✔ Container Orchestration(컨테이너 배포 관리)
- Dockerfile 이미지 1개 생성, Docker-Compose 여러 컨테이너 관리
- Docker-Compose는 컨테이너 관리의 시작점이다.
개요
- 다수의 컨테이너를 유기적으로 연결 및 실행하고 상태를 추적하고 보존하는 등, 컨테이너를 안정적으로 사용할 수 있게 만들어주는 것
종류
- Docker Swarm
- 간단하게 설치할 수 있고, 사용하기도 용이하다
- 기능이 다양하지 않아서 대규모 환경에 적용하려면 사용자 환경을 변경해야 하기 때문에, 소규묘 환경에서 유용하지만, 대규모 환경에서는 잘 사용하지 않는 편이다.- Mesos
- Apache재단의 오픈 소스 프로젝트로 트위터, 에어비앤비, 애플, 우버 등 다양한 곳에서 이미 검증된 솔루션
- 기능을 충분히 활용하려면 분산관리 시스템과 연동해야 하기 때문에, 여러가지 솔루션을 유기적으로 구성해야 하는 부담이 있다.
- 비슷하게 Hadoop이 존재- Nomad
- 베이그런트를 만든 해시코드 사에서 만든 오케스트레이션
- 도커 스웜처럼 기능이 부족한 편이어서 수정을 해서 사용해야 하는 경우가 많음- Kuberentes
- 시작하는 부분이 어렵지만(설치가 어려움 - Linux에서만 가능), 쉽게 사용할 수 있는 도구들이 추가되면서 학습하기가 수월해지는 추세
- 거의 모든 벤더와 오픈 소스 진영에서 쿠버네티스를 지원하고 그에 맞게 통합/개발하고 있음
✔ Kubernetes
개요
- 컨테이너 기반의 애플리케이션을 개발하고 배포할 수 있도록 설계된 오픈 소스 플랫폼(컨테이너 오케스트레이션 도구의 일종)
- 줄여서 사용할 때는 k8s라고 한다.
- 쿠버네티스 자체를 일반적인 개발자가 관리하는 일은 매우 드물다.
- 여러 개의 컨테이너(애플리케이션 하나 또는 서비스 하나)를 관리하는 도구이기 떄문이다.
- 개발자나 프로젝트 매니저 또는 시스템 엔지니어는 쿠버네티스의 구동 원리나 할 수 있는 작업이 무엇인지는 알아둘 필요가 있음 - 기본적으로 여러 대의 물리적 서버에 걸쳐 실행되는 것을 전제로 함
- 여러 대의 서버에 여러 개의 컨테이너를 적재해서 실행하는 것으로 간주
- 20대의 컨테이너를 생성하고자 하는 경우, docker run ㅁ여령을 사용하는 경우라면 해당 명령을 20번 내려야 하고, docker-compose를 사용한다 하더라도, 각 물리적 서버마다 명령을 별로도 내려야 한다.
- 하지만 kubernetes에서는 이럴 필요가 없이 1곳에서만 명령을 내리면 됩니다. - 하나의 애플리케이션을 생성하기 위해서는 하나의 pod가 필요한데, pod가 쿠버네티스에서 생성할 수 있는 가장 작은 배포 단위이면서 단일 혹은 다수의 컨테이너를 포함함
- 파드 외에서 서비스, 볼륨, 네임스페이스 등의 오브젝트가 존재
- 파드 : 애플리케이션
- 서비스 : 파드를 외부에서 접근할 수 있도록 해주는 오브젝트
- 네임스페이스 : 논리적인 분리 단위(네트워크와 비슷)
- 볼륨 : 컨테이너의 데이터를 젖아하고, 컨테이너 간 파일을 공유할 목적으로 사용하는 오브젝트 - 파드와 컨테이너
- 파드는 유사한 역할을 하는 컨테이너를 묶어서 배포하는 단위
- 하나의 애플리케이션 또는 패키지나 docker의 docker-compose와 유사
- 개발자들은 파드를 마이크로 서비스의 단위로 간주하는 경우도 많음 - 워커 노드
- 도커 런타임이 설치된 경에서 컨테이너 혹은도커를 실행, 유지 및 관리하는 것이 워커 노드
- 실제로 작업이 이루어지는 공간
기본 구성
- 기본적으로 마스터 노드 1개와 1개 이상의 워커 노드로 구성되어있음
- 워커 노드의 개수는 제한이 없음
- 마스터 노드 한개와 워커 노드 여러 개로 구성된 시스템을 클러스터라고 부릅니다.
- public cloud에서 k8s를 사용한다고 하면, 기본적으로 하나의 클러스터가 배정됩니다.
- 1개의 마스터 노드에 작업을 수행합니다.
특징
무중단 서비스
- 쿠버네티스를 사용하게 되면, 서비스 중단 없이 애플리케이션을 업그레이드 하는 것이 가능하다.
- 복제본을 만들어야 하는 이유? (레플리카)
- 애플리케이션 만들어서 서비스를 열었다.(서비스 : 외부 사용자가 쓸 수 있음)
- 애플리케이션(파드) 는 2개로 복제해놔서 업데이트에 사용 (블루그린, 카나리아 등..)
- 카나리아 테스트 (인스타) -> a/b 테스트
클라우드 밴더 종속성 해결
- 쿠버네티스는 거의 모든 클라우드에서 제공하는 서비스라서 벤더 종속성이 거의 발생하지 않습니다. (UML, 디자인 패턴 공부좀 하라고)
Lock-In
- 원하는 대로 수정할 수 없는 것
효율적인 자원 사용
- 리소스 사용량을 제어하는 것이 가능
유연한 확장성
항상 바람직한 상태 유지
- 컨테이너를 생성하거나 삭제할 수 있는데, 이 때 명령어를 이용해도 되지만, yaml 파일을 이용해서 작업하는 것도 가능하다.
- docker-compose도 옵션을 이용해서 수동으로 컨테이너의 수를 바꿀 수 있지만, 모니터링 기능이 없어서 상태 유지를 보장할 수 없지만, 쿠버네티스는 모니터링 기능이 있어서 자동으로 상태를 유지함
구조
- 클러스터
- 여러 리소스를 관리하기 위한 집합체로, 마스터 노드와 워커 노드를 이용해서 구성 - 마스터 노드
- 클러스터 전체를 관리하는 시스템으로 Control Plain이라고 함
- 마스터 노드에 kubectl을 설치해서 쿠버네티스 명령어를 실행
- API Server, Scheduler, Controller Manager, etcd 등으로 구성
- etcd 는 면접에 좀 나올 가능성이 있다. - 워커 노드
- 마스터 노드의 명령을 받아서 파드를 생성하고 서비스 하는 노드
- Computing Machine라고도 부름
- 컨테이너 런타임, kubelet, 프록시 등으로 구성 - 컨테이너 런타임
- 실제로 파드를 실행하는 엔진으로, 도커가 대표적이고, 비슷한 것으로는 컨테이너디, 크라이오 등이 있는데 최근에는 쿠버네티스에서 컨테이너디를 표준으로 채택함 - 영구 스토리지
- 컨테이너의 데이터를 저장하기 위한 영역으로, 최근에는 CSI(Container Storage Interface)로 클라우드 벤더의 외부 스토리지를 사용하는 것을 권장함
컴포넌트
API SERVER
- 클러스터의 API를 사용할 수 있게 해주는 프로세스
- 클러스터로 요청이 들어왔을 때, 그 요청이 유효한지 검증하는 역할
- 사용자가 보낸 명령어를 검증하고 유효성을 검사한 뒤 워커 노드에 파드를 생성하도록 명령을 전송
etcd
- 클러스터에 필요한 정보, 파드와 같은 리소스들의 상태 정보를 저장하는 곳
- 일종의 데이터베이스, key-value 형태로 저장
- API Server는 파드를 만든다는 사실을 etcd에게 알리고, 사용자에게 파드가 생성되었다고 알리는데, 아직은 파드가 생성되지 않은 상태임 그때는
scheduler
- API Server가 etcd에게 파드 생성 여부를 알리고, 실제 어떤 워커 노드에 파드를 생성할 것인지 결정하는 컴포넌트
- 어떤 워커 노드에 파드를 생성해야 할 지를 API Server에게 알려줌
kubelet
- API Server는 scheduler로 부터 어떤 워커 노드에 파드를 생성해야 할 지를 통보하고, 그 워커 노드의 kubelet에게 파드의 생성 정보를 전달해서 파드를 생성하도록 합니다.
- kubelet은 파드를 생성하고 그 정보를 API Server에게 전달하고, API Server는 파드의 상태를 etcd에 저장합니다.
Controller Manager
- kube-controller-manager
- 컴포넌트들의 상태를 지속적으로 모니터링하고 실행 상태를 유지하는 역할을 수행
- 파드의 상태가 이상하거나 우커ㅓ 노드의 상태가 이상하면, kube-controller-manager가 이 사실을 가지고 문제가 있는 파드나 워커 노드를 제거하고 다른 워커 노드에 파드를 생성합니다. - cloud-controller-manager
- public cloud에서 제공하는 컴포넌트로, 실제 kubernetes와 연동되는 서비스들을 관리
Proxy
- kube proxy는 클러스터의 모든 노드에서 실행되는 네트워크의 프록시
- 노드에 대한 네트워크의 규칙을 관리
Container Runtime
- 실제 컨테이너를 실행시키는 컴포넌트
- 도커가 많이 사용되었는데, 1.2 버전부터는 컨테이너디나 크라이오를 사용하는 것을 권장함
kubernetes controller
- 파드를 관리하는 역할
컨트롤러 종류
- 데몬셋
- 디플로이먼트
- 스테이플셋
- 크론잡과 잡
- 레플리케이션 컨트롤러
레플리카 셋(ReplicaSet)
- 몇 개의 파드를 유지할 지 결정하는 컨트롤러
Deployment
- 상태가 없는 애플리케이션을 배포할 때 사용하는 가장 기본적인 컨트롤러
- 레플리카 셋의 상위 개념으로 보통은 yaml 파일로 만들어서 배포
Job
- 하나 이상의 파드를 지정하고 지정된 수의 파드가 성공적으로 실행되도록 해주는 컨트롤러
- 노드의 하드웨어 장애나 재부팅 등으로 파드가 비정상적으로 작동하면, 다른 노드에서 파드를 시작해 서비스가 지속되도록 합니다.
Cron Job
- 지정한 일정에 따라서 잡을 실행시킬 때 사용
- 데이터 백업이나 일정한 주기를 가진 데이터 수집 등에 사용
Daemon Set
- 디플로이먼트 처럼 팓를 생성하고 관리하는 컨트롤러
- 특정 노드 또는 모든 노드에 파드를 생성하도록 합니다.
- taint
- 특정 워커 노드에 특정 성격의 파드만 배포하고자 할 때 설정하는 것
- ex) 특정 애플리케이션을 구동하는 파드는 GPU가 있는 노드에만 배치 - toleration
- taint가 설정된 노드에는 일반 파드는 배포될 수 없으나, 이를 적용하면 배포할 수 있음
State Full Set
- 상태를 가진 파드를 배포할 때 사용
- 파드들의 순서 및 고유성을 보장
Kubernetes의 Service
- 동일한 구성을 갖는 파드들을 모아 놓은 것
- 여러 개의 워커 노드에 존재하더라도 동일한 구성을 갖는 파드라면, 하나의 서비스가 관리
- 컨테이너는 한 번 도커 엔진에 만들어지면 이동이 안되지만, 파드는 어느 한 쪽에 생성되었다가 다른 워커 노드(컴퓨터)에 생성되기도 하기 때문에, 외부와 직접 연결을 할 수 없다.
- 외부와 직접 포트포워딩을 할 수 없다는 것이다. - 서비스가 일종의 고정 IP를 가지고 외부에서 파드를 사용할 수 있도록 한다.
- Load Balancer의 역할도 수행한다.
- 내부적으로 여러 개의 파드가 있어도, 밖에서는 하나의 IP 주소(서비스의 주소)만 볼 수 있다.
Cluster IP
- 파드들이 내부에서 서로 통신할 수 있도록 부여된 IP
NodePort
- 서비스를 외부로 노출할 때 사용하는 IP와 Port번호
Load Balancer
- public cloud에 존재하는 로드 밸런서에 연결하고자 할 때 사용하는 IP
- 서비스가 분배하는 통신은 하나의 워커 노드로 국한되고, 여러 워커 노드 간의 분배는 실제 로드 밸런서나 인그레스가 담당합니다.
- 로드 밸런서 또는 인그레스 안에 여러 개의 클러스터, 그 안에 서비스가 놓임
쿠버네티스의 통신
- 파드가 사용하는 네트워크와 노드(호스트)가 사용하는 네트워크는 다르다.
- 파드가 사용하는 네트워크는 가상 네트워크(vetho0)이고 노드가 사용하는 네트워크는 실제 네트워크(etho0) 이다. - 기본적으로는 동일한 노드에 있는 파드끼리만 통신이 가능합니다.
- 다른 노드의 파드와 통신을 하고자 한다면, CNI 플러그인이나 서비스를 이용해야 한다.
Ingress
- 클러스터 외부에서 내부로 접근하는 요청을 어떻게 처리할 것인지에 관한 규칙 모음
- 클러스터 외부에서 URL로 접근할 수 있도록 해주는 Load Balancing, SSL 인증서 처리 등의 규칙을 정의한 것
오브젝트와 인스턴스
- 오브젝트는 파드나 서비스, 레플리카, 디플로이먼트 등을 의미
- 이를 이용해서 실제 생성을 해서 etcd에 등록디 되면 인스턴스라고 합니다.
✔ 쿠버네티스 사용
외부 서비스 사용
- 기업에서 쿠버네티스를 사용하는 비중이 높아지면서 Public Cloud 서비스 제공업체들이 PaaS 형태로 서비스를 출시
종류
- AWS의 EKS
- MS의 MKS
- GOOGLE의 GKE
- Kakao의 DKOS
- NHN의 NKS
리눅스에 설치
- Suse의 Rancher나 RedHat의 OpenShift와 같은 플랫폼에서 제공하는 설치형 쿠버네티스 : 유료
- kubeadam, kops, KRIB, kubespray 등의 구성형 쿠버네티스를 이용 : 무료
- 현재는 kubeadam이 설치하기 쉬워서 많이 사용됩니다.
경량 버전의 쿠버네티스
- 학습용
- 운용 환경에서는 사용할 수 없음 - k3s
- Rancher사에서 만든 쿠버네티스의 경량 버전
- 자원을 적게 사용하기 때문에 edge나 사물 인터넷에서 주로 이용
minikube
- 하나의 컴퓨터에 단일 노드의 쿠버네티스 클러스터를 구성하고 사용
- 학습용으로 많이 사용
- MAC에서 설치
- Docker Desktop을 설치
- 명령어 사용을 위한 kubectl을 설치
- minikube 설치 (brew install minikube, minikube start)
- 확인 : kubectl version - Windows에서 설치 (Hyper-V 때문에 설치해도 초기화가 잘 안되는 경우가 있음)
- WSL2를 설치
- Docker Desktop을 설치
- minikube 직접 다운받아 설치 가능하지만, docker desktop에서 kubernetes를 사용한다고 설정하는게 더 편하다.
- 된다면 kubectl version을 cmd에서 해보자.
- 만약에 kubectl 명령어 없다고 에러뜨면 kubectl 다운받아 path 설정하고 사용해야 함
kind
- 쿠버네티스의 경량 버전으로 다중 노드를 구성할 수 있음
✔ POD
개요
- 쿠버네티스의 기본 배포 단위이면서, 다수의 컨테이너를 포함하는 것이 가능함
- 하나의 Pod에 다른 종류의 컨테이너를 여러 개 배치할 수 있는데, 이러한 패턴을 sidecar 패턴이라고 합니다.
create 또는 apply 명령어를 이용해서 생성하기
- 생성은 명령어를 이용할 수 있고, 정의된 yaml 파일을 호출해서 생성하는 것도 가능합니다.
- httpd 이미지를 가지고 명령어를 이용해서 pod를 새엇ㅇ
kubectl create deployment 파드이름 --image=이미지이름 --replicas=레플리카개수 --port=포트번호설정
- httpd 니까 포트 번호 설정한 것이다.kubectl create deployment my-httpd --image=httpd --replicas=1 --port=80
- port를 포워딩하지 않는다. 외부에 연결하는게 아니니까 말이야.
- --replicas 는 복제본의 개수이다.
- --port는 노드 내에서 접속하기 위한 포트 이다.
stateless와 stateful
- stateless
- 사용자가 애플리케이션을 사용할 때, 상태나 세션을 저장해 둘 필요가 없는 경우에 사용하는 방식
- 저장소가 없다 - stateful
- 상태나 세션을 별도의 데이터 저장소에 저장하는 방식
- 상태나 세션을 저장해야 하는 경우는 로그인이 있거나 장바구니와 같은 데이터가 필요한 애플리케이션
배포가 제대로 되었는지 확인하자
kubectl get deployment- READY
- 레플리카 개수 - UP-TO-DATE
- 최신 상태로 업데이트 된 레플리카의 개수 - AVAILABLE
- 사용 가능한 레플리카의 개수 - AGE
- 파드가 실행되고 있는 지속 시간 - 배포의 자세한 정보는 -o wide 옵션을 추가하면 된다.
-kubectl get deployment -o wide - CONTAINERS
- 컨테이너 개수 - IMAGES
- 파드 생성에 사용된 이미지 - SELECTOR
- yaml 파일의 selector이다.
파드의 상태 확인
kubectl get pods
파드의 상태를 자세히 확인하기
kubectl get pods -o wide
파드 삭제
kubectl delete pod 파드이름
디플로이먼트 삭제
kubectl delete deployment 디플로이먼트이름
- 기본적으로는 디플로이먼트를 삭제하면 파드도 삭제
파드 수정
kubectl edit deployment 디플로이먼트이름
- 기본 editor로 편집을 할 수 있는 화면이 출력
-kubectl edit deployment my-httpd
배시에 접속하기
- 생성한 컨테이너나 파드에 접속할 떄는
kubectl exec명령을 사용 - 파드 이름을 먼저 확인하자
-kubectl get pods
-kubectl exec -it my-httpd-cf79fbb57-lh67s -- /bin/bash

- exit 입력하면 빠져나옴 - 배시 셸에 접속하는 이유는 리눅스의 경우는 패키지나 프레임워크 등을 설치해서 개발 환경을 만들기 위해서 하거나, 일반 애플리케이션의 경우는 환경 설정을 변경하기 위해서 이다.
- 최근에는 배시 셸에 직접 접속해서 수행하기 보다는 Dockerfile이나 Docker-Compose 같은 설정 파일에서 RUN이나 CMD명령을 작성해서 수행하고, 환경 설정의 경우는 기본적으로 존재하는 환경 설정 파일을 삭제하고 외부에서 작성한 환경 설정 파일을 복사하는 형태로 사용하는 경우가 많습니다.
파드에 대한 로그 관리
kubectl logs 파드이름
✔ Deployment & Service
Deployment
- 쿠버네티스에서 상태가 없는 애플리케이션을 배포할 때 사용
- 레플리카셋의 상위 개념
- 파드의 개수를 유지할 뿐 아니라 배포 작업을 조금 더 세분화해서 관리 할 수 있음
디플로이먼트 > 레플리카셋 > 파드
- 배포 전략
- 애플리케이션이 변경될 때 사용
- 방법으로는 롤링 업데이트, 재생성 업데이트, 블루/그린 업데이트, 카나리아 업데이트가 있음
롤링업데이트 - 기본
- 새 버전의 애플리케이션을 배포할 때, 새 버전의 애플리케이션은 하나씩 늘려가고 기존 버전의 애플리케이션은 하나씩 줄여나가는 방식으로 업데이트
- 새로운 버전으로 배포된 파드에 문제가 발생하면 다시 이전 버전으로 서비스를 대체할 수 있어서 안정적인 방식이지만 업데이트가 느림
- maxSurge
- 롤링 업데이트를 위해서 최대로 생성할 수 있는 파드 갯수
- 높게 설정하면 배포를 빠르게 할 수 있음 - maxUnavailable
- 롤링 업데이틀 위해서 최대로 삭제할 수 있는 파드 갯수
- 높게 설정하면 배포를 빠르게 할 수 있음 - 롤링 업데이트 일시 중지
-kubectl rollout pause 디플로이먼트이름 - 상태 확인
-kubectl rollout status 디플로이먼트이름 - 롤링 업데이트 계속 수행
-kubectl rollout resume 디플로이먼트이름 - 롤링 업데이트 롤백
-kubectl rollout undo 디플로이먼트이름 - 롤링 업데이트 롤백 히스토리
- `kubectl rollout history 디플로이먼트이름
- 히스토리를 확인해서 나오는 revision 번호를 이용해서 롤백이 가능
재생성(recreate) 업데이트
- 기존의 모든 파드를 삭제하고 새로운 버전으로 파드를 생성
- 빠르게 업데이트 할 수 있지만, 새로운 버전에 문제가 발생하면 대처가 늦어질 수 있음
- 애플리케이션을 충분히 테스트 한 뒤, 에러가 발생하지 않는다는 가정이 있을 때 사용
- 일시적인 서비스 중단이 발생할 수 있음
v1,v1 -> v2, v2
strategy:
type:Recreate블루/그린 업데이트
- 블루는 이전 버전, 그린은 새로운 버전
- 블루와 그린을 동시에 운영하는 형태
- 서비스 목적으로 그린 버전을 업로드해서 사용하고, 이전 버전은 테스트 목적의 블루 버전이 됩니다.
- 서비스는 그린 버전만 됩니다.
- 그린 버전에 문제가 생기면, 그린 버전만 삭제하면 이전 버전을 사용할 수 있음
- 그린 버전을 배포할 때는 내용은 거의 블루 버전과 동일하고
version이라는 키의 내용만 다른 값으로 수정하면 됩니다. - 많은 파드가 필요하기 때문에 많은 자원을 소모합니다.
카나리아 업데이트
- 블루/그린과 유사하지만, 더 진보적인 방식
- 몇몇 새로운 기능을 테스트 할 때 주로 이용
- 2개의 버전을 배포합니다.
- 나중에 배포되는 버전은 트래픽을 조금씩 증가시킵니다.
- 5%로 시작해서 마지막엔 50% (일반적)로 트래픽 증가시키면서 업데이트 - 새로운 버전이 문제가 없다고 판단하면 이전 버전을 종료시키면 됩니다.
- labels 키에 track:canaru 만 추가해주면 됩니다.
- 이 방식은 SNS와 UI나 UX업데이트를 자주 하는 곳에서 많이 사용합니다.
- 카나리아 업데이트를 할 때, 파드가 여러 개인 경우, 클라이언트가 어떤 파드로 접속할 지 알 수 없음
- 유저가 새로운 UI로 접속했다가, 재접속시 이전 버전의 UI로 접속하는 문제 발생
- 이런 경우를 방지하기 위해서 sticky session을 활용
- 한 번 접속한 노드로 계속 접속하도록 만듭니다.
yaml 파일 만들어서 deployment 배포
apiVersion: apps/v1 kind: Deployment #배포할 오브젝트 종류 설정 # 메타 데이터 설정 - 기본이 되는 옵션 metadata: name: nginx-deploy # 디플로이먼트이름, 안헷갈리게 yaml파일이름과 같게 함 주로 labels: app: nginx # deployment의 label, #이 안에 생성되는 레플리카나 파드의 기본 이름이 된다.(prefix) #즉 nginx이름을 달고 나온다. spec: replicas: 2 # 파드의 개수 설정 - 동일 종류의 파드 개수 # 디플로이먼트가 관리할 파드를 선택 selector: matchLabels: # nginx 붙는 애들은 다 선택한거임 이러면 app: nginx #실제 파드를 만들 정보 template: metadata: labels: app: nginx # 컨테이너 정보를 설정 spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80
- kubectl apply -f nginx-deploy.yaml 실행하면 됩니다.
- Deployment 확인
-kubectl get deployment

- 물론 자세히 볼 수 있긴 하다
- pod도 당연히 확인 할 수 있다.
-kubectl get pods - pod 이름 부여 방법
- 디플로이먼트이름-레플리카셋이름-파드의이름을 랜덤하게 생성
-nginx-deploy-57d84f57dc-ljjb4이렇게 말이다. - 현재 상태에서 외부 접근을 시도 하면 될까?
- 당연히 안된다.
쿠버네티스의 서비스
- 파드는 동일한 워커 노드 안에서만 접근이 가능합니다.
- 파드를 만들더라도 외부에서는 파드에 접근할 수 없습니다.
- 동일한 종류를 갖는 파드들에 서비스를 연결해주면 외부에서 접근이 가능합니다.
- 서비스는 여러개의 파드가 존재하는 경우, 로드 밸런싱 기능도 수행합니다.
- 실제 로드밸런싱 기능은 대부분 클라우드의 로드 밸런서나 인그레스가 담당합니다.
- 쿠버네티스에서는 개발자가 직접 로드 밸런서를 구현할 필요가 없습니다. - 서비스를 만들면 Cluster IP 외에 NodePort가 할당되어 외부와 연결합니다.
- 서비스에서 포트 포워딩을 수행합니다.
앞에서 만든 nginx 파드를 외부에서 접속이 가능하도록 해주는 yaml파일 생성
- nginx-svc.yaml
apiVersion: apps/v1 kind: Service metadata: name: nginx-svc labels: app: nginx #서비스의 레이블 spec: type: NodePort #외부로 노출시킬 것이다. # 포트 포워딩을 할거라는 말이지 ports: - port: 8080 NodePort: 31472 #외부 포트 targetPOrt: 80 #내부 포트 selector: app: nginx
- 서비스 실행
-kubectl apply -f nginx-svc.yaml - 확인
-kubectl get svc

- 그럼 이제 localhost:31472 해주면 nginx 접근 가능하겠지?
롤백
- 디플로이먼트는 롤백 기능을 제공함
- 업데이트 버전에 문제가 발생한 경우, 이전 버전으로 변경할 수 있는 기능
- 이미 배포된 deployment의 이미지를 변경할 수 있음

kubectl set image deployment.v1.apps/디플로이먼트이름 기존이미지=새로운이미지
- 물론 yaml 기반으로 변경점은 알아서 바꾸면 된다.- nginx:1.16.1로 바꾼다하면?
-kubectl set image deployment.v1.apps/nginx-deploy nginx=nginx:1.16.1 - 확인
-kubectl describe deploy nginx-deploy
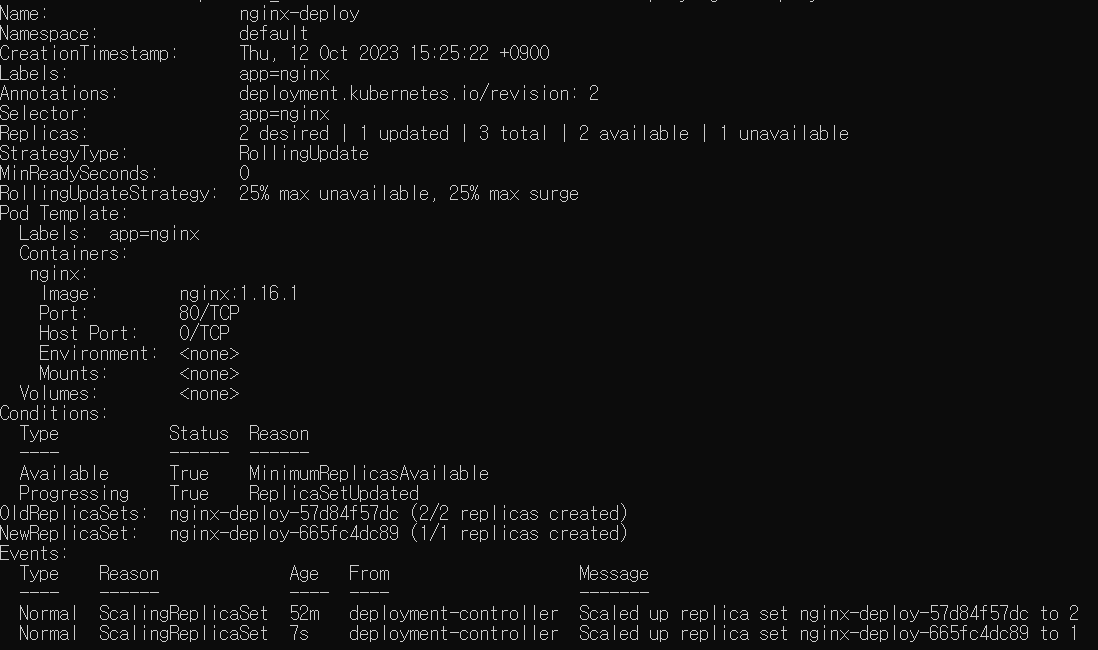
- 1.200 버전으로 해보자(문제발생!)
-kubectl set image deployment.v1.apps/nginx-deploy nginx=nginx:1.200 - 현재 상태 확인
-kubectl rollout status deployment/nginx-deploy
쿠버네티스는 잘못된 업데이트를 해도 기존의 상태를 유지할 수 있다(무중단 서비스)
- 파드 확인하기
-kubectl get pods

- 업데이트를 하고 있는데 이미지 풀백을 못하고 있어서 못쓰고 있지만, 나머지가 계속해서 running 중임을 알 수 있다.
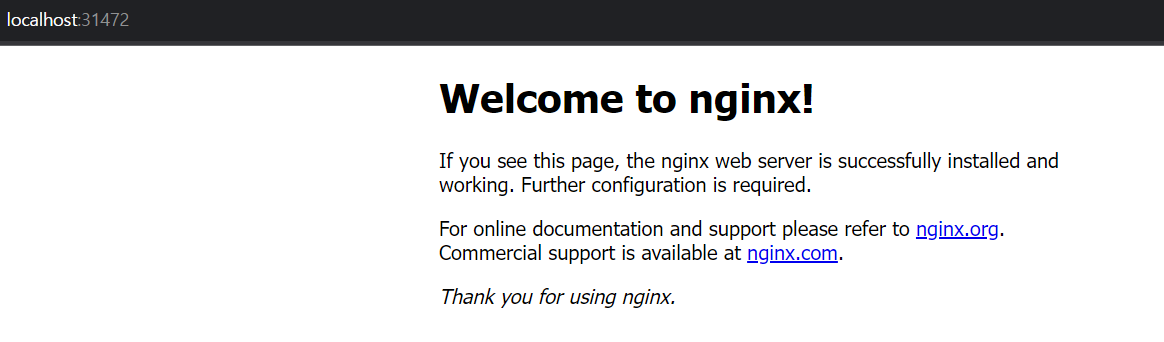
- 귀신같이 잘돌아감
- 롤백해야겠다.
-kubectl rollout undo deployment/nginx-deploy
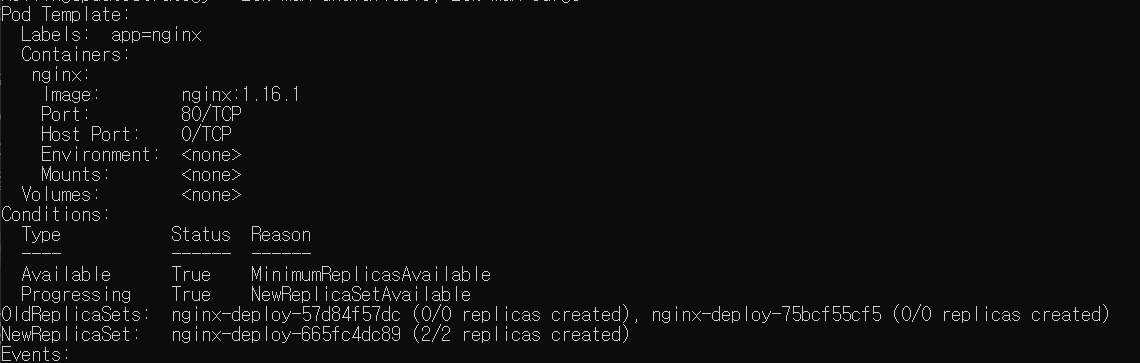

- 중단되는 애 없이 잘 돌아가고 있다.
✔ 정리
- 파드
- 한꺼번에 관리되어야 하는 컨테이너의 집합(애플리케이션)
- deployment를 이용해서 배포되는데, 이 때 replica도 같이 생성
- 파드를 외부로 노출할 때는 service를 만들어서 배포해야 합니다. - 쿠버네티스의 업데이트
- deployment를 업데이트 할 때, 기존 pod를 중지시키고 업데이트를 하는 것이 아닌, 기존 pod를 그대로 둔 채 새로운 pod를 추가해서 업데이트를 수행하는데, 성공하면 기존 pod를 제거하고 새로운 pod를 서비스에 추가하는 형태 , rolling update를 진행함
- 이 방식을 이용해서 무중단 서비스를 구현합니다.
✔ ReplicaSet
개요
- 일정한 개수의 파드가 항상 실행되도록 관리
- 이 기능을 이용하면 무중단 서비스를 구현할 수 있고, scale up과 scale down이 편리해지며, 장애가 발생하더라도 서비스가 중단되지 않습니다.
ReplicaSet 테스트를 위한 yaml 파일 작성
- replicaset.yaml
apiVersion: apps/v1 kind: ReplicaSet metadata: name: 3-replicaset spec: template: metadata: name: 3-replicaset labels: app: 3-replicaset spec: containers: - name: 3-replicaset image: nginx ports: - containerPort: 80 replicas: 3 selector: matchLabels: app: 3-replicaset
kubectl apply -f replicaset.yaml로 만들어보자.
- 현재 상태 확인
- replicaset과 pods를 같이 확인해보자.
-kubectl get replicaset,pods
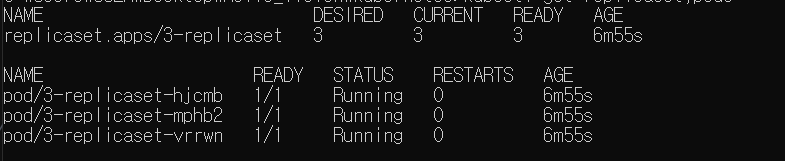
- 잘 보인다...
- 하나의 파드를 삭제하고 현재 상태를 다시 확인하겠다.
- 파드를 삭제하면, 삭제하는 순간 파드가 없어지고 새로운 파드가 생성된다.

- 바로 새로운 파드가 생성된 것을 알 수 있다.
- replicaset을 이용하면 일정한 개수의 파드를 계속 유지할 수 있습니다.
replicaset의 크기 변경
kubectl scale replecaset/레플리카셋이름 --replicas=개수
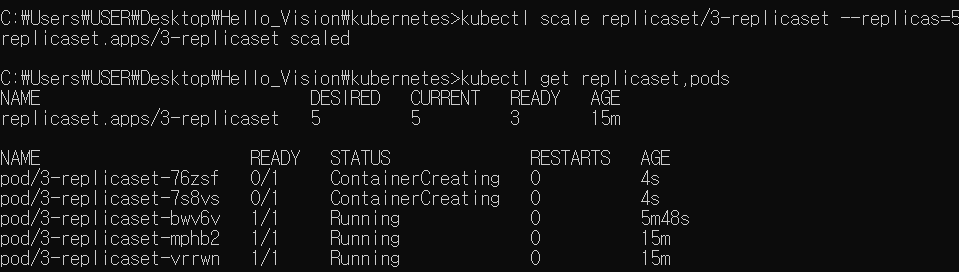
- 5개로 순식간에 변경 완료
- replicaset을 이용하면 scale up과 down이 간편하게 구현됩니다.
- 물론 정확한 표현은 scale up이 아닌 scale out 입니다.
- scale up은 장비의 성능을 높이는 것을 의미
- scale out은 장비의 개수를 늘리는 방식 - replicaset 지우는 방법
-kubectl delete -f 파일명
-kubectl delete -f replicaset.yaml
- 이러면 생성된 파드도 같이 삭제
-kubectl delete -f 파일명 --cascade=orphan- 이러면 레플리카 셋만 삭제합니다.
- 레플리카 셋만 삭제 시, 파드를 삭제하면 새로운 파드로 복원되지 않습니다.
- 이러면 레플리카 셋만 삭제합니다.

밀가루 귀여워요