
✔ Computational Thinking
-
현실 세계의 문제를 분석하여 해결책을 찾는 과학적 사고법을 Computational Thinking이라 하며 이렇게 설계한 해결책을 컴퓨터의 명령어로 작성하는 것이 컴퓨터 프로그래밍이다.
-
구성
- 분해 : 복잡한 문제를 작은 문제로 나눔
- 패턴 인식 : 문제 안에서 유사성을 발견
- 추상화 : 문제의 핵심에만 집중하고 부차적인 것은 제외
- 알고리즘 :이렇게 정의한 문제를 해결하는 절차(일반화와 모델링은 여기에 포함)
✔ DATA
- Data 처리 과정과 기술
- 데이터의 양이 많아지면서 인간이 하는 것 보다는 컴퓨터 프로그램을 활용하는 것이 효율적이고 편견을 배제할 수 있음
데이터소스 - 수집 - 저장 - 처리 - 분석 - 표현
모델링 : 도메인 지식이 부족할 수 있다.
분석 -> 비즈니스 인사이트 도출이 메인이다.
-
컴파일러 & 인터프리터 : 인간이 고급 프로그래밍 언어(소스코드)로 작성한 것을 컴퓨터가 실행할 수 있도록 운영체제나 가상머신이 이해할 수 있는 코드로 번역해주는 프로그램
-
IDE(Intergrated Development Environment)
- 코딩, 디버그, 컴파일, 배포 등 프로그램 개발에 관련된 모든 작업을 하나의 프로그램 안에서 처리하는 환경을 제공하는 프로그램 -
컴파일러는 bin파일로 os가 이해할 수 있도록 한다. 한 번에 실행하기에 bin파일이 필요한다.
-
Unix/Linux/MS Windows/Macintosh : 다 python 사용 가능한 플랫폼이다.
- 전부 다 C 계열이다.
- Cpython 이 좀 쓰기가 좋겠죠?
- MS는 조금 다르기에 visual 뭐 설치하라고 하는거야. -
python interpreter 종류
- python : 일반적인 파이썬, 기본적인 모듈 포함
- Anaconda : 데이터 분석할 사람들은 주로 씀
- Canopy : 우리나라는 별로 안씀
✔ Python을 해보자
파이썬 프로그래밍의구성 요소
- Literal : 사용자가 직접 입력하는 데이터
- Variable : 데이터에 붙이는 이름
- Function : 독립된 메모리 공간을 할당받아서 한 번에 수행되는 코드 블럭
- Class & Instance : 동일한 목적을 달성하기 위해 모인 데이터와 기능의 집합
- Module : 파이썬에서는 파일을 모듈이라고 합니다.
- Package: Module의 집합으로 배포 단위이다.
- Comment : 번역하지 않는 문장(파이썬에서는 #으로 시작합니다.)
코딩 시 주의 사항
- 파이썬은 line 단위로 번역해서 실행하기 때문에, 기본적으로 세미콜론(;)은 필요가 없다.
- 대신 한 줄에 2개의 실행문이 있다면 세미콜론으로 구분해 주어야 한다.
- 실행문 : (대부분) 대입문이 존재하는 문장, 함수호출 - 파이썬은 하나의 블럭을 만들 때, 들여쓰기를 이용합니다.
- 기본은 빈칸 4개지만, 일정하게 맞추기만 하면 상관은 없습니다.(tab 가능) - 콘솔에 출력 할 때는 print 함수를 이용하는데, 여러 개 출력하고자 하면 콤마(,)로 구분
- 기본적으로 print 함수는 줄바꿈을 수행함 - 하위 레벨을 만들 때는 콜론(:)하고 들여쓰기를 합니다.

Comment
-
(#) 다음에 작성하면 주석이 됩니다.
-
파이썬에는 문자열 상수를 만들 때, 작은 따옴표나 큰 따옴표를 안에 묶고 여러 줄의 경우는 작은 따옴표나 큰 따옴표를 3번해서 묶습니다.

-
#! 는 주석이 아니고 유닉스의 shebang 입니다.
- 일반적으로 파이썬에서는 소스 코드의 인코딩을 표시할 목적으로 사용합니다.
Document
-
dir(데이터) : 데이터가 호출 가능한 속성과 메서드를 리턴합니다.
- print 안에서 불러야 할 것이다. -
help(함수나 메서드) : 함수나 메서드의 도움말을 출력합니다.
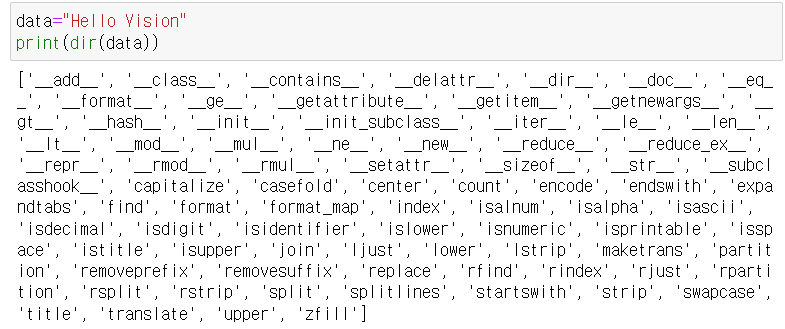
-
__ __ 가 붙는 것들 : 특수 메서드(근본적으로 직접 호출이 아닌 호출법이 따로 존재함)
-
안붙은 것들 : 메서드, 함수

- 잘 설명해 주는 것을 확인할 수 있다.
Keyword(예약어)
- python이 기능을 정해둔 것으로, 다른 용도로 사용하면 에러가 납니다.
- 변수의 이름이나 함수의 이름으로 사용할 수 없다는 의미입니다.
- 확인하는 방법import keyword print(keyword.kwlist)를 해보자 - 예약어의 개수가 매우 적은 것이 장점이다.
Module을 찾아오는 순서
pip install을 했는데 왜 없다 그러지?import sys print(sys.path)를 해보자.

- 맨 처음 나온 경로가 최우선권을 가진다.
- 2개 python 깔면 pip 를 현재 쓰는 애가 아닌 다른 버전에 깔고 그래서 없다 뜨는거다.
users-user-anaconda3-tools-python.exe
파이썬의 기본 자료형(무조건 알고 있어야 합니다.)
-
숫자 데이터 : int, float, complex - 하나의 데이터(scala data), 불변(immutable), 직접 접근
-
문자열 : str : 0개 이상의 문자의 집합, 불변, 순차 접근
-
tuple : 0개 이상의 데이터의 모임, 불변, 순차 접근
-
list : 0개 이상의 데이터의 모임, 가변, 순차 접근
-
set(집합) : 0개 이상의 데이터의 모임, 가변, 순차 접근을 못함(순서대로 저장x)
- set은 데이터를 빨리 찾으려고 쓰는 것이다.
- id만 불러온다고 하면 set(중복도 안되며 찾는 속도는 다 똑같음) -
dict(딕셔너리, 사전, map, hashtable 등) : 0개 이상의 데이터의 모임으로, 가변, key-value 시스템
- key가 set으로 만들어 집니다.(똑같은 key는 없다.) -
이름으로 찾는 것이 index보다 빠르다. list vs dict : dict가 이김
-
하지만 장점이 있다면 단점도 있다. (속도의 이득->메모리낭비)
- trade-off라고 하네요
- 적절한 지점을 찾아가는 것이 중요하다.
? 직접 접근 : 순차 접근
Literal
-
사용자가 직접 입력하는 데이터로 처음 사용될 때 static 영역에 생성되고 이후 부터는 재사용을 합니다.
-
static영역은 한 번 쓰면 안사라짐
-a=10a에 10에 저장한다고 말하지좀 말자
-b=10하면 10을 참조하는 것이 2개인 것이다.

-
숫자 : 정수, 실수, 복소수
-
정수(int) : 10진수(숫자), 8진수(0o숫자), 16진수(0x숫자), 2진수(0b숫자), 숫자L(long 형)
-
실수(float) : 1.2(단순 숫자입력), 0.12e1(0.12*10^1)
-
복소수(complex) : 4+5j(j로 표현)
-
bool : True, False(첫 글자는 대문자)
-
str : 작은 따옴표나 큰 따옴표 안에 기재하면 되는데, 여러 줄은 3번
-
bytes : 바이트의 집합으로 b'문자열' 또는 b'\코드\코드..'
-
list : [] 안에 나열
-
tuple : () 안에 나열
-
set : {}안에 나열
-
dict : {key:value, key:value...}방식으로 나열
str, bytes, list, tuple, set, dict는 순차적으로 접근이 가능하다고 해서
iterable이라고 합니다.
확인방법 : dir 에 넣어서 __iter__가 있는지 확인
python을 알고 분석하는 것과 모르고 분석하는 것은 매우 큰 차이가 난다.
- 제어문자 : \다음에 영문 1글자를 기재해서 특별한 명령을 수행하도록 하는 문자
\n : 줄바꿈
\t : 탭
\,\',\" : 등등등...
- None : 가리키는 데이터가 없다
- null 이라고 하기도 하고, 자료구조에서는 nil이라고 하기도 하며, 데이터 분석 라이브러리에서는 NaN 도 유사한 의미로 사용
- NaN (숫자가 아니다, 연산 실패) 는 None(없는것)과 마찬가지라고 생각해서 비슷하게 사용
사용자 정의 명칭 - Identifier(ID)
- 데이터, 함수나 메서드, 클래스, 인스턴스, 모듈, 패키지에 부여하는 이름
- 영문자, 숫자, 한글, 언더바, $ 등을 사용 할 수 있다.
- 시작은 문자나 언더바 ( 문자가 좋아)
- 중간 공백은 안됨 - 예약어는 사용자 정의 명칭으로 사용할 수 없습니다.
- 일반적으로 클래스 이름만 대문자로 시작하고 변경할 생각이 없는 데이터의 이름은 모두 대문자로 만드는 것이 관례
변수 - Variable
- 변수는 데이터에 이름을 붙여주는 것
- 데이터는 다른 변수, 리터럴, 함수도 가능합니다.
- 이름이 존재하지 않으면 이름을 생성
- 이름이 존재하면 가리키는 곳을 변경합니다. - 데이터를 가리킬 때, 자료형이 결정됩니다.(Dynamic Binding)
- 동적 바인딩 : value type X, reference type O
- 정적 바인딩 : 이름 앞에 자료형이 붙어서 static 하게 함
value type : 값을 직접 저장
장점 : 빠르다.
reference type : 참조를 저장
단점 : 느리다.
장점 : dynamic binding(어떠한 타입이라도 저장 가능)
- 이름을 만들 때는 기억하기 쉬운 이름 또는 의미를 파악하기 좋은 이름을 사용하는 것이 좋다.
- 변수는 기본적으로 자신의 영역이 종료되면 파괴되지만, 강제로 파괴하고자 하는 경우는
del 변수명이는 데이터 파괴가 아님. - 하나의 데이터를 저장하는 경우에는 이름이 데이터를 의미하지만, 0개 이상의 데이터를 저장하는 경우에는 이름은 시작 위치를 의미합니다.(BoF)
- 영역이 다르면 동일한 이름으로 변수를 생성할 수 있다.

자기 블럭이 끝나면 데이터는 이미 파괴 된다.
연산자
- 연산을 수행해주는 부호나 명령어
산술연산 : 숫자 데이터를 연산해서 숫자로 결과를 리턴하는 연산
논리연산 : bool 데이터를 연산해서 결과를 bool로 리턴하는 연산
단항 연산(Unary) : 데이터의 개수가 1개인 연산(피연산자)
이항 연산(Binary) : 데이터의 개수가 2개인 연산(피연산자)
python은 삼항 연산 없다
할당 연산자
- =(asignment) : 오른쪽 데이터의 참조를 왼쪽 변수에 대입
산술연산자
- '+' : 숫자의 경우는 덧셈을 하고 데이터의 모임은 결합
- 다른 종류의 데이터끼리는 덧셈 연산이 안됨 - '-' : 당연히 뺄셈임
- '*' : 숫자의 경우는 곱셈이고, 데이터의 모임과 정수의 경우는 반복임
- '**' : 거듭제곱
- '/' : 나눗셈
- '//' : 몫만 가져옴
- '%' : 나머지



파이썬은 숫자데이터의 메모리 제한이 없음. 최대한으로 잡음
비교 연산자
-
연산의 결과를 bool로 리턴
-
bool 데이터도 크기 비교가 가능
- True는 1, False 는 0 -
문자열도 크기 비교가 가능
- 첫 글자부터 코드 값을 비교해서 크다 작다를 판별
- A는 65, a는 97
산술 비트 연산자
-
정수 데이터를 2진수로 변환해서 각 비트 단위로 연산을 수행한 후 10진 정수로 결과를 리턴하는 연산자
-
'&' : and로 둘 다 1일때만 결과가 1이고 나머지는 0
-
'|' : or로 둘 다 0인 경우만 0이고 나머지는 1
- 2개의 연산자는 데이터 분석을 위한 라이브러리(numpy)에서는 데이터 모임에서도 사용이 가능한데, 이 경우는 위치 별로 연산을 수행해서 리턴 -
'^' : eXclusive OR 로 두 개의 데이터가 같은 경우는 0 다른 경우는 1
-
'~' : 단항 연산으로 1의 보수
-
'<<' : 왼쪽으로 미는 연산자 - 곱하기 2
-
'>>' : 오른쪽으로 미는 연산자 - 나누기 2
진법 : 몫이 0이 나올때까지 나누고 나머지를 역순으로 나열하기
이거 한번 만들어보자
논리 비트 연산자
- bool 데이터를 가지고 연산을 수행해서 결과를 bool로 리턴하는 연산
- and : 둘 다 True인 경우만 True 이고 나머지는 False
- or : 둘 다 False인 경우만 False 이고 나머지는 True
- not : True이면 False, False이면 True 리턴
and와 or가 같이 있으면 and가 우선입니다.
and와 or는 연산자의 좌우를 변경해도 연산의 결과는 그대로입니다.
과정은 다릅니다.
- and는 앞의 결과가 False인 경우, 뒤의 연산 결과를 확인 X
- or는 앞의 결과가 True인 경우, 뒤의 연산 결과를 확인 X
if i%3==0 and i%4==0과if i%4==0 and i%3==0은 다릅니다. 이는 아래와 같습니다.
i는 0부터 100까지 순회를 한다고 가정합시다.
if i%3==0 : if i%4==0: // 33개 체크한 것을 안에서 체크합니다.if i%4==0 : if i%3==0: // 25개 체크한 것을 안에서 체크합니다.충분히 차이가 납니다.
check1, check2 넣어서 몇번씩 들어가는지 확인해도 됩니다.
우리는 컴퓨터 입장에서 생각을 해봐야 합니다.
논리 함수
- all(데이터 집합) : 데이터의 집합에 있는 모든 데이터가 True이면 True
- any(데이터 집합) : 데이터의 집합에 있는 데이터 중 하나만 True이면 True
- Falsy : 0은 False로 간주
복합 할당 연산자
- 변수 연산자 = 데이터 : 변수가 가리키는 데이터와 오른쪽 데이터를 연산자에 해당하는 연산을 하고, 그 데이터를 변수가 가리키도록 합니다.
데이터 타입 확인
type(데이터)
- 타입을 확인할 수 있습니다.
참조하고 있는 데이터 확인
id(데이터)
- id가 같으면 동일한 데이터를 가리키는 것입니다.
연산자의 우선 순위
- . , [인덱스]
- **
- ~, 부호(+,-)
- *, /, //, %, @
- '>>, <<'
- &,^,|(이 셋은 순서대로)
- '>, >=, <, <='
- ==, !=
- in, not in, is, is not
- not
- and
- or
- =(할당 연산자)
위에서부터 우선 순위가 높은 순이다.
데이터의 자료형 변환(Casting)
- 다른 자료형끼리 연산을 수행하거나 원하는 결과를 만들어내기 위해서 형 변환을 수행합니다.
프로그래밍에서는 일반적으로 숫자와 문자열 사이의 변환이나 문자열과 날짜 사이의 변환을 많이 수행하지만, 데이터 분석에서는 이외에도 factor타입으로의 변환이나 문자열 데이터를 비트열로 변환하는 것을 많이 수행합니다.
factor(나열형 상수?)
- 숫자와는 조금 다릅니다.
ex
남자와 여자가 있다.
데이터 분석을 하려면 숫자로 바꿔야 한다.
0, 1로 치환한다 하자. 2,3,4 같은 숫자 방지를 해야 한다.
이외의 값을 통제한다.
분석하는 사람들은 (0 1) (1 0) 을 생각한다.
형 변환의 종류
-
묵시적 형변환 : 자동으로 형 변환이 되는 경우
- 파이썬은 묵시적 형변환이 한개밖에 없다. 다른 종류의 숫자 데이터끼리 연산을 하는 경우, 작은 타입을 큰 타입으로 변환해서 수행 -
명시적 형변환 : 형 변환을 직접 해줘야 하는 경우
- 정수로 변환 : int(숫자 혹은 숫자로된 문자열)
- 실수로 변환 : float(숫자 데이터 또는 숫자로 된 문자열)
- bool로 변환 : bool(숫자 데이터 또는 bool 문자열)
- 문자열로 변환 : str(데이터) -
실수를 정수로 변경하면 소수가 소멸됩니다.
- 3750을 10의 자리에서 반올림해서 백의 단위로 변환
- 내가 반올림 하고 싶은 자리를 소수 첫째자리로 옮기기
- 37.5+0.5 하고 소수 버리고 다시 곱한다.
콘솔 입출력
콘솔 출력 : print
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
- 첫 번째 매개변수(value)는 출력할 데이터
- 두 번째 매개변수(...)는 출력할 데이터인데 개수 제한이 없음
- sep는 데이터 사이의 출력되는 문자(구분자, 현재는 공백)
- end는 출력하고 난 후 출력되는 문자
- file은 출력할 대상을 지정하는 것인데, sys.stdout은 표준 출력장치(일반적으로 모니터)이다. 파일경로를 쓰면 파일에 출력
- flush는 버퍼의 내용을 비울지에 대한 옵션이다. True, False로 지정할 수 있다.(False는 바로바로, True는 모아서 출력 내부적으로 작용)
flush는 버퍼의 내용을 비울 지에 대한 옵션입니다.
- 서식 설정
- % 다음에 숫자와 영문자 1개를 이용해서 데이터를 포맷에 맞춰서 출력
- %10d: 열 자리를 확보해서 정수를 출력
- %s : 문자열
- %f : 실수
- %b : bool
- 실수를 출력할 때, .소수자릿수f를 이용하면 출력되는 소수의 자릿수를 설정할 수 있다.
num=20 print("num은", num) print("num은 %d" %(num))동일합니다.
"{데이터의 인덱스}".format(데이터나열)" print("{0}은 {1}을 좋아합니다.".format("mino","home"))물론 인덱스 위치는 상관없습니다.
인덱스 자리대신에 변수를 쓸 수 있다면?
// 따옴표 앞에 f를 추가하면 인덱스 대신에 이름 사용 가능합니다. name="mino" place="home" print(f"{name}은 {place}을 좋아합니다.")이를 f-string 이라고 합니다. 이렇게 출력하는 것을 권장합니다.
콘솔 입력 : input
input(prompt=None,/)
- prompt는 메시지
- enter를 누를 때 까지 입력을 받아서 받은 내용을 하나의 문자열로 리턴합니다.
- 정수나 실수 또는 bool을 입력받고자 하는 경우는 형 변환을 이용해야 합니다.
- 이때, 데이터 포맷이 맞지 않으면 예외가 발생합니다. - 한 번에 여러개를 입력받고자 할 때는 구분 기호를 이용해서 입력받고 split으로 분할하면 list로 만들 수 있습니다.
name=input("이름을 입력하세요:") print(name)메시지가 없다면 그냥 빈 화면에서 입력해야 한다.
try: age=int(input("나이 입력")) print(age) except: print("문제 발생") print("프로그램 종료")이와 같이 예외처리를 하지 않으면 안된다.
hobbys=input("취미 입력을 ,로 구분해서 입력").split(",") for hobby in hobbys: print(hobby)이렇게 한다면 여러 값을 넣을 수 있다. 형태는 리스트 형태로 저장
