print(outer_data) inner() outer()이 구문은 에러가 나지 않습니다.
inner를 호출할 때 outer_data는 함수 회부에 있는 oute_data로 해석이 되기 때문입니다.
def outer(): outer_data="함수 외부에서 만든 데이터" def inner(): print(outer_data) outer_data="함수 내부에서 만든 데이터" inner() outer() UnboundLocalError: local variable 'outer_data' referenced before assignment이 코드는 에러
outer_data가 만들어지기 전에 사용되었다고 해석해서 에러가 발생합니다.
def outer(): outer_data="함수 외부에서 만든 데이터" def inner(): outer_data="함수 내부에서 만든 데이터" print(outer_data) inner() print(outer_data) outer()과연 outer에 있는 출력은?
함수 외부에서 만든 데이터 가 출력이 된다.
왜냐? outer에서 불렀기 때문이다.
- 외부함수는 내부 함수의 데이터에 접근하는 것이 안됨
- 내부 함수는 함수 외부에서 직접 호출이 안됨
- 내부함수에 외부와 같은 것을 만들면 혼란스러우니 지양하자.
- 자기거는 자기만 하는것이 가장 좋다.
nonlocal 과 global
- 함수 내부에 nonlocal이나 global이라는 키워드와 함께 변수 이름을 기재하면, 함수 내부에서 변수 이름을 이용해서 지역변수를 만들 수 없게 됩니다.
- nonlocal을 기재한 경우는, 자신의 외부에서부터 데이터를 찾아가게 됩니다.
- global을 붙이면 최상위 레벨의 데이터를 사용합니다.
def outer(): outer_data="함수 외부에서 만든 데이터" def inner(): nonlocal outer_data # 함수 내부에 데이터를 생성하지 않고 # 외부 데이터 사용하기 위해 이름을 다시 등록 outer_data="함수 내부에서 만든 데이터" print(outer_data) inner() print(outer_data) outer()이렇게 된다면 outer_data는 inner에서 만들어 지는 것이 아니다.
결과물도 "함수 내부" 가 2번 나올 것이다.
outer_data="로컬에서 만든 데이터" def outer(): def inner(): global outer_data # 함수 내부에 데이터를 생성하지 않고 # 외부 데이터 사용하기 위해 이름을 다시 등록 outer_data="함수 내부에서 만든 데이터" print(outer_data) inner() print(outer_data) outer()이렇게 한다면 inner에서 nonlocal이 아닌 global로 바꿔야 한다. 왜냐하면 블록 밖에 있는 전역변수를 가져와 쓰는 것이기 때문이다.
- 동일한 이름의 변수를 여러 번 사용하면 이러한 문제들이 발생할 수 있기 때문에, 변수의 이름을 중첩되지 않게 잘 만들어야 하는데 예전에는 이 문제를 유효번위를 표시해서 해결했다.
- 로컬 변수의 이름 앞에는 언더바, 멤버 변수의 이름 앞에는 m+언더바, 전역변수의 앞에는 g+언더바를 붙이기도 했습니다.
closure
- 함수 내부에서 만든 함수를 리턴해서 함수 외부에서 함수 내부의 데이터를 변경할 목적으로 사용합니다.
- 함수 안에서 만든 데이터는 함수를 호출하고 나면 소멸됩니다.
- 함수 내부와 외부에서 데이터를 공유하고자 하는 경우, 전역변수를 만들어서 사용할 수 있는데, 주조적 프로그래밍이나 객체 지향 프로그래밍에서는 전역 변수를 만드는 것을 권장하지 않습니다.
- 이런 경우에는 closure를 이용해서 사용하기를 권장합니다.
def outer(): data=0 #data=data+1 #outer에서 만들어진 것이기 때문에, #outer에서만 사용 가능합니다.
def outer(): data=0 #자신을 감싸고 있는 #함수의 데이터를 수정하는 함수 def inner(): nonlocal data data=data+1 print(data) return inner #함수 호출해서 리턴하는 함수를 변수에 저장 closure=outer() closure() closure()이렇게 접근하면 closure를 이용해서 쉽게 접근 가능합니다.
Business Logic vs Common Concern
- 실제 업무 vs 업무와 직접적인 관련은 없지만 프로그램에 넣는 것
- common concern은 개발자 혼자서 가능하다.
- 개발자 / 경영 관리자
- 경영 관리자는 개발하는 사람이 아니다.
- 개발자는 경영 관리 등의 도메인지식이 없다.
- 결국 둘이 다 필요하다.
- 하지만 둘이 계속 같이 있을 수는 없다.
- 그럼 쪼개볼까?
def commonConcern1(): print("공통 관심 사항_1") def commonConcern2(): print("공통 관심 사항_2") def businessLogic(): print("비즈니스 로직") def transaction(): commonConcern1() businessLogic() commonConcern2() #이렇게 한다면 나 혼자 일하면 되는거고 #businessLogic 일때만 같이하면 된다. #이것이 모듈화 프로그래밍이다. #이후에는 또 파일까지 쪼개게 된다.이렇게 쪼개서 작업하는 것을 AoP이다.
- AoP : Aspect Oriented Programming
- 어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각 모듈화하겠다는 것
- 이렇게 분리해서 만드는거 해 본 적이 있나?
- 나는 없다.
- python 에서는 decorator를 사용합니다.
- @ class 입니다.
Decorator
- 로직을 수행하기 전이나 수행한 후에 해야 할 일을 별도의 메서드로 만들어두고 @함수이름 으로 대신하도록 하는 것
- 생성 작업이복잡하거나 알 필요가 없는 경우
- 또는 business logic과 common concern을 분리하고자 하는 경우
- business logic : 업무로직
- common concern : 공통 관심 사항 = 로깅, 벤치마크를 위한 테스트 코드 등
왜 이것을 하는지 정말 중요해
어떤 업무 로직 앞에 무엇인가를 해야 한다면 이걸 다 뜯어고쳐?
아니다
def deco(func): print("hello Wolrd!") func() # 이제부터 businessLogic 이라는 함수를 호출하면 # deco라는 함수를 수행 # 개발자가 작성한 코드 대신에 다른 코드를 불러내는 방식은 # 프록시 패턴이라고 합니다. def commonConcern1(): print("공통 관심 사항_1") def commonConcern2(): print("공통 관심 사항_2") @deco def businessLogic(): print("비즈니스 로직") #업무로직에 프린트 앞에 helloworld를 찍어야 한다는데? businessLogic()프록시 라고 합니다.
쉽게 보면 @deco를 한거면 deco의 func는 businessLogic이 된것
- 이제부터 businessLogic 이라는 함수를 호출하면 deco라는 함수를 수행
- 개발자가 작성한 코드 대신에 다른 코드를 불러내는 방식은 프록시 패턴이라고 합니다.
#고객의 니즈 변경 #업무 로직과 관계가 없는 로깅을 출력하는 코드를 추가하기를 #원하는 방향으로 변경 #유지보수 과정이나 업무 로직과 관련이 없는 코드를 #추가하거나 삭제하는 경우 #업무 로직을 직접 수정하는 것은 예상치 못한 결과를 #만들어 낼 수 있습니다. #이런 경우에는 업루 조기은 손을 대지 않고 기능하도록 #만드는 것이 좋습니다. def urNeeds(func): func() print("로깅") @ urNeeds def businessLogic(): print("업무 로직") businessLogic()이런 방식의 프로그래밍은 AoP : 관점지향 프로그래밍 이다.
- decorator를 만들 때, 대부분의 경우는 함수를 리턴해서 리턴한 함수가 수행되도록 합니다.
- decorator에 전달된 매개변수를 이용해서 함수의 이름이나 전달된 인수 그리고 리턴 값도 확인할 수 있습니다.
함수를 호출할 때 마다 실행에 걸린 시간, 인수, 리턴값을 출력하는 decorator
import time #시간 측정을 위해 def clock(func): #decorator가 적용된 함수가 호출되면 #수행될 실제 함수 def clocked(*args): start=time.time() #현재 시간 기록 #업무로직 함수 result=func(*args) end=time.time() elapsed=end-start#함수 수행시간 print(elapsed) #매개변수 확인 print("매개변수:", args) #return 값 확인 print("리턴값 : ", result) return result return clocked @clock def solution(s): #그냥 내가 만든 함수 result=[] word_index=[] word=[] word=s for i in range(len(s)): word_invers=word_index[::-1] if s[i] not in word_index: word_index.append(word[i]) result.append(-1) elif s[i] in word_index: word_index.append(word[i]) idx=word_invers.index(s[i])+1 result.append(idx) return result solution("babamba")결과는 아래와 같다.
0.0
매개변수: ('babamba',)
리턴값 : [-1, -1, 2, 2, -1, 3, 3]
decorator를 왜 쓰는지 기억을 잘 해두자
표준 라이브러리를 제공하는 데코레이터
- functools 패키지에서 제공하는 lru_cache()라는 데코레이터를 이용하면 중복된 함수 호출이 있는 경우 함수를 호출하지 않고 결과를 제시할 수 있습니다.
- lru는 무한정 캐싱되는 현상을 방지하기 위해서 오랫동안 사용하지 않은 데이터를 캐시에서 제거하는 알고리즘 입니다.
import time #시간 측정을 위해 import functools #functools로 재귀의 속도 향상을 노려보자 def clock(func): #decorator가 적용된 함수가 호출되면 #수행될 실제 함수 def clocked(*args): start=time.time() #현재 시간 기록 #업무로직 함수 result=func(*args) end=time.time() elapsed=end-start#함수 수행시간 print(elapsed) #매개변수 확인 print("매개변수:", args) #return 값 확인 print("리턴값 : ", result) return result return clocked @functools.lru_cache() #편하다 편해 @clock def fibonacci(n): if n==1 or n==2: return 1 else: return fibonacci(n-1)+fibonacci(n-2) fibonacci(20)
✔ OOP(Object Oriented Programming)
- OOP : 객체 지향 프로그래밍
특징
- Encapsulation : 캡슐화
- 불필요한 정보는 숨기고 중요한 정보만을 표현해서 프로그램을 간단하게 만드는 것(인터페이스를 간단하게 만드는 것) - Inheritance(상속)
- 하위 클래스가 상위 클래스의 모든 요소를 물려받는 것 - Polymorphism(다형성)
- 동일한 메시지에 대하여 다르게 반응하는 성질
용어
- Object(객체)
- 프로그램에 사용되는 모든 것 - Class(사용자 정의 자료형)
- 동일한 목적을 달성하기 위해 모인 속성(data) - Instance
- Class를 기반으로 메모리 할당을 받은 객체
- 동적(Dynamic) : 변경 가능함 - 정적 바인딩
- 정적 바인딩은 실행 전에 결정 되는 것
- 변수를 만들 때 자료형을 명시적으로 작성하거나 암묵적으로 결정해두고 사용하기 때문에 실행 중에 변수에 다른 종류의 데이터를 삽입할 수 없음 - 동적 바인딩
- 동적 바인딩은 실행 중 결정 가능한 것
- 참조형 데이터만 존재하고 변수는 데이터의 참조를 저장하기 때문에 실행 중에도 다른 종류의 데이터를 대입할 수 있음- python & JS 이며 실행속도가 느립니다.
- 왜냐하면 실행중에 결정할 것이 많아서 그럽니다.
- 아무거나 저장이 가능합니다.
- Attribute(속성)
- Instance를 구성하는 데이터 - Method
- Class 안에 만들어진 기능(함수) - Property
- 속성처럼 사용하지만, 실제로는 method를 호출하는 것 - Attribute와 Property를 거의 같은 개념으로 보기도 합니다.
- Record or Structure(구조체)
- 하나의 행을 의미, Instance를 구성하는 속성의 집합 - Python 의 모든 데이터는 기본적으로 Instance
- 10 int라는 class에서 만들어지기에 Instance - Information Hiding(정보 은닉)
- 불필요한 부분을 숨기는 것
Class 와 Instance
Class 생성
class 클래스이름: 초기화 메서드 생성 메서드 생성
Instance 생성
(인스턴스 이름 = )초기화메서드(매개변수)초기화 메서드의 이름은 클래스이름
인스턴스 이름은 생략 가능하지만, 이름을 만들어 재사용성을 높임
- 인스턴스를 생성하는 메서드를 호출하면 인스턴스를 생성하고 그 참조를 리턴합니다.
Instance나 Class를 이용한 멤버 호출
- (인스턴스/클래스).속성
- (인스턴스/클래스).메서드(매개변수)
Method
- 인스턴스가 있어야만 호출되는 method와 인스턴스가 없어도 호출되는 method(static, class)로 구분합니다.
- 인스턴스가 있어야 하는 method를 생성
def 메서드이름(인스턴스를 참조 저장할 매개변수, 이후 매개변수나열)): 내용관례상 인스턴스 참조를 저장할 매개변수의 이름은 self
- 인스턴스가 있어야 하는 method를 호출
-class이름 .메서드이름(인스턴스,매개변수): Unbound 호출
-인스턴스 .메서드이름(매개변수):bound 호출
-self.method이름(매개변수): 클래스 내부의 다른 메서드에서 호출
class Student: #인스턴스가 있어야만 호출되는 메서드 def disp(self): print("인스턴스 생성") #인스턴스 생성 mino=Student() mino가 인스턴스가 이난 Student()가 인스턴스이다. #한번만 사용한다면 상관이 없다. #재사용을 위해 이름만 붙일 뿐이다. #bound 호출 - 일반적으로 씁니다. 주로. mino.disp() #unbound 호출 Student.disp(mino)이걸 죽여패도 모르면 안된다.
Instance의 속성 만들기
- 파이썬에서 인스턴스의 속성을 만들고자 하는 경우에는 인스턴스가 있어야 호출되는 메서드 안에서
self.속성명으로 데이터를 대입하면 만들어집니다.
- 메서드 안에서self.을 이용하지 않고 만든 속성은 지역변수가 됩니다. - 클래스 외부에서
인스턴스.속성이름=데이터코드를 작성하면, 속성이 존재하면 속성의 값을 변경하는 것이고, 속성이 존재하지 않으면 속성이 생성됩니다.
class Student: #인스턴스가 있어야만 호출되는 메서드 def disp(self): print("인스턴스 생성") def setName(self, name): self.name=name #self.name은 instance의 속성으로 만들어집니다. #그냥 name을 했으면, 지역변수로 됩니다. #인스턴스 생성 mino=Student() #mino가 인스턴스가 아닌 Student()가 인스턴스이다. mino.setName("mino") mino.score=94 #instance에 score라는 속성 없으면 만들고 있으면 수정 print(mino.score) print(mino.name) #bound 호출 - 일반적으로 씁니다. 주로. mino.disp() #unbound 호출 Student.disp(mino)python은 동적으로 필요한 속성을 만드는 것을 확인할 수 있다.
Class 속성
- class 내부 그리고 method 외부에 변수를 생성해서 데이터를 대입하면 class 속성이 됩니다.
- class의 속성은 클래스와 인스턴스 모두 접근이 가능합니다.
- 인스턴스를 이용해서 접근할 때, 그 속성이 인스턴스 내부에 없으면 class 속성을 호출하지만, 인스턴스 내부에 존재한다면 인스턴스의 속성을 호출합니다.
- 대입문을 이용하면 인스턴스의 속성을 생성해서 사용합니다.
- 클래스 속성은 인스턴스를 이용해서 접근하는 것을 권장하지 않습니다.
class Student: class_data="클래스의 속성" #이 데이터는 클래스가 가지고 있다. mino=Student() print(Student.class_data) #클래스 이름을 이용해서 클래스 속성에 접근 print(mino.class_data) #인스턴스 이름을 이용해서 클래스 속성에 접근 Student.class_data="클래스 데이터를 수정했어요 클래스를 통해서" print(Student.class_data) #클래스 이름을 이용해서 클래스 속성에 접근 print(mino.class_data) #인스턴스 이름을 이용해서 클래스 속성에 접근 mino.class_data="인스턴스를 통해 클래스 데이터를 수정했어요" print(Student.class_data) #클래스 이름을 이용해서 클래스 속성에 접근 print(mino.class_data) #인스턴스 이름을 이용해서 클래스 속성에 접근인스턴스로 클래스 데이터를 수정하면 인스턴스의 속성값만 바뀌고 클래스에서 호출한 클래스 속성 데이터는 그대로이다.
- 인스턴스에 없다면 호출할 때, 클래스 속성을 가져오지만 , 인스턴스의 속성이 만들어진다면 그 데이터를 가져옵니다.
- 결국 우리가 똑같이 가질 데이터 : 클래스 속성 (자원 낭비 방지)
- 다르게 가져가야 하는 데이터 : 인스턴스 속성
- Student.method()는 불가
- Student.method(student)는 가능
set1.union(set2)와Set union(set1,set2)는 같지만 뭔가 느낌이 다르다.
약간 "내가 동생과 영화를 보러갔다."와 "영화를 보러갔다 나와 동생이."의 느낌 차이이다.
인스턴스는 메서드를 가지고 있지 않다.
메서드는 클래스 안에 만들어두고 공유하는 개념이다.
is 연산자
- python의 변수는 데이터를 저장하고 그 데이터의 id를 저장하는 개념
- "==" 연산자는 목적이 id를 비교하는 것이 아닙니다.
- python에서는 ==연산자는 내부에 만든 __eq__ 메서드를 호출해서 그 결과를 리턴하는 연산자 입니다.
- id를 비교하는 연산자는 is 연산자 입니다.
- is가 ==보다 빠르다.
- ==는 메서드 호출 : 스택 만들어 로직 수행하고 결과를 가져와야함
- is 연산자는 오버로딩이 안되기 때문에 명확하게 id를 비교한다고 할 수 있습니다.
==연산자는 오버로딩(기능을 변경)이 가능합니다.
그렇기 때문에 어떻게 동작할지 예측하기 어렵습니다.
class Student: class_data="클래스 속성" #인스턴스 생성 후 대입 stu1=Student() #인스턴스 생성 후 대입 stu2=Student() #stu1의 데이터를 대입 stu3=stu1 #이렇게 된다면 stu1이 참조하고 있는 #데이터의 참조를 stu3가 참조합니다. #두개의 인스턴스가 동일한지 여부 확인 print(stu1==stu2) print(stu1==stu3) #내부 데이터가 같은지확인, #id가 달라도 true가 나올 순 있음 #==를 __eq__오버로딩해야함 print(stu1 is stu2)#id가 같은지 확인 print(stu1 is stu3)#참조하기에 id는 같음
Accessor - 접근자 메서드
- 객체지향 언어에서는 인스턴스를 가지고 속성에 직접 접근하는 것을 권장하지 않습니다.
- 속성에 접근하는 메서드를 이용해서 속성의 값을 가져다가 사용하고 수정하도록 합니다.
- 속성의 값을 리턴하는 메서드를 getter라고 합니다.
- 속성의 값을 수정하는 메서드를 setter라고 합니다.
getter
이름은 get속성이름으로 하고
매개변수는 일반적으로 없고 속성을 리턴하기만 합니다.
예외적인 경우 :
속성의 자료형이 bool인 경우 get 대신 is를 붙입니다.
속성의 이름의 첫글자는 대문자로 표기,
python에서는 대문자 대신 언더바를 사용하는 경우가 있습니다.
setter
이름은 set속성이름으로 하고
매개변수는 속성과 동일한 자료형의 데이터 1개로 생성
내용은 매개변수로 받은 데이터를 속성에 대입합니다.
속성의 자료형이 Sequantial(list)인 경우 :
인덱스를 받아서 인덱스 번째 데이터를 리턴하는 getter를
추가로 생성하고
인덱스와 데이터 1개를 받아서 인덱스번째 데이터를 수정하는 setter를 생성하기도 합니다.
리스트에서 하나만 수정할 수 있도록 만들 수 있겠지
#이름과 점수를 갖는 객체를 여러개 사용해야한다. class Student: def getName(self): return self.name def setName(self,name): self.name=name def getScore(self): return self.score def setScore(self,score): self.score=score stu1=Student() #setter를 이용한 속성 생성과 설정 stu1.setName("mino") stu1.setScore(100) #getter를 이용한 속성 사용 print(stu1.getName()) print(stu1.getScore()) #최근에 등장한 IDE는 대부분 getter와 setter를 만드는 유틸을 제공
객체지향 언어에서는 속성을 직접 수정하지 말자. 메서드를 통해서 하자
✔ 궁금한 점 정리
method를 만들 때, self가 왜 필요한거야?
class Student: def disp(): print(data)이렇게 존재한다고 가정하자
stu1=Student() stu1.data="hi" stu1.disp() stu2=Student() stu2.data="hello" stu2.disp()instance를 2개 생성하였다.
- 확인해보면 stu1, stu2의 data가 class에는 존재하지 않는다.
- disp()에서
print(data)와 stu1, stu2를 생각하면 해당 공간에서는 data가 아닌 stu1, stu2의 데이터가 모두 필요하다.
이때, data대신
self.data를 사용한다면 instance를 method가 전부 보유할 필요는 없어진다.
클래스로 메서드 호출과 인스턴스 메서드 호출의 차이?
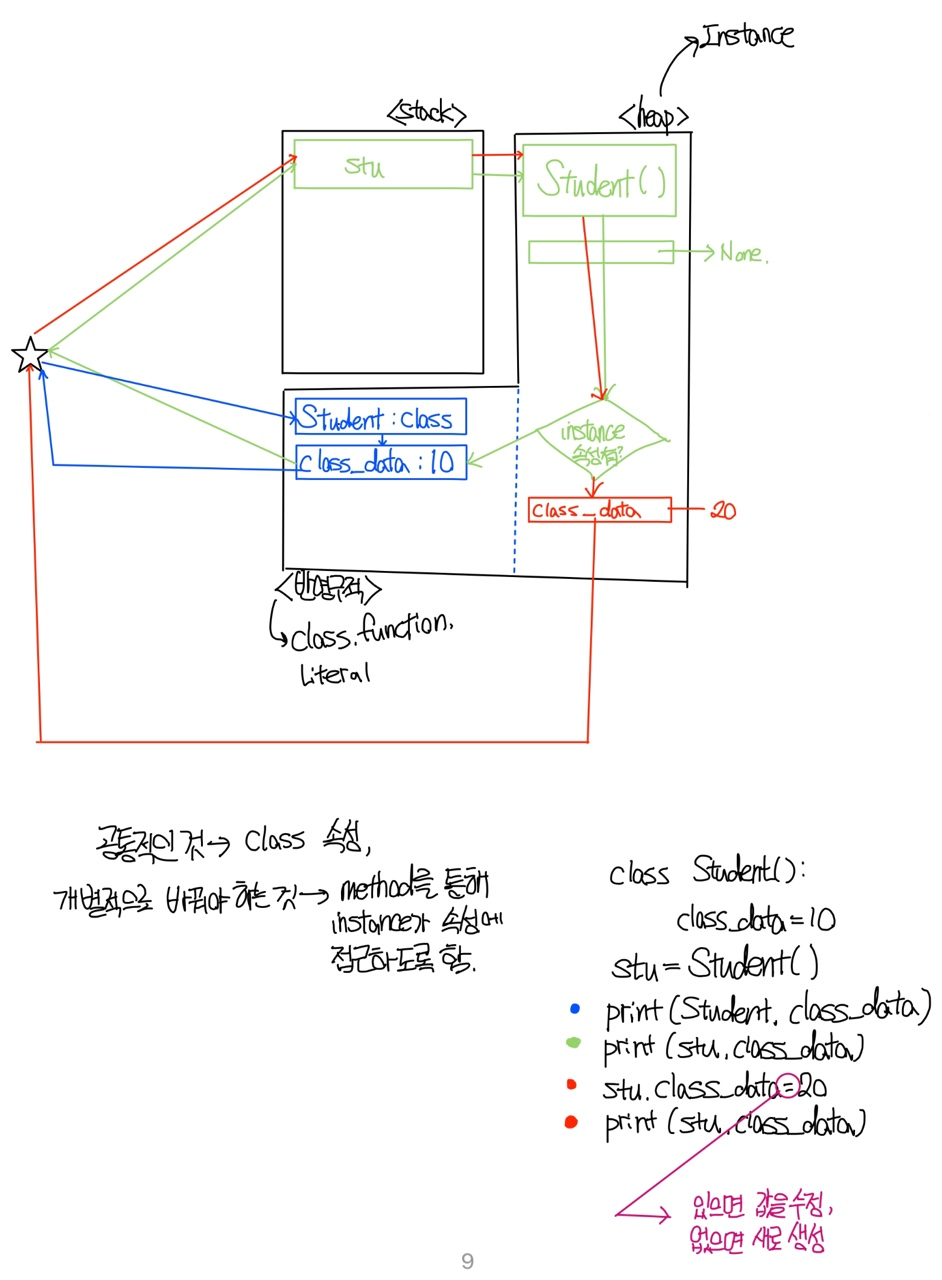
class Student: class_data=10 stu=Student() print(Student.class_data) print(stu.class_data) stu.class_data=20 print(stu.class_data)
이렇게 존재한다고 해보자.
우선 print(stu.class_data)를 보면, 인스턴스의 class_data는 아직 존재하지 않아서 class의 속성값을 가져온 것이다.
그래서 print(Student.class_data) print(stu.class_data) 이 둘의 결과는 우선 같다.
하지만 stu.class_data=20를 통해서 해당 속성값이 없다면 속성값을 만들어 주기 때문에, 인스턴스의 속성값이 생긴다.
이후 print(stu.class_data)를 한다면 class의 속성값과는 다르게 나올 것이다.
해당 코드의 구조는 아래와 같다.